
ACL 2023 | 文档级别机器翻译的目标端数据增强
导读
文档级别机器翻译任务由于输入较长而训练样本较少,导致模型训练遭遇严重的数据稀疏问题。针对这个问题,本文提出一种新的数据增强方法“目标端数据增强”,引入一个数据增强模型来为每个输入文档生成多个潜在的高质量翻译文档。
通过学习这些新生成的翻译文档,传统的机器翻译模型也能够学到平滑的目标分布,从而降低数据稀疏的风险。本文的方法在News和Europarl评测基准上获得SOTA结果,在News语料上提升达2.30个BLEU。

论文题目:Target-Side Augmentation for Document-Level Machine Translation
论文链接:https://aclanthology.org/2023.acl-long.599/
代码链接:https://github.com/baoguangsheng/target-side-augmentation
研究动机
尽管神经网络模型在句子级别机器翻译上达到了与人类相媲美的水平,但在文档级别机器翻译上还远远不能令人满意。相比句子级别机器翻译,文档级别机器翻译更加接近真实的应用场景,因为实际应用中翻译的典型输入是文本文档而不是单个句子。
与句子级别翻译任务不同的是,文档级别机器翻译任务在翻译每个句子时,需要考虑更大范围的句子间的前后关联,包括句间指代、词汇一致性、篇章关系等。
以英语到俄语的翻译场景为例,对于英语语句“We haven't really spoken much since your return. Tell me, what's on your mind these days? ”我们在翻译“your”时可以有三种不同的俄语翻译:单数非正式用语、单数正式用语和复数用语。我们需要结合上下文信息,才能够对这里的“your”的单复数做出准确判断。
上下文信息对于准确理解语句至关重要,而这种考虑上下文信息做出翻译的能力也是人类翻译人员的必备技能。
在现实应用中,文档的结构和大小各异,从简短的电子邮件到冗长的法律合同或小说。这些文档的多样性和复杂性可能会加剧数据稀疏问题。
总的来说,尽管大型语言模型的出现,处理文档级机器翻译中的数据稀疏性问题仍然是提高翻译文档质量和一致性的关键任务。
本文提出一种目标端数据增强方法。相比较于MT任务上常用的源端数据增强方法back-translation,目标端数据增强的已有工作相对较少并且不是那么有效。本文的工作填补了现有技术在这个方向上的不足。
方法
目标端数据增强方法的核心是一个数据增强(DA)模型。不同于机器翻译(MT)模型,数据增强模型对机器翻译的后验分布进行建模。它基于一个核心的假设:机器翻译的后验分布比先验分布能更好地逼近数据的真实分布。
在论文的4.2节中,我们集中讨论并验证了这个假设。此处,在图1中,我们使用了一个简单的例子来说明目标端数据增强方法的工作原理。
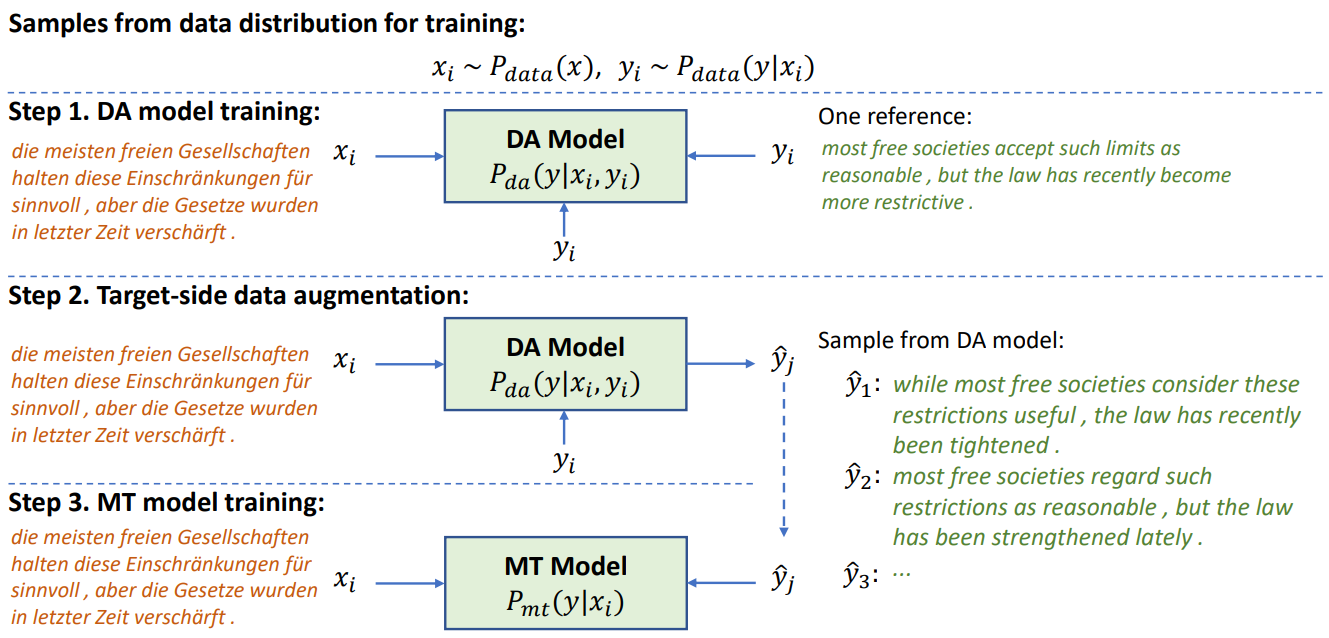
图1:一个简单的例子说明目标侧数据增强
我们首先引入一个DA模型对机器翻译的后验分布进行建模(Step 1),然后使用DA模型为每个训练样本生成多个可能的目标翻译(Step 2),最后使用增强的数据集训练MT模型(Step 3)。
对于机器翻译任务$P(y|x)$,其中输入$x$称为源端,代表源语言内容,输出$y$称为目标端,代表目标语言内容。目标端数据增强之所以有效,某种程度上是因为MT模型对机器翻译的先验分布$P(y|x_i)$进行建模,将翻译内容$y_i$作为训练目标通过梯度反传进行学习,导致学习不充分。
而DA模型对后验分布$P(y|x_i,y_i)$进行建模,将部分翻译内容作为额外输入预测完整的翻译目标。因为DA模型有额外的目标翻译信息作为输入,所以其预测任务会更简单,甚至可以用比MT模型更少的参数(详见论文4.5节)。
DA模型的设计和训练是本文的关键。DA模型对后验分布进行建模,以观测到的目标翻译$y_i$作为额外输入条件,预测其它的目标翻译$y$。因为训练数据只提供一个目标翻译$y_i$,我们需要同时使用这个翻译作为输入条件和输出的训练目标。为了防止$y_i$同时出现在输入和训练目标中导致输出结果多样性(diversity)下降,我们引入一个中间的隐变量z来隔离输入条件和输出目标,并使用蒙特卡洛采样来估算对隐变量$z$的积分。详细论述见论文第3节。
实验结果
实验结果表明,DA模型能生成非常丰富的目标翻译。如表1所示,对于源语言(source)单词或短语,生成的翻译不同于参照翻译(target),有丰富的用词、语法和同义表达。
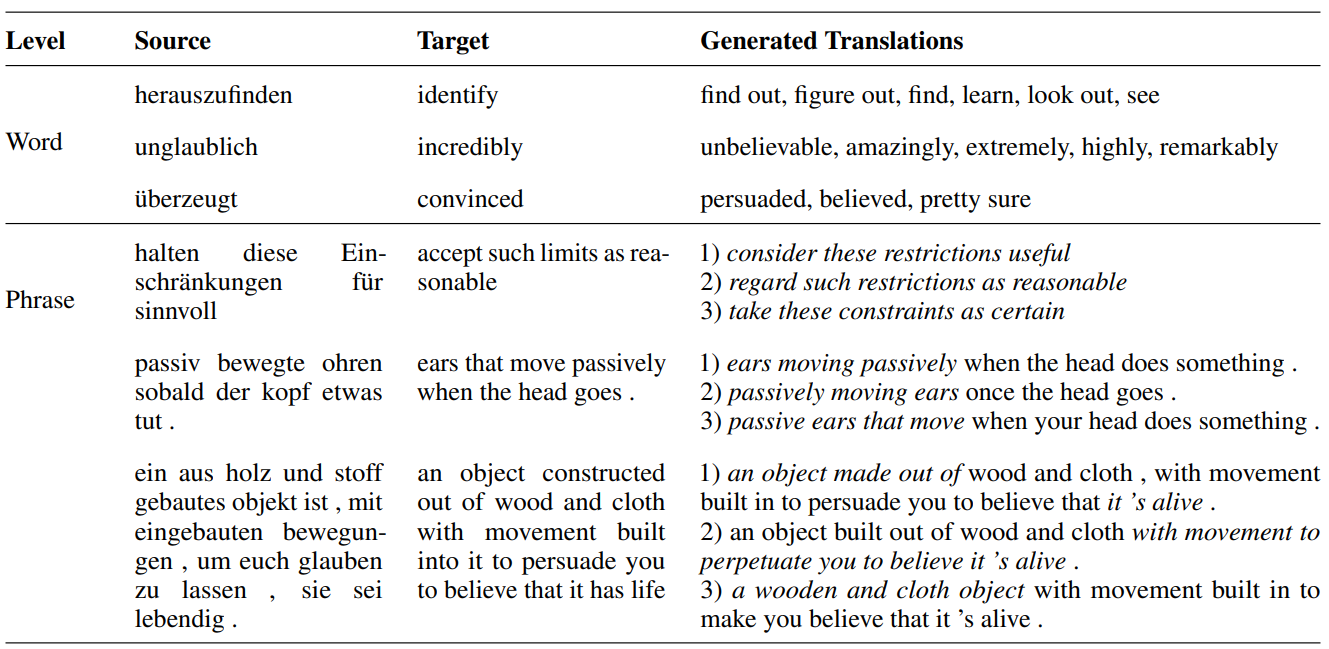
表1:DA模型生成丰富的目标翻译
从翻译指标上来看,如表2所示,我们在TED、News和Europarl三个基准测试上,对比句子级别基线模型Transformer、文档级别基线模型G-Transformer、以及他们的Back-translation数据增强基线。
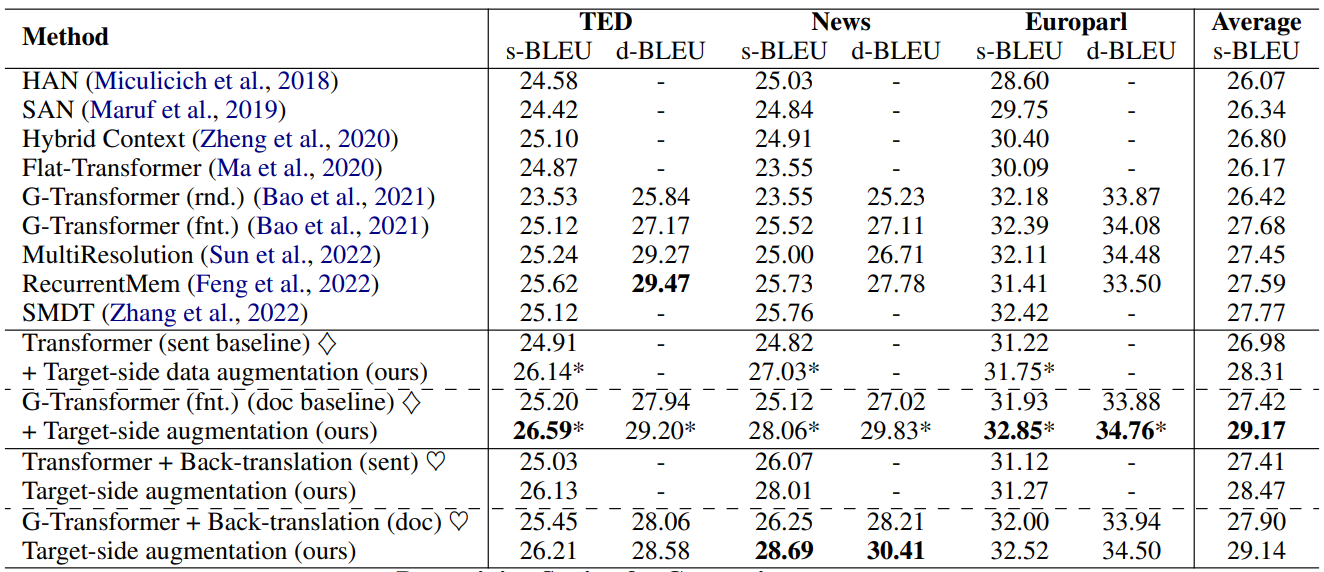
表2:在三个数据集四个基线方法上提升性能
目标端增强方法在三个数据集、四个基线方法上带来显著的BLEU指标的提升。尤其在News上,超过之前最好结果达到2.30个BLEU。在Back-translation的基础之上,还能进一步提升性能,超过之前最好结果达到2.93个BLEU。

表3:后验vs先验
后验vs先验:如表3所示,我们直接对比了先验分布和后验分布对机器翻译数据分布的逼近效果。我们使用有多个候选翻译的数据集newstest2021进行评估。对于后验分布的评估,用其中一个候选翻译作为额外输入条件,预测其它候选翻译。对于先验分布,我们直接预测其它候选翻译。在News上,后验分布能够得到更低的PPL,说明它比先验分布更符合真实的数据分布。同时,对比两种方法生成的翻译的Diversity和Deviation指标,我们可以看到后验分布能够更好的平衡Diversity和Deviation,生成的翻译更接近目标候选翻译(较低的Deviation)。
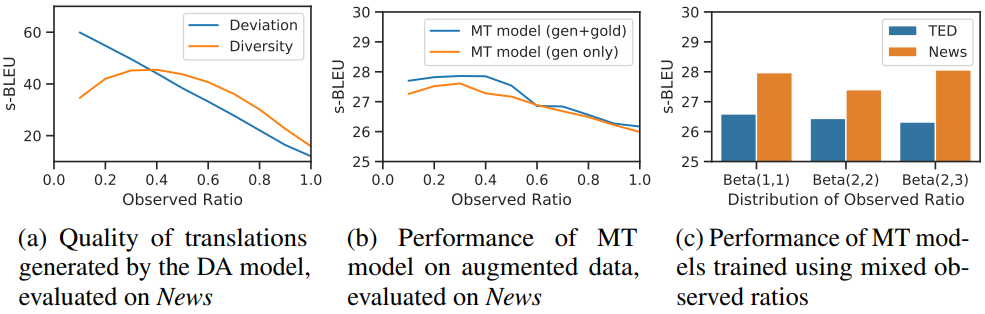
图2:隐变量z
隐变量z:如图2所示,我们分析了隐变量相关的关键参数Observed Ratio对模型效果的影响。如图2(a)所示,Observed Ratio越大,隐变量中包含的目标翻译的信息就越多,使得DA模型生成的翻译越接近于目标翻译(Deviation越小),但同时Diversity也越小。对比图2(b),我们可以看到MT效果在Observed Ratio处于0.4左右达到最好,因为图2(a)这个区域平衡了Deviation和Diversity。最终我们使用Beta分布来采样Observed Ratio,混合不同Ratio下生成的翻译获得更好的Diversity,从而得到更好的性能,如图2(c)所示。
结语
主要结论:1)传统的先验分布建模不能充分学习数据中的模式,后验分布比先验分布能更好的逼近真实的数据分布;2)在训练集没有多个候选翻译的条件下,通过引入隐变量,可以有效建模机器翻译的后验分布;3)平衡Diversity和Deviation是DA模型获得最佳效果的关键。
未来工作:
目标端增强方法理论上适用于任何“一个输入对应多个输出”的seq2seq任务。在诸如文本摘要、对话、文本生成、问答等任务上,如何使用类似的目标端增强方法,都值得深入研究。进一步的,后验分布的建模也是一个有意思的问题,理论上我们可以采用各种不同的隐变量方法,如高斯分布、离散分布等来建模。使用不同的建模方法,隐变量包含的信息是不一样的,有些是局部信息,有些是全局信息,这些都可能会产生不同的效果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢