
我们都知道OPENAI在1月25日更新了两个新的嵌入模型,text-embedding-3-small 和text-embedding-3-large。这里不同于以往,有个显著的区别,这两个模型可以动态的修改输入输出维度了,其中最核心的技术就是 2022 年谷歌的 Matryoshka Representation Learning。

openai 的 Embedding 模型
很可惜,这篇文章在谷歌2022年发布以来引用量不超过20次,今天就来聊聊基于这个工作的一个新工作,二维套娃句子嵌入(2DMSE)。
这篇工作一出就很快被 Hugging Face 的 Sentence Transformers 的项目维护者 Tom Aarsen 采纳,并目前已更新在新的 Sentence Transformers 包中。目前在X上也有许多讨论。
Aarsen 的回复
回过头来看看这篇文章到底有那些创新点呢?
套娃表示学习(MRL)能够在最小化效率与准确性权衡的情况下缩短嵌入向量。开发者可以在嵌入向量的末端简单地丢弃一些维度,而不会损害其表示质量,从而提高下游任务的效率。OpenAI 使用 MRL 来缩短他们的嵌入。但它通过所有 Transformer 层计算嵌入,导致昂贵的推理阶段没有改变。
二维套娃句子嵌入(2DMSE),它通过在训练过程中随机选择 Transformer 的不同层并进行微调,提高了句子嵌入的效率和适应性。2DMSE模型支持在嵌入大小和Transformer 层数上进行弹性配置,使得模型能够在保持性能的同时,显著减少计算和内存消耗。实验结果表明,2DMSE在语义文本相似性(STS)任务上表现出色,且在不同嵌入维度和模型深度的配置下具有很好的可扩展性,使其适用于各种计算资源和任务需求。
下面这张图对比了传统嵌入,MRL 和 2DMSE 三种嵌入方法的区别,可以看出三者都是基于Transformer架构,但是传统句子嵌入不具有层可伸缩性,且推理速度传统句子嵌入<MRL<2DMSE,嵌入的利用率,传统的要慢于 MRL 和 2DMSE。且后两个都有嵌入可以独立使用。紫色块代表与套娃损失一起经过AngIE微调的Transformer层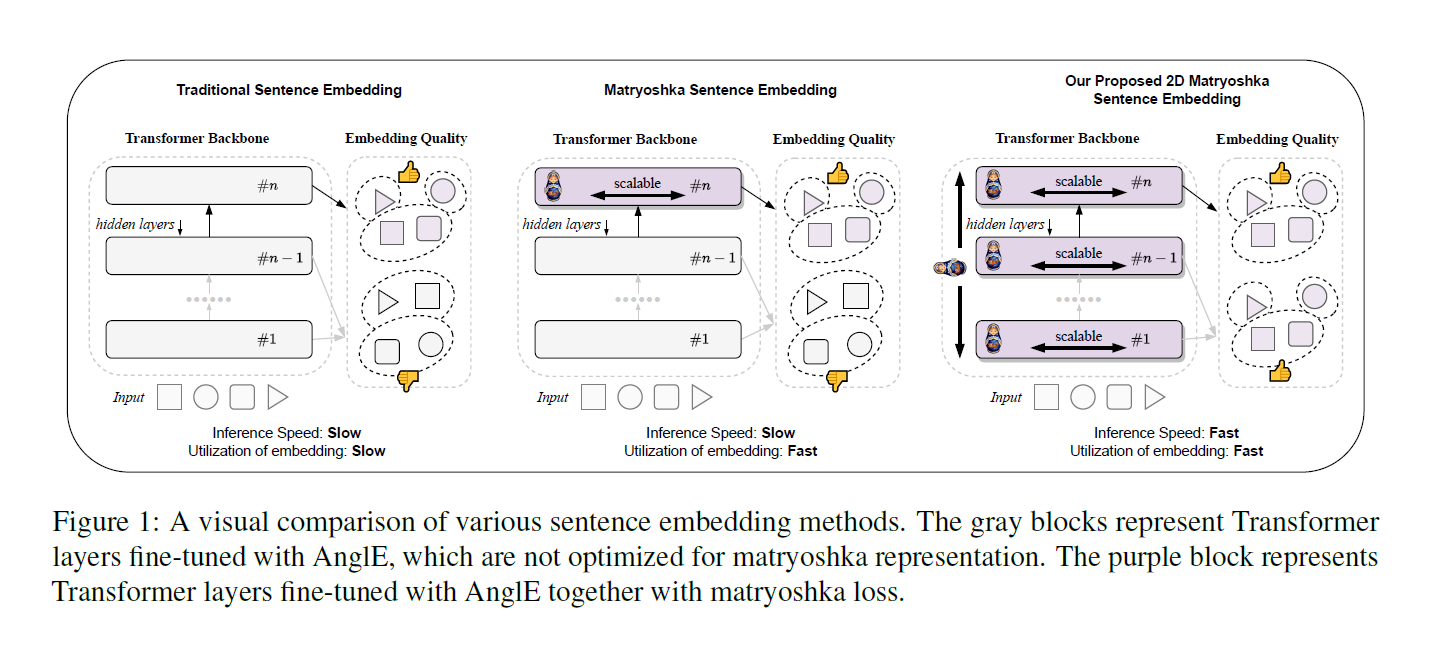
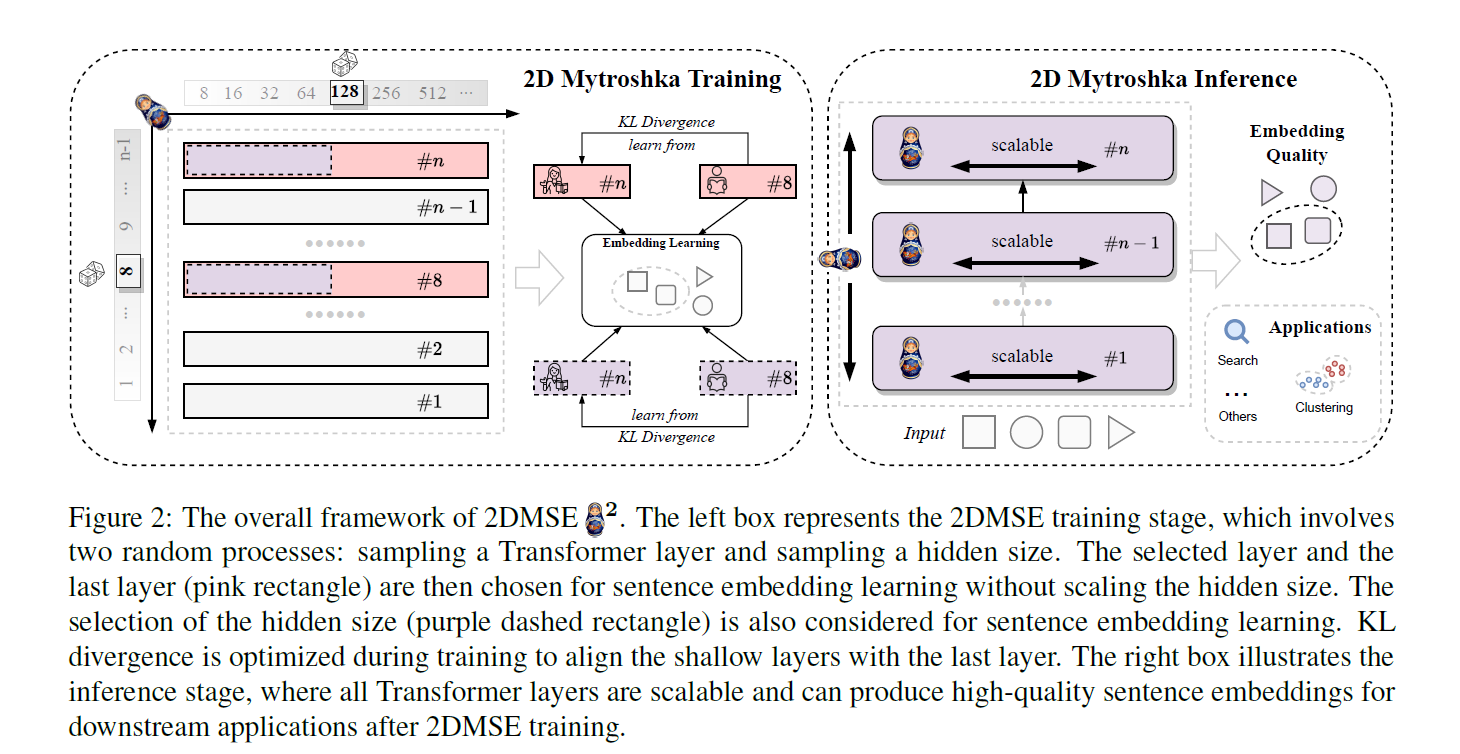
下面详细描述了 2DMSE 的整体框架
-
2D Matryoshka Training(2D套娃式训练):
- 左边的框体代表了2D套娃式训练(2DMSE)的阶段。
- 这个过程涉及随机选择一个Transformer层和一个隐藏层的大小。图中显示了不同的隐藏层大小(例如8, 16, 32, ... 512)。
- 被选中的层(粉红色矩形)和选择的隐藏大小(紫色虚线矩形)用于句子嵌入的学习,而不改变隐藏层的大小。
- 在训练期间,通过KL散度(KL Divergence)优化,以将浅层与最后一层对齐。
-
2D Matryoshka Inference(2D套娃式推断):
- 右边的框体说明了推断阶段,在这个阶段,所有Transformer层都是可伸缩的,并且能够产生高质量的句子嵌入。
- 这些嵌入可用于下游应用,例如搜索和聚类,这些应用在图的右下角用图标表示。
在STS基准测试中,可以看出,对于某些层(如层索引为1和2),提出的2DMSE方法(绿色正方形)通常得到了更高的Spearman得分,这表明它在这些特定层级上产生了更好的句子嵌入。
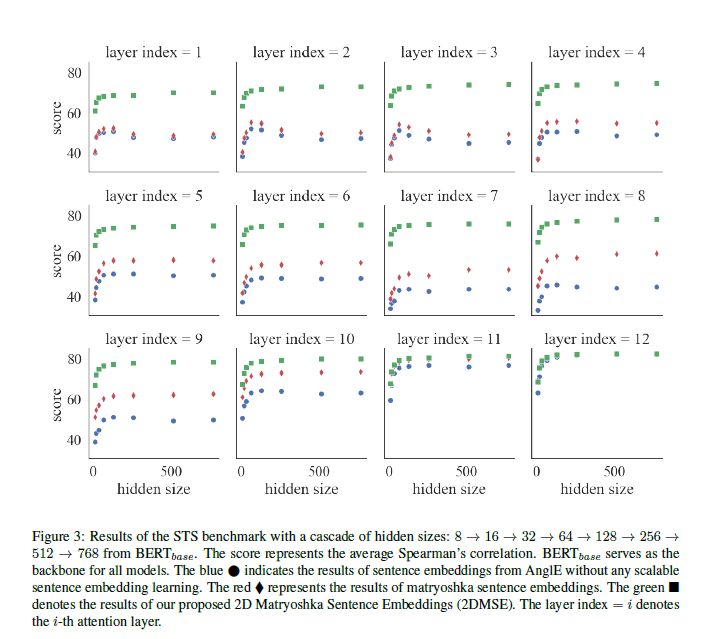
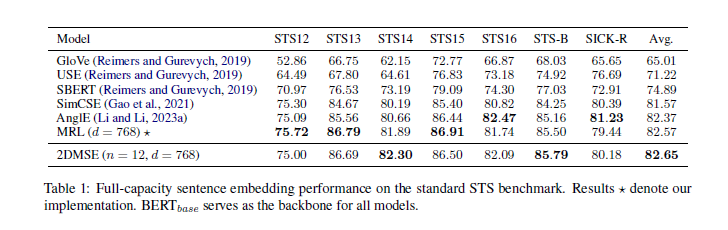
这里是不同模型在STS中的表现,以BERTbase作为基准
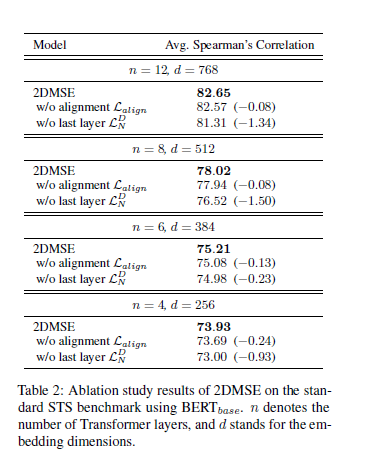
下面是消融实验的结果
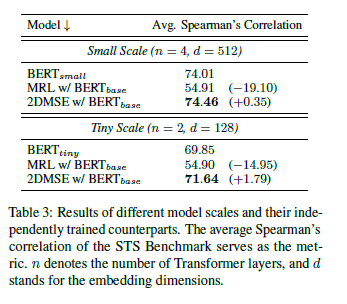
这个表格显示了当模型规模缩小以适应部署限制时,2DMSE方法相对于基线BERT_base和MRL方法的性能提升。在这些实验中,2DMSE在较小规模的BERT模型上表现出了更好的性能。这些结果可能对于那些需要在资源受限环境中部署高效的语义理解模型的开发者很有用。
最后面讲了讲性能和计算成本的权衡
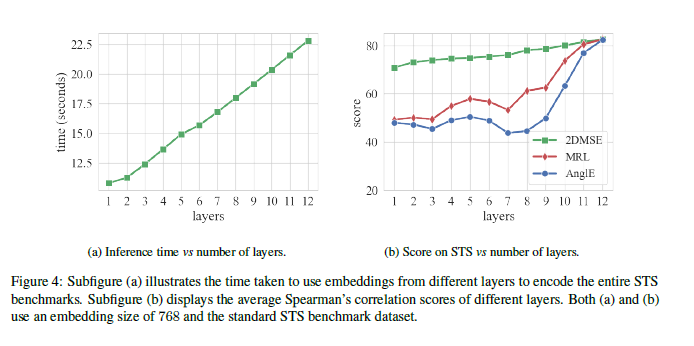
最神奇的是,整个实验下来,明明是缩小了嵌入维数,按理来说应该降低了精度,但在某些情况下反而升高了,也就是说很有可能在俄罗斯套娃的过程中去掉了一些干扰噪声,使得模型不仅推理更快,连下游任务的精度也进一步提升了,欢迎更多小伙伴讨论一下自己的看法!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢