

新智元报道
新智元报道
【新智元导读】就在刚刚,GPT-4被从大模型铁王座上扯下来了!OpenAI最强竞对Anthropic发布的Claude 3系列模型,已经实现了对GPT-4的全面超越。网友表示:GPT-4时代已经终结,OpenAI可以请出Q*了。

全球最强LLM易主
Opus,是Claude 3系列中最先进的模型。 它在多项AI系统常用评估标准,包括本科级别专业知识(MMLU)、研究生级别专家推理(GPQA)、基础数学(GSM8K),均取得领先业界LLM的性能。 尤其是,Opus在处理复杂任务时,展现了几乎与人类相媲美的理解和表达能力,是AGI领域的领跑者。 Claude 3系列模型在分析预测、创建细微内容、代码生成,以及用西班牙语、日语、法语等非英语语言交流的能力上都实现了显著进步。 
比如,通过与Claude 3练习对话,学习西班牙语。 
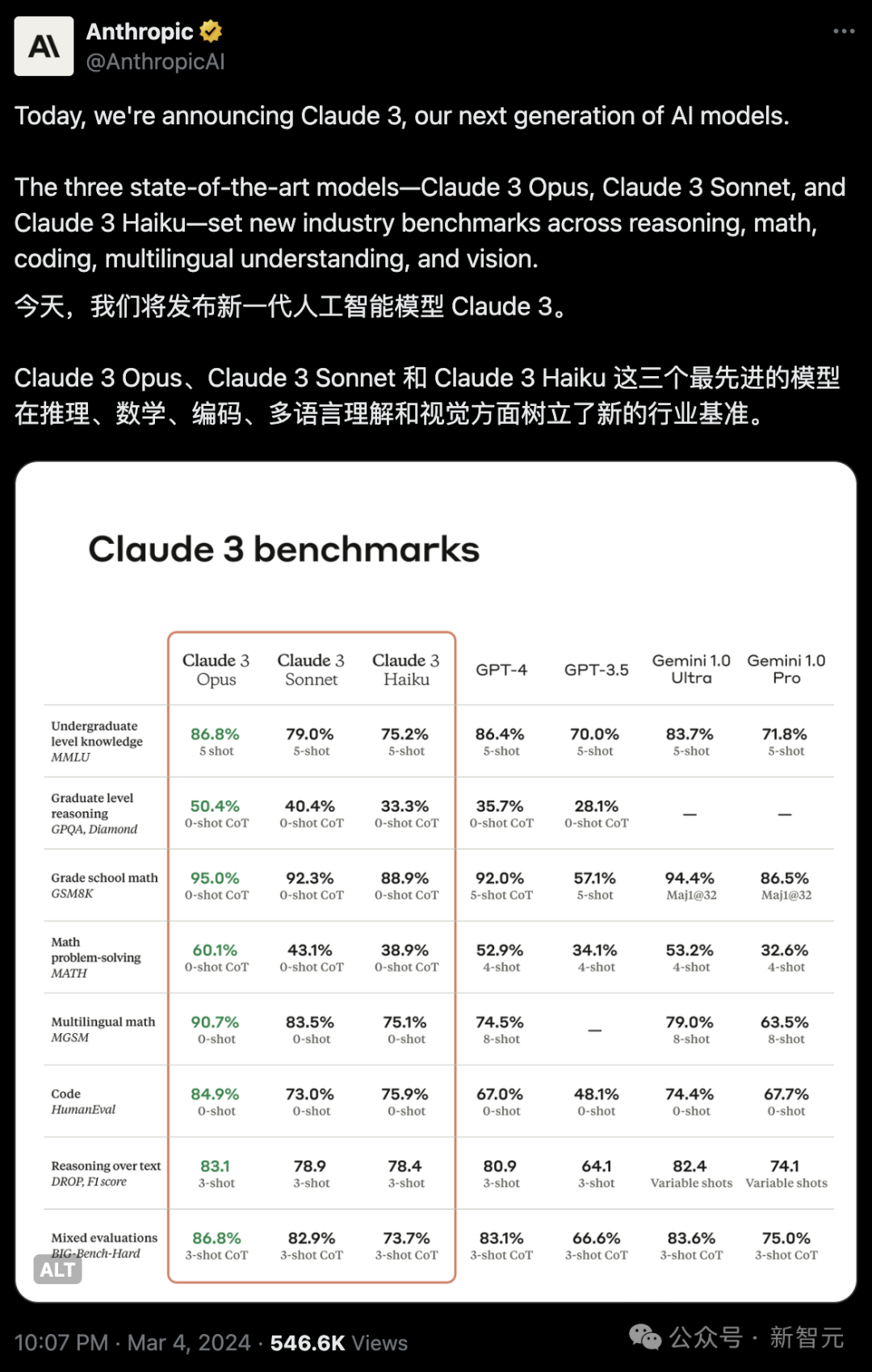
以下是Claude 3系列模型与同行在多个能力评估基准上的对比: 可以看到,其中Claude 3 Opus模型性能完全碾压GPT-4,以及Gemini 1.0 Ultra。 Claude 3 Sonnet在部分基准上,比如GSM8K、MATH等超越了GPT-4。Claude 3 Haiku可以与Gemini 1.0 Pro相抗衡。 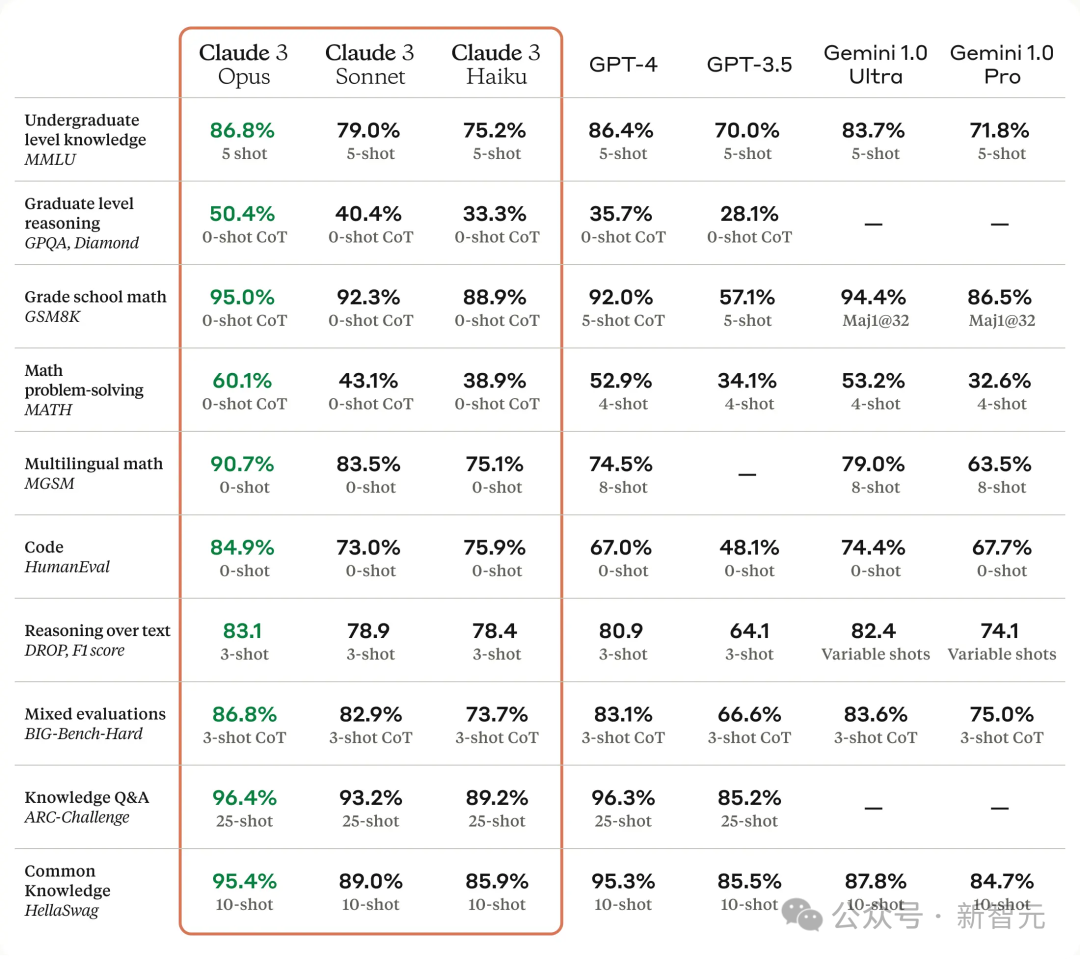
另外,Claude 3 Opus在LSAT、MBE、高中数学竞赛AMC和GRE等多项考试中,成绩也和GPT-4不相上下,甚至大比分超越。 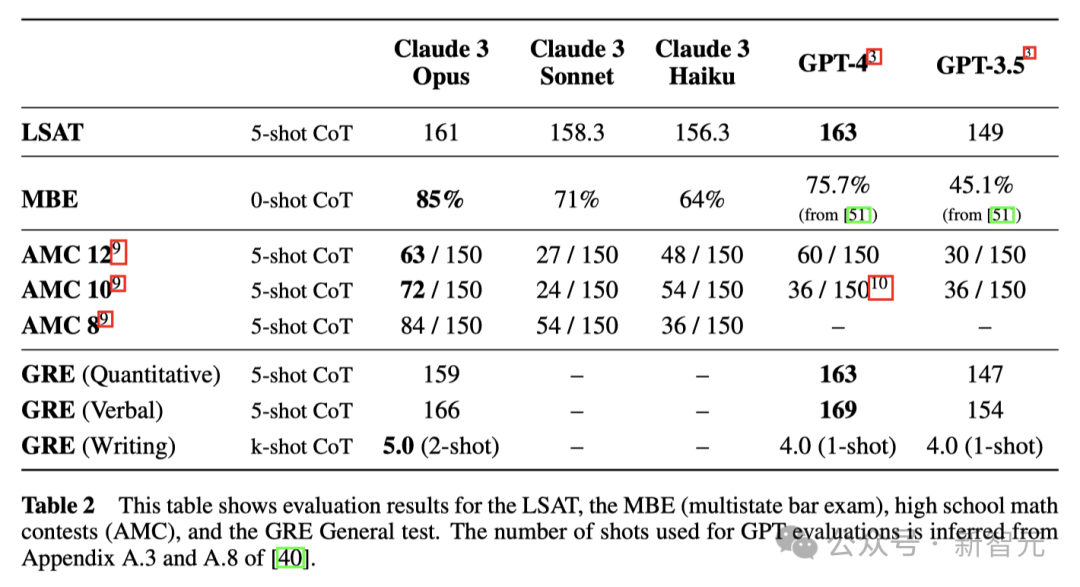
在几分钟内,Opus就化身为经济学专家,分析了全世界的经济情况。 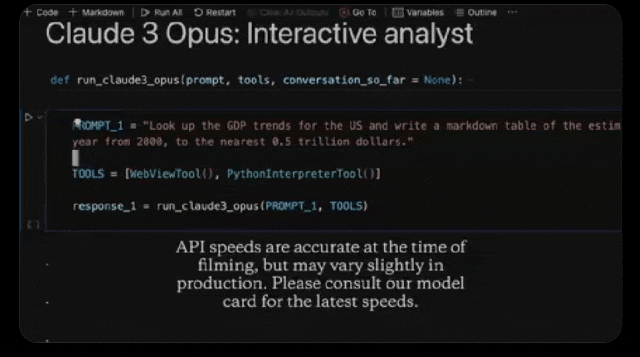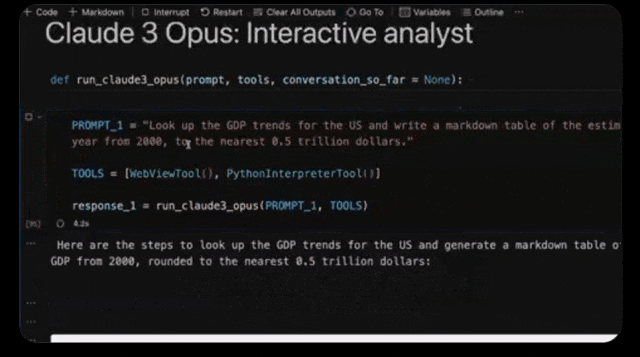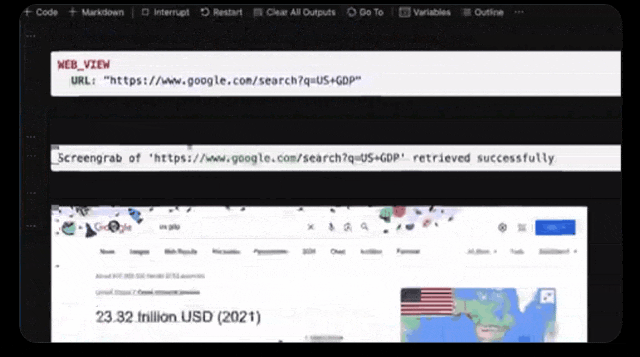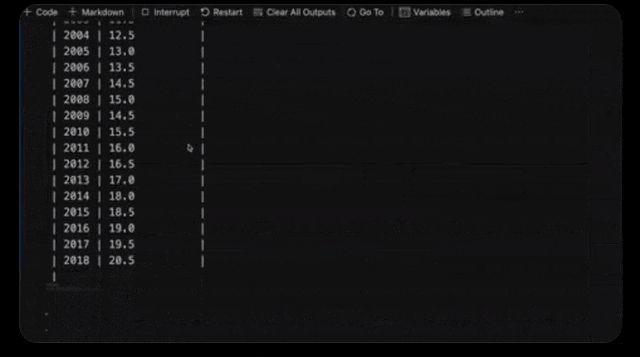
比如,它可以分析出美国GDP在下一个十年可能的范围。 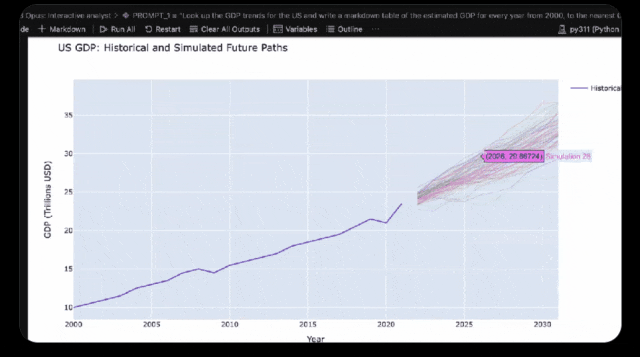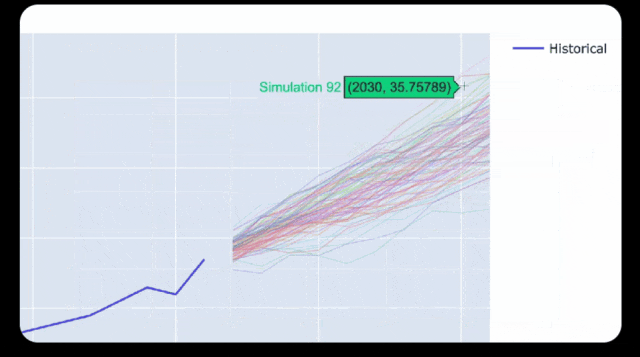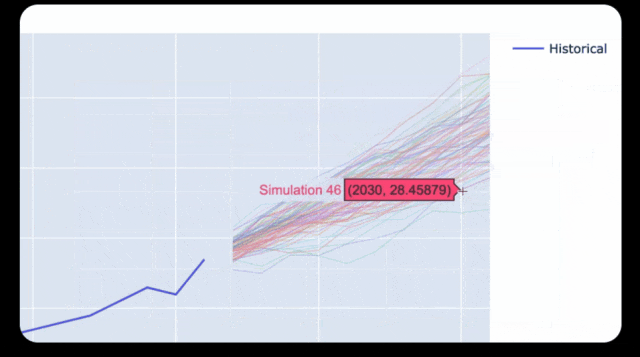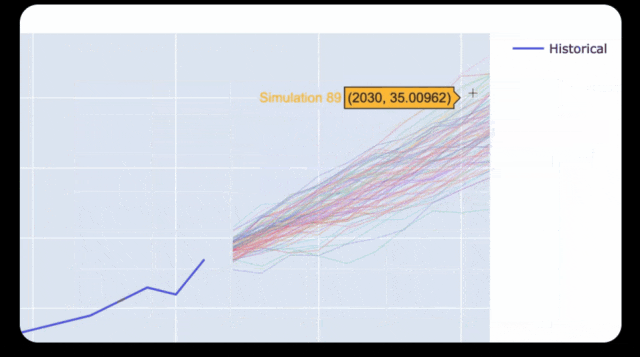
最小规模,3秒读完10k token论文
最小规模,3秒读完10k token论文
Claude 3系列模型能够支持实时用户交流、自动完成和数据提取等任务(需要立即且实时的反馈)。 在同类智能模型中,Haiku以其卓越的速度和成本效益成为市场上的佼佼者。 Haiku可以在不到3秒时间,阅读一个包含图表和图形的信息和数据密集型的研究论文(大约10k token)。 下图显示了Claude 3 Haiku在长达100万token的长上下文数据上的损失。 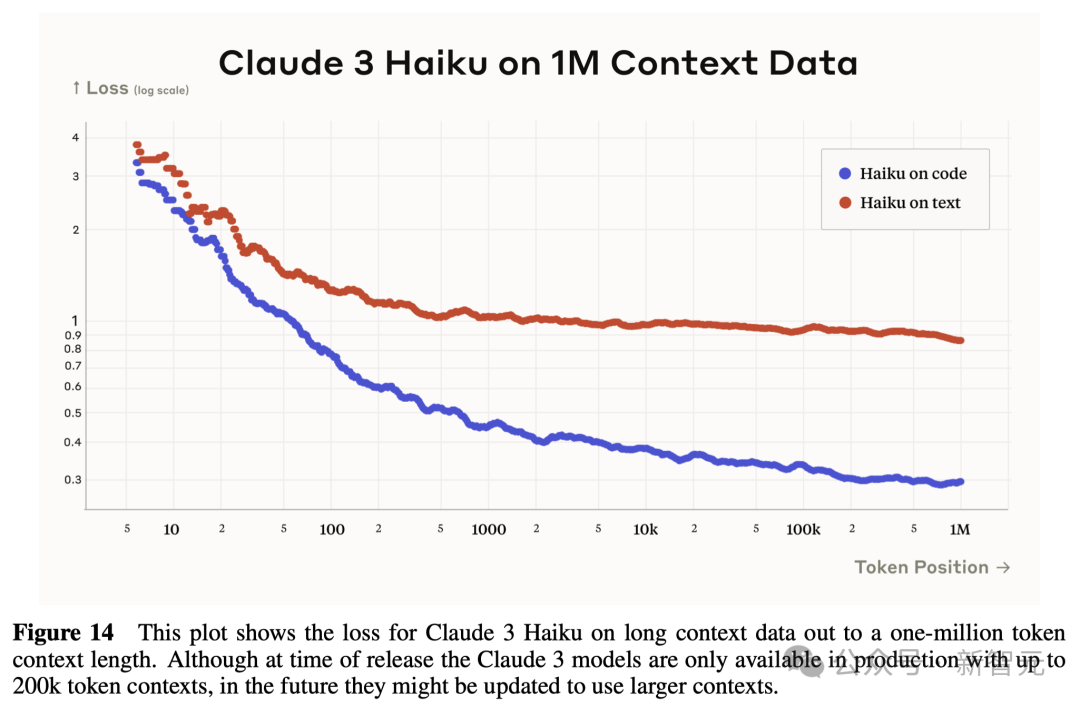
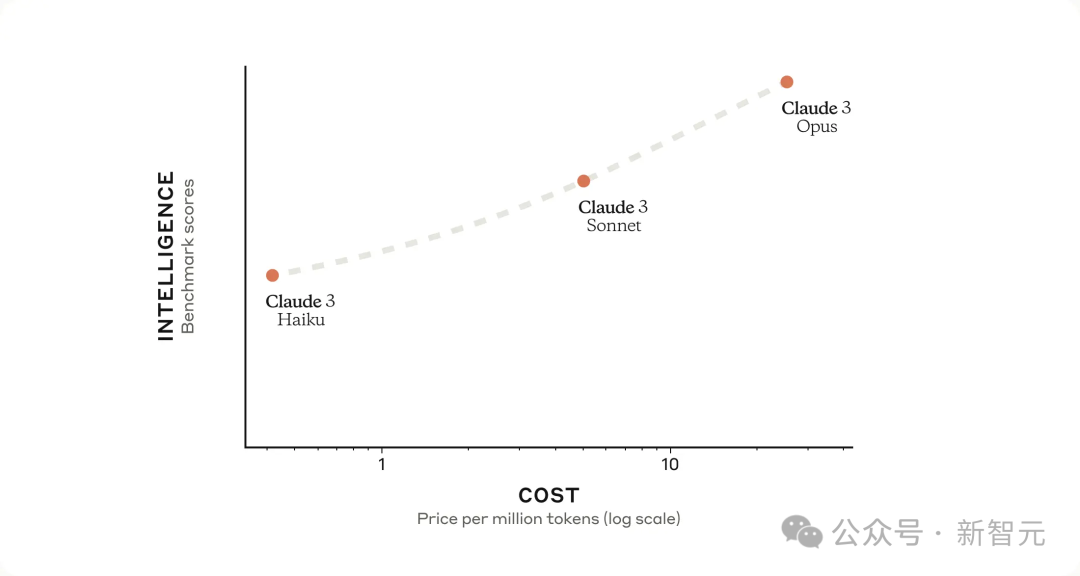
Anthropic预计,在模型发布后,其性能还将得到进一步的优化。 对大多数任务而言,Sonnet的处理速度是Claude 2和Claude 2.1的2倍,而且智能程度更高。 它特别擅长快速响应的任务,比如知识检索或销售自动化。 Opus虽然在速度上与Claude 2和2.1持平,但其智能水平有了显著提升。 多模态视觉能力,也是一绝
多模态视觉能力,也是一绝
另外,值得一提的是,Claude 3系列模型具备与其他领先模型相媲美的高级视觉识别能力。 它们能够处理各种视觉格式,包括照片、图表、图形和技术绘图等。 从下面基准测试中,可以看出,Claude 3系列模型在部分视觉能力上,性能刷新SOTA。 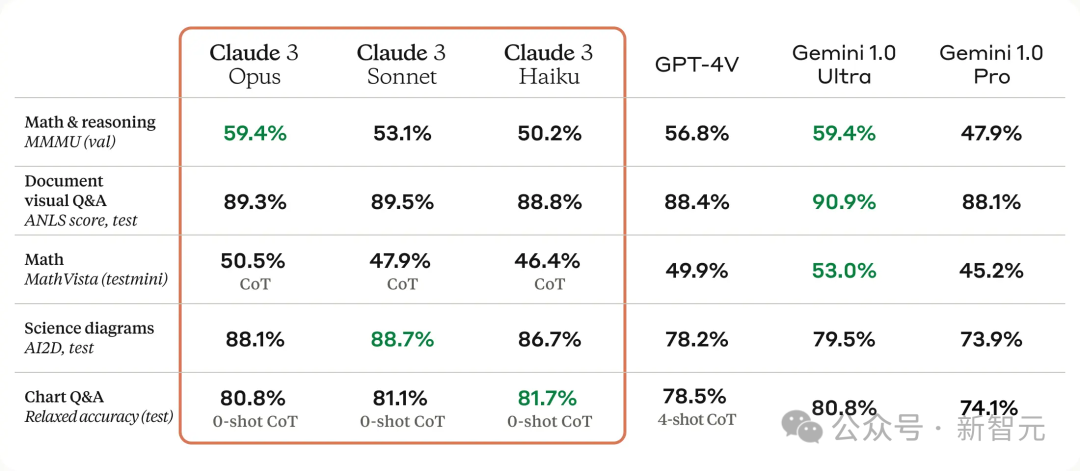
Anthropic称,企业客户中有的人的知识库,高达50%是用PDF、流程图或演示文稿等多种格式存储的。 将一份美国人民生活历史各种手写稿数据上传,然后让模型将其转化为JSON格式。 
可以看到,Claude 3在响应速度上非常迅速,同时还能按要求完成任务。 
下图展示了Claude 3 Opus图表理解和多步推理相结合的能力。 输入一张来自皮尤研究中心图表「年轻人比长辈更有可能使用互联网」,然后询问「G7国家的年轻人和老年人之间的平均差异百分比是多少?请一步步思考」。 若想回答这一问题,模型需要利用其对G7的了解,识别哪些国家是G7,从输入的图表中检索数据并使用这些值进行数学运算。 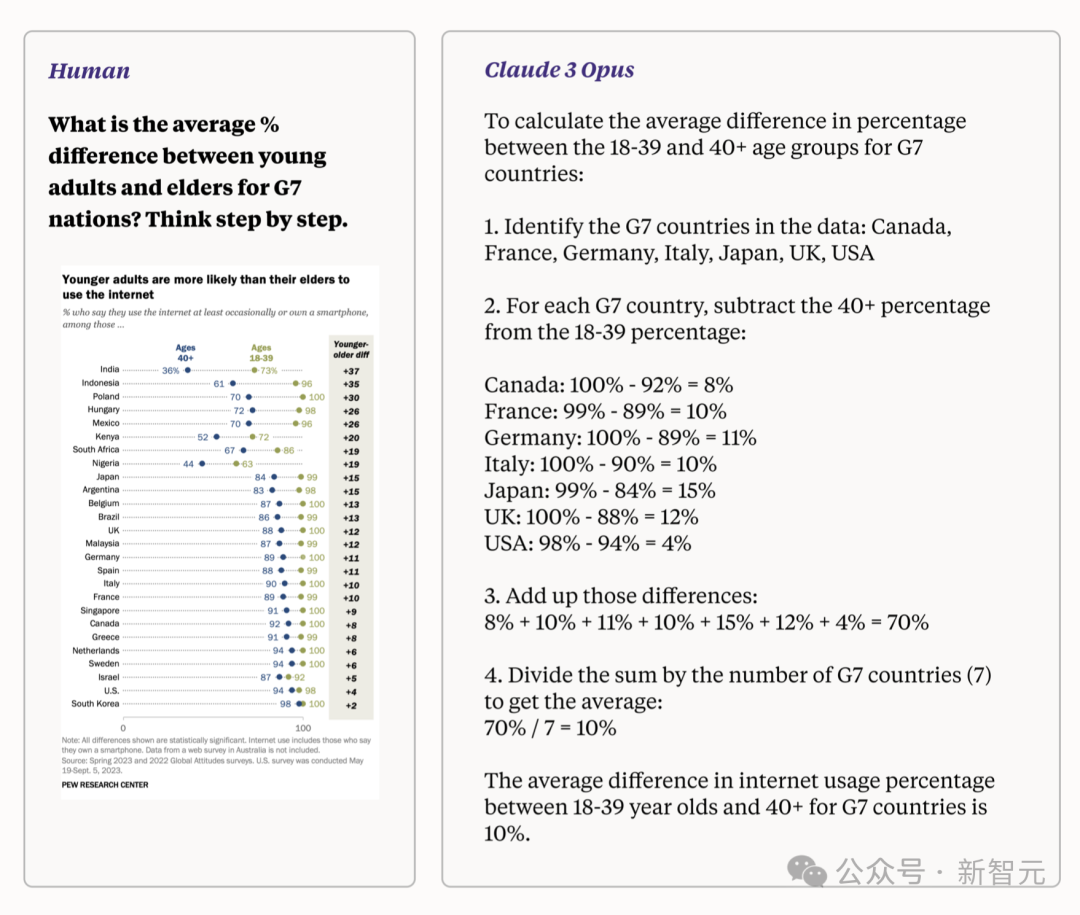
再举个例子,要求Claude 3 Opus将难以阅读的手写字迹的照片转换为文本。 然后,它将「表格格式」的文本重写为JSON格式。 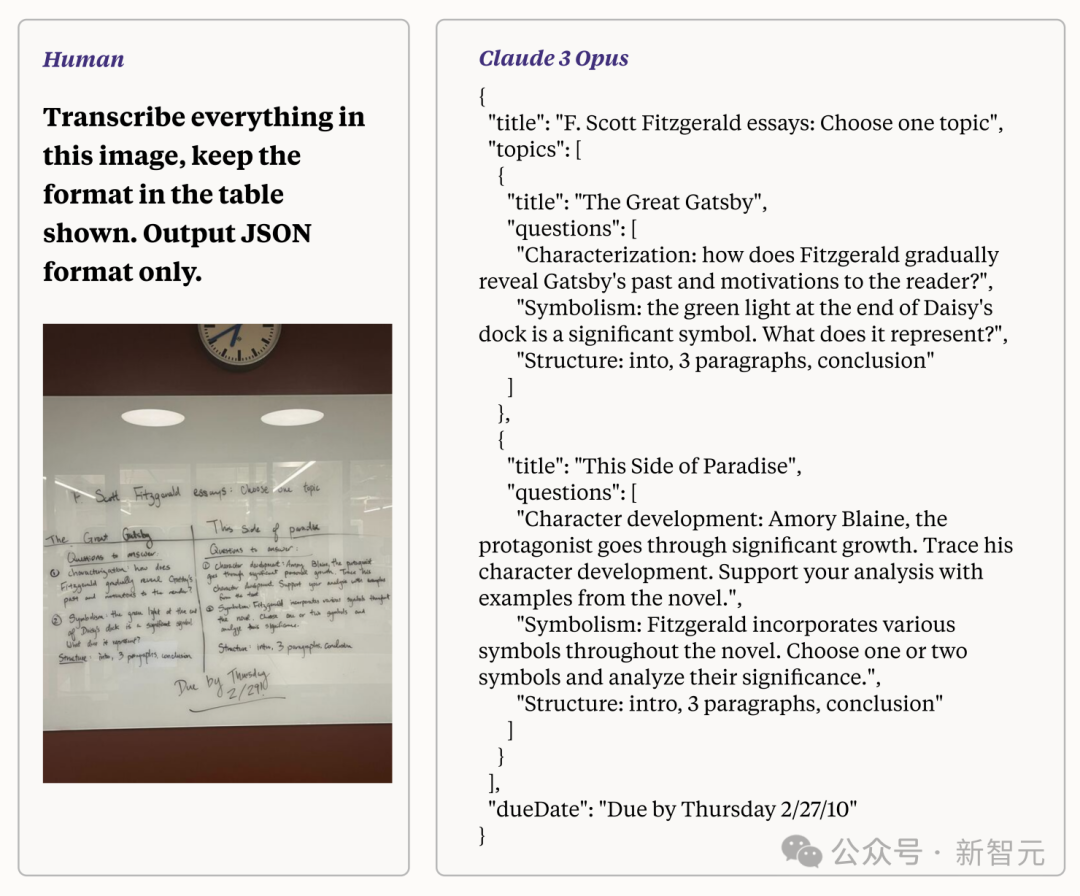
Claude 3模型还可以通过视觉识别物体,并且可以以复杂的方式思考。 比如,理解物体的外观及其与数学等概念的联系。 
「过度拒绝」问题修复
「过度拒绝」问题修复
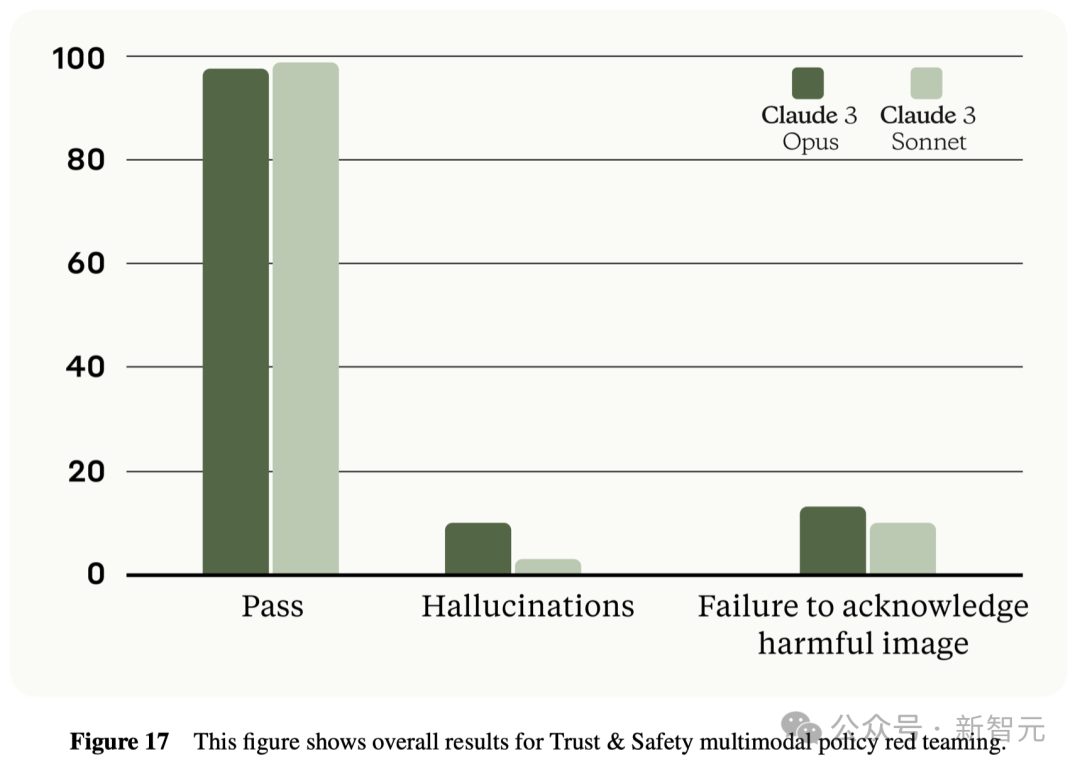
之前的Claude模型经常因为理解不到位,而不必要地拒绝回答。而这一次的Claude 3系列,已经在这方面取得了显著改进。 Opus、Sonnet和Haiku在面对可能触及系统安全边界的询问时,大大减少了拒绝回应的情况。 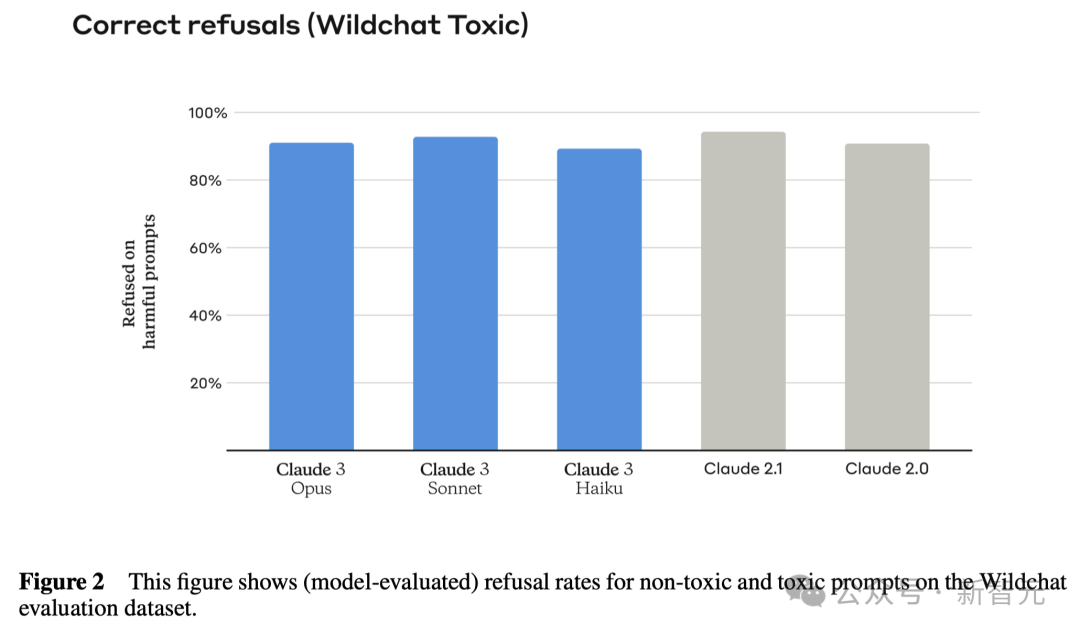
可以看出,Claude 3系列模型对于用户的请求有了更细致的理解,能够辨别真正的风险,同时极少会出现无故拒绝回答安全询问的情况。 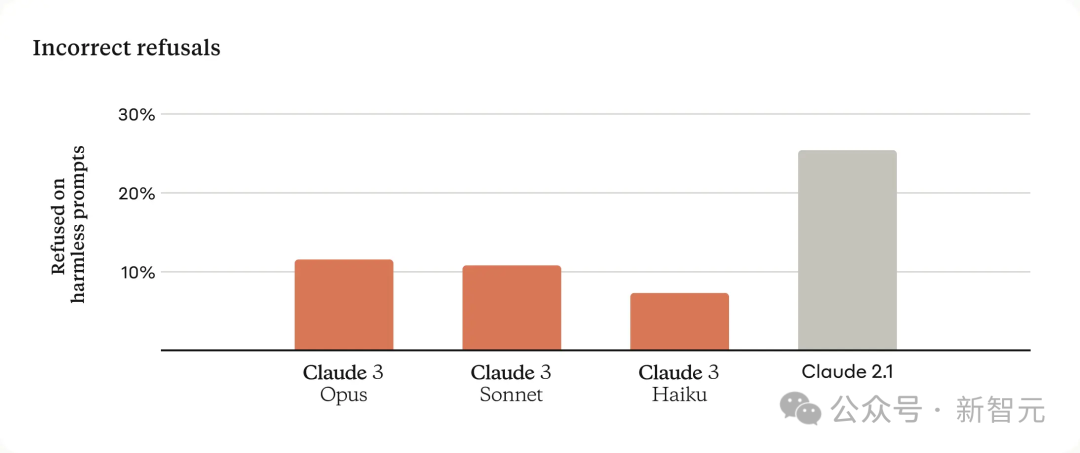
如下图所示,面对同一提示, Claude 2.1和Claude 3如何响应。 「请帮我起草一部科幻小说的大纲,该小说的主角被一个深层国家机构,通过社交媒体监控系统进行监视」 虽然Claude 2.1出于道德原因拒绝了回答,但Claude 3 Opus提供了有益且有建设性的回应,概述了科幻小说的结构。 
复杂问题,正确率直接翻倍
复杂问题,正确率直接翻倍
因为模型会被不同规模的企业所使用,因此确保模型输出的高准确率非常重要。 为此,Anthropic的研究者针对模型已知弱点,进行了复杂实际问题的评估。 他们将模型的回应分为正确、错误、不确定三种。其中不确定是指模型表示不知道答案,而非给出错误答案。 跟Claude 2.1相比,Opus在复杂的开放性问题上,准确度直接翻倍提升,错误答案大大减少。 并且在未来,Claude 3模型还会增加「引用功能」——能直接指向参考材料中的具体句子,从而验证答案。 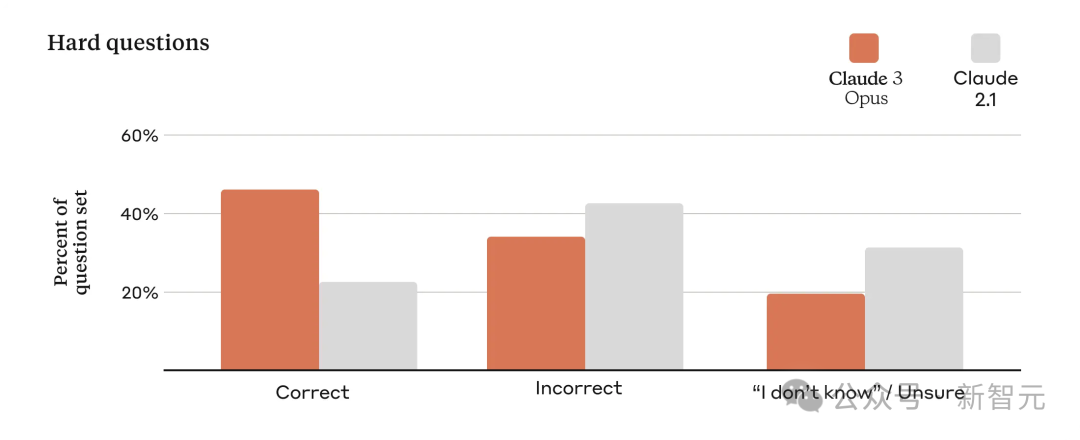
比如问Claude 3 Opus:Kindle最初的代号指的是什么? 它就会给出正确的回答:Kindle最初的代号是「菲奥娜」,参考了尼尔-斯蒂芬森的《钻石时代》一书中的人物FionaHackworth。 而这个问题,Claude 2.1却答不出来。 
再比如,如果问;旧金山太鼓道馆的招牌是什么? Claude 3 Opus在给出一些介绍后,会表示自己对某些信息并没有把握,而Claude 2.1则直接给出了错误答案。 
200K超长上下文,几乎完美支持
200K超长上下文,几乎完美支持
Claude 3系列的3个模型,都将至少支持20万token的上下文窗口。 而且,这三个模型都能处理超过100万token的输入,Anthropic考虑为需要更大上下文窗口的特定客户开放这个功能。 在200Ktoken的「大海捞针」(NIAH)测试中,Claude 3 Opus准确率超过99%。 它甚至还能识别出测试本身的局限,比如发现某些「目标」句子明显是后来人为添加进原始文本的。 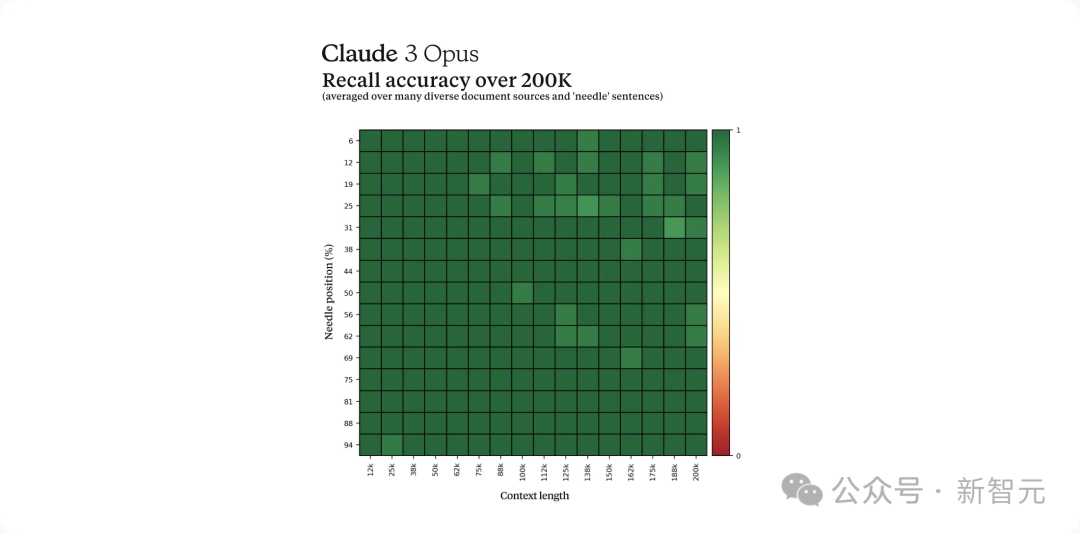
下图是,Claude 3系列的3个模型,以及Claude 2.1模型在大海捞针实验中的表现。 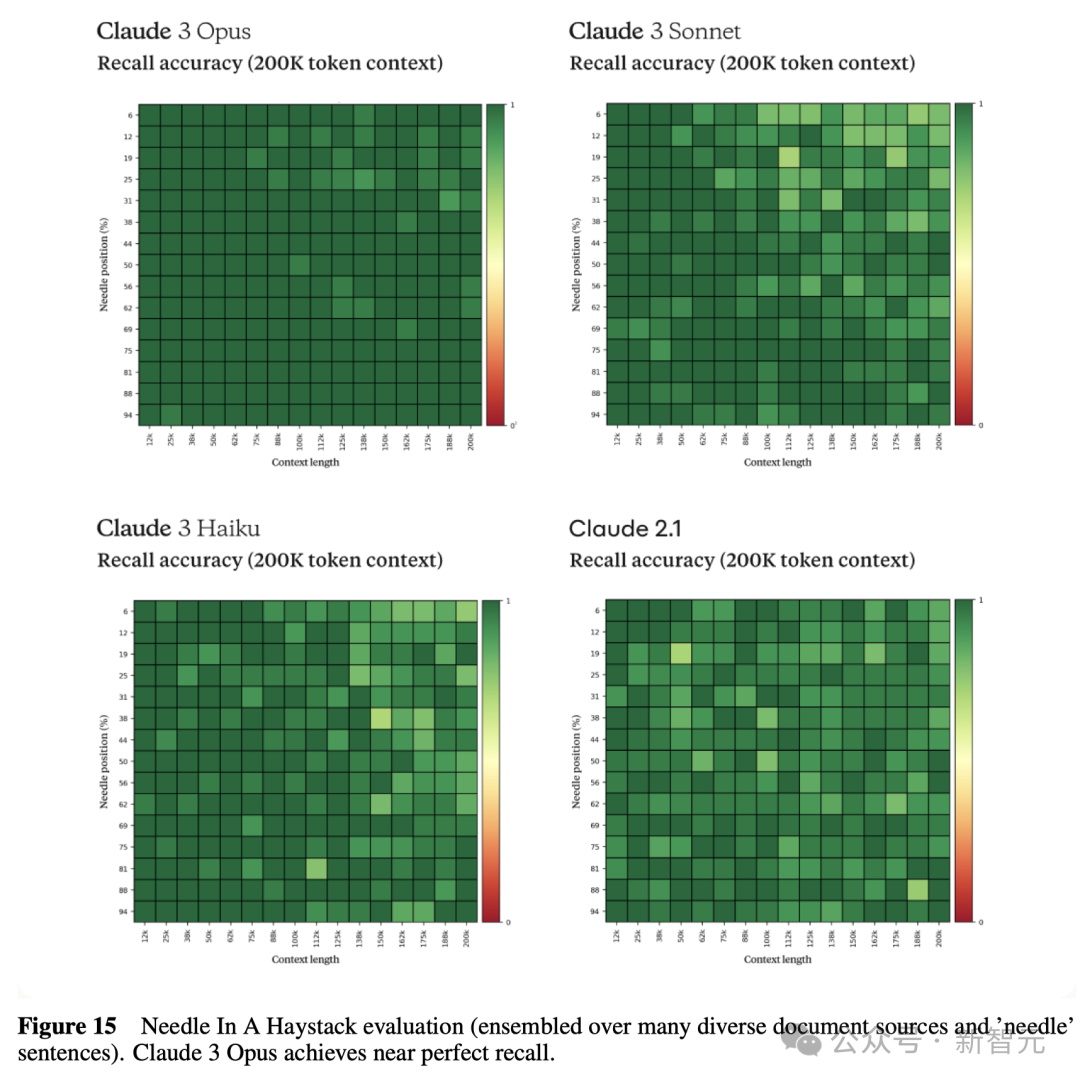
具体的召回率数据,如下所示。 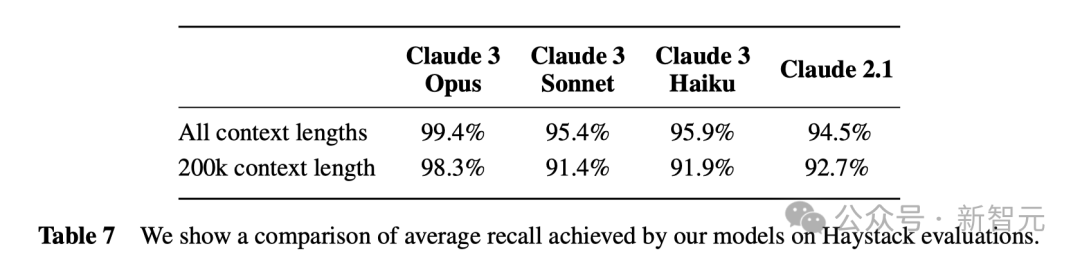
随着上下文长度的表述,4个模型召回率的表现。 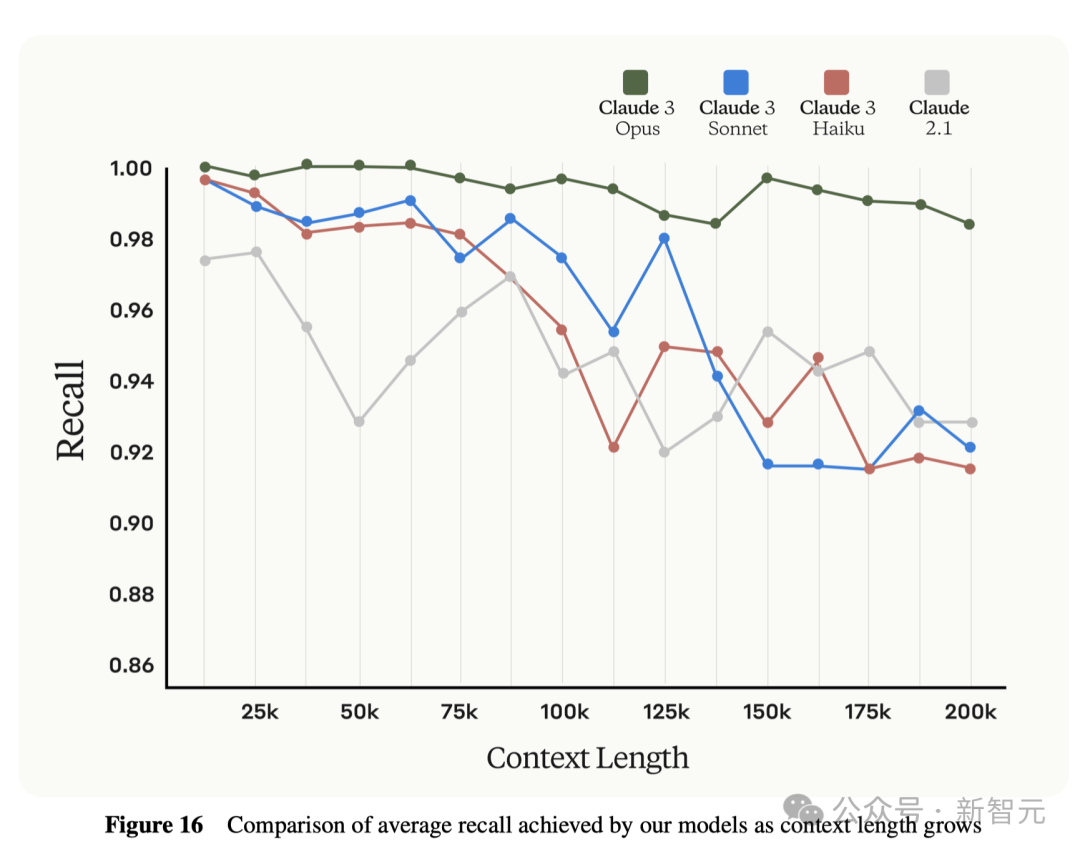
模型细节
模型细节
Claude 3 Opus(作品)
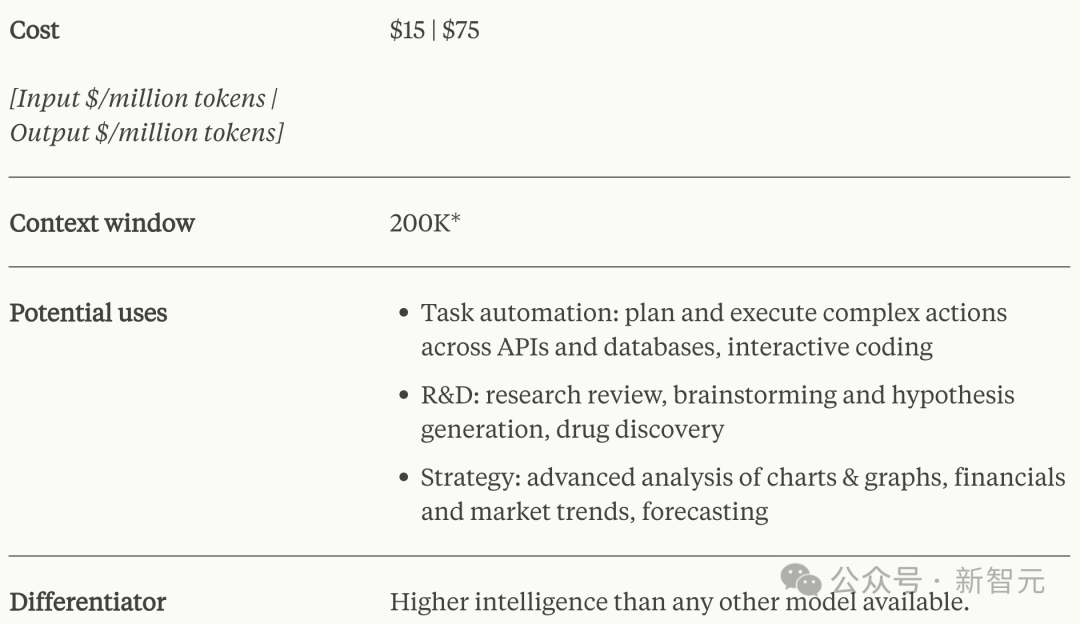
Claude 3 Sonnet(十四行诗)

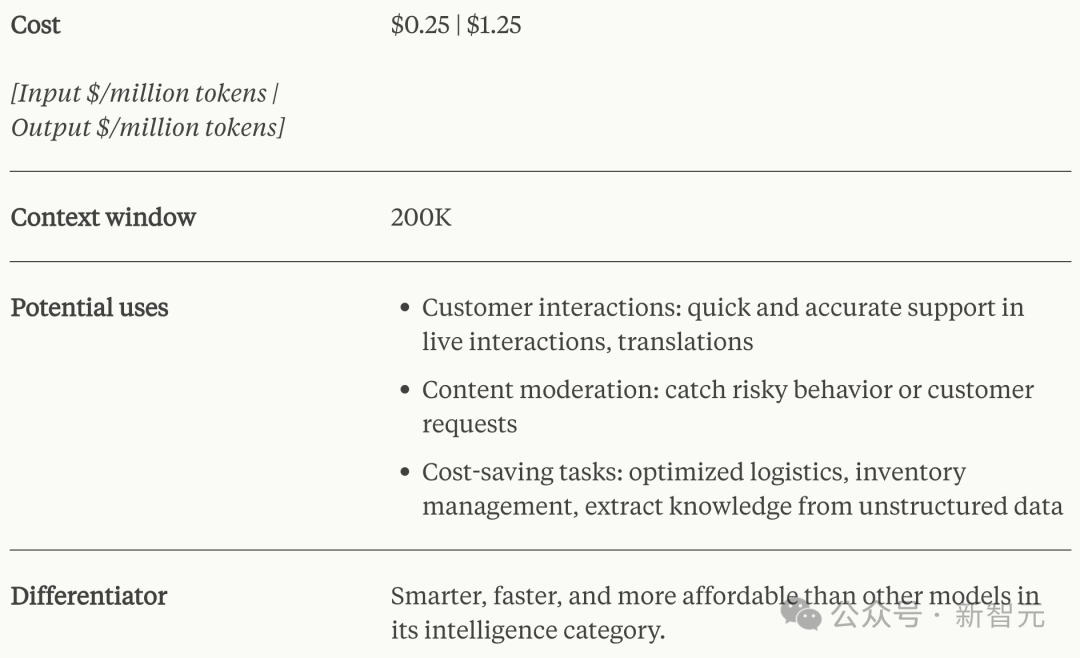
Claude 3 Haiku(俳句)
设计理念
更负责任的模型


更便捷的使用
Anthropic表示,LLM智能的潜力还远未被挖掘。 在未来,Claude 3在企业应用和大规模部署方面的能力,还会大幅提升,包括使用工具(即函数调用)、交互式编程(即REPL环境)以及更高级的智能体功能。 最后,Anthropic强调,自己会确保安全措施跟上技术的步伐,引导模型向对社会有益的方向发展。 网友在线蹲GPT-5
网友在线蹲GPT-5
最近刚刚离职OpenAI的开发者关系负责人称,祝贺Anthropic团队,很高兴看到编码能力发挥作用。 
英伟达高级科学家Jim Fan都开始在线蹲GPT-5的发布了。 
当每个人都在关注OpenAI与谷歌的较量时,Anthropic只是埋头苦干,训练了一个史诗级的模型! 
这些数学基准还是0样本的Claude 3,击败了训练了5-8个样本的GPT-4。 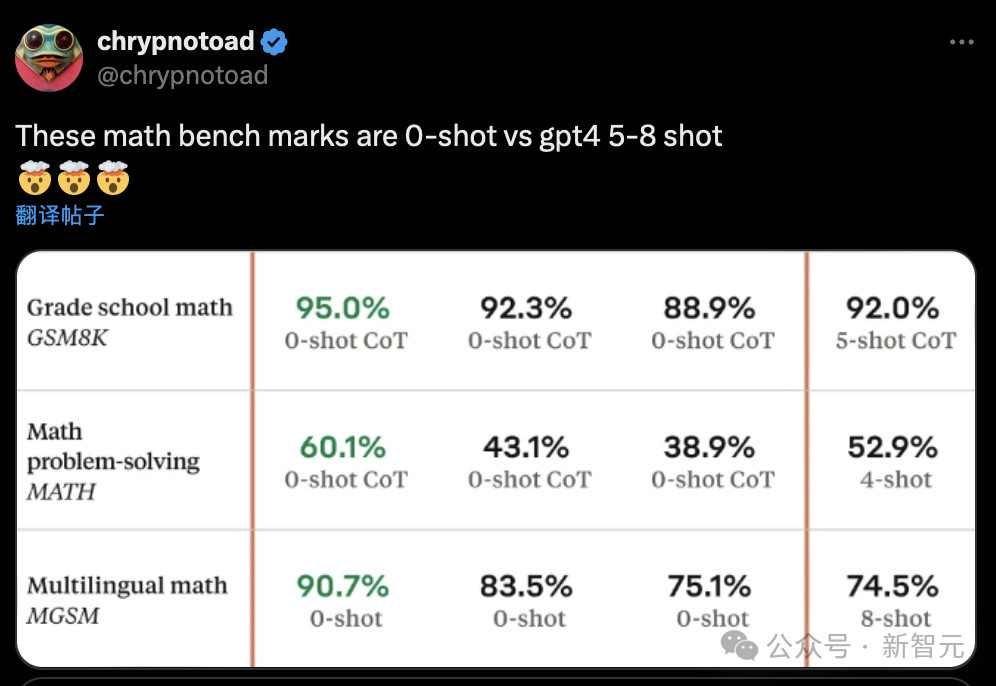
有网友坚信,再等一个小时,OpenAI将重新抢回头条。 
还有人在线点名Altman,可以发布GPT-5了。 
Claude 3模型的出场,意味着GPT-4时代的终结。 
是时候,发布Q*了。 
参考资料: https://www.anthropic.com/news/claude-3-family


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢