
近期也有一个新的综述工作:《Retrieval-Augmented Generation for AI-Generated Content: A Survey》(https://arxiv.org/abs/2402.19473),该工作对应的论文列表放在:https://github.com/hymie122/RAG-Survey
本文对该工作进行介绍,供大家一起参考,并思考,值得收藏。
一、从RAG的整体架构说起
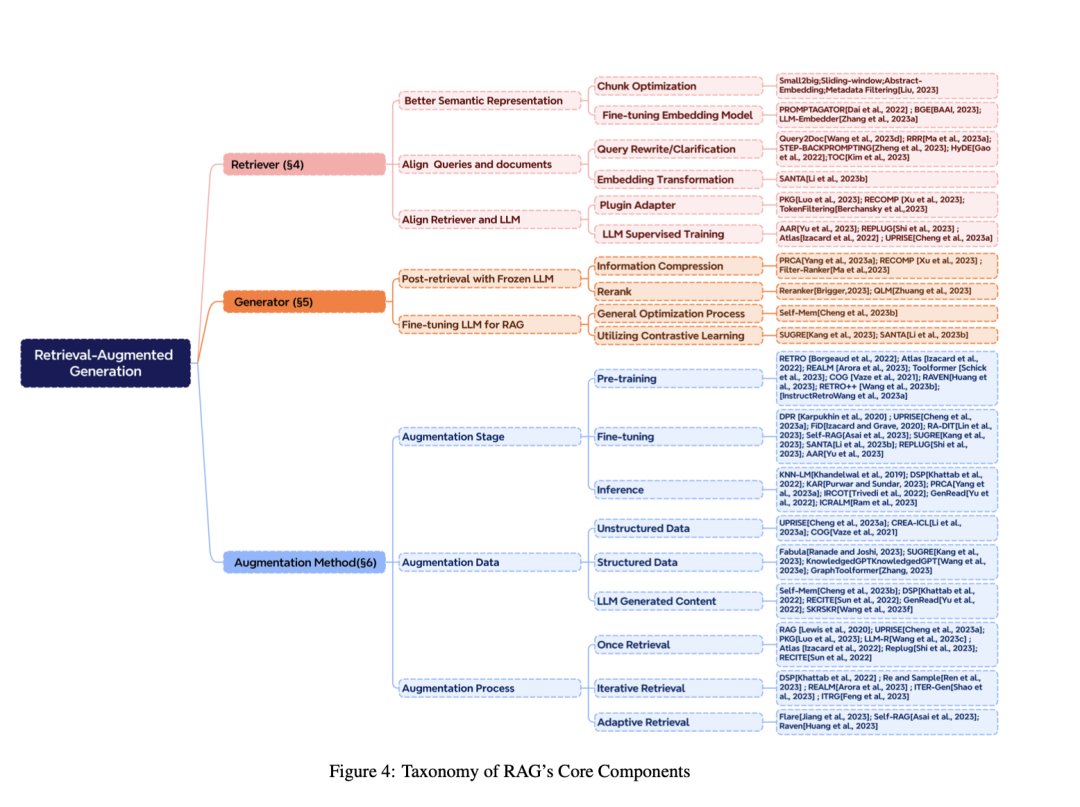
通用的RAG架构。用户的查询可能是不同模式的,是检索器和生成器的输入。检索器搜索存储中的相关数据源,而生成器则与检索结果交互,并最终生成各种模式的结果。
1、RAG基础
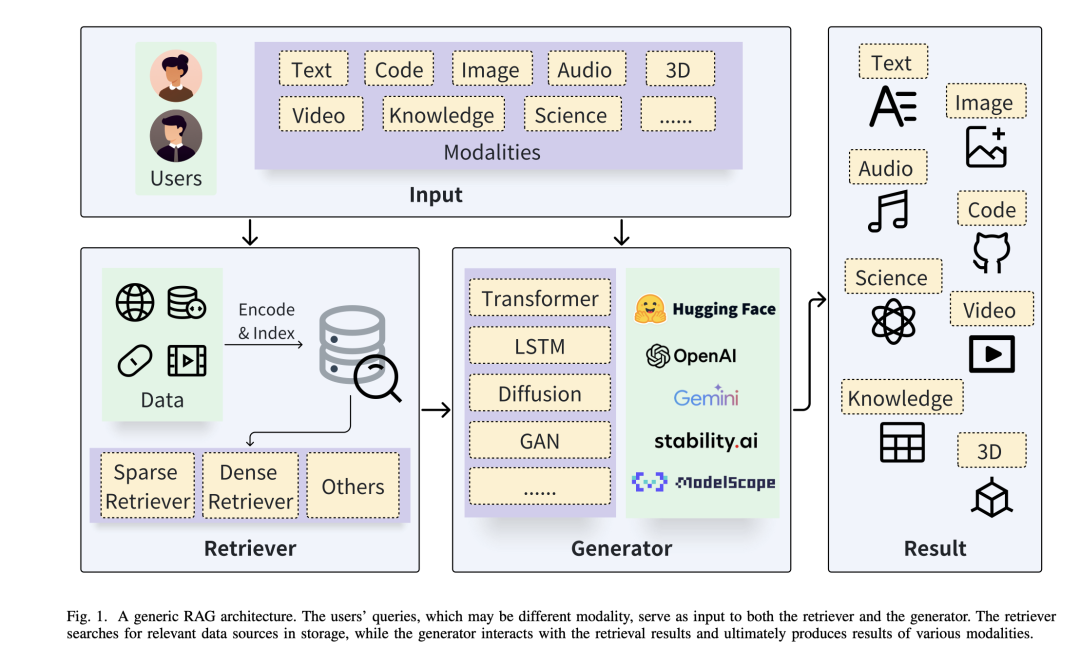
该工作将RAG分成四种类型,如下图所示:
1)Query-based RAG
基于查询的RAG也称为提示增强。它将用户的查询与检索过程中从文件中获取的信息直接整合到语言模型输入的初始阶段。这种模式是RAG应用中广泛采用的方法。一旦检索到文档,它们的内容就会与用户的原始查询合并,从而创建一个组合输入序列。这一增强序列随后被输入到预先训练好的语言模型中,以生成回复。
2)Latent Representation-based RAG
在基于潜在表征的RAG框架中,生成模型与检索对象的潜在表征相互作用,从而提高模型的理解能力和生成内容的质量。
3)Logit-based RAG
在基于对数的RAG中,生成模型在解码过程中通过对数将检索信息结合起来。通常情况下,对数通过模型求和或组合,以产生逐步生成的概率。
4)Speculative RAG
投机性RAG寻找使用检索代替生成的机会,以节省资源和加快响应速度。例如,REST用检索取代了推测解码中的小模型,从而生成草稿。GPTCache尝试通过建立语义缓存来存储LLM响应,从而解决使用LLMAPI时的高延迟问题。
二、RAG的评估方案
当前RAG评估也是一个主要话题,包括CRUD-RAG、ARES、RAGAS等多个
1、Benchmarking Large Language Models in Retrieval-Augmented Generation
地址:https://doi.org/10.48550/arXiv.2309.01431)
2、CRUD-RAG: A Comprehensive Chinese Benchmark for Retrieval-Augmented Generation of Large Language Models
地址:https://doi.org/10.48550/arXiv.2401.17043
3、ARES: An Automated Evaluation Framework for Retrieval-AugmentedGeneration Systems
地址:https://doi.org/10.48550/arXiv.2311.09476
4、RAGAS: Automated Evaluation of Retrieval Augmented Generation
地址:https://doi.org/10.48550/arXiv.2309.15217
三、RAG增强的多阶段方案
该工作将RAG增强分成多种类型,包括Input Enhancement、Retriever Enhancement、Generator Enhancement、Result Enhancement以及RAG Pipeline Enhancement共5种,如下图所示:
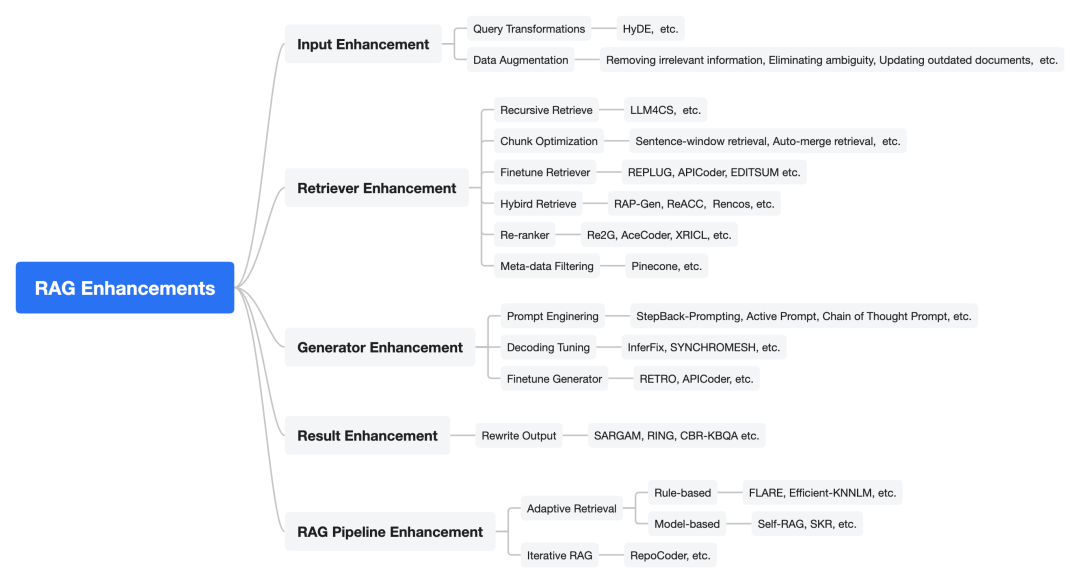
其中:
1、Input Enhancement输入增强

输入是指用户的查询,它最初被馈送到检索器中。输入的质量显著影响检索阶段的最终结果。因此,增强输入变得至关重要。主要包括查询转换和数据增强两种。
1)Query Transformation查询转换
查询转换可以通过修改输入查询来增强检索结果。Query2doc和HyDE首先使用query生成伪文档,然后使用该文档作为检索的键。这样做的好处是,伪文档将包含更丰富的相关信息,这有助于检索更准确的结果。
2)Data Augmentation数据增强
数据增强是指在检索前对数据进行预先完善,如去除不相关信息、消除歧义、更新等。合成新的数据等,可以有效地提高最终RAG系统的性能。MakeAnAudio使用字幕和音频-文本检索为无语言音频生成字幕以减轻数据稀疏性,并添加随机概念音频以改进原始音频。
2、Retriever Enhancement检索增强

在RAG系统中,检索过程至关重要。一般来说,内容质量越好,就越容易激发大模型的情境学习能力,以及其他生成器和范式。内容质量越差,越容易引起模型幻觉。因此,其核心在于如何有效地提高检索过程的有效性。
1)递归检索Recursive Retrieve
递归检索是在检索之前对查询进行拆分,并执行多次搜索以检索更多更高质量的内容的过程,例如,使用思维链(Chain-of-Thought,COT)使模型能够逐步分解查询,提供更丰富的相关知识。
LLMCS将该技术应用于会话系统,通过重写会话记录获得了更好的检索结果。
2)块优化Chunk Optimization
块优化技术是指通过调整块的大小来获得更好的检索结果。句子窗口检索是一种有效的方法,它通过获取小块文本并返回被检索片段周围的相关句子窗口来增强检索。这种方法确保了目标句子前后的上下文都包含在内,从而对检索到的信息有了更全面的理解。
自动合并检索是LlamaIndex的另一种高级RAG方法,它以树状结构组织文档,父节点包含所有子节点的内容。例如,文章和段落,以及段落和句子,都遵循亲子关系。在检索过程中,对子节点的细粒度搜索最终返回父节点,从而有效地提供更丰富的信息。
3)微调向量嵌入模型Finetune Retriever
作为RAG系统的核心部件,寻回器在整个系统运行过程中起着至关重要的作用。一个好的嵌入模型可以使语义相似的内容在向量空间中更加紧密。召回能力越强,为后续发生器提供的有用信息就越多,从而提高RAG系统的有效性。因此,嵌入模型的能力对RAG系统的整体有效性至关重要。
此外,对于已经具有良好表达能力的嵌入模型,我们仍然可以使用高质量的领域数据或任务相关数据对其进行微调,以提高其在特定领域或任务中的性能。REPLUG将LM视为黑盒,根据最终结果更新检索器模型。例如:
APICoder使用python文件和api名称、签名、描述对检索器进行微调。EDITSUM对检索器进行微调,以减少检索后摘要之间的夹板距离。
SYNCHROMESH在损失中添加ast的树距离,并使用目标相似度调优来微调检索器。R-ConvED使用与生成器相同的数据对检索器进行微调。
4)混合检索Hybrid Retrieve
混合检索是指同时使用多种类型的检索方法。RAP-Gen和ReACC同时使用密集检索器和稀疏检索器来提高检索质量。
Ren-cos使用稀疏检索器在句法层面检索相似的代码片段,使用密集检索器在语义层面检索相似的代码片段。
BASHEXPLAINER首先使用密集检索器捕获语义信息,然后使用稀疏检索器获取词汇信息。
RetDream首先用文本检索,然后用图像嵌入检索。
5)重新排序Re-ranking
重新排序技术是指对检索到的内容重新排序,以达到更大的多样性和更好的结果。Re2G采用了继传统寻回犬之后的重新排序token模型。
重新排序模型的作用是对检索到的文档进行重新排序,其目的是为了减少将文本压缩成向量所造成的信息丢失对检索质量的影响。
AceCoder使用选择器对检索到的程序重新排序。引入选择器的目的是为了减少冗余程序,获得多样化的检索程序。
XRICL在检索后使用基于蒸馏的范例重新排序器。
6)元数据过滤Meta-data Filtering
元数据过滤是另一种帮助处理检索到的文档的方法,它使用元数据(如时间、目的等)过滤检索到的文档,以获得更好的结果。
2、生成器增强Generator Enhancement

在RAG系统中,生成器的质量往往决定了最终输出结果的质量。因此,该模块的能力决定了整个RAG系统效能的上限。
其增强可以从以下方面进行:
1)提示工程 Prompt Engineering
提示工程(Prompt Engineering)中的技术侧重于提高LLM输出的质量,如Promptcompression、StepbackPrompt、ActivePrompt、Chain of Thought Prompt等,这些技术都适用于RAG系统中的LLM生成器。
其中:
LLM-Lingua采用小模型压缩查询的总长度来加速模型推理,缓解不相关信息对模型的负面影响,缓解“迷失在中间”的现象。
ReMo Diffuse使用ChatGPT将复杂的描述分解为结构文本脚本。
ASAP将范例添加到提示符中以获得更好的结果。示例元组由输入代码、函数定义、分析该定义的结果及其相关注释组成。
CEDAR使用一个设计好的提示模板将代码演示、查询和自然语言指令组织到一个提示中。
XRICL利用COT技术添加翻译对作为跨语言语义解析和推理的中间步骤。
Make An Audio能够使用其他模态作为输入,这可以为后续过程提供更丰富的信息。
2)微调解码器 Decoding Tuning
译码调优是指在生成器处理过程中增加额外的控制,可以通过调整超参数来实现更大的多样性,以某种形式限制输出词汇表等。例如:
interfix通过调节解码器的温度来平衡结果的多样性和质量。
SYNCHROMESH通过实现补全引擎来消除实现错误,从而限制了解码器的输出词汇表。DeepICL根据一个额外的温度因素控制生成的随机性。
3)微调生成器 Finetune Generator
对生成器进行微调,可以增强模型拥有更精确的领域知识的能力,或者更好地与检索对象匹配,例如:
RETRO固定了检索器的参数,并使用生成器中的分块交叉注意机制将查询内容与检索器结合起来。
APICoder对生成器CODEGEN-MONO350M进行微调,将一个经过洗牌的新文件与API信息和代码块结合起来。
CAREt首先使用图像数据、音频数据和视频文本对对编码器进行训练,然后以减少标题损失和概念检测损失为目标对解码器(生成器)进行微调,在此过程中,编码器和检索器被冻结。
animation-a-story使用图像数据优化视频生成器,然后对LoRA适配器进行微调,以捕获给定角色的外观细节。Ret-Dream用渲染的图像微调LoRA适配器
4、结果增强Result Enhancement

在很多场景下,RAG的最终结果可能达不到预期效果,一些结果增强技术可以帮助缓解这一问题。
例如,重写输出Rewrite Output,SARGAM通过Levenshtein Transformer对删除分类器、占位分类器和插入分类器进行分类,修改代码相关任务中生成的结果,以更好地适应实际的代码上下文。
Ring通过重新排序得到多样性结,候选基于生成器生成的每个token日志概率的平均值。
CBR-KBQA通过将生成的关系与知识图中查询实体的局部邻域中的关系对齐来修正结果。
5、RAG流程增强RAG Pipeline Enhancemen

1)自适应检索 Adaptive Retrieval
实际经验表明,检索并不总是有利于最终生成的结果,当模型本身的参数化知识足以回答相关问题时,过度检索会造成资源浪费,并可能增加模型的混乱。因此,在本章中,我们将讨论确定是否检索的两种方法,即基于规则的方法和基于模型的方法。
基于规则Rule-based,例如:FLARE在生成过程中通过概率主动决定是否搜索以及何时搜索。efficiency-knnlm将KNN-LM和NPM的生成概率与超参数λ相结合,以确定生成和检索的比例。malen等在生成答案前对问题进行统计分析,允许模型直接回答高频问题,对低频问题引入RAG。
又如,Jiang等研究了模型不确定性(Model Uncertainty)、输入不确定性(Input Uncertainty)和输入统计量(Input Statistics),综合评估了模型的置信水平。最后,基于模型的置信度,决定是否检索。
Kandpal等人通过研究训练数据集中相关文档的数量与模型掌握相关知识的程度之间的关系,帮助确定是否需要检索。
基于模型的Model-based,例如,Self-rag使用经过训练的生成器根据不同指令下的检索确定是否执行检索,并通过Self-Reflection评估检索文本的相关性和支持程度。最后,最终输出结果的质量基于批判进行评估。
Ren等人使用“判断提示”来判断大模型是否能够回答相关问题,以及他们的答案是否正确,从而帮助确定检索的必要性。
SKR利用llm自身提前判断是否能回答问题的能力,如果能回答,则不进行检索。
2)迭代RAG
RepoCoder采用迭代检索生成管道,更好地利用代码完成任务中分散在不同文件中的有用信息。它在第i次迭代期间使用先前生成的代码增强检索查询,并获得更好的结果。
ITER-RETGEN以迭代的方式协同检索和生成,生成器当前的输出可以在一定程度上反映出它还缺乏的知识,检索器可以检索缺失的信息作为下一轮的上下文信息,这有助于提高下一轮生成内容的质量。
3、RAG的应用
如下图所示,该工作将RAG的应用分成面向不同模态的检索增强
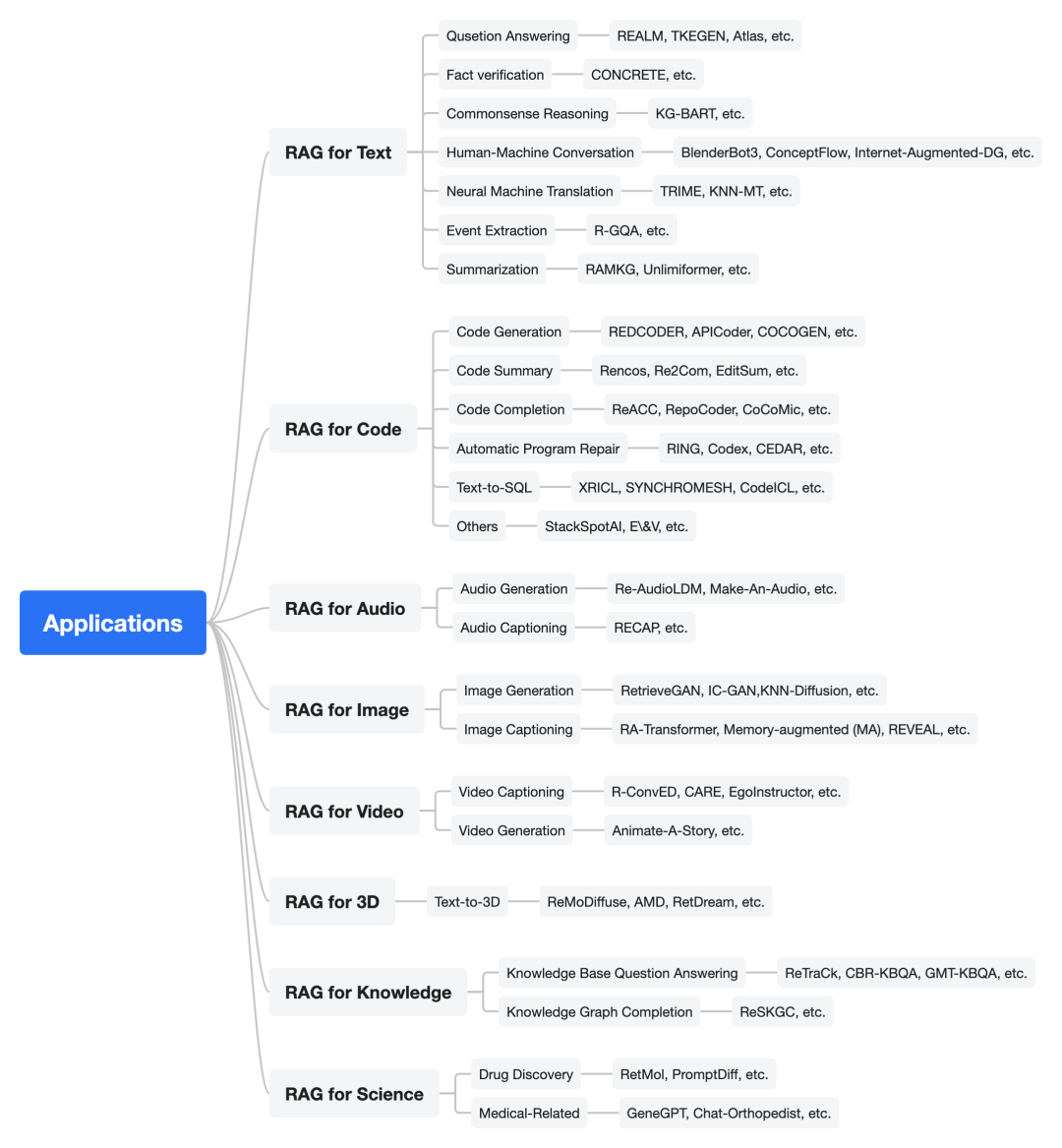
四、面向文本模态的RAG应用
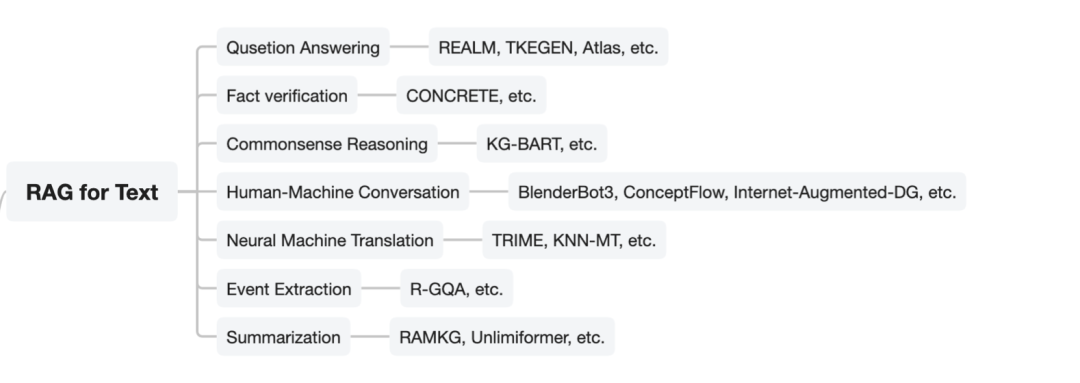
1、Qusetion Answering问答
1)Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
地址:https://doi.org/10.18653/v1/2021.eacl-main.74
2)REALM: Retrieval-Augmented Language Model Pre-Training
地址:https://arxiv.org/abs/2002.08909
3)Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training
地址:https://doi.org/10.18653/v1/2021.naacl-main.278
4)Atlas: Few-shot Learning with Retrieval Augmented Language Models
地址:http://jmlr.org/papers/v24/23-0037.html
5)Improving Language Models by Retrieving from Trillions of Tokens
地址:https://proceedings.mlr.press/v162/borgeaud22a.html
6)Self-Knowledge Guided Retrieval Augmentation for Large Language Models
地址:https://aclanthology.org/2023.findings-emnlp.691
7)Knowledge-Augmented Language Model Prompting for Zero-Shot Knowledge Graph Question Answering
地址:https://doi.org/10.48550/arXiv.2306.04136
8)Think-on-Graph: Deep and Responsible Reasoning of Large Language Model with Knowledge Graph
地址:https://doi.org/10.48550/arXiv.2307.07697
9)Nonparametric Masked Language Modeling
地址:https://doi.org/10.18653/v1/2023.findings-acl.132
10)CL-ReLKT: Cross-lingual Language Knowledge Transfer for Multilingual Retrieval Question Answering
地址:https://doi.org/10.18653/v1/2022.findings-naacl.165
11)One Question Answering Model for Many Languages with Cross-lingual Dense Passage Retrieval
地址:https://proceedings.neurips.cc/paper/2021/hash/3df07fdae1ab273a967aaa1d355b8bb6-Abstract.html
12)Entities as Experts: Sparse Memory Access with Entity Supervision
地址:https://arxiv.org/abs/2004.07202
13)When to Read Documents or QA History: On Unified and Selective Open-domain QA
地址:https://doi.org/10.18653/v1/2023.findings-acl.401
2、Fact verification事实校验
CONCRETE: Improving Cross-lingual Fact-checking with Cross-lingual Retrieval
地址:https://aclanthology.org/2022.coling-1.86
3、Commonsense Reasoning常识推理
KG-BART: Knowledge Graph-Augmented {BART} for Generative Commonsense Reasoning
地址:https://doi.org/10.1609/aaai.v35i7.16796
4、Human-Machine Conversation人机对话
1)Grounded Conversation Generation as Guided Traverses in Commonsense Knowledge Graphs
地址:https://doi.org/10.18653/v1/2020.acl-main.184
2)Skeleton-to-Response: Dialogue Generation Guided by Retrieval Memory
地址:https://doi.org/10.18653/v1/n19-1124
3)Internet-Augmented Dialogue Generation
地址:https://doi.org/10.18653/v1/2022.acl-long.579
4)BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage
地址:https://doi.org/10.48550/arXiv.2208.03188
5)A Model of Cross-Lingual Knowledge-Grounded Response Generation for Open-Domain Dialogue Systems
地址:https://doi.org/10.18653/v1/2021.findings-emnlp.33
5、Neural Machine Translation机器翻译
1)Neural Machine Translation with Monolingual Translation Memory
地址:https://doi.org/10.18653/v1/2021.acl-long.567
2)Nearest Neighbor Machine Translation
地址:https://openreview.net/forum?id=7wCBOfJ8hJM)
Training Language Models with Memory Augmentation
地址:https://doi.org/10.18653/v1/2022.emnlp-main.382)
6、Event Extraction事件抽取
Retrieval-Augmented Generative Question Answering for Event Argument Extraction
地址:https://doi.org/10.18653/v1/2022.emnlp-main.307
7、Summarization文本摘要
1)Retrieval-Augmented Multilingual Keyphrase Generation with Retriever-Generator Iterative Training
地址:https://doi.org/10.18653/v1/2022.findings-naacl.92
2)Unlimiformer: Long-Range Transformers with Unlimited Length Input
地址:https://doi.org/10.48550/arXiv.2305.01625)
五、RAG用于Code代码领域

1、Code Generation代码生成
1)Retrieval Augmented Code Generation and Summarization
地址:https://doi.org/10.18653/v1/2021.findings-emnlp.232
2)When Language Model Meets Private Library
地址:https://doi.org/10.18653/v1/2022.findings-emnlp.21
3)DocPrompting: Generating Code by Retrieving the Docs
地址:https://openreview.net/pdf?id=ZTCxT2t2Ru)
4)CodeT5+: Open Code Large Language Models for Code Understanding and Generation
地址:https://aclanthology.org/2023.emnlp-main.68)
5)AceCoder: Utilizing Existing Code to Enhance Code Generation
地址:https://arxiv.org/abs/2303.17780)
6)The impact of lexical and grammatical processing on generating code from natural language
地址:https://doi.org/10.18653/v1/2022.findings-acl.173)
2、Code Summary代码摘要
1)Retrieval-based neural source code summarization
地址:https://doi.org/10.1145/3377811.3380383
2)Retrieve and Refine: Exemplar-based Neural Comment Generation
地址:https://doi.org/10.1145/3324884.3416578
3)RACE: Retrieval-augmented Commit Message Generation
地址:https://doi.org/10.18653/v1/2022.emnlp-main.372
4)BashExplainer: Retrieval-Augmented Bash Code Comment Generation based on Fine-tuned CodeBERT
地址:https://doi.org/10.1109/ICSME55016.2022.00016
3、Code Completion代码补全
1)ReACC: A Retrieval-Augmented Code Completion Framework
地址:https://doi.org/10.18653/v1/2022.acl-long.431)
2)RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation
地址:https://aclanthology.org/2023.emnlp-main.151)
3)CoCoMIC: Code Completion By Jointly Modeling In-file and Cross-file Context
地址:https://doi.org/10.48550/arXiv.2212.10007)
4、Automatic Program Repair自动程序修复
1)Repair Is Nearly Generation: Multilingual Program Repair with LLMs
地址:https://doi.org/10.1609/aaai.v37i4.25642)
2)Retrieval-Based Prompt Selection for Code-Related Few-Shot Learning
地址:https://doi.org/10.1109/ICSE48619.2023.00205)
3)InferFix: End-to-End Program Repair with LLMs
地址:https://doi.org/10.1145/3611643.3613892
5、Text-to-SQL and Code-based Semantic Parsing
1)XRICL: Cross-lingual Retrieval-Augmented In-Context Learning for Cross-lingual Text-to-SQL Semantic Parsing
地址:https://doi.org/10.18653/v1/2022.findings-emnlp.384
2)Synchromesh: Reliable Code Generation from Pre-trained Language Models
地址:https://openreview.net/forum?id=KmtVD97J43e
3)Leveraging Code to Improve In-context Learning for Semantic Parsing
地址:https://arxiv.org/abs/2311.09519
4)Leveraging training data in few-shot prompting for numerical reasoning
地址:https://arxiv.org/abs/2305.18170
六、面向Audio音频处理的RAG应用

1、Audio Generation音频生成
1)Retrieval-Augmented Text-to-Audio Generation
地址:https://doi.org/10.48550/arXiv.2309.08051
2)Large-Scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation
地址:https://doi.org/10.1109/ICASSP49357.2023.10095969
3)Large-Scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation
地址:https://doi.org/10.1109/ICASSP49357.2023.10095969
2、Audio Captioning音频字幕生成
1)RECAP: Retrieval-Augmented Audio Captioning
地址:https://doi.org/10.48550/arXiv.2309.09836
2)Large-Scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation
地址:https://doi.org/10.1109/ICASSP49357.2023.10095969
3)CNN architectures for large-scale audio classification
地址:https://doi.org/10.1109/ICASSP.2017.7952132)
七、面向Image图像模态的RAG应用

1、Image Generation图像生成
1)Retrievegan: Image synthesis via differentiable patch retrieval
地址:https://arxiv.org/abs/2007.08513
2)Instance-conditioned gan
地址:https://arxiv.org/abs/2109.05070
3)Memory-driven text-to-image generation
地址:https://arxiv.org/abs/2208.07022
4)RE-IMAGEN: RETRIEVAL-AUGMENTED TEXT-TO-IMAGE GENERATOR
地址:https://arxiv.org/abs/2209.14491
5)KNN-Diffusion: Image Generation via Large-Scale Retrieval
地址:https://arxiv.org/abs/2204.02849
6)Retrieval-Augmented Diffusion Models
地址:https://arxiv.org/abs/2204.11824
7)Text-Guided Synthesis of Artistic Images with Retrieval-Augmented Diffusion Models
地址:https://arxiv.org/abs/2207.13038
8)X&Fuse: Fusing Visual Information in Text-to-Image Generation
地址:https://arxiv.org/abs/2303.01000
2、Image Captioning图像字幕生成
1)Memory-augmented image captioning
地址:https://ojs.aaai.org/index.php/AAAI/article/view/16220
2)Retrieval-enhanced adversarial training with dynamic memory-augmented attention for image paragraph captioning
地址:https://www.sciencedirect.com/science/article/pii/S0950705120308595
3)Retrieval-Augmented Transformer for Image Captioning
地址:https://arxiv.org/abs/2207.13162
4)Retrieval-augmented image captioning
地址:https://arxiv.org/abs/2302.08268
5)Reveal: Retrieval-augmented visual-language pre-training with multi-source multimodal knowledge memory
地址:https://arxiv.org/abs/2212.05221
6)SmallCap: Lightweight Image Captioning Prompted With Retrieval Augmentation
地址:https://arxiv.org/abs/2209.15323
7)Cross-Modal Retrieval and Semantic Refinement for Remote Sensing Image Captioning
地址:https://www.mdpi.com/2072-4292/16/1/196
八、面向Video视频模态的RAG

1、Video Captioning
Retrieval Augmented Convolutional Encoder-decoder Networks for Video Captioning
地址:https://doi.org/10.1145/3539225
2、Concept-Aware Video Captioning: Describing Videos With Effective Prior Information
地址:https://doi.org/10.1109/TIP.2023.3307969
3、Video Generation视频生成
1)Animate-A-Story: Storytelling with Retrieval-Augmented Video Generation
地址:https://doi.org/10.48550/arXiv.2307.06940
2)Frozen in Time: {A} Joint Video and Image Encoder for End-to-End Retrieval
地址:https://doi.org/10.1109/ICCV48922.2021.00175
九、面向3D创作的的RAG

1、ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model
地址:https://doi.org/10.1109/ICCV51070.2023.00040
2、AMD: Anatomical Motion Diffusion with Interpretable Motion Decomposition and Fusion
地址:https://arxiv.org/abs/2312.12763
3、Retrieval-Augmented Score Distillation for Text-to-3D Generation
地址:https://doi.org/10.48550/arXiv.2402.02972
十、面向知识领域的RAG

1、Knowledge Base Question Answering知识库问答
1)ReTraCk: A Flexible and Efficient Framework for Knowledge Base Question Answering
地址:https://doi.org/10.18653/v1/2021.acl-demo.39
2)Case-based Reasoning for Natural Language Queries over Knowledge Bases
地址:https://doi.org/10.18653/v1/2021.emnlp-main.755
3)Logical Form Generation via Multi-task Learning for Complex Question Answering over Knowledge Bases
地址:https://aclanthology.org/2022.coling-1.145
2、Knowledge Graph Completion知识图谱补全
Retrieval-Enhanced Generative Model for Large-Scale Knowledge Graph Completion
地址:https://doi.org/10.1145/3539618.3592052
十一、面向科学领域的RAG

1、Drug Discovery药物发现
1)Retrieval-based controllable molecule generation
地址:https://arxiv.org/abs/2208.11126
2)Prompt-based 3d molecular diffusion models for structure-based drug design
地址:https://openreview.net/forum?id=FWsGuAFn3n
3)A protein-ligand interaction- focused 3d molecular generative framework for generalizable structure- based drug design
地址:https://chemrxiv.org/engage/chemrxiv/article-details/6482d9dbbe16ad5c57af1937
2、Medical Applications医学应用
Genegpt: Augmenting large language models with domain tools for improved access to biomedical information
地址:https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10153281
2)Retrieval-augmented large language models for adolescent idiopathic scoliosis patients in shared decision-making
地址:https://dl.acm.org/doi/abs/10.1145/3584371.3612956
总结
本文主要介绍了《Retrieval-Augmented Generation for AI-Generated Content: A Survey》(https://arxiv.org/abs/2402.19473)这一工作,该工作所归纳的增强方案以及给出的论文引导很具有参考价值,感兴趣的可以根据自己的需求进行选择性阅读,会更有收获。
感谢该工作的辛苦整理,以及数据资源整理的辛苦工作,很不容易且很有意义。
参考文献
1、Retrieval-Augmented Generation for AI-Generated Content: A Survey,https://arxiv.org/pdf/2402.18041
关于作者
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢