

新智元报道
新智元报道
【新智元导读】GPT-5「如来」,网上的小道消息已经传得漫天飞。然而,无论是GPT-4.5还是GPT-5,实际上未必适用于所有场景。
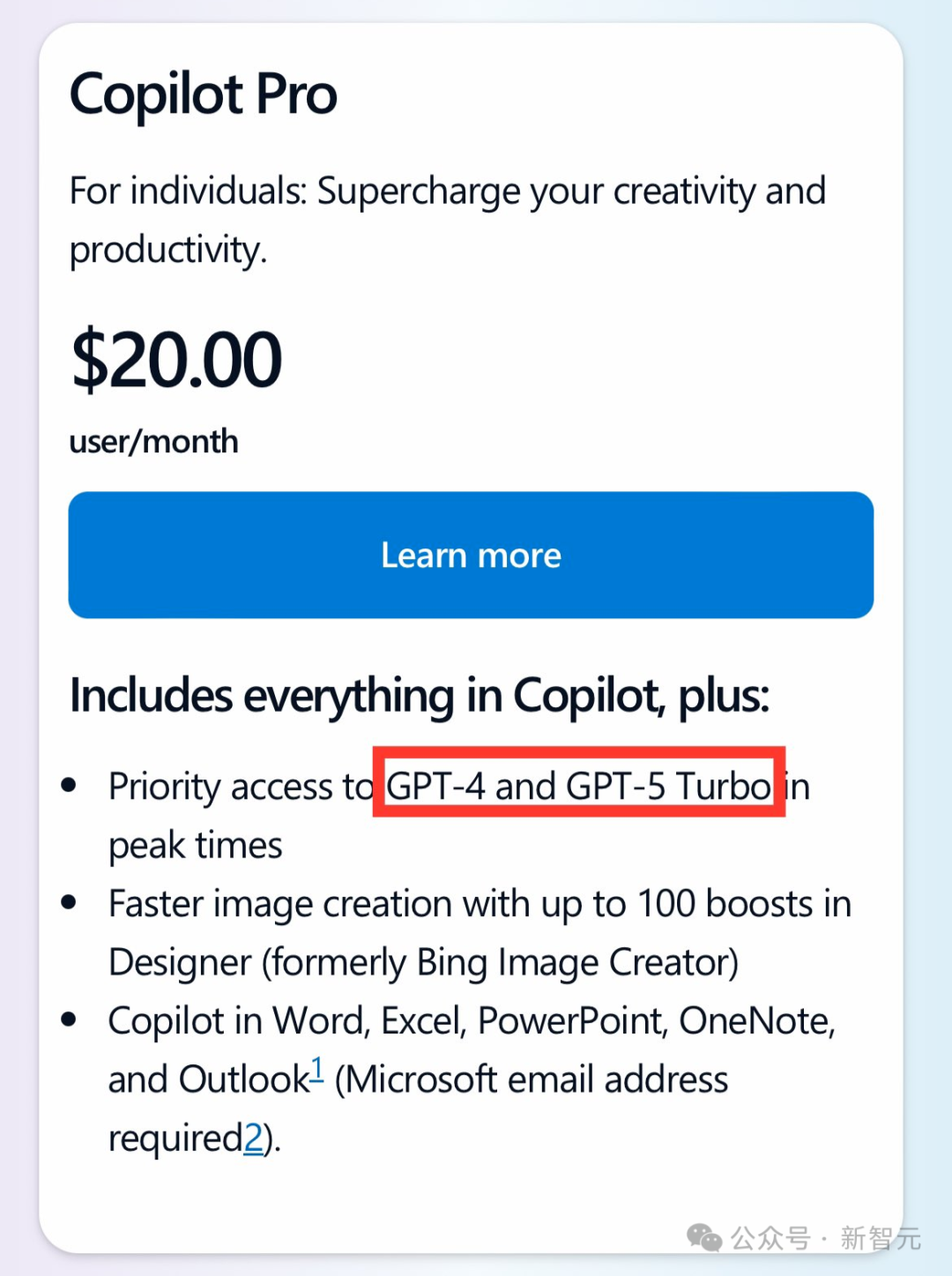
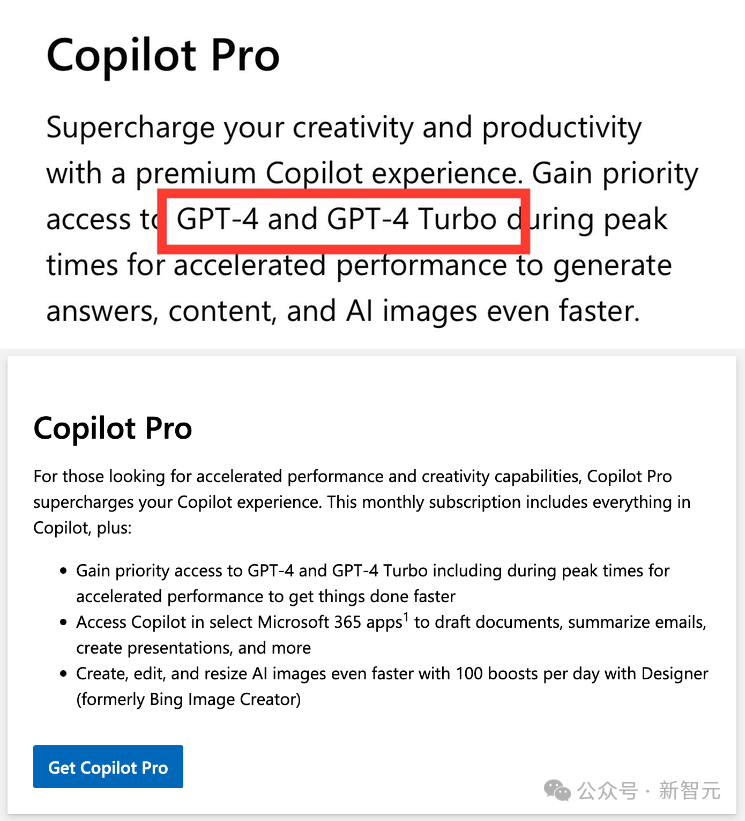

企业,真需要「大」模型吗?
大家都知道,ChatGPT和Sora,都可谓是「力大砖飞」的产物。 不过,这种大力出奇迹的暴力美学,恐怕在企业侧却并不一定适用。 对于企业来讲,大模型之「大」可能并不是唯一的诉求,甚至可能恰恰跟客户所需南辕北辙。 通用大模型的过人之处,在于跨领域的通用,以及追求通用的过程中涌现出来的能力,如很强的推理能力、逻辑能力。 ChatGPT是什么新鲜事物吗?显然,在图灵奖巨头Yann LeCun看来,它在技术上并不新。 
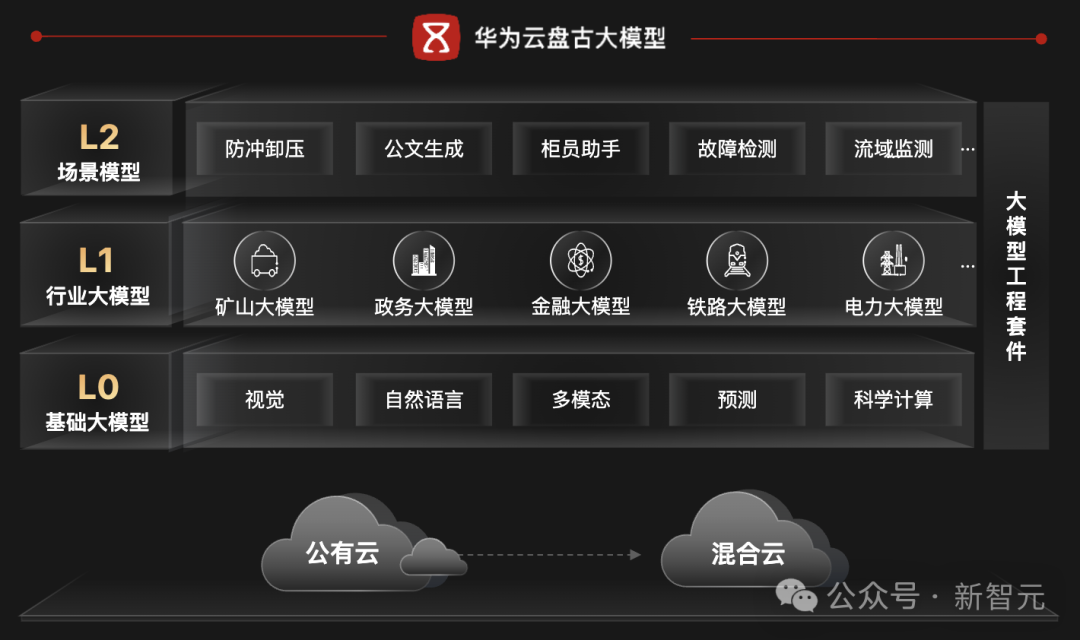
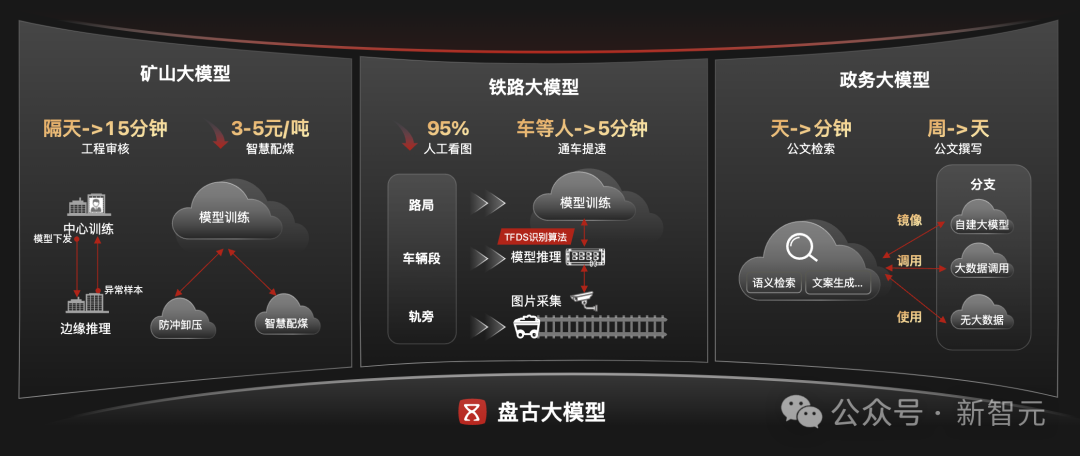
那究竟是什么,推动了GPT现象级的成功? 答案很简单,就是庞大的高质量语料——它们才是模型迈向更深层次智能的关键。 如果说有什么是全世界没有一个人做到、只有OpenAI想到且做到的,那就是他们系统性地将多源、复杂、信息密度差异巨大的知识「原料」,转为了让模型成长的教科书。 人工和自动化相结合的策略,让「原料」通过「数据飞轮」源源不断地转了起来,最终造就了GPT这个性能巨兽。 而企业所需要的行业大模型则需要垂直且可靠。 比如你可以让通用模型帮你写诗,帮你画画,这些都属于通识。 相比之下,煤矿企业往往需要远程采煤运煤,这就需要煤矿大模型看得懂采、掘、机、运、通、洗、选七大作业面的场景。 而气象大模型,则需要掌握历史天气数据,从而更好得预报天气。 
从力大砖飞,到现实落地
从力大砖飞,到现实落地
本地or上云,二者不可兼得?
我们都知道,大型政企客户的生产场景复杂多样,传统AI方案开发的模型复制到其他生产单位后,通常都会出现识别精度断崖式下降,无法推广复制的问题。 因此,把企业的用户数据、行业数据,甚至图谱或规则,放到大模型里继续训练,就能解决好行业问题,还能克服很多幻觉。 尤其在政企场景下,存在海量生产碎片化的情况,而工业生产推理因时延要求和带宽限制,需要在生产边缘部署管理。 例如在煤矿,一个大型的煤矿集团通常都需要将大模型能力部署到分布在各地的大量矿井,部署点位通常可以达到数千个。 如何高效部署、更新、持续收集异常样本成为企业规模化、集约化使用AI的一个难题。 而且工业生产普遍缺少负样本数量,原始模型精度往往有限,需要在使用过程中,边用边学,把新发现的异常样本及时上传到中心帮助大模型持续迭代,并及时把最新的能力快速的发放到海量的边缘,从而实现问题的精准监测,越用越聪明。 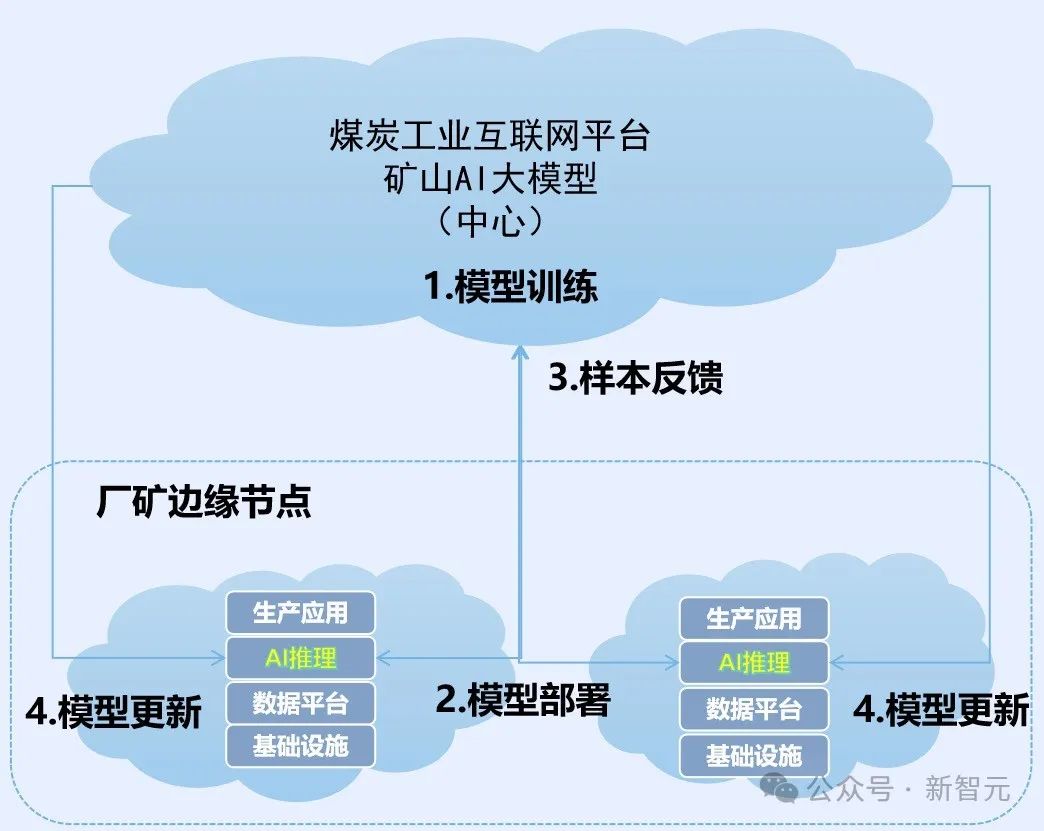
那怎么解决这些问题呢? 基于这个需求,一种全新的方案被提了出来——基于本地部署具备边云协同、软硬协同的混合云,来构建大模型。 具体来说就是,依托公有云上丰沛的算力资源,打造预训练基础大模型,利用混合云架构将大模型同步到企业本地,用企业私有数据对基础大模型来进行微调,然后推送到边缘做推理。 如此一来,既能满足业务创新诉求,也能缓解企业对数据安全和隐私的担忧,同时还能避免大量资金和人力的投入,实现大模型能力的快速建设。 而这无疑是政企实现智能化的更优选择。同时,也将成为未来行业大模型的重要部署形态。 开源大模型,还是商用大模型?
开源大模型,还是商用大模型?
对于上面的第二个问题,如果想要从0设计开发大模型,所需的不仅仅是上亿元的巨额投资,往往还得准备一个至少由十数名AI博士组成的专业人才团队,最后还不一定能达到预期效果。 显然,对于企业的应用来说,这种「费力不讨好」的重复造轮子,是完全没有必要的。 那么,我们是否可以借助现成的开源大模型,来构建专属大模型呢? 对不起,很难…… 
首先,企业选出来的大模型,从参数规模到准确率,再到泛化性等层面,最终能否满足业务场景的需求,实际上是一个未知数。 其次,大模型的开发和部署是一个系统性工程,而开源大模型往往缺乏完善的工具链支撑。如果企业想要对模型进行二次开发或者精调,面临的将会是一连串非常复杂的挑战。 第三,在整个过程中,企业不仅需要自主选择AI算力、框架,还有模型的部署模式等等。如果缺乏必要的软硬结合的调优能力,将难以充分发挥算力潜能。 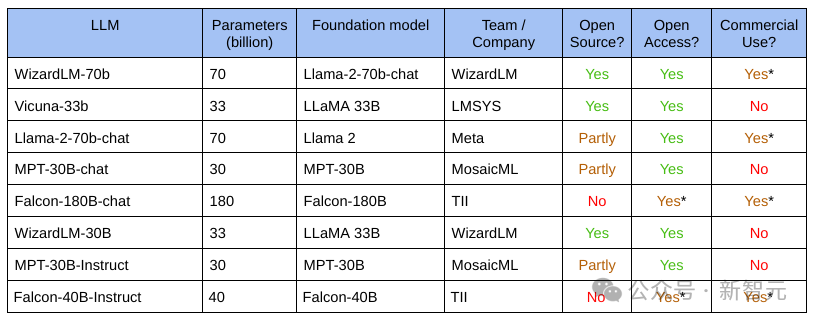
如此看来,相比起看似「0成本」的开源大模型,商用大模型显然更适合企业们的体质。 正如之前所讨论的,数据的质量,决定了我们能不能微调出可以真正解决实际问题的专属大模型。 而这里就涉及到的,便是模型供应商的数据工程能力了。 在企业中,数据样本散落在生产的各个环节里,收集起来非常困难。 在这里,供应商必须具有从获取、清洗、标注到管理的全链路专业服务能力,才能保障企业客户的高质量样本数据供给。 并且,还需要了解行业Know-how,让模型紧密结合行业经验知识。 因此,成熟的、工程化能力强的商用大模型,将会是企业应用的首选。 建设大模型,更要建设算力
建设大模型,更要建设算力
曾经的LLM大战,Meta迟迟没有动作。后来被外媒曝出个中原因,竟是因为GPU成本太高,于是一直在用CPU跑AI。 而决定重点科技树的Meta,即将在今年年底部署总共约60万颗的GPU来运行和训练AI系统。但后果就是,他们必须费老大劲重组数据中心,来适应这些新的GPU。 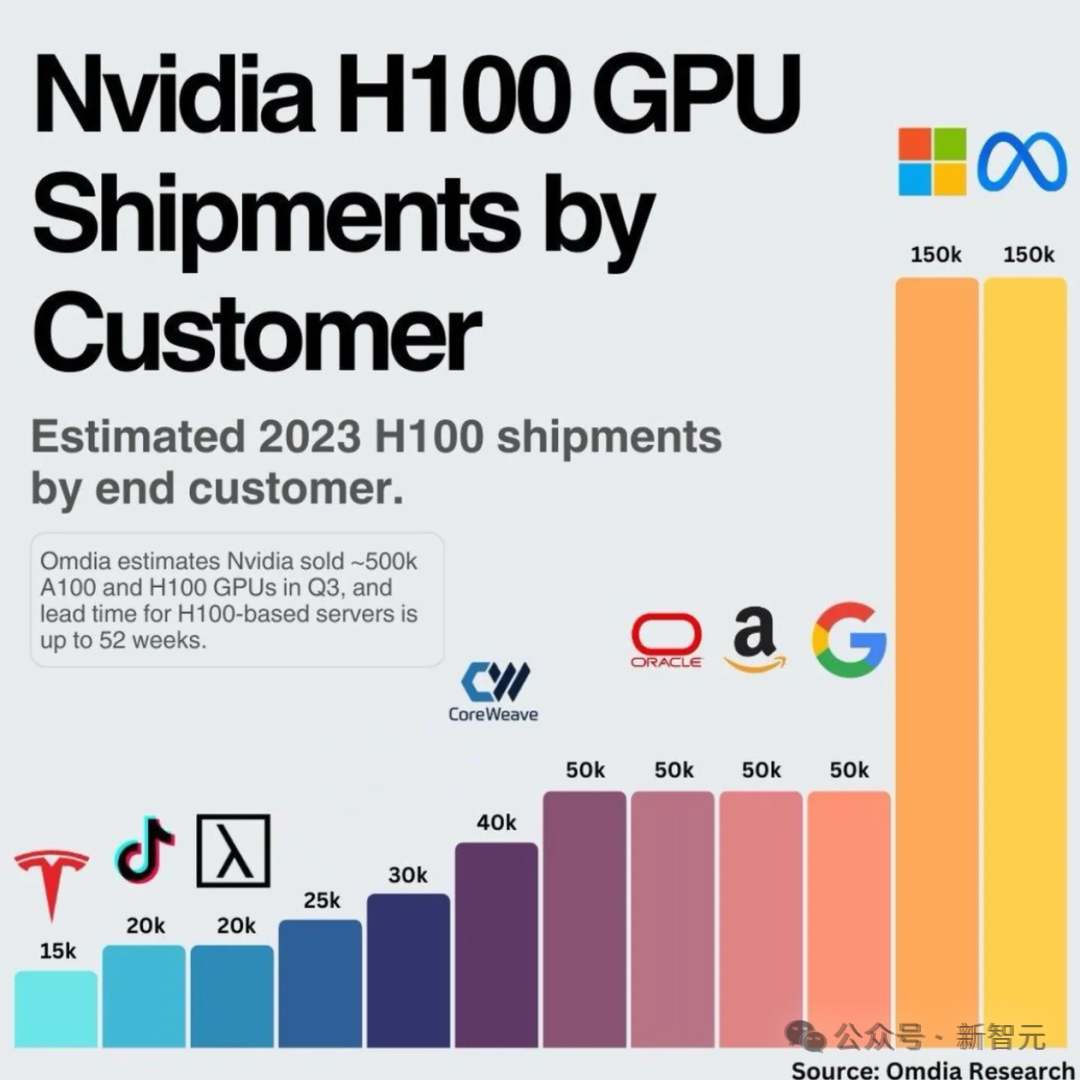
如今,算力紧缺已是不争的事实,如何高效利用有限算力,已成为大模型角逐的关键。 因此,选择合适的基础算力架构,对于大模型的商用来说至关重要。

- 优化技术架构和算子
- 减少计算图的大小和复杂度
- 降低计算时延
- 减少模型的存储空间
- 降低模型的部署成本
问题何解?
正如前文所说,既能兼顾本地部署,又能实现深度用云,还能保证数据安全和模型性能的方案,就是「混合云+大模型」了。 根据《深度用云展望2025》报告预测,中国人工智能市场空间到2025年将超过4000亿元。其中,75%的企业将会使用AI大模型,而基于混合云的AI大模型占比将达到38%。 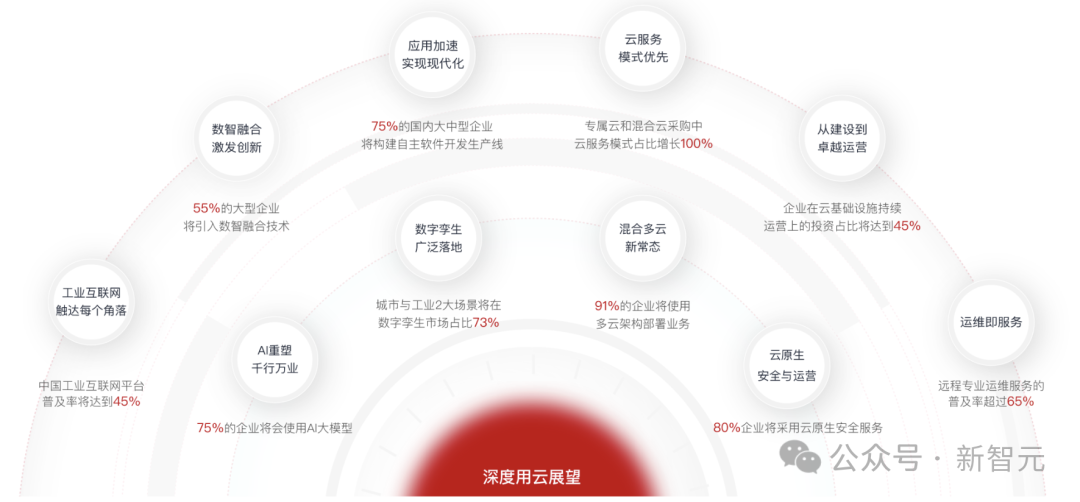
在这个赛道中,华为云Stack称得上是行业佼佼者。 从2019年开始,华为云就下场大模型研发。盘古大模型从一开始,就是为行业而生,赋能行业创新。 而华为混合云也是专为大型政企客户,量身定制的解决方案,历经了多年的市场和政企用户的打磨。 可以说,从基础设施、到算力、算法、开发框架等全栈的AI能力,华为为整个行业打造了一款智能的AI云底座。
为政企而生的大模型和混合云





内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢