

李飞飞团队发布具身智能基准,包含 1000 种日常活动和逼真模拟 清华团队新研究:只需一张图,5 分钟定制高保真一致 3D 内容 苹果 MM1 大模型:300 亿参数,多模态,在预训练指标上达到 SOTA 达摩院 AesopAgent:从故事到视频制作,智能体驱动的进化系统 CogView3:更精细、更快速的“文生图” 微软 AutoDev:人工智能驱动的自动化开发 谷歌 VLOGGER:基于多模态扩散的具身虚拟形象合成 LM2D:歌词与音乐驱动的舞蹈合成 清华团队新研究:视频扩散模型是有效的 3D 生成器 RecAI:利用大模型开发新一代推荐系统

BEHAVIOR-1K 包括两个部分,由 “您希望机器人为您做什么?”这一问题的广泛调查结果指导和推动。第一部分是对 1000 种日常活动的定义,以 50 个场景(房屋、花园、餐厅、办公室等)为基础,其中有 9000 多个标注了丰富物理和语义属性的物体。其次是 OMNIGIBSON,这是一个模拟环境,通过对刚体、可变形体和液体进行逼真的物理模拟和渲染来支持这些活动。
实验表明,BEHAVIOR-1K 中的活动是长视距的,并且依赖于复杂的操作技能,这两点对于最先进的机器人学习解决方案来说仍然是一个挑战。为了校准 BEHAVIOR-1K 的模拟与现实之间的差距,研究团队进行了一项初步研究,将在模拟公寓中使用移动机械手学习到的解决方案转移到现实世界中。
研究团队希望 BEHAVIOR-1K 以人为本的特性、多样性和现实性能使其在具身智能和机器人学习研究中发挥重要作用。
https://arxiv.org/abs/2403.09227
清华团队提出了一种新型 3D 定制方法——Make-Your-3D ,该方法可在 5 分钟内,仅通过一张带有文字描述的主题图像,个性化地生成高保真且一致的 3D 内容。
该项研究的主要内容是协调多视角扩散模型和特定身份 2D 生成模型的分布,使它们与所需 3D 主体的分布对齐。具体来说,研究团队设计了一个协同进化框架来减少分布的方差,其中每个模型分别通过身份感知优化和主体先验优化来学习另一个模型。
实验证明,这一方法可以生成高质量、一致且针对特定主题的 3D 内容,这些内容由文本驱动修改,在主题图像中是看不到的。
https://arxiv.org/abs/2403.09625
例如,与其他已发布的预训练结果相比,在大规模多模态预训练中,精心混合使用图像字幕、交错图像文本和纯文本数据,对于在多个基准测试中取得 SOTA 少样本结果至关重要。此外,研究团队还展示了图像编码器、图像分辨率和图像 token 数都会产生重大影响,而视觉语言连接器设计的重要性则相对较小。
通过所提出的方法,研究团队建立了一个多模态模型系列 MM1,它由密集模型和专家混合(MoE)变体组成,参数多达 30B,在预训练指标上达到了 SOTA,并在一系列既定的多模态基准上经过监督微调后取得了具有竞争力的性能。得益于大规模的预训练,MM1 具有增强的上下文学习和多图像推理等吸引人的特性,从而能够进行少样本的思维链提示。

https://arxiv.org/abs/2403.09611
该系统在一个统一的框架内集成了多种生成功能,因此个人用户可以轻松利用这些模块。这一创新系统可将用户故事提案转化为脚本、图像和音频,然后将这些多模态内容整合到视频中。此外,动画单元(如 Gen-2 和 Sora)可以使视频更具感染力。
AesopAgent 系统可以协调视频生成的任务流程,确保生成的视频内容丰富且连贯一致。该系统主要包括两层,水平层(Horizontal Layer)和实用层(Utility Layer)。在水平层中,研究团队提出了一种基于 RAG 的新颖进化系统,该系统可优化整个视频生成工作流程以及工作流程中的各个步骤。它通过积累专家经验和专业知识,不断进化和迭代优化工作流程,包括优化大型语言模型提示和实用程序的使用。实用程序层提供多种实用程序,可生成在构图、角色和风格方面具有视觉连贯性的一致图像。同时,它还提供音频和特效,将它们整合到富有表现力和逻辑安排合理的视频中。
总体而言,与之前的许多视觉故事作品相比,AesopAgent 实现了最先进的性能。
https://arxiv.org/abs/2403.07952
据介绍,CogView3 是第一个在文本到图像生成领域实现 relay diffusion 的模型,它通过首先创建低分辨率图像,然后应用基于中继(relay-based)的超分辨率来执行任务。这种方法不仅能产生有竞争力的文本到图像输出,还能大大降低训练和推理成本。
实验结果表明,在人类评估中,CogView3 比目前最先进的开源文本到图像扩散模型 SDXL 高出 77.0%,而所需的推理时间仅为后者的 1/2。经过提炼(distilled)的 CogView3 变体性能与 SDXL 相当,而推理时间仅为后者的 1/10。

https://arxiv.org/abs/2403.05121
为了填补这一空白,微软团队推出了全自动 AI 驱动软件开发框架 AutoDev,该框架专为自主规划和执行复杂的软件工程任务而设计。AutoDev 使用户能够定义复杂的软件工程目标,并将其分配给 AutoDev 的自主 AI 智能体来实现。这些 AI 智能体可以对代码库执行各种操作,包括文件编辑、检索、构建过程、执行、测试和 git 操作。它们还能访问文件、编译器输出、构建和测试日志、静态分析工具等。这使得 AI 智能体能够以完全自动化的方式执行任务并全面了解所需的上下文信息。
此外,AutoDev 还将所有操作限制在 Docker 容器内,建立了一个安全的开发环境。该框架结合了防护栏以确保用户隐私和文件安全,允许用户在 AutoDev 中定义特定的允许或限制命令和操作。
研究团队在 HumanEval 数据集上对 AutoDev 进行了测试,在代码生成和测试生成方面分别取得了 91.5% 和 87.8% 的 Pass@1 好成绩,证明了它在自动执行软件工程任务的同时维护安全和用户控制的开发环境方面的有效性。
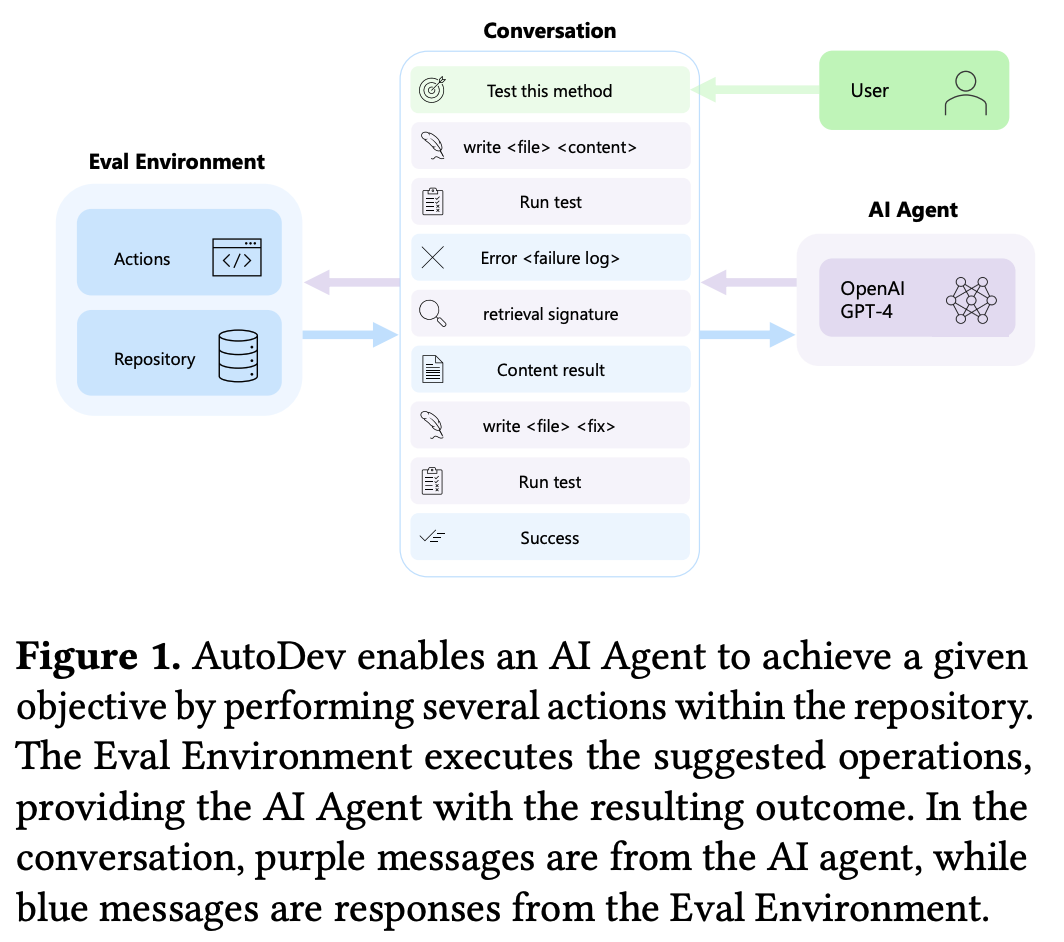
https://arxiv.org/abs/2403.08299
VLOGGER由两部分组成,一是随机人体到三维运动扩散模型,二是一种基于扩散的新型架构,它通过空间和时间控制来增强文本到图像模型。这有助于生成长度可变的高质量视频,并可通过人脸和身体的高级表示轻松控制。
与之前的工作相比,这一方法不需要对每个人进行训练,不依赖于人脸检测和裁剪,能生成完整的图像(不仅仅是人脸或嘴唇),并能考虑广泛的情况(如可见躯干或不同的主体身份),这对于正确合成交流的人类至关重要。研究团队还提出了一个包含三维姿势和表情注释的全新多样化数据集 MENTOR,它比以前的数据集大一个数量级(800000 identities),并且包含动态手势。研究团队在其上训练并简化了他们的主要技术贡献。
VLOGGER 在三个公共基准测试中的表现达到了 SOTA,考虑到图像质量、身份保留和时间一致性,同时还能生成上半身手势。VLOGGER 在多个多样性指标方面的表现都表明其架构选择和 MENTOR 的使用有利于大规模训练一个公平、无偏见的模型。最后,研究团队还展示了在视频编辑和个性化方面的应用。
https://arxiv.org/abs/2403.08764
为此,来自瑞典皇家理工学院、南洋理工大学、国立情报学研究所和哥本哈根大学的研究团队通过两项贡献来弥补这一差距。首先,他们提出了一个新的概率架构 LM2D,它将多模态扩散模型与一致性蒸馏相结合,旨在通过一个扩散生成步骤同时创建以音乐和歌词为条件的舞蹈。其次,研究团队提出了首个包含音乐和歌词的 3D 舞蹈动作数据集,该数据集通过姿势估计技术获得。
研究团队通过客观指标和人类评估(包括舞者和舞蹈编导)对其模型与纯音乐基线模型进行了评估。结果表明,LM2D 能够生成与歌词和音乐相匹配的逼真、多样的舞蹈。
https://arxiv.org/abs/2403.09407
为了充分发挥视频扩散感知 3D 世界的潜力,研究团队进一步引入了几何一致性先验,并将视频扩散模型扩展为多视角一致性 3D 生成器。得益于此,最先进的视频扩散模型可以通过微调在给定单张图像的情况下生成围绕物体的 360 度轨道帧。利用这一量身定制的重建管道可以在 3 分钟内生成高质量的网格或 3D 高斯。
此外,V3D 还可扩展到场景级新视图合成,在输入视图稀疏的情况下实现对摄像机路径的精确控制。实验证明了这一方法在生成质量和多视图一致性方面的卓越性能。

https://arxiv.org/abs/2403.06738
有了 LLMs 的加持,新一代的推荐系统有望变得更加通用、可解释、可对话和可控,从而为更加智能和以用户为中心的推荐体验铺平道路。研究团队希望 RecAI 的开源能帮助加速新的高级推荐系统的发展。
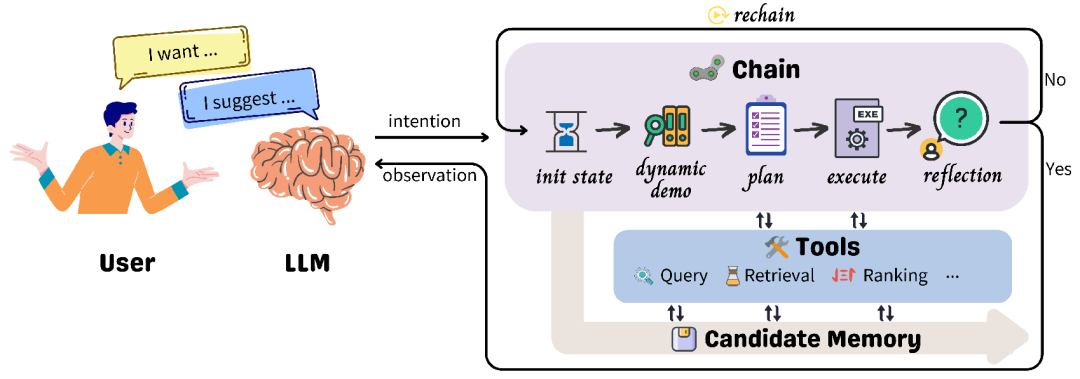
https://arxiv.org/abs/2403.06465
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢