
Datawhale分享
最新:英伟达,来源:量子位
AI春晚GTC开幕,皮衣老黄再次燃爆全场。
时隔两年,英伟达官宣新一代Blackwell架构,定位直指“新工业革命的引擎” ,“把AI扩展到万亿参数”。
作为架构更新大年,本次大会亮点颇多:
宣布GPU新核弹B200,超级芯片GB200
Blackwell架构新服务器,一个机柜顶一个超算
推出AI推理微服务NIM,要做世界AI的入口
新光刻技术cuLitho进驻台积电,改进产能。
……

8年时间,AI算力已增长1000倍。
老黄断言“加速计算到达了临界点,通用计算已经过时了”。
我们需要另一种方式来进行计算,这样我们才能够继续扩展,这样我们才能够继续降低计算成本,这样我们才能够继续进行越来越多的计算。
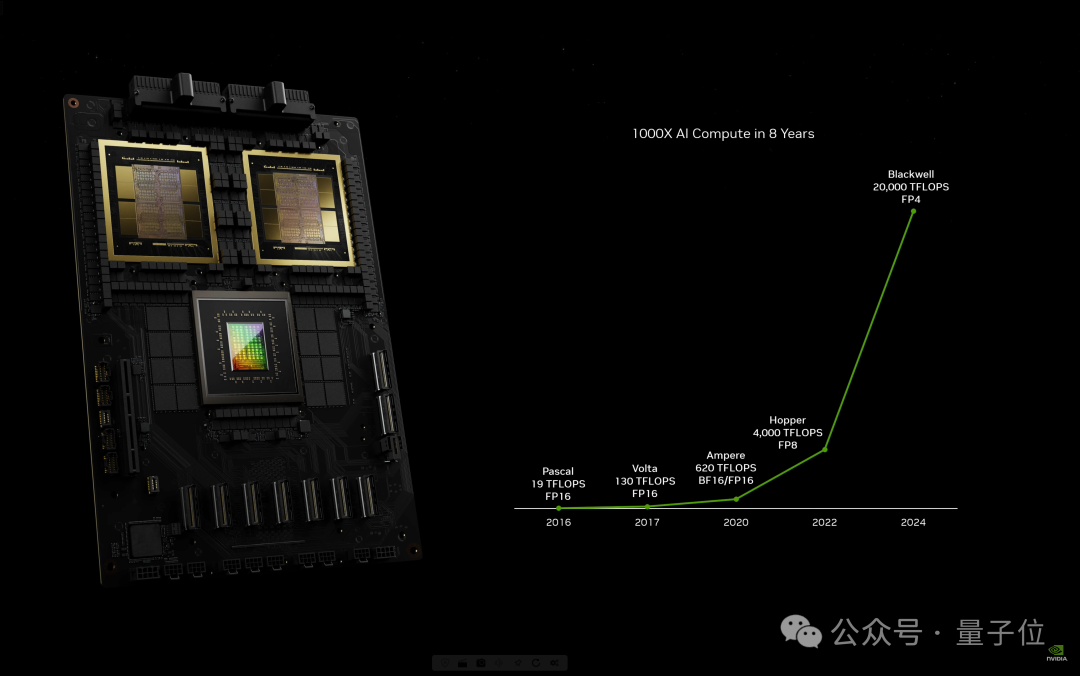
老黄这次主题演讲题目为《见证AI的变革时刻》,但不得不说,英伟达才是最大的变革本革。
GPU的形态已彻底改变
我们需要更大的GPU,如果不能更大,就把更多GPU组合在一起,变成更大的虚拟GPU。
Blackwell新架构硬件产品线都围绕这一句话展开。
通过芯片,与芯片间的连接技术,一步步构建出大型AI超算集群。
4nm制程达到瓶颈,就把两个芯片合在一起,以10TB每秒的满血带宽互联,组成B200 GPU,总计包含2080亿晶体管。
没错,B100型号被跳过了,直接发布的首个GPU就是B200。

两个B200 GPU与Grace CPU结合就成为GB200超级芯片,通过900GB/s的超低功耗NVLink芯片间互连技术连接在一起。
两个超级芯片装到主板上,成为一个Blackwell计算节点。

18个这样的计算节点共有36CPU+72GPU,组成更大的“虚拟GPU”。
它们之间由今天宣布的NVIDIA Quantum-X800 InfiniBand和Spectrum™-X800以太网平台连接,可提供速度高达800Gb/s的网络。

在NVLink Switch支持下,最终成为“新一代计算单元”GB200 NVL72。
一个像这样的“计算单元”机柜,FP8精度的训练算力就高达720PFlops,直逼H100时代一个DGX SuperPod超级计算机集群(1000 PFlops)。

与相同数量的72个H100相比,GB200 NVL72对于大模型推理性能提升高达30倍,成本和能耗降低高达25倍。
把GB200 NVL72当做单个GPU使用,具有1.4EFlops的AI推理算力和30TB高速内存。

再用Quantum InfiniBand交换机连接,配合散热系统组成新一代DGX SuperPod集群。
DGX GB200 SuperPod采用新型高效液冷机架规模架构,标准配置可在FP4精度下提供11.5 Exaflops算力和240TB高速内存。
此外还支持增加额外的机架扩展性能。

最终成为包含32000 GPU的分布式超算集群。
老黄直言,“英伟达DGX AI超级计算机,就是AI工业革命的工厂”。
将提供无与伦比的规模、可靠性,具有智能管理和全栈弹性,以确保不断的使用。

在演讲中,老黄还特别提到2016年赠送OpenAI的DGX-1,那也是史上第一次8块GPU连在一起组成一个超级计算机。

从此之后便开启了训练最大模型所需算力每6个月翻一倍的增长之路。
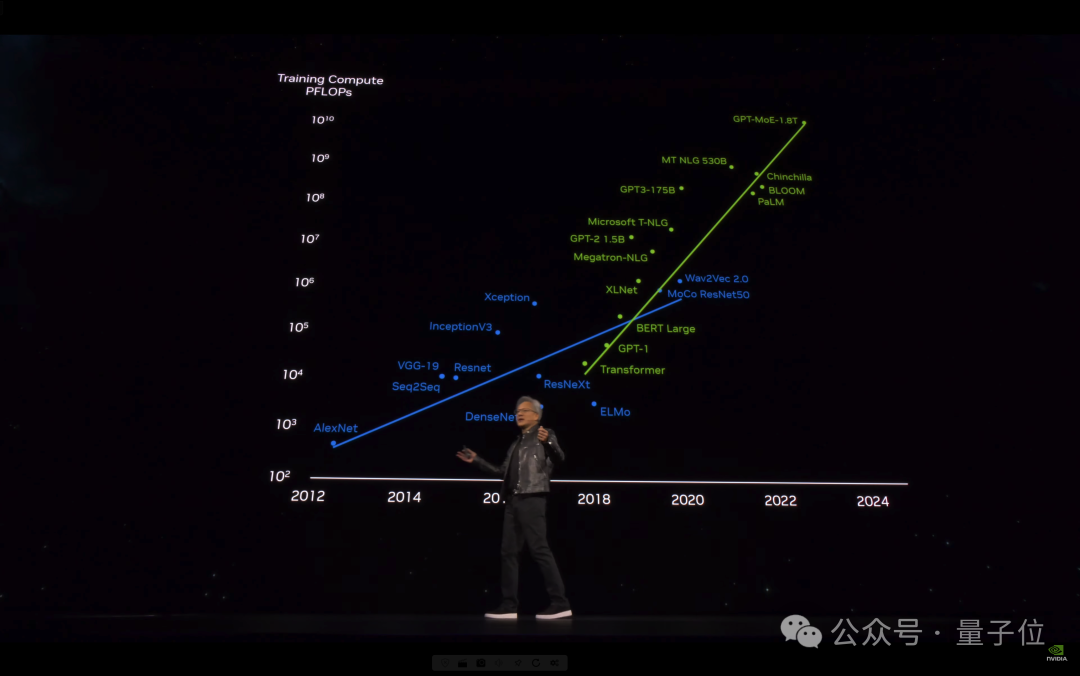
GPU新核弹GB200
过去,在90天内训练一个1.8万亿参数的MoE架构GPT模型,需要8000个Hopper架构GPU,15兆瓦功率。

如今,同样给90天时间,在Blackwell架构下只需要2000个GPU,以及1/4的能源消耗。

在标准的1750亿参数GPT-3基准测试中,GB200的性能是H100的7倍,提供的训练算力是H100的4倍。

Blackwell架构除了芯片本身外,还包含多项重大革新:
第二代Transformer引擎
动态为神经网络中的每个神经元启用FP6和FP4精度支持。

第五代NVLink高速互联
为每个GPU 提供了1.8TB/s双向吞吐量,确保多达576个GPU之间的无缝高速通信。

Ras Engine(可靠性、可用性和可维护性引擎)
基于AI的预防性维护来运行诊断和预测可靠性问题。
Secure AI
先进的加密计算功能,在不影响性能的情况下保护AI模型和客户数据,对于医疗保健和金融服务等隐私敏感行业至关重要。
专用解压缩引擎
支持最新格式,加速数据库查询,以提供数据分析和数据科学的最高性能。

在这些技术支持下,一个GB200 NVL72就最高支持27万亿参数的模型。
而GPT-4根据泄露数据,也不过只有1.7万亿参数。

英伟达要做世界AI的入口
老黄官宣ai.nvidia.com页面,要做世界AI的入口。
任何人都可以通过易于使用的用户界面体验各种AI模型和应用。
同时,企业使用这些服务在自己的平台上创建和部署自定义应用,同时保留对其知识产权的完全所有权和控制权。
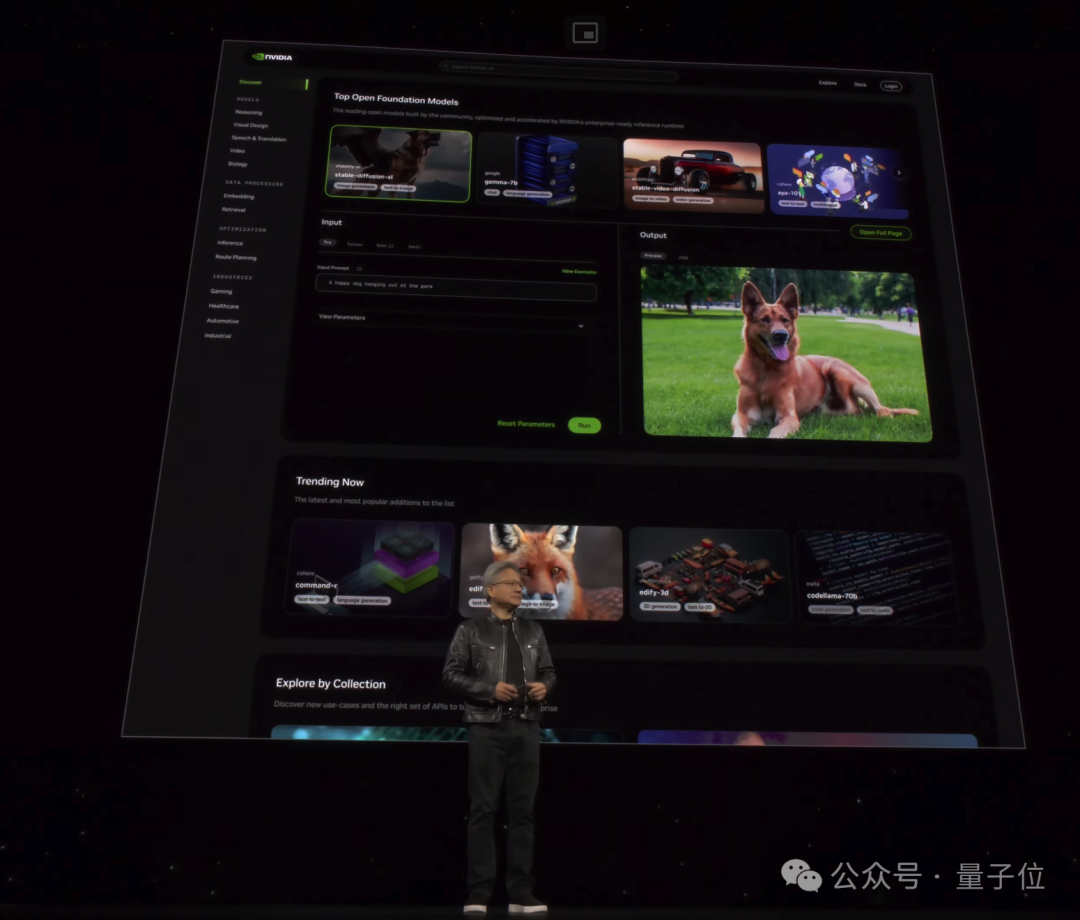
这上面的应用都由英伟达全新推出的AI推理微服务NIM支持,可对来自英伟达及合作伙伴的数十个AI模型进行优化推理。

此外,英伟达自己的开发套件、软件库和工具包都可以作为NVIDIA CUDA-X™微服务访问,用于检索增强生成 (RAG)、护栏、数据处理、HPC 等。
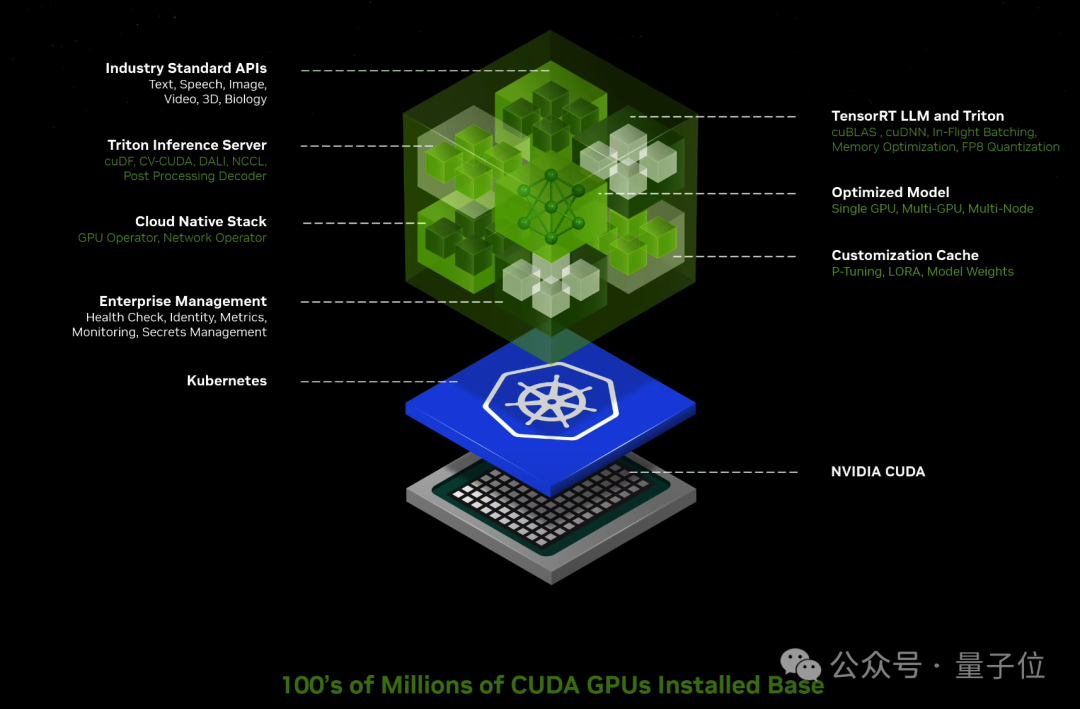
比如通过这些微服务,可以轻松构建基于大模型和向量数据库的ChatPDF产品,甚至智能体Agent应用。
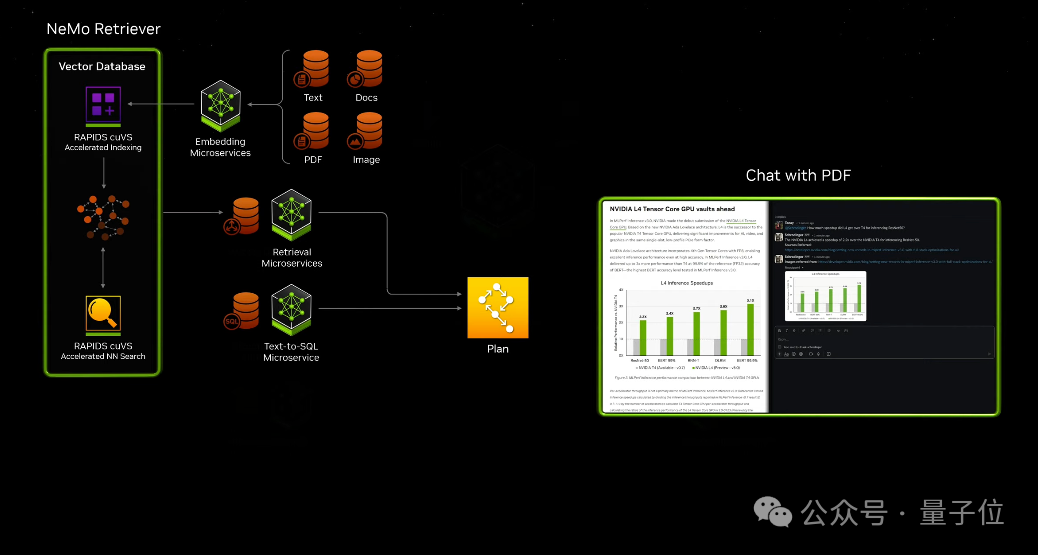
NIM微服务定价非常直观,“一个GPU一小时一美元”,或年付打五折,一个GPU一年4500美元。
从此,英伟达NIM和CUDA做为中间枢纽,连接了百万开发者与上亿GPU芯片。
什么概念?
老黄晒出AI界“最强朋友圈”,包括亚马逊、迪士尼、三星等大型企业,都已成为英伟达合作伙伴。

最后总结一下,与往年相比英伟达2024年战略更聚焦AI,而且产品更有针对性。
比如第五代NVLink还特意为MoE架构大模型优化通讯瓶颈。
新的芯片和软件服务,都在不断的强调推理算力,要进一步打开AI应用部署市场。
当然作为算力之王,AI并不是英伟达的全部。
这次大会上,还特别宣布了与苹果在Vision Pro方面的合作,让开发者在工业元宇宙里搞空间计算。

此前推出的新光刻技术cuLitho软件库也有了新进展,被台积电和新思科技采用,把触手伸向更上游的芯片制造商。

当然也少不了生物医疗、工业元宇宙、机器人汽车的新成果。


以及布局下一轮计算变革的前沿领域,英伟达推出云量子计算机模拟微服务,让全球科学家都能充分利用量子计算的力量,将自己的想法变成现。

One More Thing
去年GTC大会上,老黄与OpenAI首席科学家Ilya Sutskever的炉边对谈,仍为人津津乐道。
当时世界还没完全从ChatGPT的震撼中清醒过来,OpenAI是整个行业绝对的主角。
如今Ilya不知踪影,OpenAI的市场统治力也开始松动。在这个节骨眼上,有资格与老黄对谈的人换成了8位——
Transformer八子,开山论文《Attention is all you need》的八位作者。
他们已经悉数离开谷歌,其中一位加入OpenAI,另外7位投身AI创业,有模型层也有应用层,有toB也有toC。
这八位传奇人物既象征着大模型技术真正的起源,又代表着现在百花齐放的AI产业图景。在这样的格局中,OpenAI不过是其中一位玩家。
而就在两天后,老黄将把他们聚齐,在自己的主场。

要论在整个AI界的影响力、号召力,在这一刻,无论是“钢铁侠”马斯克还是“奥特曼”Sam Altman,恐怕都比不过眼前这位“皮衣客”黄仁勋。
……
直播回放:
https://www.youtube.com/watch?v=Y2F8yisiS6E

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢