

新智元报道
新智元报道
【新智元导读】就在刚刚,老黄又来打破摩尔定律了:英伟达新核弹B200,一块能顶5个H100,30倍推理加速,能训万亿参数大模型!同时推出的AI推理微服务NIM,号称让全世界用上AI。
就在刚刚结束的GTC人工智能大会上,英伟达的新一代性能巨兽Backwell诞生了!

Blackwell B200 GPU,是如今世界上最强大的AI芯片,旨在「普惠万亿参数的AI」。
本来,H100已经使英伟达成为价值数万亿美元的公司,赶超了谷歌和亚马逊,但现在,凭着Blackwell B200和GB200,英伟达的领先优势还要继续领先。
老黄表示——「H100很好,但我们需要更大的GPU」!
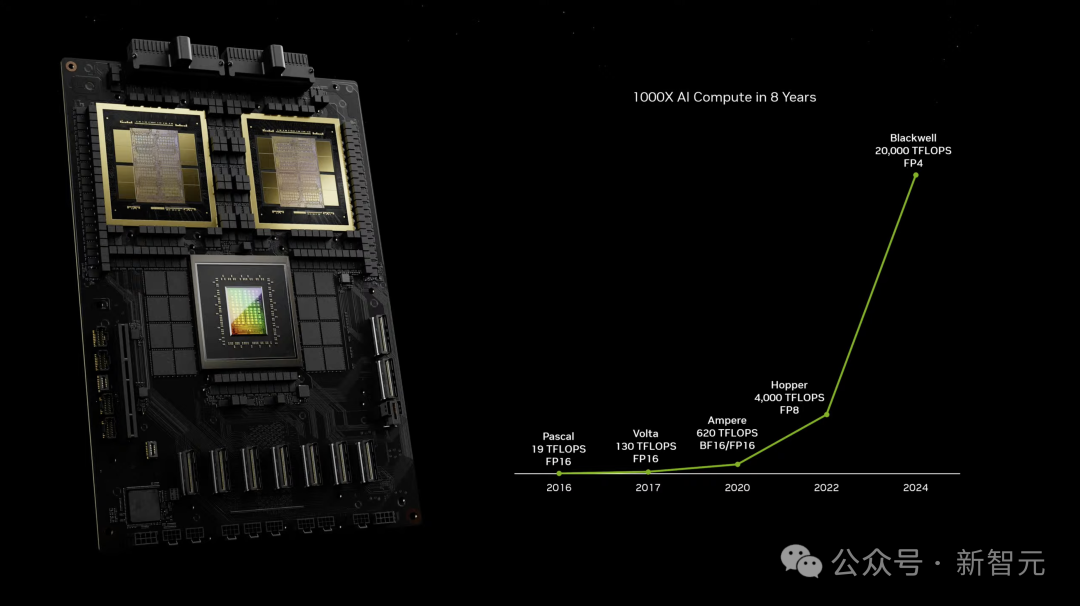
新的B200 GPU,从2080亿个晶体管中能提供高达20 petaflops的FP4性能。(H100仅为4 petaflops)
而将两个B200与单个Grace CPU相结合的GB200,则可以为LLM推理工作负载提供30倍的性能,同时大大提高效率。
比起H100,GB200的成本和能耗降低了25倍!

Blackwell芯片和Hopper H100芯片的尺寸比较
这种额外的处理能力,就能让AI公司训练更大、更复杂的模型,甚至可以部署一个27万亿参数的模型。
更大的参数,更多的数据,未来的AI模型,无疑会解锁更多新功能,涌现出更多新的能力。
现在,老黄拿在手里的,或许是100亿美元。

新一代性能巨兽,深夜重磅登场
凭借H100成为全球市值第三大公司的英伟达,今天再次推出了性能野兽——Blackwell B200 GPU和GB200「超级芯片」。 
它以著名数学家David Blackwell(1919-2010)命名。他一生中对博弈论、概率论做出了重要的贡献。 
老黄表示,「30年来,我们一直在追求加速计算,目标是实现深度学习和AI等变革性突破。生成式AI已然成为我们这个时代的标志性技术,而Blackwell将是推动这场新工业革命的引擎」。 「我们认为这是个完美的博弈概率」。 全新B200 GPU拥有2080亿个晶体管,采用台积电4NP工艺节点,提供高达20 petaflops FP4的算力。 与H100相比,B200的晶体管数量是其(800亿)2倍多。而单个H100最多提供4 petaflops算力,直接实现了5倍性能提升。 
而GB200是将2个Blackwell GPU和1个Grace CPU结合在一起,能够为LLM推理工作负载提供30倍性能,同时还可以大大提高效率。 
值得一提的是,与H100相比,它的成本和能耗「最多可降低25倍」。 过去,训练一个1.8万亿参数的模型,需要8000个Hopper GPU和15MW的电力。 
如今,2000个Blackwell GPU就能完成这项工作,耗电量仅为4MW。 在GPT-3(1750亿参数)大模型基准测试中,GB200的性能是H100的7倍,训练速度是H100的4倍。



网友:新的摩尔定律诞生了!
网友们纷纷惊叹,Blackwell再一次改变了摩尔定律。 英伟达高级科学家Jim Fan表示:Blackwell,城里的新野兽。 - DGX Grace-Blackwell GB200:单机架计算能力超过1 Exaflop。 - 从这个角度来看:老黄交付给OpenAI的第一台DGX是0.17 Petaflops。 - GPT-4-1.8T参数在2000张Blackwell上可在90天内完成训练。
新摩尔定律诞生了。 
贾扬清回忆道,「我记得在Meta,当我们在一小时内(2017年)训练ImageNet时,总计算量约为1exaflop。这意味着有了新的DGX,理论上你可以在一秒钟内训练ImageNet」。 
还有网友表示,「这简直就是野兽,比H100强太多」。 
另有网友戏称,「老黄确认GPT-4是1.8万亿参数」。 
所以,GB200的成本是多少呢?英伟达目前并没有公布。 此前据分析师估计,英伟达基于Hopper的H100芯片,每颗的成本在25,000美元到40,000美元之间,整个系统的成本高达200,000美元。 而GB200的成本,只可能更高。 新超算可训万亿参数大模型
新超算可训万亿参数大模型
当然,有了Blackwell超级芯片,当然还会有Blackwell组成的DGX超算。 这样,公司就会大量购入这些GPU,并将它们封装在更大的设计中。 GB200 NVL72是将36个Grace CPU和72个Blackwell GPU集成到一个液冷机柜中,可实现总计720 petaflops的AI训练性能,或是1,440 petaflops(1.4 exaflops)的推理性能。 它内部共有5000条独立电缆,长度近两英里。 
它的背面效果如下图所示。 
机柜中的每个机架包含两个GB200芯片,或两个NVLink交换机。一共有18个GB200芯片托盘,9个NVLink交换机托盘有。 老黄现场表示,「一个GB200 NVL72机柜可以训练27万亿参数的模型」。 此前传言称,GPT-4的参数规模达1.8万亿,相当于能训练近15个这样的模型。 
与H100相比,对于大模型推理工作负载,GB200超级芯片提供高达30倍的性能提升。 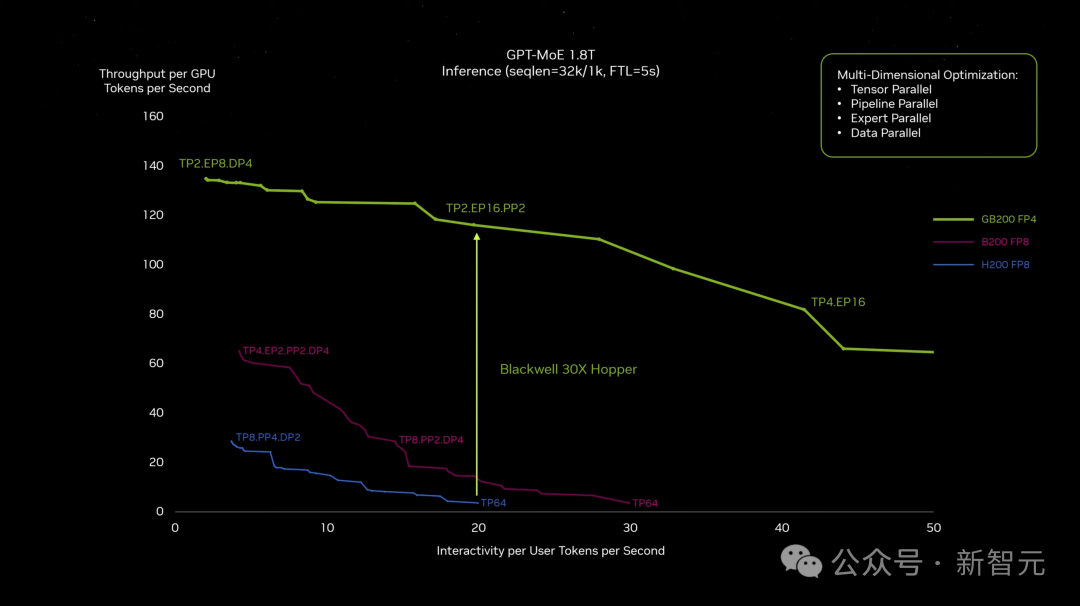
那么,由8个系统组合在一起的就是DGX GB200。 总共有288个Grace CPU、576个Blackwell GPU、240 TB内存和11.5 exaflop FP4计算。 
这一系统可以扩展到数万个GB200超级芯片,通过Quantum-X800 InfiniBand(最多144个连接)或Spectrum-X800ethernet(最多64个连接)与800Gbps网络连接在一起。 
配备DGX GB200系统的全新DGX SuperPod采用统一的计算架构。 除了第五代NVIDIA NVLink,该架构还包括NVIDIA Bluefield-3 DPU,并将支持Quantum-X800 InfiniBand网络。 这种架构可以为平台中的每个GPU提供高达每秒1,800 GB的带宽。 除此之外,英伟达还发布了统一的超算平台DGX B200,用于AI模型训练、微调和推理。 它包括8个Blackwell GPU和2个第五代Intel Xeon处理器,包含FP4精度功能,提供高达144 petaflops的AI性能、1.4TB的GPU内存和64TB/s的内存带宽。 这使得万亿参数模型的实时推理速度,比上一代产品提高了15倍。 用户还可以使用DGX B200系统构建DGX SuperPOD,创建人工智能卓越中心,为运行多种不同工作的大型开发团队提供动力。 目前,亚马逊、谷歌、微软已经成为最新芯片超算的首批用户。 亚马逊网络服务,将建立一个拥有20,000 GB200芯片的服务器集群。 
「不只是一个芯片,更是一个平台」
「不只是一个芯片,更是一个平台」

终极生成式AI模型
而现在,整个行业都已经为Blackwell准备好了。 2012年,将一只小猫的图片输入,AlexNet识别后输出「cat」,让世界所有人为之震惊,并高呼这改变了一切。 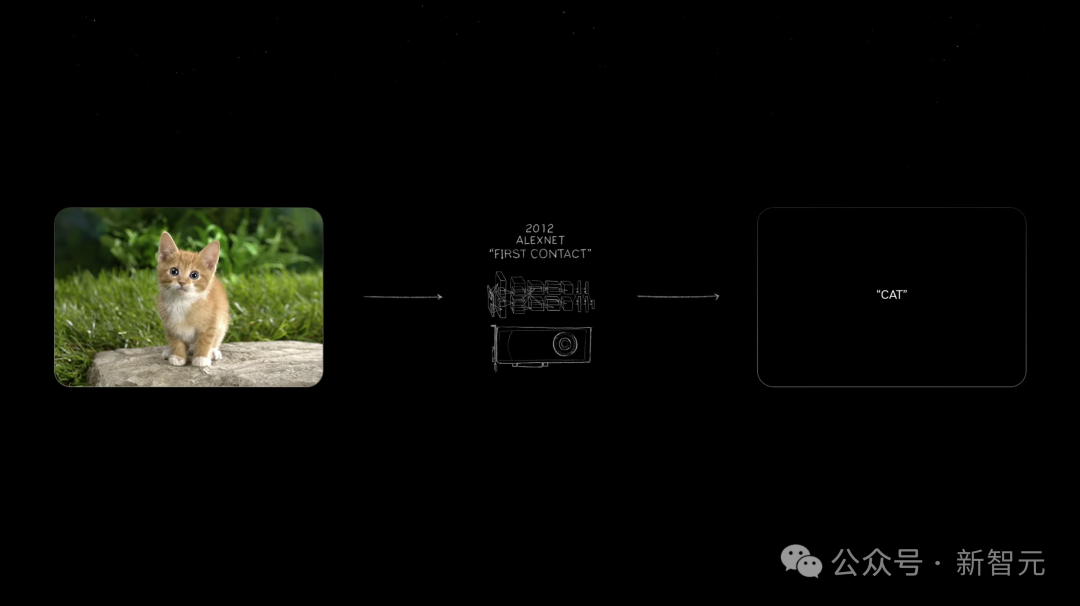
而现在从三个字「cat」输出10 million 像素成为了可能。仅用了10年时间,我们就可以识别文本、图像、视频。 万物都皆可数字化。 
网友表示,老黄向我们展示了GenAI的终极游戏:多模态输入——多模态输出。 「这是我们总有一天都会使用的最终模型。它可以获取任何模态并生成任何模态。同时,它还能在没有每个部件的情况下工作」。 
数字化的目的是让所有的目标都能成为机器学习的目标,从而让它们都能被AI生成。 比如,数字孪生地球,可以很好地帮助我们了解全球气象气候的变化。 
将基因、蛋白质、氨基酸数字化,可以让人类去理解生命的力量。 
在大会接近尾声时,活动迎来了一个小高潮:WALL-E机器人也登台表演了。 
而生成式AI的未来应用不仅于此。 现在,有了世界最强的处理器Blackwell,新一轮技术革命即将开启。 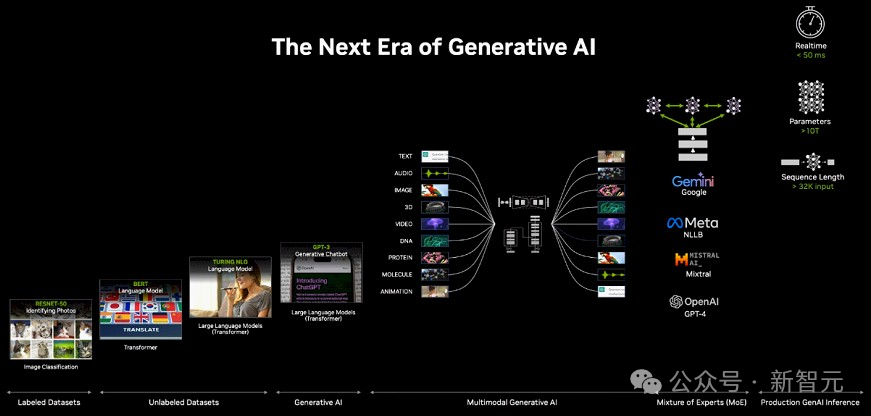
参考资料: https://youtu.be/Y2F8yisiS6E?list=TLGGFIbdOwQMZx4xODAzMjAyNA



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢