
BGE(BAAI General Embedding)是智源研究院打造的通用语义向量模型。自2023年8月发布以来,智源团队陆续发布了中英文模型BGE v1.0、v1.5以及多语言模型 BGE-M3,截至目前,BGE 系列模型全球下载量超过 1500万,位居国内开源AI模型首位。BGE-M3模型一度跃居 Hugging Face 热门模型前三,其所属代码仓库FlagEmbedding位居Github热门项目前10;BGE-M3所带来的全新的通用检索模式也相继被Milvus、Vespa等主流向量数据库集成。近日,智源团队再度推出新一代检索排序模型 BGE Re-Ranker v2.0,同时扩展向量模型BGE的“文本+图片”混合检索能力。
↓ 上述模型现已通过 Hugging Face、Github 等平台发布,采用免费、商用许可的开源协议:
https://github.com/FlagOpen/FlagEmbeddinghttps://huggingface.co/BAAI技术亮点
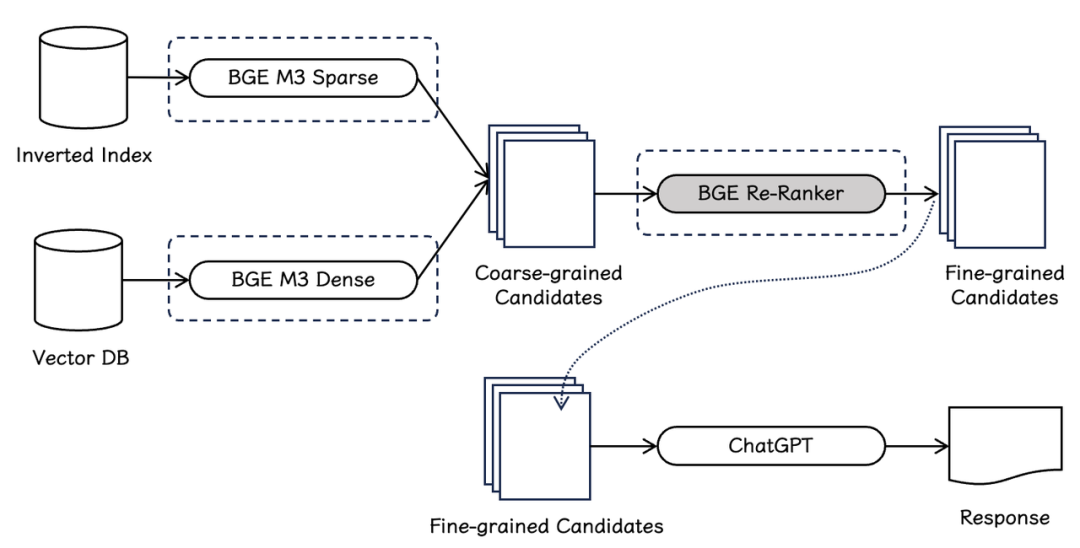
图1 RAG pipline
如图1所示,检索排序模型是信息检索及RAG pipeline中的重要组成部分。与向量模型与稀疏检索模型相比,检索排序模型会利用更加复杂的判定函数以获得更加精细的相关关系。通常,系统会首先借助向量模型(BGE-M3-Dense)与稀疏检索模型(BGE-M3-Sparse)分别从向量数据库与倒排索引中初步获取粗力度的候选文档(coarse-grained candidates)。紧接着,系统会进一步利用排序模型(BGE Re-Ranker)进一步过滤候选集,并最终获得精细的文档集(fine-grained candidates),以支持下游大语言模型完成检索增强任务(RAG)。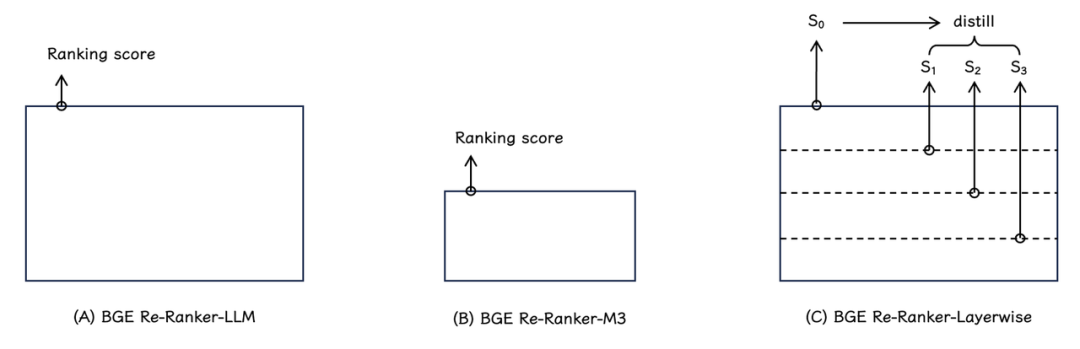
图2
1. BGE Re-Ranker v2.0系列排序模型采用了两种不同尺寸的模型基座:- BGE Re-Ranker v2-LLM(如图2A):基于 MiniCPM-2B,Gemma-2B等性能卓越的轻量化大语言模型。
BGE Re-Ranker v2-M3(如图2B):基于性能出色、参数量更小的 BGE-M3-0.5B(速度更快)。
2. 所有模型均通过多语言数据训练产生,具备多语言检索的能力。例如:BGE Re-Ranker v2-MiniCPM-2B 大幅提升了中英文检索能力,而BGE Re-Ranker v2-Gemma-2B与BGE Re-Ranker v2-M3则在多语言检索任务中取得了最佳的检索效果(注:BGE Re-ranker v2.0 系列模型训练数据配比见GitHub仓库说明)。
3. 为了进一步提升模型推理效率,BGE Re-Ranker v2.0 采取了分层自蒸馏训练策略(如图2C)。具体而言,模型最终排序得分(S(0))被用作教师信号,利用知识蒸馏的方式,模型的各中间层也被学习并赋予了排序能力。在实际应用中,用户可以基于具体场景的算力条件及时延限制灵活选择排序模型的层数。
4. BGE系列向量模型扩展“文本+图片”混合检索功能。通过引入由CLIP模型所生成的visual token,BGE得以获得“文本+图片”混合建模能力。值得注意的是,扩增visual token的训练仅仅作用在visual tokenizer之上,而原本的BGE模型(BGE v1.5,BGE M3)参数保持不变。因此,在获得混合建模能力的同时,BGE模型出色的文本检索能力得以完全保持。
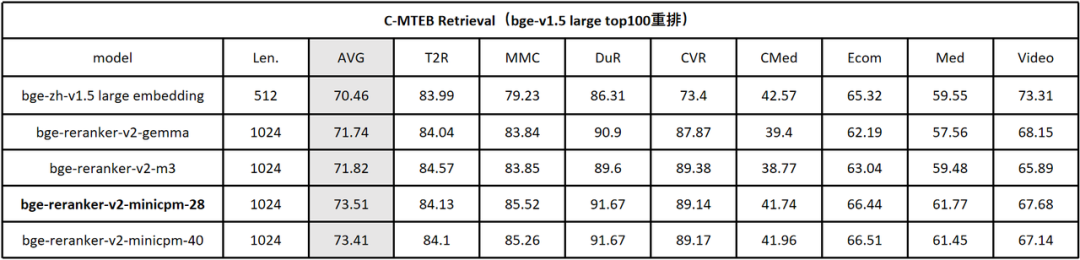
BGE Re-Ranker v2.0系列模型在英文、中文、多语言主流基准的检索性能评测结果如下:英文评测 MTEB/Retrival 结果如下(表1):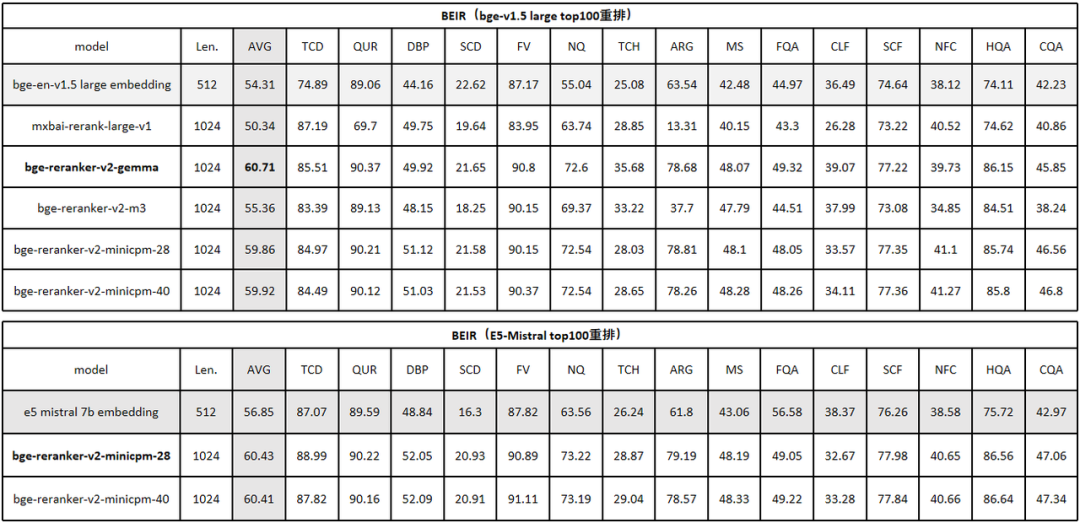
表1
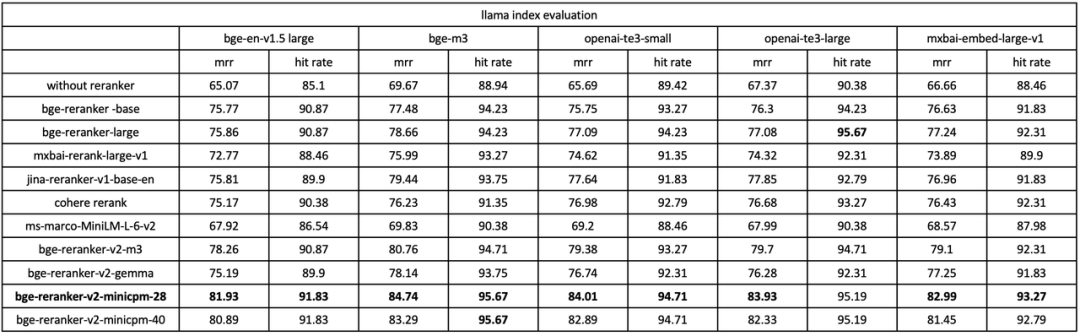
BGE Re-Ranker v2首先对BGE-v1.5-large的top-100候选集进行重排。实验结果显示,BGE Re-Ranker v2-Gemma-2B取得了最为出色的效果,检索精度得以大幅提升 6%。与此同时,通过分层自蒸馏策略获得的中间层排序结果(BGE Re-Ranker v2-MiniCPM-28 vs. BGE Re-Ranker v2-MiniCPM-40)很好的保持了最终层的检索精度。此外,在切换至性能更为出色的向量模型E5-Mistral-7B之后(仍旧重拍其top-100),检索精度获得了进一步提升,平均检索等分(NGCG@10)达到了60.4,相较原本的embedding-only的结果56.85 提升了近4%,这一结果也是目前BEIR基准上的最佳评测结果。[1][2]。在中文评测C-MTEB/Retrival 中,BGE Re-Ranker v2同样对BGE- v1.5-large的top-100候选集进行重排。与英文结果相类似,BGE Re-Ranker v2-MiniCPM-2B取得了最优检索质量,且中间层排序结果(BGE Re-Ranker v2-MiniCPM-2B-layer 28)仍旧充分保持最终层的检索精度。在多语言评测MIRACL中(表3),BGE Re-Ranker v2对BGE-M3的top-100候选集进行重排。与先前结果不同的是,BGE Re-Ranker v2-Gemma-2B综合效果位居首位,而BGE Re-Ranker v2-M3则以较小的模型尺寸(0.5B)取得了与之相近的效果。上述结果也反映了各个预训练模型基座在不同语言下的性能差异。在Llama Index所提供的RAG评测基准中 [3],我们使用BGE Re-Ranker v2及多种baseline re-ranker对不同的embedding模型(bge v1.5 large, bge-m3, openai-te3, mxbai-embedding)的召回结果进行重排。如下表所示(表4),BGE Re-Ranker v2可以大幅提升各个embedding model在RAG场景下的精度。同时,BGE Re-Ranker v2搭配bge-m3可以获得最佳的端到端检索质量。表4
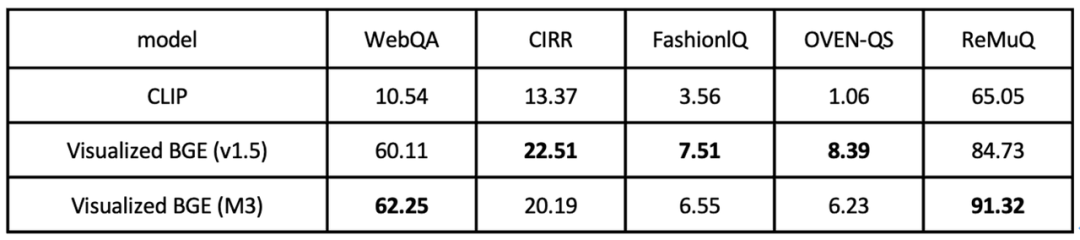
最后,在“文本+图片”混合检索的任务中(表4),Visualized BGE在WebQA、CIRR、FashionlQ、OVEN-QS、ReMuQ等五个常用评测基准上取得了对比CLIP baseline的显著优势。表5
得益于BGE出色的性能与良好的通用性,行业内主流的向量数据库纷纷跟进BGE的各个模型版本。此前备受欢迎的BGE-M3模型已被Vespa、Milvus等框架集成,为社区用户快速搭建“三位一体的”(稠密检索、稀疏检索、重排序)检索流水线带来的极大便利。

[1] MTEB Leaderboard, https://huggingface.co/spaces/mteb/leaderboard
[2] SFR-Embedding-Mistral, https://blog.salesforceairesearch.com/sfr-embedded-mistral/
[3] Llama-Index Evaluation, https://docs.llamaindex.ai/en/latest/optimizing/evaluation/evaluation.html
[4] Vespa for BGE M3, https://github.com/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/mother-of-all-embedding-models-cloud.ipynb
[5] Zilliz for BGE, https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3


内容中包含的图片若涉及版权问题,请及时与我们联系删除





评论
沙发等你来抢