- 清华朱军团队:根据人类偏好实现高保真文本-3D生成
- 西湖大学新研究:优于Transformer的高效推理
- AnyV2V:即插即用,轻松完成任何视频到视频编辑任务
- MathVerse:多模态语言模型真的懂数学图表吗?
扫描下方二维码,或添加微信 Tobethenum1,加入大模型论文分享群,务必备注“大模型日报”。
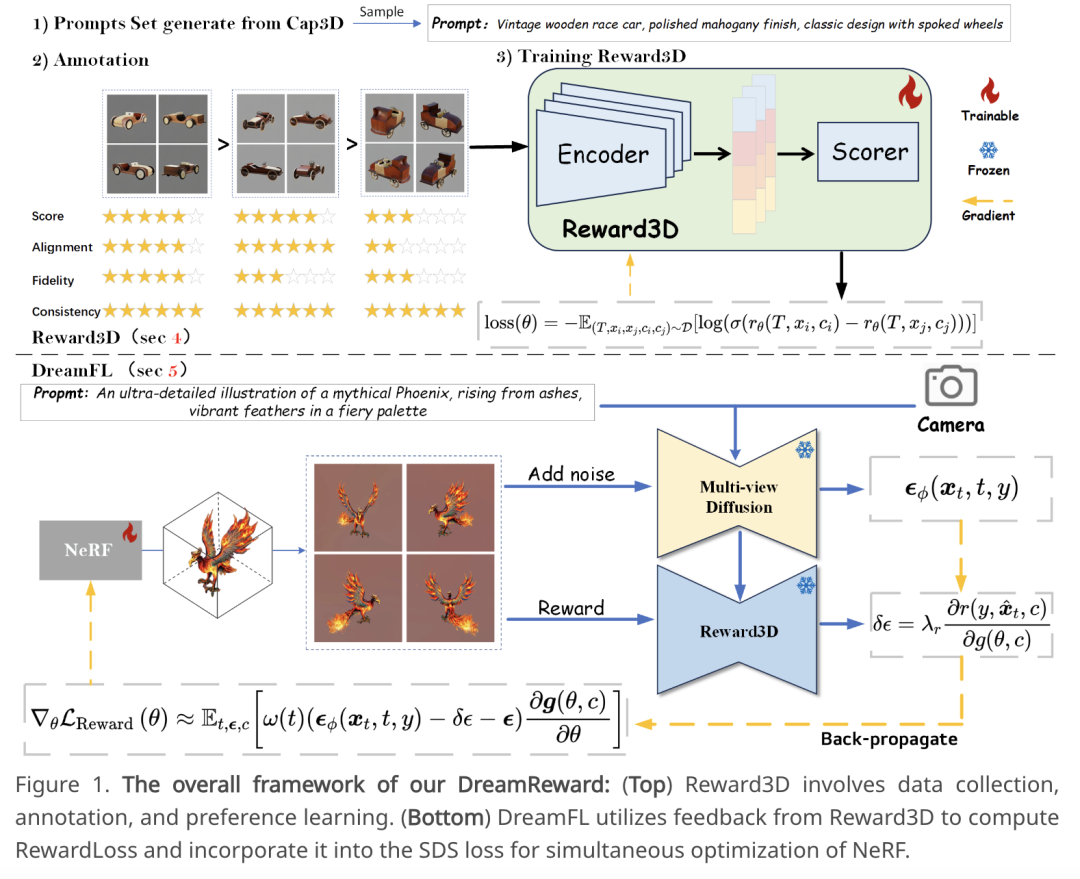
1.清华朱军团队:根据人类偏好实现高保真文本-3D生成近来,根据文字提示创建 3D 内容取得了显著的突破。然而,目前的文本-3D 方法生成的 3D 结果往往与人类的偏好不太一致。为此,清华大学朱军教授团队提出了一个名为 DreamReward 的综合框架,用于从人类偏好反馈中学习和改进文本-3D 模型。首先,他们基于一个系统化的注释管道(包括评级和排名)收集了 25000 个专家比较结果;然后,他们建立了首个通用的文本-3D 人类偏好奖励模型——Reward3D,该模型可以有效地编码人类偏好;最后,在 3D 奖励模型的基础上,他们进行了理论分析,并提出了 Reward3D 反馈学习(DreamFL),这是一种直接微调算法,可通过重新定义的评分器优化多视角扩散模型。在理论证明和大量实验对比的基础上,DreamReward 成功生成了高保真和 3D 一致的结果,且显著提高了与人类意图的提示一致性。这一研究结果证明了从人类反馈中学习来改进文本-3D 模型的巨大潜力。论文链接:
https://arxiv.org/abs/2403.14613
项目地址:
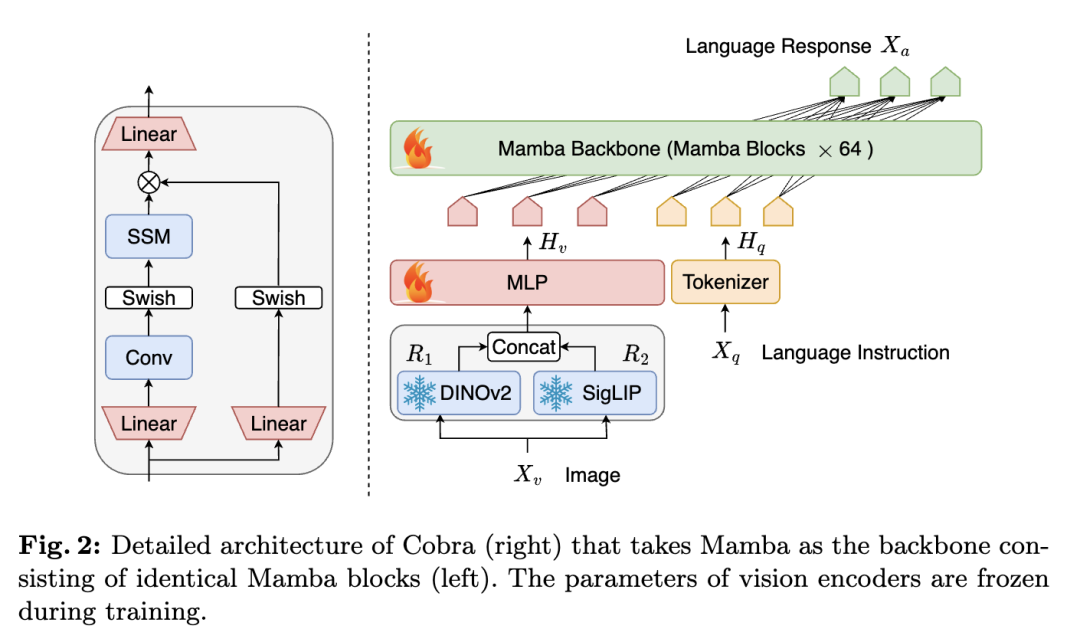
https://jamesyjl.github.io/DreamReward/2.西湖大学新研究:优于Transformer的高效推理近来,多模态大型语言模型(MLLM)已被应用于各个领域。然而,用于许多下游任务的基础模型,目前的 MLLM 都是由 Transformer 网络组成,其二次计算复杂度效率较低。为了提高基础模型的效率,西湖大学团队提出了线性计算复杂度 MLLM—Cobra,将高效的 Mamba 语言模型整合到了视觉模式中。此外,他们也探索和研究了各种模态融合方案,从而创建有效的多模态 Mamba。大量实验证明:Cobra 与当前计算效率最高的方法 LLaVA-Phi、TinyLLaVA 和 MobileVLM v2 相比,性能极具竞争力,而且由于 Cobra 采用线性顺序建模,速度更快;有趣的是,封闭集挑战性预测基准测试结果表明,Cobra 在克服视觉错觉和空间关系判断方面表现出色;值得注意的是,Cobra 甚至只用了约 43% 的参数数量就实现了与 LLaVA 相当的性能。论文链接:
https://arxiv.org/abs/2403.14520项目地址:
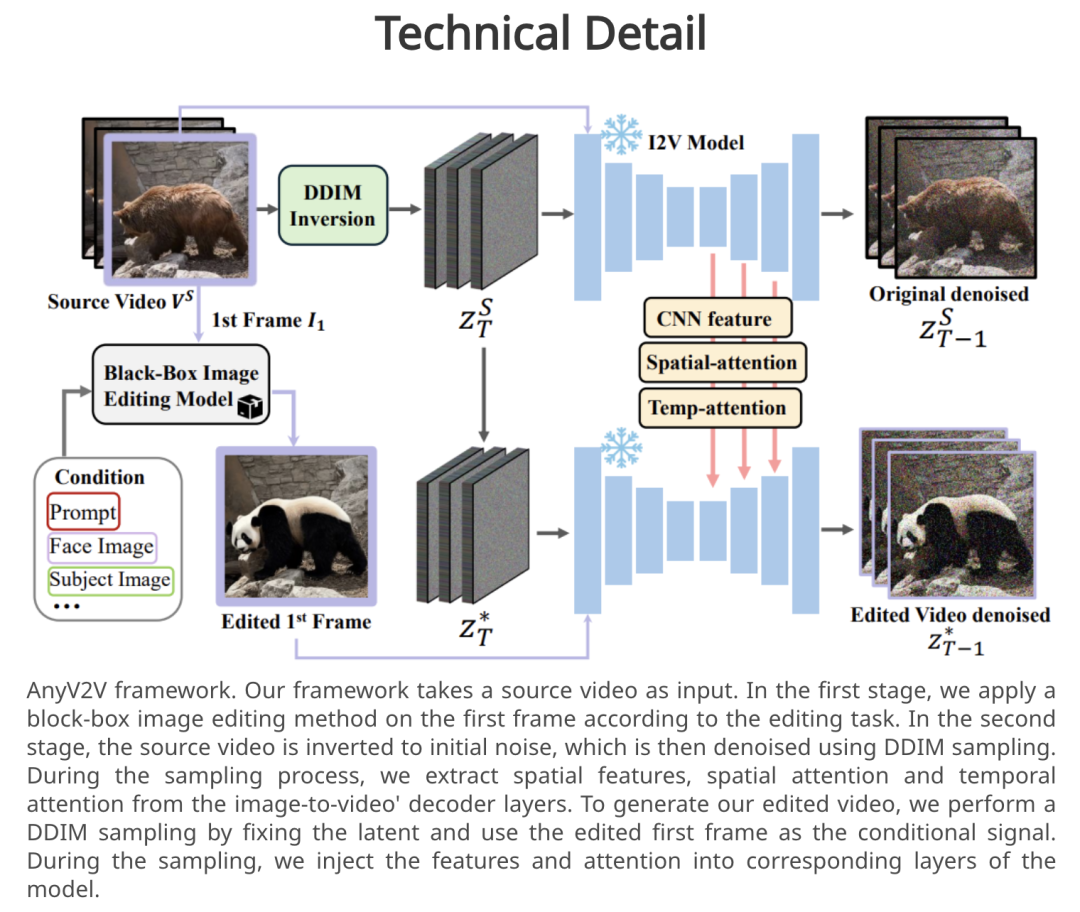
https://sites.google.com/view/cobravlm3.AnyV2V:即插即用,轻松完成任何视频到视频编辑任务视频到视频编辑包括编辑源视频和附加控件(如文本提示、主题或样式),从而生成与源视频和所提供控件一致的新视频。然而,传统方法局限于某些编辑类型,限制了其满足用户广泛需求的能力。来自滑铁卢大学、Vector Institute 和 Harmony.AI 的研究团队,提出了一种新型免训练框架 AnyV2V,从而将视频编辑简化为了两个主要步骤:(1)利用现有的图像编辑模型(如 InstructPix2Pix、InstantID 等)修改第一帧;(3)利用现有的图像视频生成模型(如 I2VGen-XL)进行 DDIM 反转和特征注入。在第一阶段,AnyV2V 可以插入任何现有的图像编辑工具,从而支持多个视频编辑任务。除了传统的基于提示的编辑方法外,AnyV2V 还可以支持视频编辑任务,包括基于参考的风格转换、主题驱动编辑和身份处理。在第二阶段,AnyV2V 可以插入任何现有的图像视频模型,执行 DDIM 反转和中间特征注入,从而保持与源视频的外观和运动一致性。在基于提示的编辑方面,AnyV2V 在提示对齐方面比之前的最佳方法高出 35%,在人类偏好方面比之前的最佳方法高出 25%。结果显示,AnyV2V 在三项新任务中也取得了很高的成功率。此外,AnyV2V 也具有很好的通用性,能够无缝集成快速发展的图像编辑方法,从而满足用户的不同需求。论文链接:
https://arxiv.org/abs/2403.14468
项目地址:
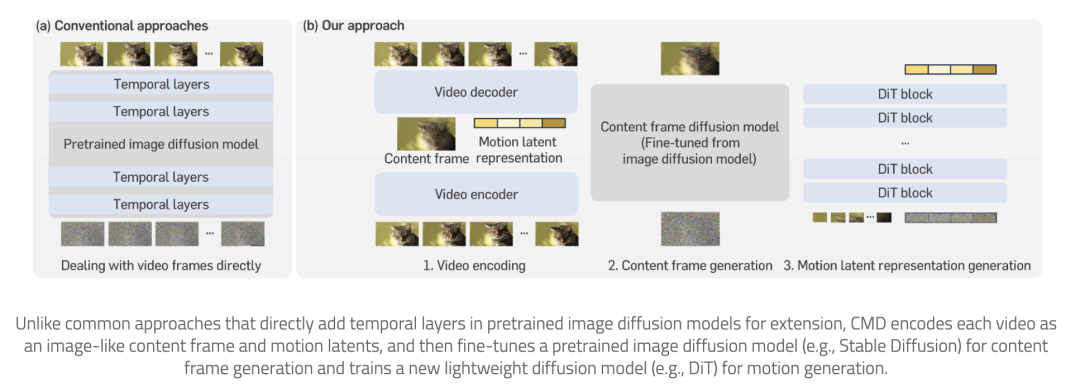
https://tiger-ai-lab.github.io/AnyV2V/近来,视频扩散模型在生成质量方面取得了很大进步,但仍受限于高内存和计算要求。这是因为当前的视频扩散模型通常试图直接处理高维视频。为了解决这一问题,来自韩国科学技术院、英伟达和加州理工学院的研究团队提出了内容-运动潜在扩散模型(CMD),其为预训练图像扩散模型在视频生成方面的新型高效扩展。具体来说,他们提出了一种自动编码器,可将视频简洁地编码为内容帧(如图像)和低维运动潜表示的组合。前者代表视频中的普通内容,后者代表视频中的潜在运动。他们通过微调预先训练好的图像扩散模型来生成内容帧,并通过训练新的轻量级扩散模型来生成运动潜表征。该工作的关键创新是设计了一个紧凑的潜空间,可以直接利用预训练的图像扩散模型。结果表明,该研究大大提高了生成质量,降低了计算成本。例如,通过在 3.1 秒内生成分辨率为 512×1024 长度为 16 的视频,CMD 的视频采样速度比之前的方法快 7.7 倍。此外,CMD 在 WebVid-10M 上的 FVD 得分为 212.7,比之前最高分 292.4 分高出 27.3%。论文链接:
https://arxiv.org/abs/2403.14148
项目地址:
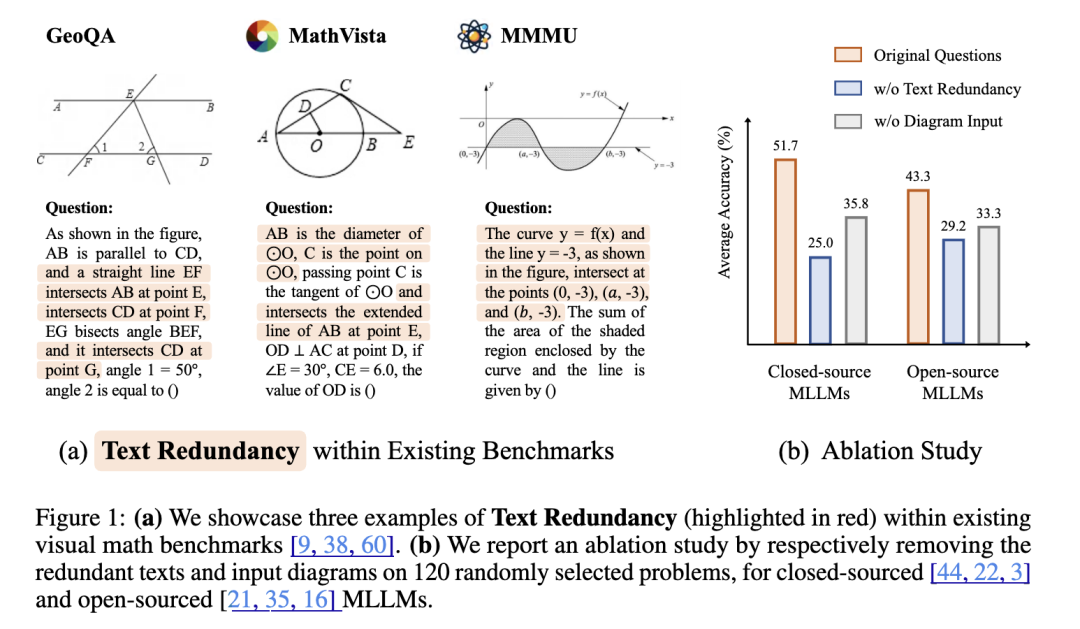
https://sihyun.me/CMD/5.MathVerse:多模态语言模型真的懂数学图表吗?尽管多模态大型语言模型(MLLMs)在视觉环境中展现出了强大的能力,但在视觉数学解题中的能力仍未得到充分评估和理解。为了对 MLLMs 进行公平、深入的评估,来自香港中文大学、上海人工智能实验室和加州理工大学洛杉矶分校的研究团队,提出了一个全方位的可视化数学基准 MathVerse。据介绍,他们从公开资料中精心收集了 2612 个高质量、多主题、带图表的数学问题。然后,每个问题都会被人类注释者转换成六个不同的版本,每个版本都提供了不同程度的多模态信息内容,共计有 15000 个测试样本。通过这种方法,MathVerse 可以全面评估 MLLM 是否以及在多大程度上能够真正理解用于数学推理的可视化图表。此外,为了对输出答案进行精细评估,他们还提出了一种思维链(CoT)评估策略。他们采用 GPT-4(V) 来自适应地提取关键推理步骤,然后通过详细的错误分析对每个步骤进行评分,从而揭示 MLLM 的中间 CoT 推理质量,而不是判断真假。论文链接:
https://arxiv.org/abs/2403.14624
项目地址:
https://mathverse-cuhk.github.io/
内容中包含的图片若涉及版权问题,请及时与我们联系删除




评论
沙发等你来抢