
复旦大学数据智能与社会计算实验室
Fudan DISC
Debatrix:大模型驱动的多角度辩论评审
Demo 地址:
https://debatrix.hzmc.xyz:8123/
GitHub 地址:
arXiv 地址:
https://arxiv.org/abs/2403.08010
1
研究背景
辩论自古以来就是不同人群之间分析问题、交换意见并达成共识的重要形式。在竞技辩论和许多政治辩论中,通常只有获胜一方的观点会被采纳,因此一方面,辩论者必须运用各种策略说服听众支持自己一侧,另一方面,衡量哪一方的发言更有说服力同样至关重要。
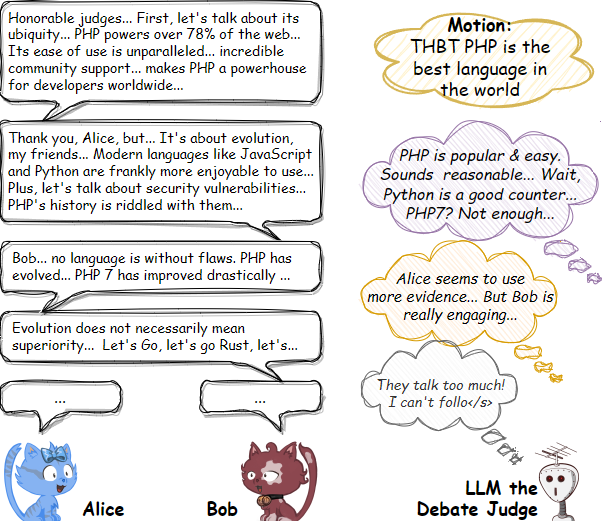
如图,一位大模型辩论评委正在评判 Alice 和 Bob 之间的辩论。大模型需要了解双方的论点以及它们如何相互反驳(紫色气泡);大模型还需要从多个维度评估双方的发言(橙色气泡)。然而,多轮辩论通常时间较长,会分散大模型的注意力,甚至超出上下文窗口(浅灰色气泡)。
2
研究贡献
在目前主流大语言模型的基础上,我们提出了Debatrix 框架,使多回合辩论的分析和评估更符合多数听众的偏好。具体来说,Debatrix 一方面纵向地、迭代地按照时间顺序分析辩论中的每轮发言,另一方面横向地在多个维度下分析辩论过程,并最终将各个维度的分析结果聚合为一个多维度综合分析。
3
Demo 展示
一对一网络辩论(及 Demo 功能展示)
英国议会式辩论(二对二辩论,2020 欧辩赛 1/4 决赛)
4
Debatrix:框架设计
我们提出的 Debatrix 是一个基于大模型的细粒度自动辩论评判框架,它可以按照时间轴和维度轴对辩论评价任务进行细分。
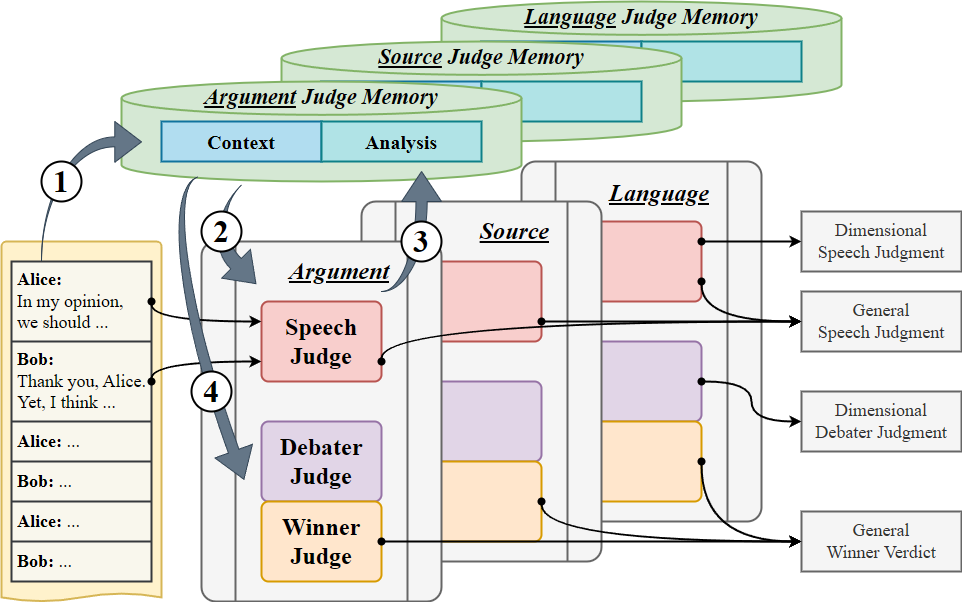
时间轴:迭代发言分析
我们引导大模型对辩论发言逐一进行分析,通过记忆系统维护到目前为止的发言流和分析流,并在分析新发言时提供先前所有发言的内容分析。在处理完所有发言后,大模型会根据所有发言的分析结果做出最终决定。这种迭代方法可让大模型一次只专注于一轮发言,更高效、高质量地了解其内容与上下文。它还能对每轮发言、每位辩手做出细粒度的反馈,或决定辩论的最终获胜者。
维度轴:多维度协作分析
在分析每轮发言过程中,Debatrix 还可以让大模型专注于特定的评判维度,如论证水平、语言风格或反驳力度。每个维度下,大模型都可以就这些特定的维度发表评论。辩论结束后,所有这些单独的分析都会合并成一个总体评价,从而提供综合多个维度的系统性辩论评判结果。
5
PanelBench:数据集
DebateArt
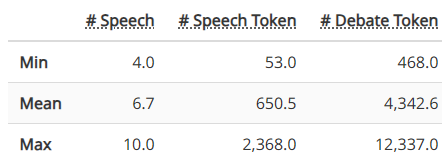
DebateArt 辩论集的长度统计
在 DebateArt 平台上,投票者必须考虑并投票决定四项指标,以获得比较表现的见解:论点(argument)、论据(source)、可读性(legibility)和行为(conduct)。为了与口语辩论保持一致,我们将可读性和行为这两个维度合并为一个语言(language)维度,代表辩手的语言风格。

DebateArt 辩论集的获胜者统计;较小的 D2G RMSE 表明该维度的投票结果更接近最终不分维度的投票结果
BP-Competition
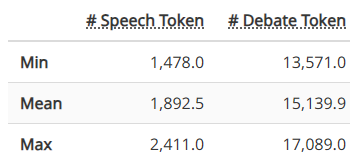
BP-Competition 辩论集包括从世界级辩论比赛中转录的 22 场辩论。这些辩论遵循英国议会式(BP)辩论形式,由四支队伍(正反方各两队)参加,为 PanelBench 提供了内容丰富且复杂的高质量样本。
在 BP 辩论中,四支队伍(OG、OO、CG 和 CO)被分为正反两方,但每支队伍在辩论中都要与其他三支队伍(包括本方的另一支队伍)竞争。PanelBench 要求评判四支队伍中哪支队伍最优秀。有些 BP 辩论的获胜者不止一个;PanelBench 将预测任何获胜队伍视为正确。
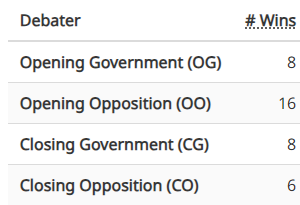
BP-Competition 辩论集的获胜者统计;总和大于 22 是由于胜者不唯一
6
实验结果
得分比较:比较所有辩手的得分;对于来源和语言,得分差异在 ±3 以内的为平局。 直接预测:直接预测获胜者。
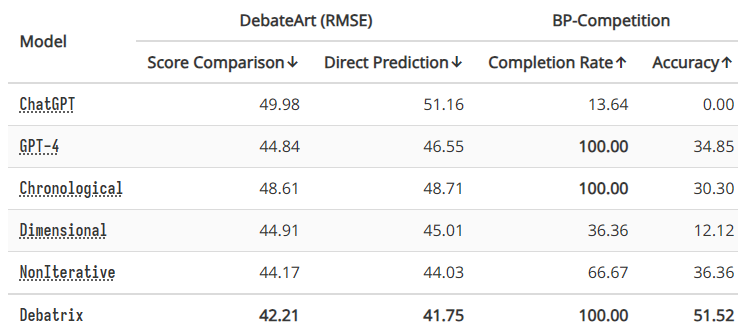
实验结果表明,迭代发言分析对于 ChatGPT 处理超长辩论至关重要。同时,维度协作也有利于处理较短的辩论。不过,将两者结合起来会产生更好的性能。最后,通过迭代使用之前的内容分析,Debatrix 在两个辩论集上的表现优于所有基线模型,包括能力更强大的 GPT-4。
多轮辩论与长辩论
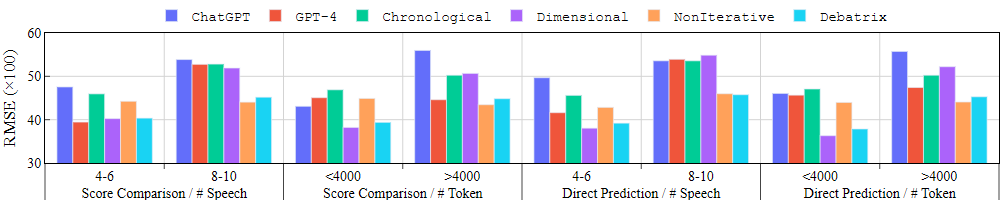
DebateArt 辩论的发言次数和长度各不相同:在所有 100 场辩论中,有 34 场辩论的发言次数不少于 8 次,51 场辩论的发言长度不少于 4000 个 token。一方面,一些基准模型显示出部分优势,但无法覆盖所有情况。另一方面,Debatrix 无论发言的数量或长度如何,都能保持相对较低的 RMSE。这表明,Debatrix 可以有效地帮助 LLM 评估长篇、多回合辩论,同时维持短篇辩论的评价能力。
论点维度分析
在所有评价维度中,论点是影响辩手说服力的主要维度。在 DebateArt 辩论集论点维度上的实验表明,与 ChatGPT 相比,规模更大、功能更强的 GPT-4 在这方面的改进却十分有限。相反,按时间顺序分析每轮发言能带来显著的性能提升;在分析发言时迭代输入过去的内容分析也很有益处。这些方法使 Debatrix 得以更好地理解论点,而无需求助于更大的模型。
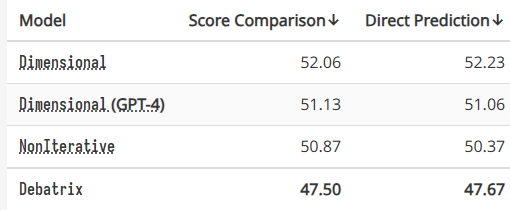
GPT-4 的位置偏差
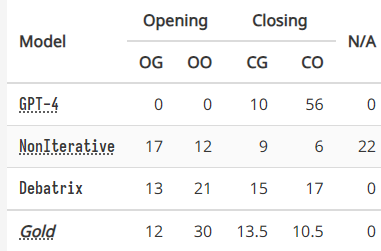
我们推测,位置偏差(position bias)可能是导致 GPT-4 在判断 BP 辩论时失败的一个重要因素:大模型可能更喜欢最后发言的人,因为他可以反驳别人,同时又不会被反驳,因此看起来更有说服力。
7
总结
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disc_imcs@163.com
地址:复旦大学邯郸校区计算中心

点击“阅读原文”体验Debatrix
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢