【新智元导读】UC伯克利的双足机器人,400米直接跑进了2分34秒,这个速度属实是超越不少人类了。而背后的RL通用框架,让它无论是站立,还是跑步、跳高、跳远,动作都十分丝滑。
最近,HYBRID ROBOTICS研究团队的Cassie,给我们来了一段惊艳的表演——随后,它又在不需要额外训练的情况下,完成了1.4米的跳远。是的,相信你已经注意到了,它的外形十分独特——只有下半身!没错,跑步什么的,要上半身干啥。
就是,不知道脚下这双跑鞋有没有速度加成?可以看到,Cassie的跑步姿势十分标准,没有任何累赘的动作。现在,Cassie在做最后的冲刺,它集中精力一鼓作气,一跃而冲过了终点线。在21年,Cassie在中途不充电的条件下,完成了5公里的户外长跑,用时53分钟,这个步速是每分94.3米。Cassie是利用神经网络强化学习进行训练的,因此,它可以从头掌握简单的技能,比如原地跳跃、向前走或跑而不摔倒。最后,团队还测试了Cassie的跳远能力,注意,这是在它没有经过额外训练的情况下。

论文地址:https://arxiv.org/pdf/2401.16889.pdf利用深度强化学习(RL),研究者为双足机器人创建了动态运动控制器。他们开发出了一种通用控制解决方案,可用于一系列动态双足技能,比如周期性行走,跑步,以及非周期性的跳跃和站立。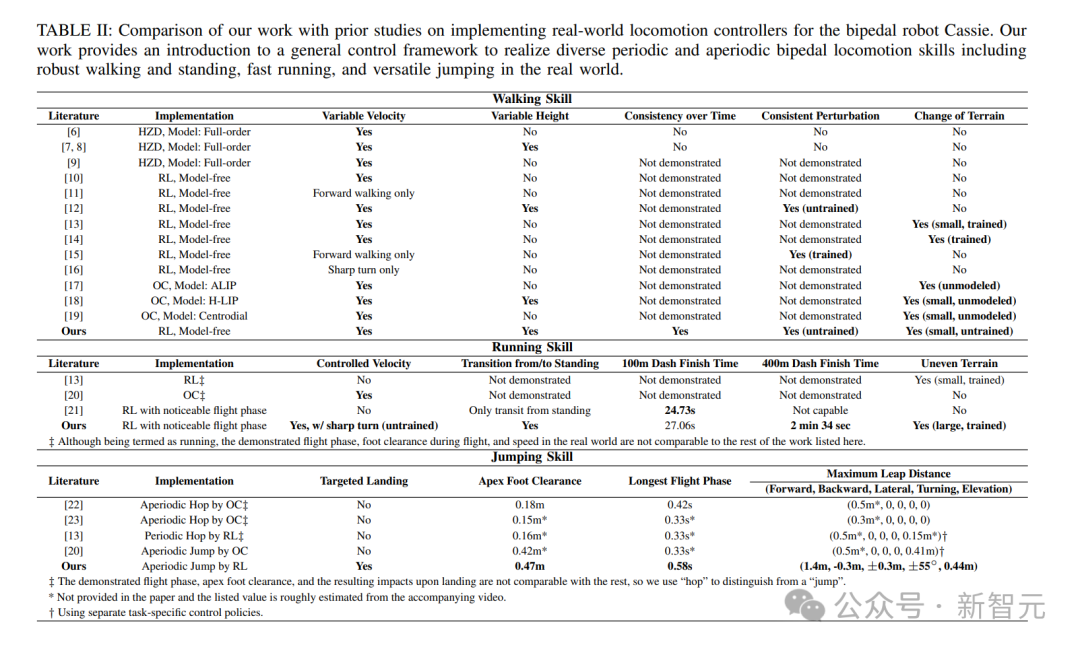
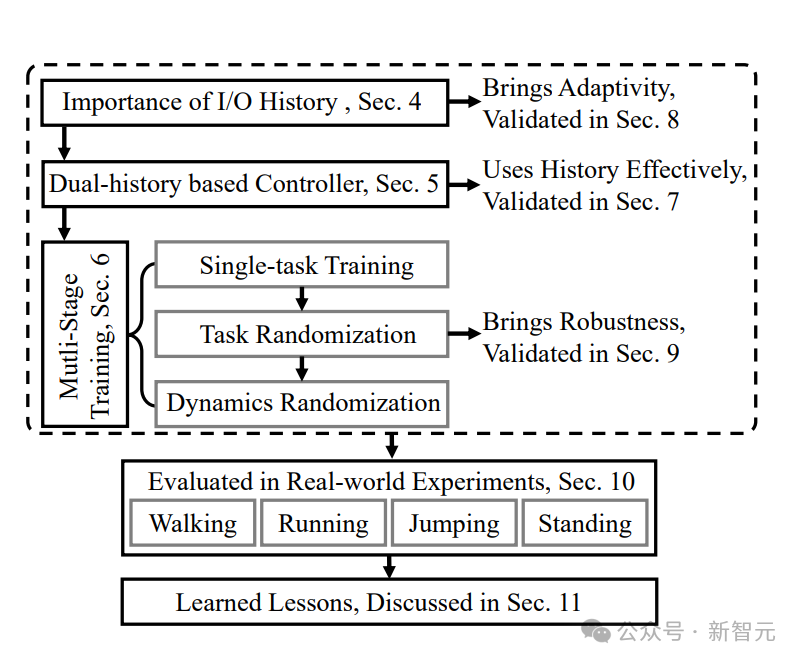
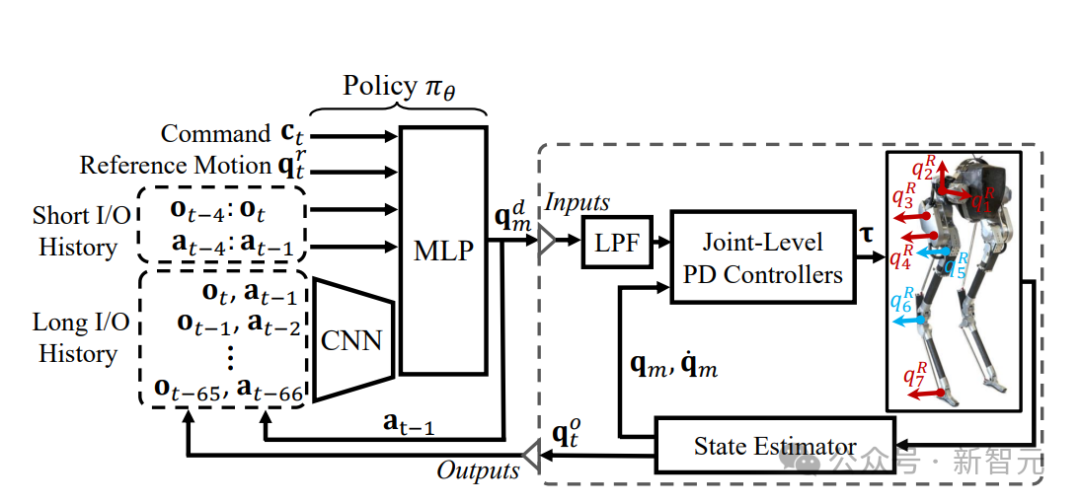
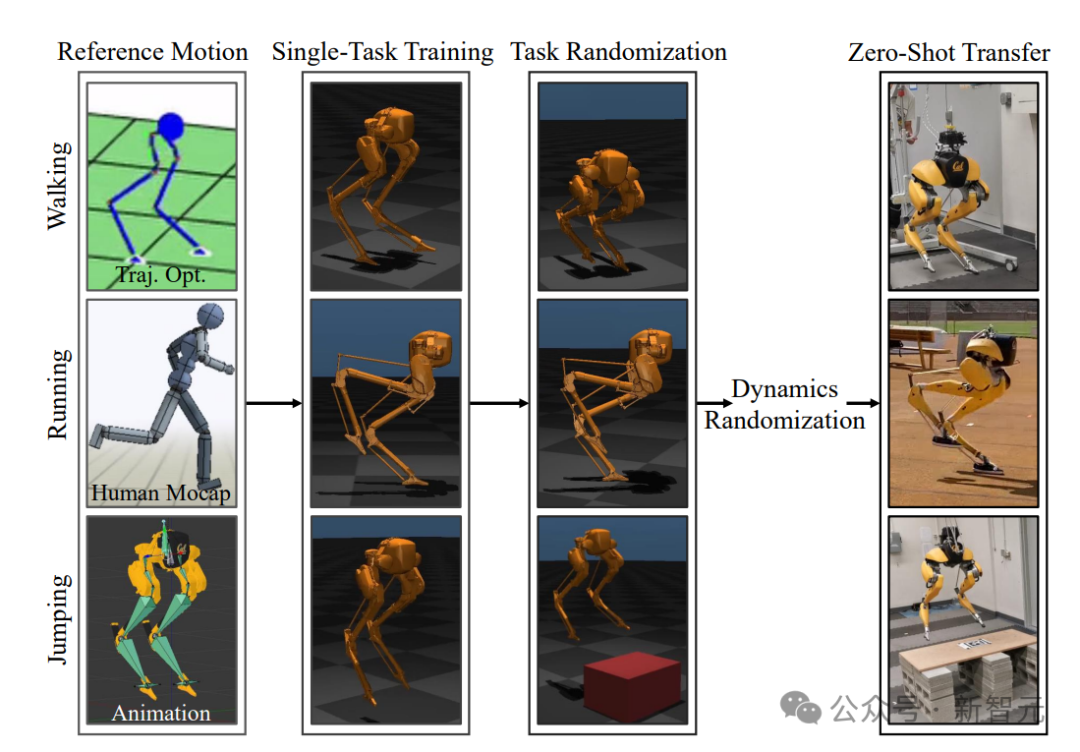
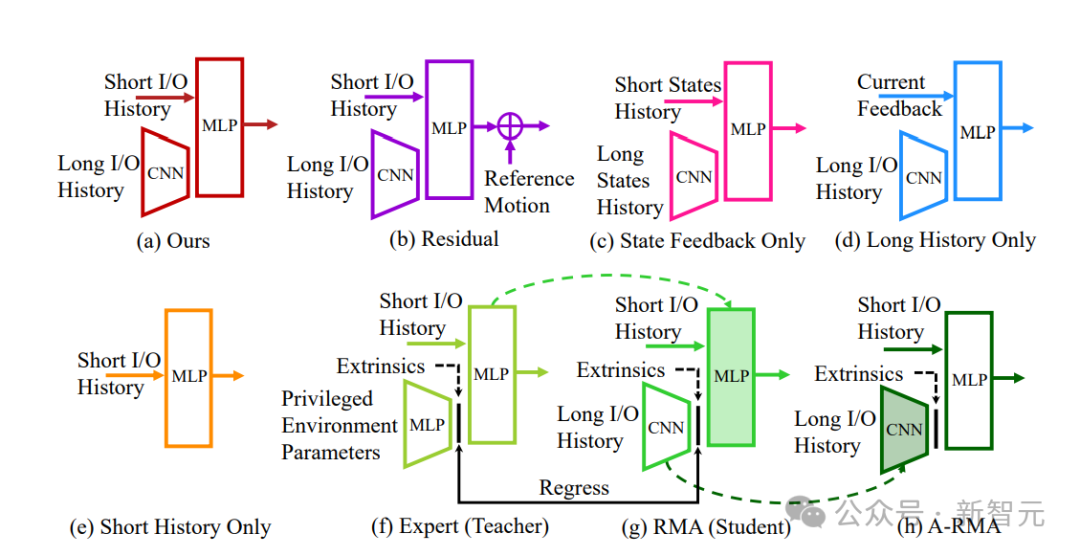
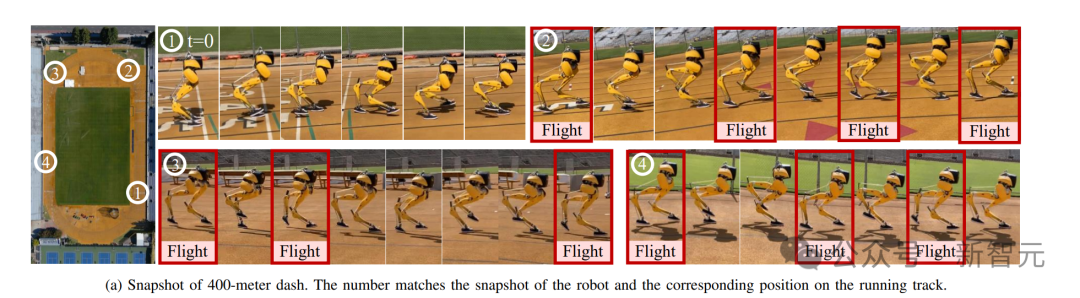
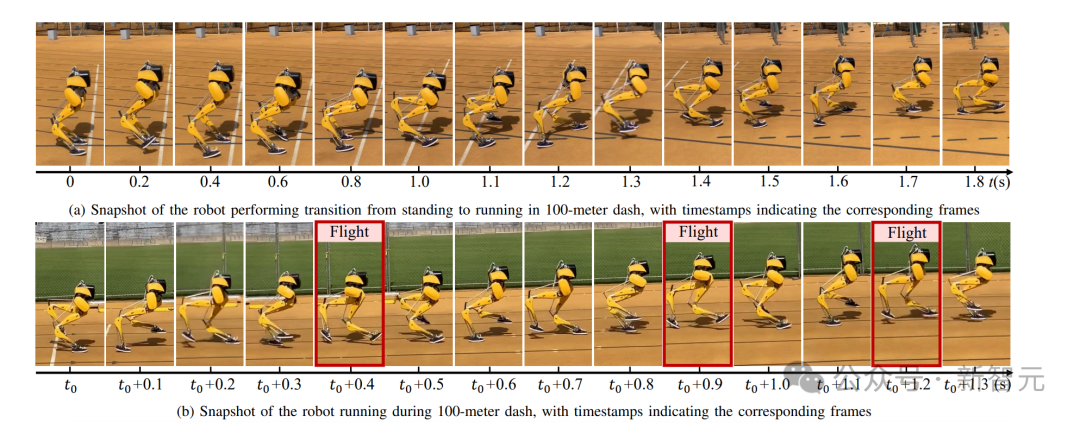
这个通用控制框架,可以实现各种周期性和非周期性的双足运动技能基于强化学习的控制器,他们采用了新颖的双历史架构,利用了机器人的长期和短期输入/输出(I/O)历史。当通过端到端强化学习方法进行训练时,这种控制架构在模拟和现实世界中的各种技能上,都始终优于其他方法。可以证明,通过有效利用机器人的I/O历史记录,架构就可以适应各种变化,如接触事件。因此,我们就看到了Cassie的各种运动技能。比如稳稳地站立,多才多艺地步行,快速跑步,以及各种跳高和跳远。这个研究所基于RL的控制器架构如下图,它利用了机器人的输入和输出(I/O)的双重历史记录。利用这个多阶段的训练框架,就可以获得零样本转移到现实世界的通用控制策略。如下是基于RL的双足机器人运动控制策略架构各种基线的图示。利用研究者开发的多功能跑步策略,Cassie成功完成了400米冲刺。它使得机器人能够从站立姿势转变为平均2.15m/s和峰值3.54m/s的快速跑步步态。使用微调的跑步策略,Cssie还以快速的跑步步态完成了100米短跑。
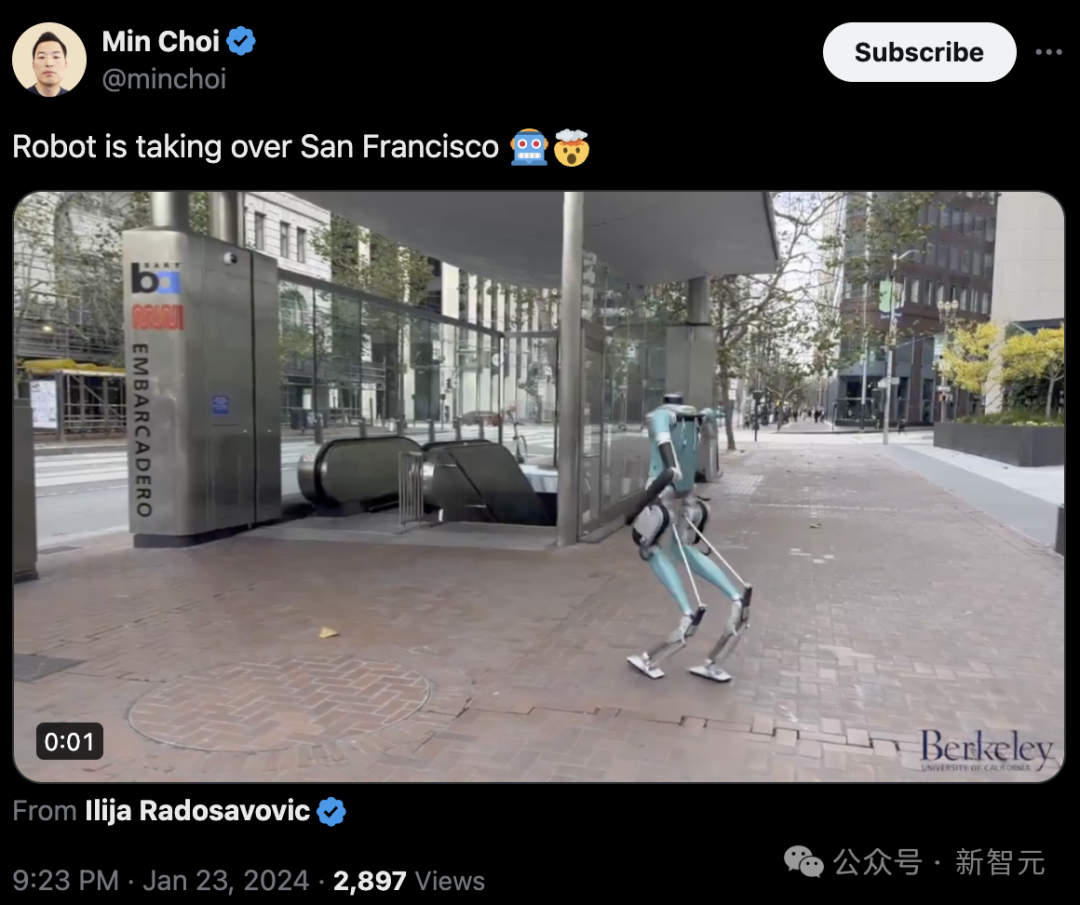
机器人接管旧金山?
在今年1月,UC伯克利的人形机器人显眼包「小绿」,就曾经大规模引起了人们的注意。只见它在围观人群的惊叹声中,大摇大摆地走出UC伯克利校门。预测下一个动作,控制人形机器人行走
不久后,就在2月底,UC伯克利就发表了一篇重磅论文,介绍「小绿」是怎么训练出的。
论文地址:https://arxiv.org/pdf/2402.19469.pdf在这篇论文中,他们介绍了训练人形机器人的方法——跟训练GPT的方法是一样的。用这种训练GPT的方法,研究者成功地训练出了人形机器人的类人运动。重点就是:通过预测下一个动作,来控制人形机器人的行走。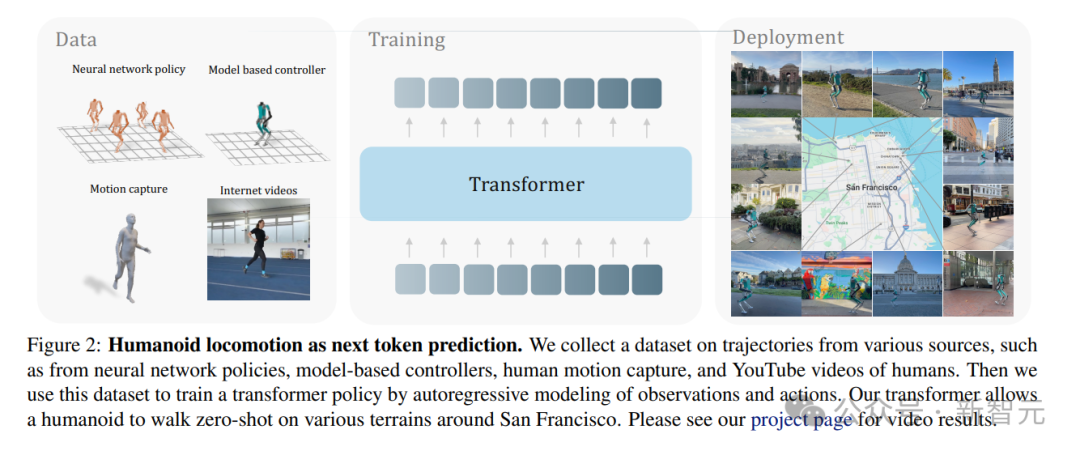
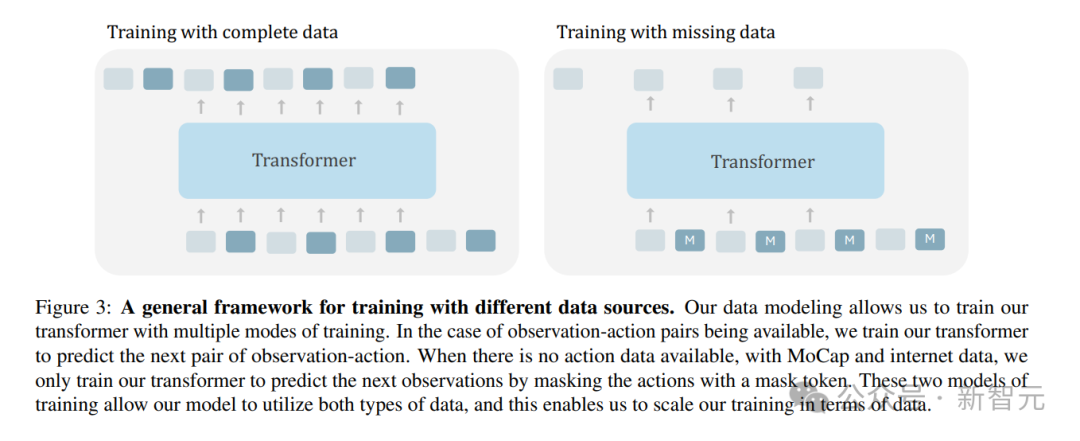
人形机器人所学习的,就是基于模型的控制器、动捕数据和YouTube上的人类视频。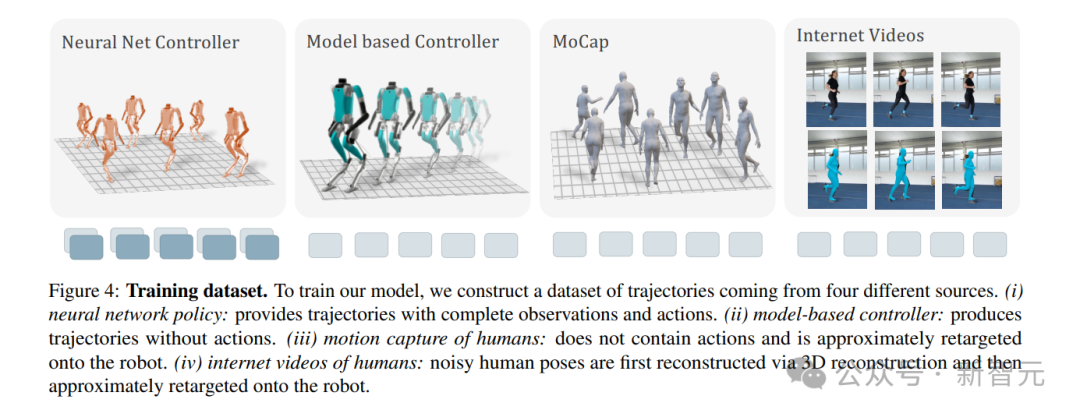
结果,这个模型能让全尺寸的人形机器人在完全未经训练的情况下,直接完成行走!仅仅用了27个小时的训练,模型就能在现实世界中泛化了。https://arxiv.org/abs/2402.19469https://arxiv.org/abs/2401.16889
内容中包含的图片若涉及版权问题,请及时与我们联系删除










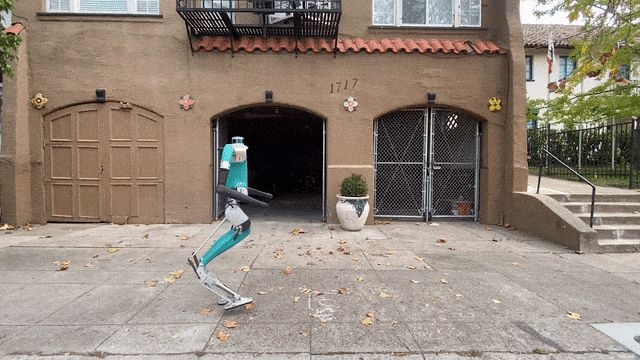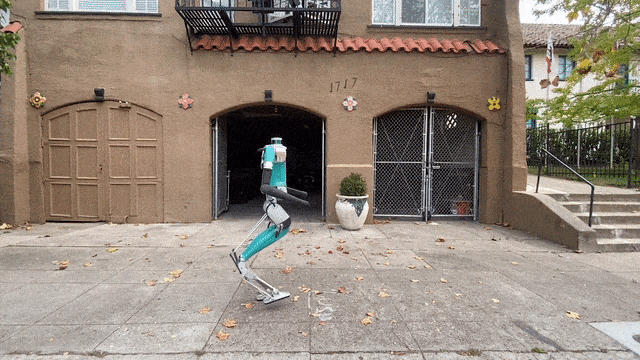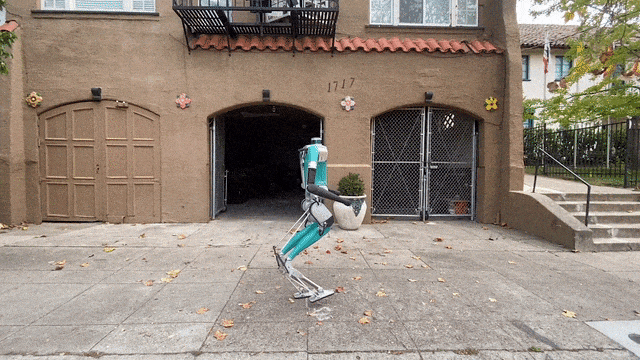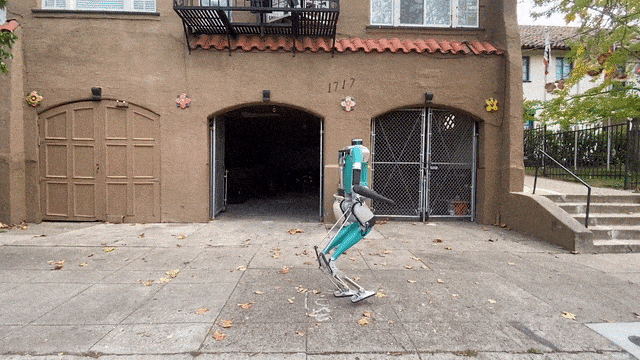





评论
沙发等你来抢