
今天为大家介绍的是来自Yaochu Jin团队的一篇论文。进化算法在解决多目标优化问题(MOPs)方面取得了成功。然而,作为一类基于群体的搜索方法,进化算法需要大量的目标函数评估,这阻碍了它们在一系列成本高昂的多目标优化问题上的应用。为了解决上述挑战,作者首次提出了一个能够学习执行进化多目标搜索的扩散模型,称为EmoDM。

近期,生成式扩散模型(DMs)在多个应用领域展现出了卓越的性能,包括图像合成、分子图建模和材料设计。这些扩散模型擅长模拟复杂数据集,并生成高质量的样本来执行多种任务。到目前为止,关于使用扩散模型进行优化的工作还不多,只有少数例外。例如,Graikos提出通过将旅行商问题(TSP)的解视为灰度图像,使用基于图像的扩散模型来解决TSP。与之前的想法不同,作者提出了一种用于进化多目标优化但不需要进化过程的扩散模型,称为EmoDM。主要思想是从以往的进化搜索过程中,使用扩散模型学习进化搜索能力。一旦在一系列多目标优化问题上训练完成,EmoDM就可以从随机生成的解开始,为任何新的多目标优化问题近似一组帕累托最优解,而无需额外的进化搜索,从而显著减少目标函数评估。
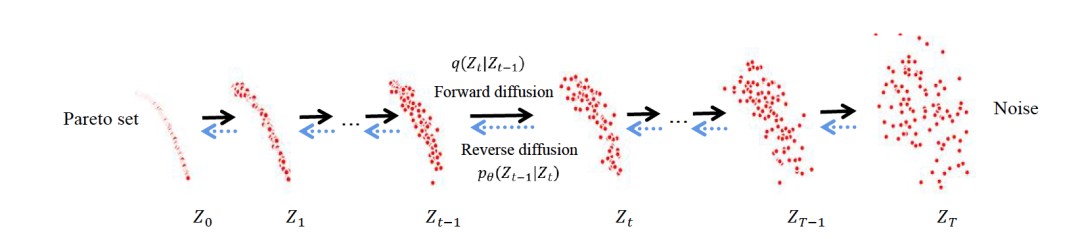
图 1
EmoDM的前向和逆向扩散的示例图(图1),其中Zt代表在步骤t的解决方案群体。前向扩散是逆向的进化搜索过程,即,ZT是进化搜索中的初始群体,通常是随机生成的,ZT-1是第二代,而Z0是最终代。在训练EmoDM时,作者使用连续的进化搜索解决方案(例如,Zt和Zt-1)来估计噪声分布。相比之下,逆向扩散可以视为前向的进化搜索过程,从一个随机生成的群体开始,最终会得到一组帕累托最优解。
多目标优化
一般而言,无约束的多目标优化问题(MOP)可以表达如下:
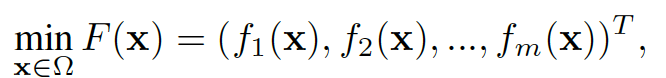
其中 x = (x₁, x₂, ..., x_d) 表示 d 个决策变量在搜索空间 Ω,m 表示优化目标的数量,fᵢ(x) 是第 i 个(i = 1, 2, ..., m)目标函数。在非平凡场景中,决策变量经常表现出相互依赖性,目标之间通常呈现出冲突。具体来说,不存在一个单一解决方案能够同时最小化所有目标。因此,优化一个 MOP 的目标是要在其搜索空间内获得一组帕累托最优解。对于两个解 x₁, x₂ ∈ Ω, 如果 x₁ 支配 x₂,当且仅当 fᵢ(x₁) ≤ fᵢ(x₂) 对所有 i ∈ {1, 2, ..., m},且至少存在一个 j ∈ {1, 2, ..., m} 使得 fⱼ(x₁) < fⱼ(x₂)。只有在不存在任何 x₂ ∈ Ω 支配它的情况下,x₁ 才是一个帕累托最优解。帕累托解决方案的整个集合在目标空间中被称为帕累托前沿(PF)。在多目标优化中我们的目标是紧密地近似并且均匀覆盖 MOP 的 PF。
方法部分
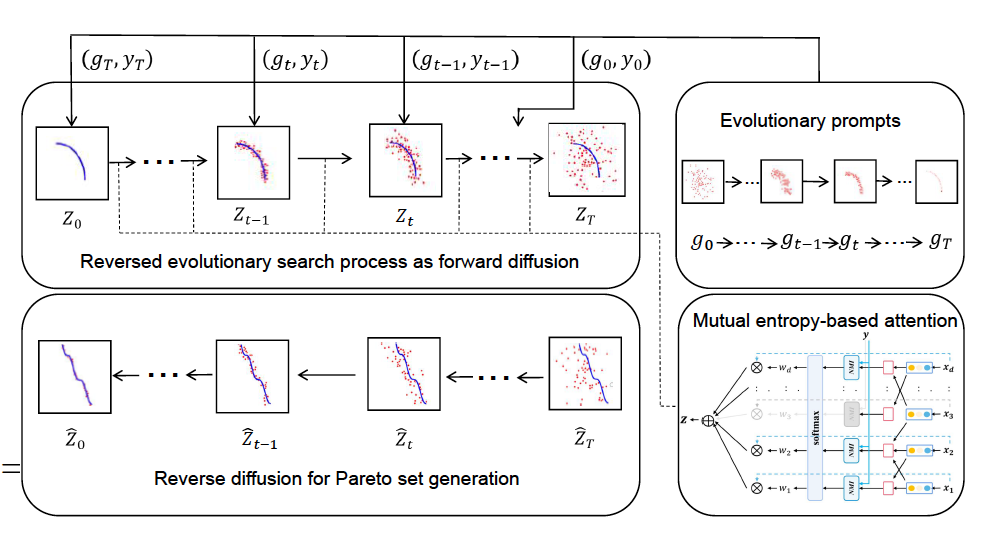
图 2
作者所提出的EmoDM用于多目标优化的总体框架如图2所示。与DDPM类似,EmoDM包括两个阶段,一个是前向扩散,它学习从收敛的最终群体到随机初始化群体的逆进化搜索,另一个是逆向扩散,它从随机生成的初始群体开始近似一个帕累托集。如先前工作所解释的,可以利用马尔可夫链来模拟多目标优化中的进化搜索动态。因此,给定输入数据Z0,即由MOEA找到的MOP的帕累托解集合,可以利用进化提示,即两个连续种群的解(g_t, y_t)来逐步估计噪声数据,其中g_t代表第(T − t)代用于在第t步生成样本Z_t的种群数据。y_t = (f1(g_t), f2(g_t), ... f_m(g_t))代表当前种群的m个目标函数。EmoDM中的总步骤数(T)等于进化优化的总代数。将进化提示与基于互信息熵的注意力机制整合在一起,后者提取重要的潜在搜索维度,模型可以通过在每个给定样本上训练前向扩散模型来估计两个连续步骤之间的多变量噪声分布。在决策变量和目标之间的互信息熵差异的指导下,模型可以在逆向扩散中为新的MOP重建帕累托集,其中通过迭代减少多变量噪声的影响来实现采样。
实验部分
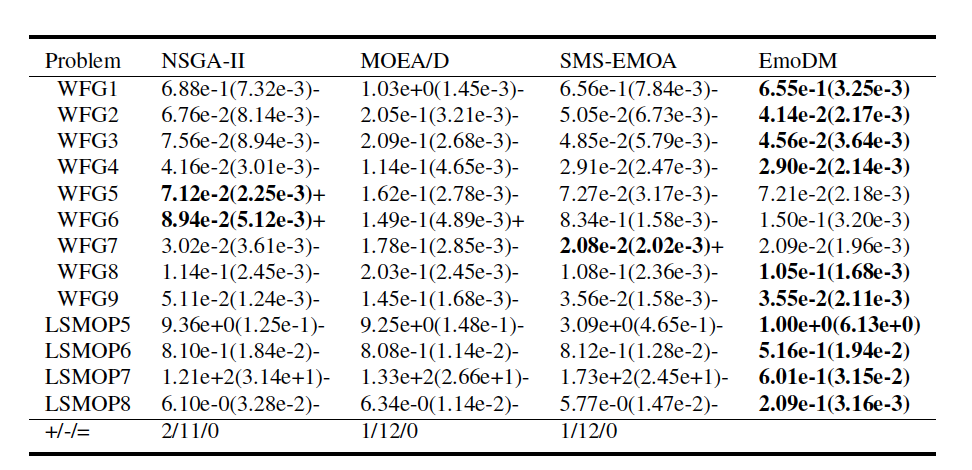
表 1
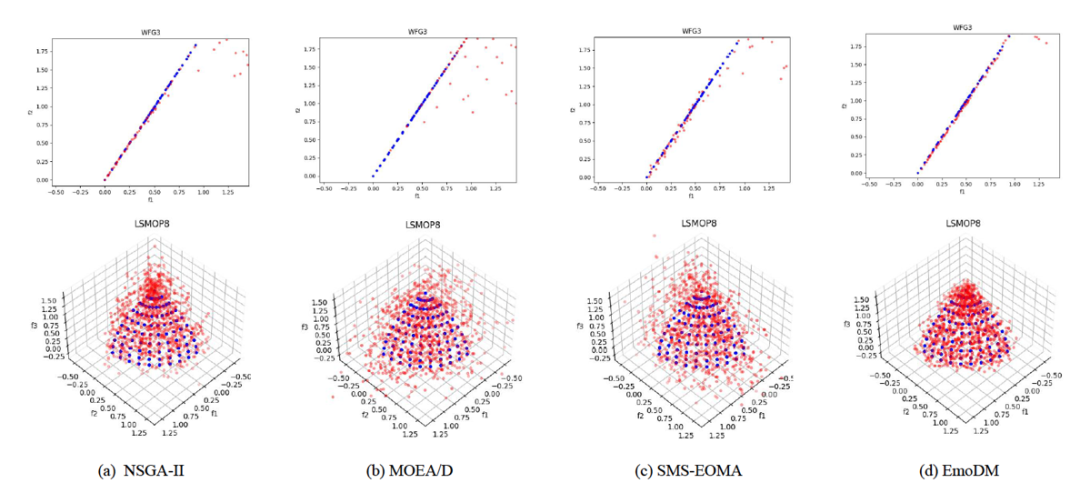
图 3
表1展示了2目标WFG实例和3目标四个LSMOP实例的平均IGD值。为了与MOEAs(多目标进化算法)的设置一致,作者也对EmoDM进行了30次独立运行,以在每个MOP实例上生成帕累托集。在表中,每个实例上表现最好的结果以粗体突出显示。符号“+”、“−”和“=”分别表示与EmoDM相比,对应方法在解决MOP实例方面的IGD性能更好、更差或相当。与NSGA-II、MOEA/D和SMS-EOMA这三种流行且具有代表性的MOEAs相比,如表1所示,EmoDM在平均IGD值方面表现出极具前景的性能。在总共13个测试实例中,EmoDM在10个实例上取得了最佳IGD结果,其次是NSGA-II在2个实例上取得最佳结果,SMS-EOMA在1个实例上取得最佳结果。分别在11个、12个和12个测试实例上,EmoDM显著优于NSGA-II、MOEA/D和SMS-EOMA。值得注意的是,在所有LSMOP测试实例中,EmoDM在IGD方面的表现都是最好的。这些结果相当令人惊讶,因为EmoDM的搜索能力是从NSGA-II中学习来的。这可能归因于EmoDM在多个实例上进行了训练,隐式的知识转移帮助提高了其在新实例上的搜索性能。作者还在图3中展示了比较中的四种算法在2目标WFG3和3目标LSMOP8上获得的近似帕累托前沿,其中绘制了30次运行中的最佳结果。这些结果确认了EmoDM的收敛性能。
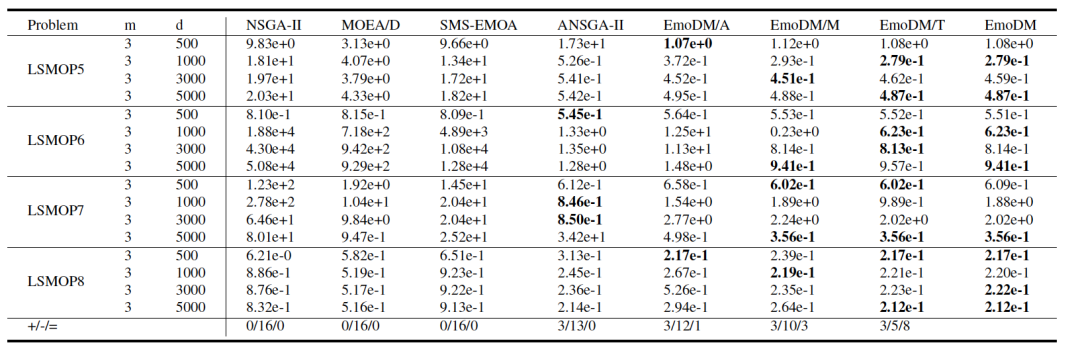
表 2
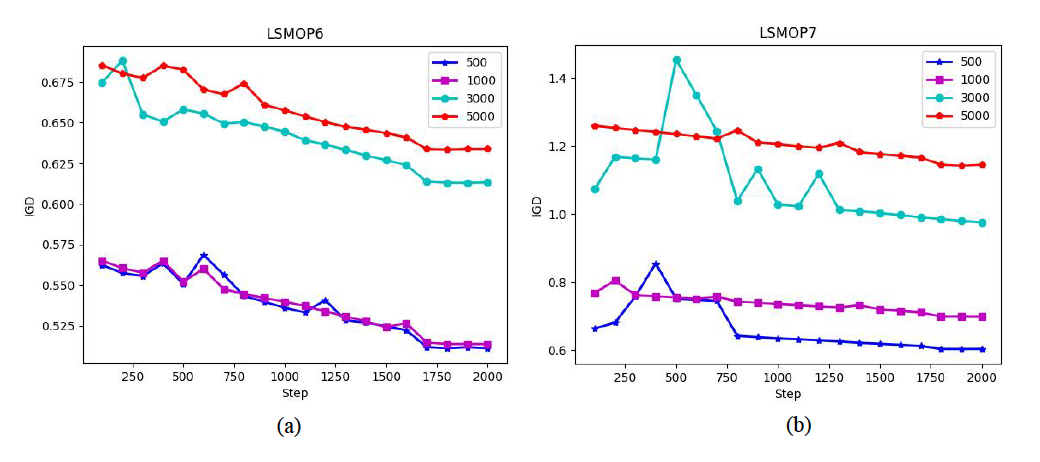
图 4
在第二组实验中,作者加入了一种用于大规模MOPs的实验,名为ANSGA-II,比较的是搜索维度从500到5000的LSMOP实例。除了EmoDM,还考虑了三种EmoDM的变体,即EmoDM/A、EmoDM/M和EmoDM/T,以检验EmoDM中注意力机制的效果以及训练数据的影响。EmoDM/A是没有基于互信息熵注意力机制的EmoDM变体。EmoDM/M是使用由三种MOEAs(即NSGA-II、MOEA/D和SMS-EMOA)平等贡献的进化提示训练的EmoDM。最后,EmoDM/T是由原始训练数据加上测试实例的提示训练的EmoDM,即当在LSMOPs 5-8实例上测试时,NSGA-II在优化LSMOPs 1-8实例时生成的提示。表2展示了四种MOEAs、EmoDM及其三个变体在不同搜索维度的LSMOP5-LSMOP8实例上获得的最佳IGD结果。从表2可以观察到,与NSGA-II、MOEA/D、SMS-EMOA相比,EmoDM在16个案例中的13个案例中获得了最佳IGD值,仅在三个实例中被ANSGA-II超越。因此可以得出结论,当搜索维度增加到5000时,EmoDM在解决MOPs时仍然有效。与其三个变体相比,EmoDM在14个案例中的8个案例中取得了最佳结果。相比之下,EmoDM/A获得了两个最佳结果,EmoDM/M获得了五个最佳结果,EmoDM/T获得了八个最佳结果。EmoDM/T略微优于EmoDM的事实似乎是合理的,因为EmoDM/T在训练中已经看到了测试问题。然而,值得注意的是,即使EmoDM/M的进化提示涉及到来自三种MOEAs的搜索过程,它也无法胜过EmoDM。这可能意味着同时学习不同MOEAs的搜索动态并没有好处。有趣的是,当维度增加到5000时,EmoDM在四个实例上取得了最佳IGD值。图4描绘了EmoDM在LSMOP6和LSMOP7上生成帕累托集的IGD曲线,有500、1000、3000和5000个决策变量,展示了EmoDM的搜索过程。如图4所示,虽然在早期步骤中有波动,但EmoDM的学习曲线通常是收敛的。这主要归因于在EmoDM的逆扩散过程中采用基于互信息熵的抽样策略,这使其能够适应LSMOP7的搜索行为。
编译 | 曾全晨
审稿 | 王建民
参考资料
Yan, X., & Jin, Y. (2024). EmoDM: A Diffusion Model for Evolutionary Multi-objective Optimization. arXiv preprint arXiv:2401.15931.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢