


关键词
Graph Neural Networks
Generative AI
Representation Learning
导 读
VQGraph: 重新审视图表示学习
将Graph空间Token化
GNN-to-MLP distillation旨在利用知识蒸馏(KD)通过模拟teacher GNN的输出表示来学习计算高效的多层感知器(student MLP)用于图数据。现有方法主要使MLP模仿GNN对少量类别标签的预测。然而,类别空间可能不足以覆盖众多不同的局部图结构,从而限制了从GNN到MLP的知识迁移的性能。为解决这一问题,我们提出通过直接标记节点的多样局部结构来学习新的强大图表示空间用于GNN-to-MLP蒸馏。具体来说,我们提出了VQ-VAE的变体在图数据上学习一个结构感知的标记器,该标记器可以将每个节点的局部子结构编码为离散化语义token。如下图所示
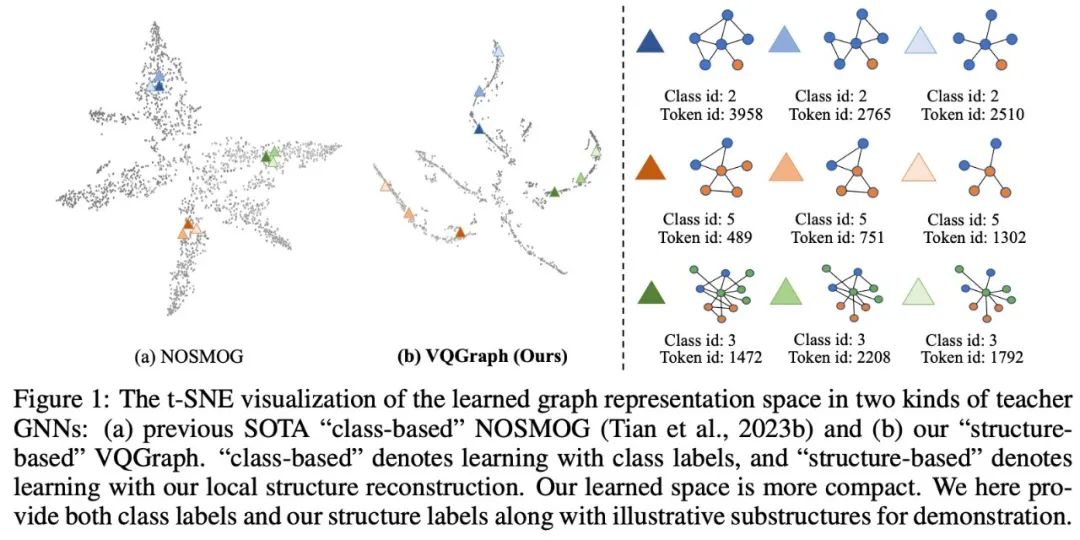
这些token构成了一个代码簿(codebook),作为一个新的图表示空间,能够识别具有相应代码索引的节点的不同局部图结构。然后,基于学习的codebook,我们提出了一种新的蒸馏目标,即soft code assignments,以直接将每个节点的结构知识从GNN传输到MLP。由此产生的框架VQGraph在跨七个图数据集的传导和归纳设置中实现了新的最先进性能。我们展示了VQGraph比GNN快828倍,并且分别比GNN和独立的MLP平均提高了3.90%和28.05%的准确率。
论文链接:
https://openreview.net/forum?id=h6Tz85BqRI
代码链接:
https://github.com/YangLing0818/VQGraph
VQGraph 的 训 练 流 程
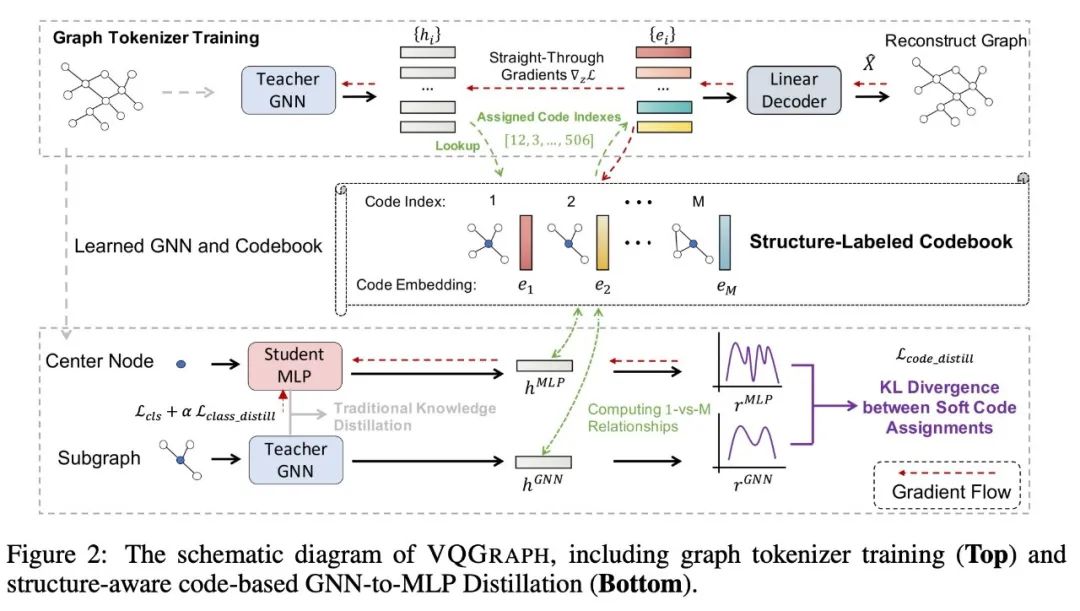
VQGraph的训练流程包含两个阶段:
01
第一阶段
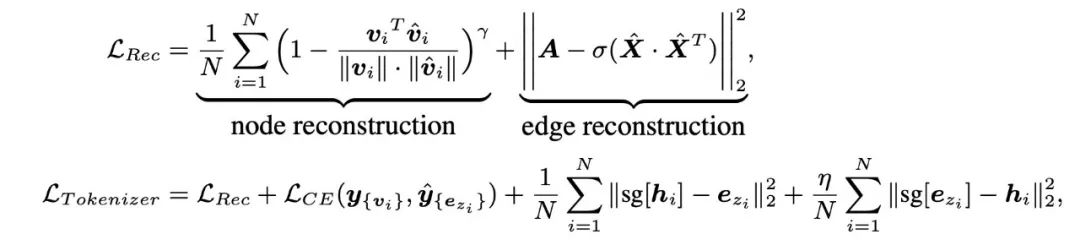
首先是Graph Tokenizer Training,该阶段是为了在graph空间里学习一个包含不同局部字结构信息的codebook,即码本。码本中的每一个token是一个向量,并有唯一的index去代表它。码本学习的同时,teacher GNN也会同时进行学习。该阶段训练好坏的判断标准是将学到的token分配到不同graph node上之后,能否解码重构原有的图结构信息(所有node和edge)。我们在decoder部分的设计非常简单,就是普通的MLP结构。这样设计的初衷是,如果解码器设计过于强大,那么模型的重构就会过分依赖解码器,那样就得不到很好的具有表达力的码本空间。
第一阶段训练目标函数:
02
第二阶段
第二部分是基于学习得到的teacher GNN和codebook,进行GNN-to-MLP训练。相比较之前的蒸馏方法,我们不仅让MLP去模仿GNN的类别预测或者特征,我们还让MLP去模仿GNN上每个node的token分布情况。这样的蒸馏过程能更好地让MLP学习到GNN中的局部结构信息,分类也会更准确。
第二阶段训练目标函数:
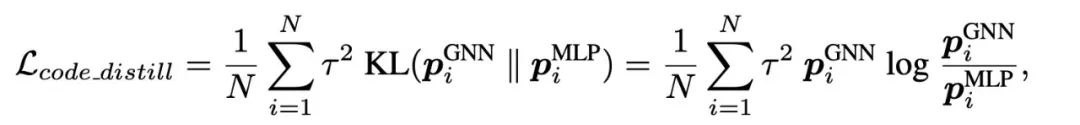
整体框架图:
实 验 分 析
本文通过一系列实验分析验证了VQGraph模型的有效性和泛化性。在节点分类场景下,VQGraph蒸馏得到的MLP分类效果在所有数据集上(包含大规模图数据)超越了之前的蒸馏方法,包括teacher GNN的表现,这是因为我们新提出的基于codebook的图表征空间比之前更加有效。
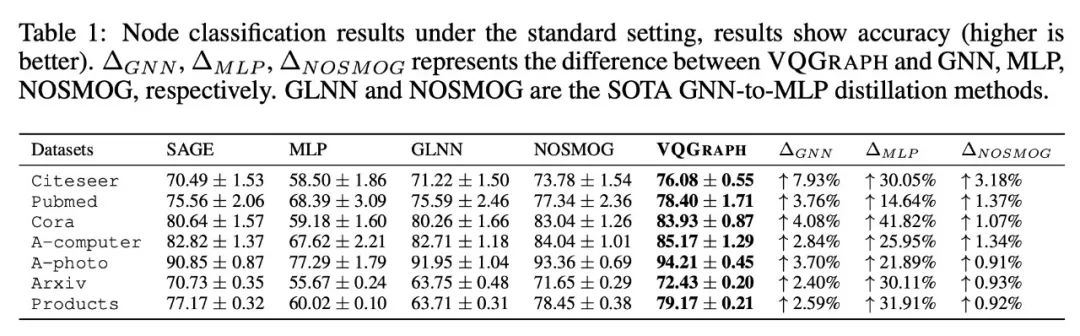
在工业级场景下,VQGraph也是相比之前的方法取得了全面的领先:
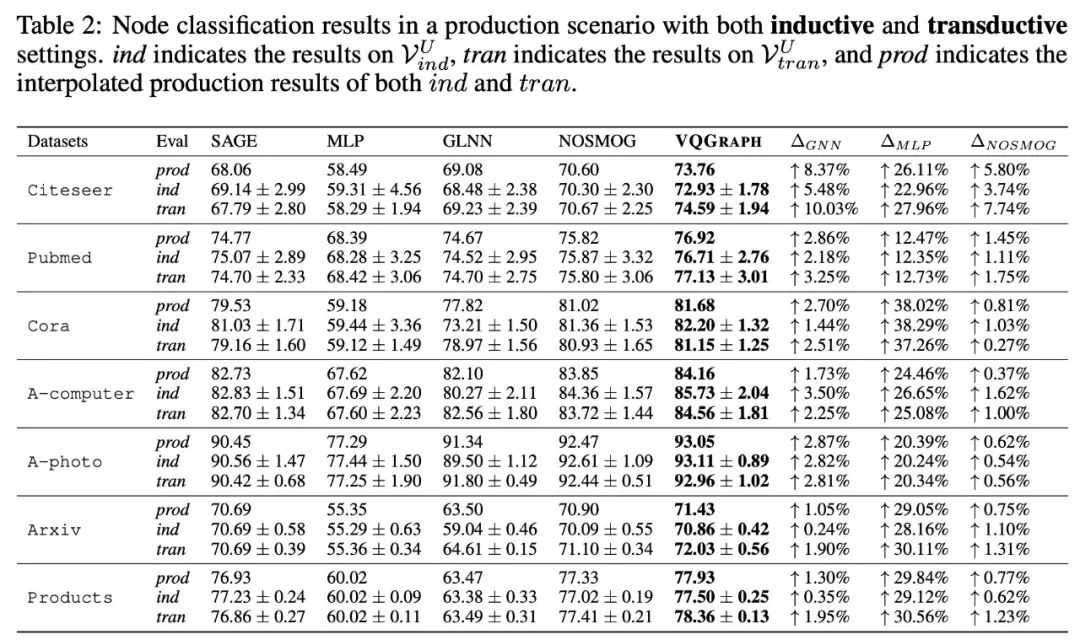
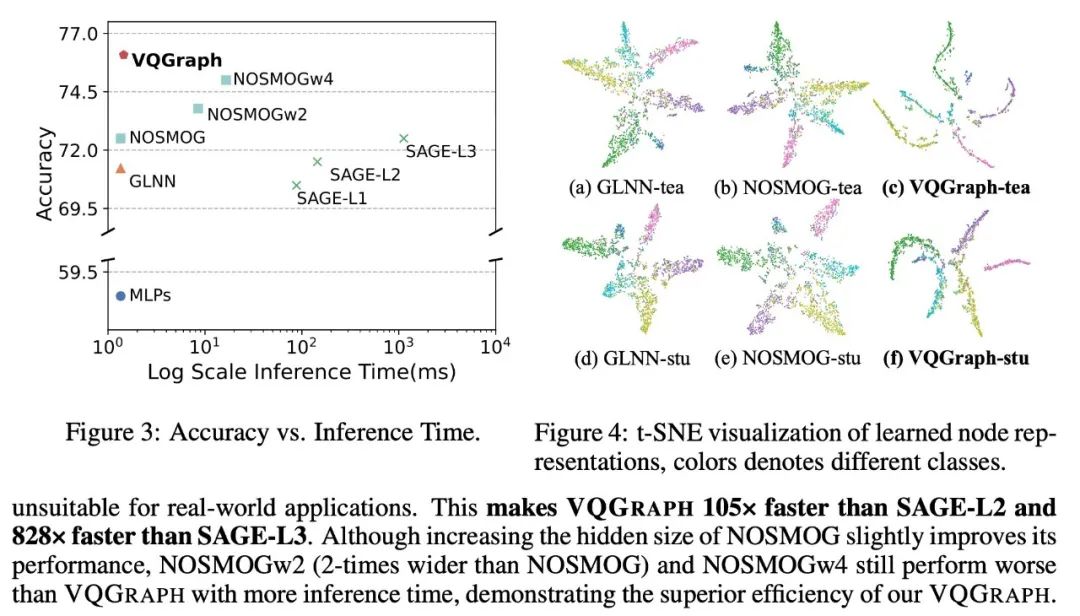
我们对VQGraph的inference-accuracy之间的trade-off以及特征空间可视化都进行了探索。可以发现,我们蒸馏得到的graph MLP在速度、精度以及表达性上都要优于之前的方法。
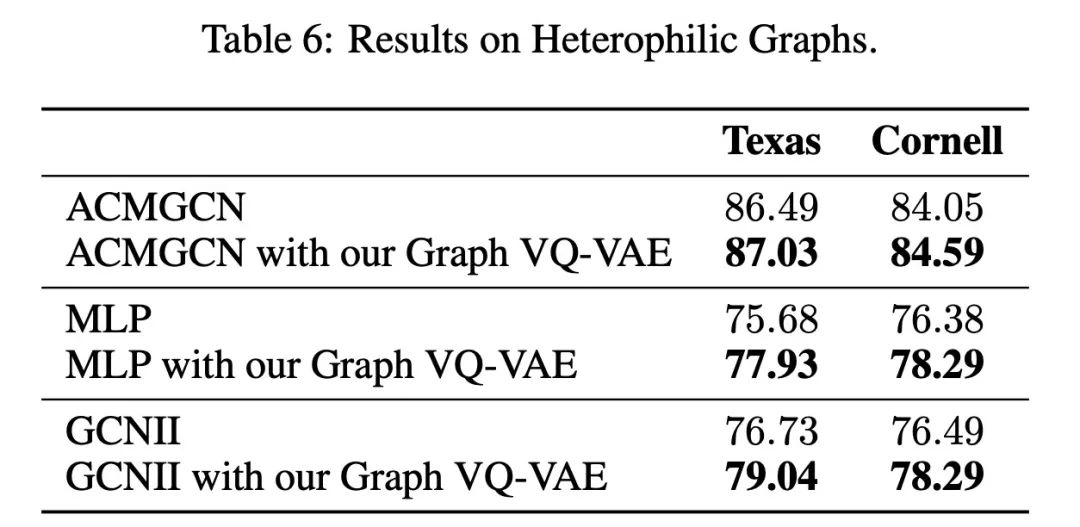
最后我们还把VQGraph扩展到异构图数据,发现我们新提出的图表征空间依然能提升现有方法的效果,说明局部结构信息的显式化表达确实能够增强不同类型图数据分类场景下的表现。
总 结
在这篇论文中,我们通过为节点的多样化局部子结构学习新的图表征空间-codebook,以及利用codebook促进结构感知的 GNN 到 MLP 蒸馏,改进了现有图表示空间的表达能力。对七个数据集进行的广泛实验表明,我们的VQGraph可以显著提高 GNN 的性能,平均准确率提升 3.90%,提高 MLP 的性能达到 28.05%,提高了最先进的 GNN 到 MLP 蒸馏方法的性能达到 1.39%,同时与 GNN 相比保持了快速的推理速度,为 828 倍。此外,我们还提供了额外的可视化和统计分析,以及消融实验,以证明所提出模型的优越性。在拓展到异构图上的实验中,我们还发现了VQGraph强大的泛化性以及在更多复杂图数据集上进行应用的可能性。
详细了解本工作,请访问下方链接地址:
论文链接:
https://openreview.net/forum?id=h6Tz85BqRI
References:
[1] Sami Abu-El-Haija, Bryan Perozzi, Amol Kapoor, Nazanin Alipourfard, Kristina Lerman, Hrayr Harutyunyan, Greg Ver Steeg, and Aram Galstyan. Mixhop: Higher-order graph convolutional architectures via sparsified neighborhood mixing. In international conference on machine learning, pp. 21–29. PMLR, 2019.
[2] Yoshua Bengio, Nicholas Leonard, and Aaron Courville. Estimating or propagating gradients ´ through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432, 2013.
[3] Filippo Maria Bianchi, Daniele Grattarola, and Cesare Alippi. Mincut pooling in graph neural networks. 2019.
[4] Aleksandar Bojchevski, Johannes Gasteiger, Bryan Perozzi, Amol Kapoor, Martin Blais, Benedek Rozemberczki, Michal Lukasik, and Stephan G ´ unnemann. Scaling graph neural networks with ¨ approximate pagerank. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 2464–2473, 2020.
[5] H Bunke and G Allermann. Inexact graph matching for structural pattern recognition. Pattern Recognition Letters, 1(4):245–253, 1983. ISSN 0167-8655.
[6] Jianfei Chen, Jun Zhu, and Le Song. Stochastic training of graph convolutional networks with variance reduction. In International Conference on Machine Learning, pp. 942–950. PMLR, 2018a.
[7] Jie Chen, Tengfei Ma, and Cao Xiao. Fastgcn: Fast learning with graph convolutional networks via importance sampling. In International Conference on Learning Representations, 2018b.
[8] Ling Yang and Shenda Hong. Omni-granular ego-semantic propagation for self-supervised graph representation learning. In International Conference on Machine Learning, pp. 25022–25037. PMLR, 2022.
[9] Ling Yang, Liangliang Li, Zilun Zhang, Xinyu Zhou, Erjin Zhou, and Yu Liu. Dpgn: Distribution propagation graph network for few-shot learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 13390–13399, 2020.
[10] Hongbin Pei, Bingzhe Wei, Kevin Chen-Chuan Chang, Yu Lei, and Bo Yang. Geom-gcn: Geometric graph convolutional networks. In International Conference on Learning Representations, 2020b.
欢迎关注本公众号,帮助您更好地了解北京大学数据与智能实验室(PKU-DAIR),第一时间了解PKU-DAIR实验室的最新成果!
实验室简介
北京大学数据与智能实验室(Data And Intelligence Research Lab at Peking Univeristy,PKU-DAIR实验室)由北京大学计算机学院崔斌教授领导,长期从事数据库系统、大数据管理与分析、人工智能等领域的前沿研究,在理论和技术创新以及系统研发上取得多项成果,已在国际顶级学术会议和期刊发表学术论文100余篇,发布多个开源项目。课题组同学曾数十次获得包括CCF优博、北大优博、微软学者、苹果奖学金、谷歌奖学金等荣誉。PKU-DAIR实验室持续与工业界展开卓有成效的合作,与腾讯、阿里巴巴、苹果、微软、百度、快手、中兴通讯等多家知名企业开展项目合作和前沿探索,解决实际问题,进行科研成果的转化落地。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢