

新智元报道
新智元报道
【新智元导读】大模型落地并不缺场景,却往往因算力不够遇难题。这家国产平台从今日起,免费送百万token。开发者们不仅可以对20多种开源模型精调,还能用上极具性价比的多元算力。


算力难,有解法了!
目前,无穹Infini-AI已支持了Baichuan2、ChatGLM2、ChatGLM3、ChatGLM3闭源模型、Llama2、Qwen、Qwen1.5系列等共20多个模型,以及AMD、壁仞、寒武纪、燧原、天数智芯、沐曦、摩尔线程、NVIDIA等10余种计算卡,支持多模型与多芯片之间的软硬件联合优化和统一部署。

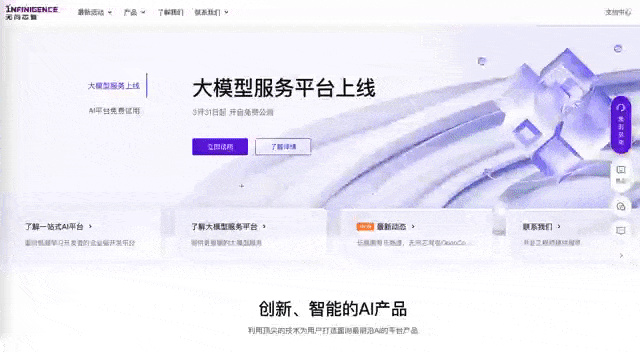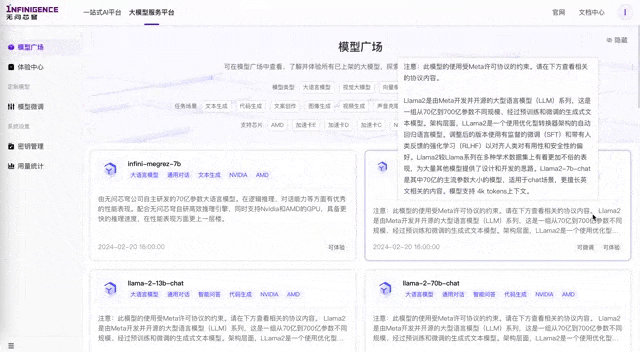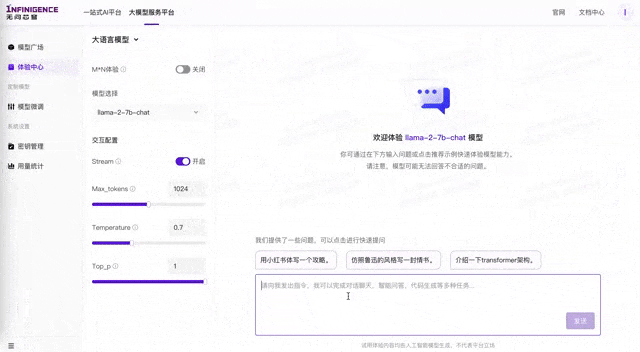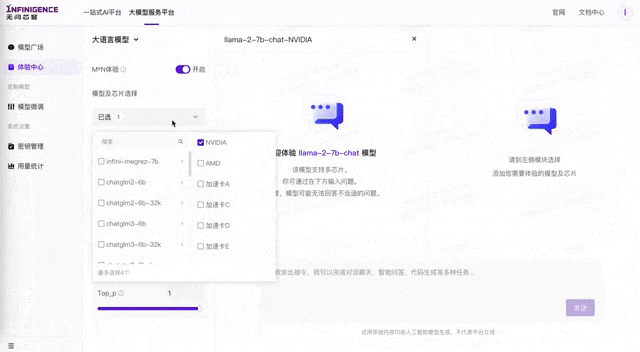


算力性价比大幅提升,源自多芯片优化实力
想在成熟场景中应用大模型的企业,找到了算力但不会用,无法做出差异化的产品实现业务升级。 想创造AI-Native应用的企业,算力成本难负担,工具链也不好用,产品启动投产比不合理。 自行训练模型的企业,随着业务的拓展,往往找不到也买不起所需体量的算力,业务运行成本过高。 截至2023年年末,我国算力总规模达到每秒1.97万亿亿次浮点运算(197E FLOPs),位居全球第二,算力规模近5年年均增速近30%。 如此增速,为何行业内仍然感到算力尤其难? 背后的原因是,人工智能行业发展恰逢工程师人才红利爆发,加速了我国大模型行业的蓬勃发展,需求端「嗷嗷待哺」,而市面上仍存在大量未被收集和充分利用的算力资源,缺少一种足够成体系的「大模型原生」商业模式,将算力供给转化为满足市场需求的产品和服务。 
「市面上有很多未被激活的有效算力,硬件本身差距在快速缩小,但大家在使用时总会遇到『生态问题』。」 夏立雪说,这是因为硬件的迭代速度总是比软件更慢、价格更高,软件开发者不希望工作中出现除自身研发工作之外的其他「变量」,因而总是会倾向于直接使用有成熟生态的芯片。 无问芯穹希望帮助所有做大模型的团队「控制变量」,即在使用无问芯穹的算力服务时,用户不需要也不会感觉到底层算力的品牌差异。 
成立不足一年的无问芯穹,何以能够在这么短时间内跑通多种计算卡上的性能优化?
成立不足一年的无问芯穹,何以能够在这么短时间内跑通多种计算卡上的性能优化?

做「大模型原生」的加速技术栈与系统

Transformer统一了这一轮的模型结构,并且表现出持续取得应用突破的趋势。」
汪玉在开场发言中说:「从前在AI1.0时代我们做上一家公司,只能做很小一部分AI任务。今时不同往日,大模型结构统一了,依靠生态建立起来的硬件壁垒正在『变薄』。」


One More Thing
无问芯穹联合创始人兼首席科学家戴国浩认为,未来,凡是有算力的地方,都会有AGI级别的智能涌现。
而每一个端上的智能来源,就是大模型专用处理器LPU。

大模型处理器LPU可以提升大模型在各种端侧硬件上的能效与速度。
戴国浩在发布会上向观众展示了「一张卡跑大模型」,其团队于今年1月初推出的全球首个基于FPGA的大模型处理器,通过大模型高效压缩的软硬件协同优化技术,使得LLaMA2-7B模型的FPGA部署成本从4块卡减少至1块卡,并且性价比与能效比均高于同等工艺GPU。未来,无问芯穹的端侧大模型专用处理器IP,可以被模块化地集成到各类端侧芯片中。
未来,该IP将被集成于「无穹LPU」。戴国浩宣布,「无穹LPU」将于2025年面世。
「从云到端,我们要将软硬件一体联合优化进行到底。大幅降低大模型在各个场景中的落地成本,让更多好用的AI能力更好、更平价地走进更多人的生活」。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢