【新智元导读】Stability AI推出Stable LM 2 12B模型,作为其新模型系列的进一步升级,该模型基于七种语言的2万亿Token进行训练,拥有更多参数和更强性能,据称在某些基准下能超越Llama 2 70B。
继16亿轻量级Stable LM 2推出之后,12B参数的版本在今天亮相了。见状,不少网友纷纷喊话:干的漂亮!但,Stable Diffusion 3啥时候出啊?总得来说,Stable LM 2 12B参数更多,性能更强。120亿参数版本包含了基础模型和指令微调模型,并在七种多语言,高达2万亿Token数据集上完成训练。在基准测试中,其性能赶超Llama 2 70B等开源模型。官博介绍,最新版本的模型兼顾了性能、效率、内存需求和速度,同时继续采用了Stable LM 2 1.6B模型的框架。通过这次更新,研究人员还为开发者提供了一个透明而强大的工具,以推动AI语言技术的创新。
模型地址:https://huggingface.co/stabilityai/stablelm-2-12bStability AI表示很快就会推出更长的版本,并且可以第一时间在Hugging Face上获取。
Stable LM 2 12B是一个专为处理多种语言任务设计的高效开源模型,它能够在大多数常见硬件上流畅运行。值得一提的是,Stable LM 2 12B可以处理通常只有大模型才能完成的各种任务。比如混合专家模型(MoE),往往需要大量的计算和内存资源。此外,指令微调版本在工具使用,以及函数调用展现出强大的能力,可以适用于各种用途,包括作为检索RAG系统的核心部分。性能评估
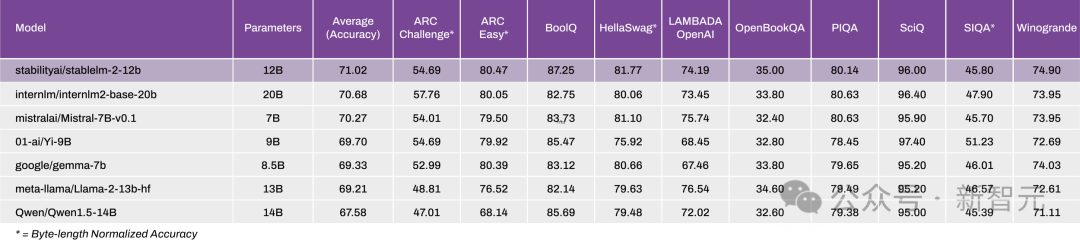
在性能方面,参与对比的有Mixtral(MoE,总共47B/激活13B)、Llama2(13B和70B)、Qwen 1.5(14B)、Gemma(8.5B)和Mistral(7B)。根据Open LLM Leaderboard和最新修正的MT-Bench基准测试的结果显示,Stable LM 2 12B在零样本以及少样本的任务上展现了出色的性能。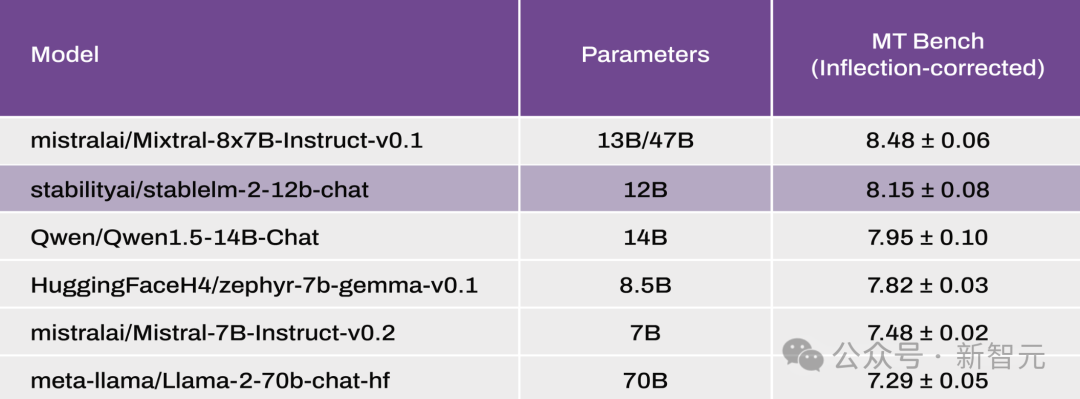
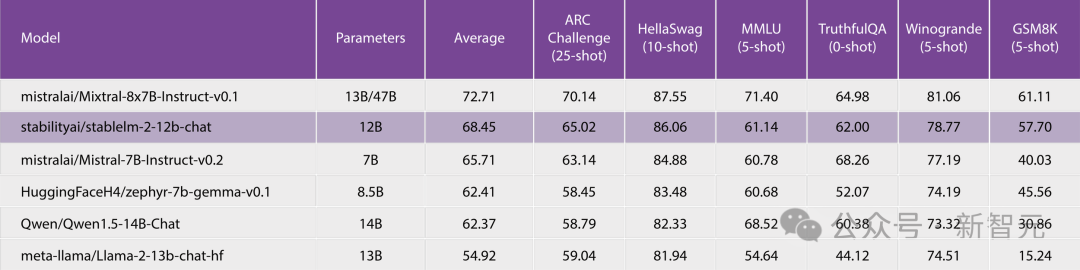
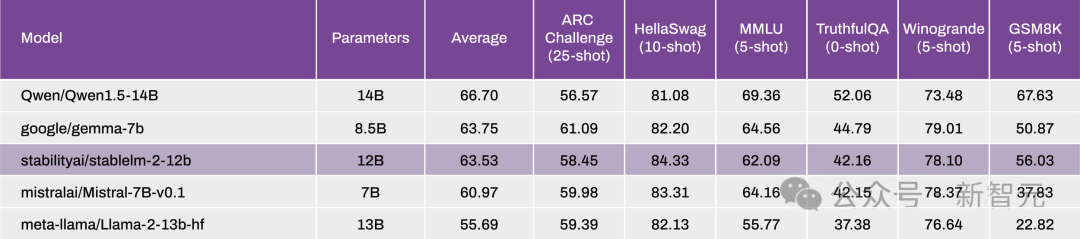
在这个新版本中,他们将StableLM 2系列模型扩展到了12B类别,提供了一个开放、透明的模型,在功率和精度方面丝毫不打折扣。
最初发布的Stable LM 2 1.6B已经在Open LLM 排行榜上取得了领先地位,证明了其在同类产品中的卓越性能。
论文地址:https://arxiv.org/abs/2402.17834模型预训练
训练大模型(LLM)的第一阶段主要是学习如何利用大量不同的数据源来预测序列中的下一个token,这一阶段也被称之为训练。它使模型能够构建适用于基本语言功能甚至更高级的生成和理解任务的通用内部表示。训练
研究人员按照标准的自回归序列建模方法对Stable LM 2进行训练,以预测下一个token。他们从零开始训练模型,上下文长度为4096,受益于FlashAttention-2的高效序列并行优化。训练以BFloat16混合精度进行,同时将all-reduce操作保持在FP32中。数据
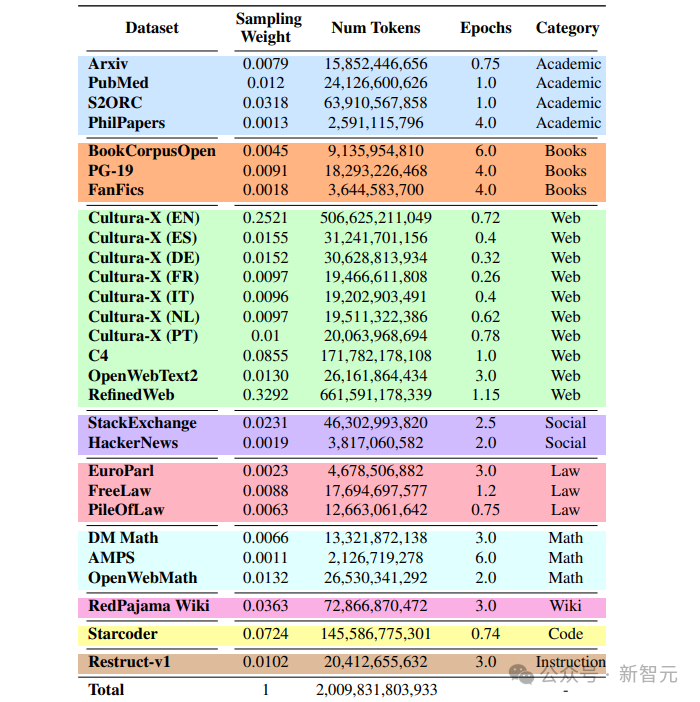
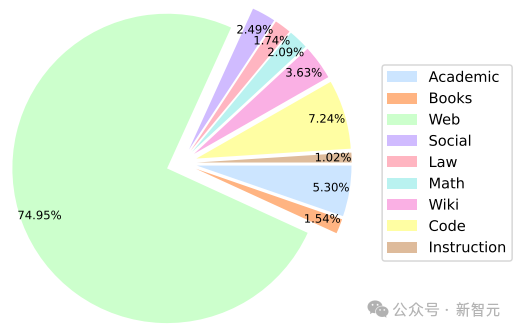
模型性能受训练前数据设计决策的影响,包括源选择和采样权重。训练中所用的数据均为公开数据,大部分训练数据由其他LLM训练中使用的数据源组成,其中包括德语(DE)、西班牙语(ES)、法语(FR)、意大利语(IT)、荷兰语(NL)和葡萄牙语(PT)的多语言数据。仔细选择不同数据域的混合比例至关重要,尤其是非英语数据和代码数据。下图展示了Stable LM 2预训练数据集中各领域有效训练词块的百分比。分词器
研究人员使用了Arcade100k,这是一个从OpenAI的tiktoken.cl100k_base扩展而来的BPE标记器,其中包括用于代码和数字拆分处理的特殊token。词库由100,289个token组成,在训练过程中被填充为最接近的64的倍数(100,352),以满足NVIDIA A100设备上推荐的Tensor Core对齐方式。架构
该模型在设计上与LLaMA架构类似,下表显示了一些关键的架构细节。1. 位置嵌入
旋转位置嵌入应用于头嵌入尺寸的前25%,以提高后续吞吐量2. 归一化
相对于RMSNorm,LayerNorm具有学习偏置项3. 偏置
从前馈网络和多头自注意层中删除了键、查询和值预测以外的所有偏置项。模型微调
有监督微调(SFT)
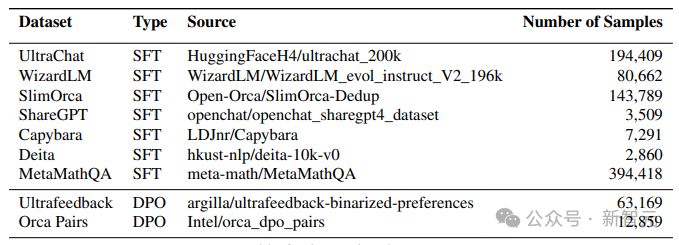
研究人员在Hugging Face Hub上公开的一些指令数据集上对预训练模型进行微调。尤其是使用了UltraChat、WizardLM、SlimOrca、ShareGPT、Capybara、Deita和MetaMathQA会话数据集,样本总数为826,938个。直接偏好优化(DPO)
直接偏好优化(Direct Preference Optimization,简称 DPO)是 Zephyr-7B、Neural-Chat-7B和Tulu-2-DPO-70B等近期强模型的基本工具。在这个阶段,他们使用UltraFeedback和Intel Orca Pairs这两个数据集,并通过删除了排名并列的配对、内容重复的配对以及所选回应得分低于80%的配对来过滤数据集。实验结果和基准测试
少样本和零样本评估
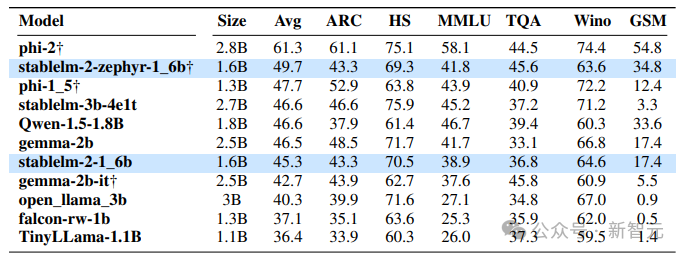
研究人员通过流行基准评估了Stable LM 2的少样本和零样本能力,并将结果与类似大小的开源预训练模型进行了比较。下表列出了模型评估结果。可以看出,Stable LM 2 1.6B (stablelm-2-1-6b)的性能明显优于其他基础模型。同样,经过指令微调的版本(stablelm-2-1-6b-dpo)比微软的Phi-1.5平均提高了2%,但在几发准确率上却落后于更大的Phi-2.0。与谷歌的Gemma 2B(2.5B参数)相比,性能也有显著提高。多语种评估
通过在 ChatGPT 翻译版本的 ARC、HS、TQA 和 MMLU 上进行评估,来评估在多语言环境下的知识和推理能力。此外,还使用了机器翻译的LAMBADA数据集测试了下一个单词的预测能力。下表为zero-shot测试结果,可以看出与规模是其两倍的模型相比,Stable LM 2的性能更加出众。MT基准评估
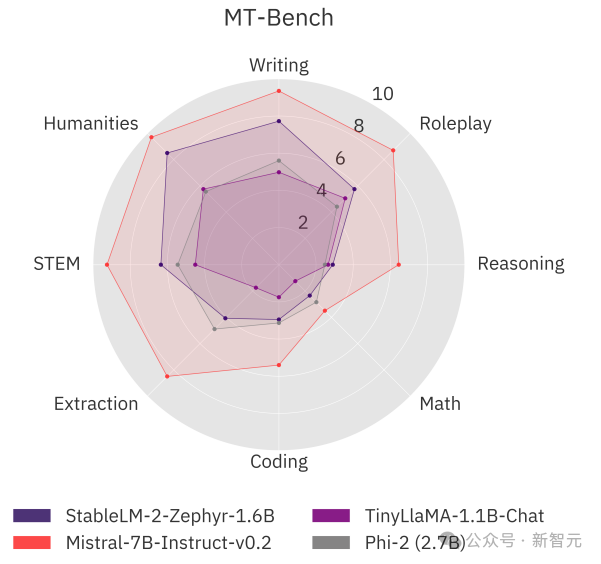
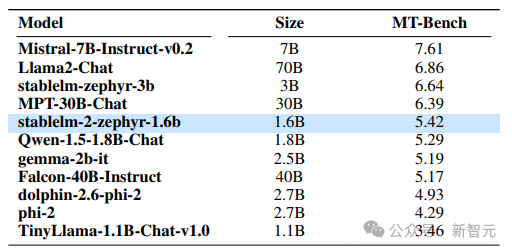
他们还在流行的多轮基准MT-Bench上测试了模型的对话能力。Stable LM 2 1.6B显示出具有竞争力的性能,与MT-Bench上的大型模型能力相当甚至更好。虽然该模型落后于Mistral 7B Instruct v0.2(比Stable LM 2大4倍多)等更强大的模型,但该模型提供了更好的聊天性能,并以较大优势击败了Phi-2、Gemma 2B和TinyLLaMA 1.1B这两个大模型。https://stability.ai/news/introducing-stable-lm-2-12b
内容中包含的图片若涉及版权问题,请及时与我们联系删除












评论
沙发等你来抢