

新智元报道
新智元报道
【新智元导读】训大模型的方法可能要被革新了!AI大神Karpathy发布的新项目仅用1000行的C语言训完GPT-2,而不再依赖庞大的GPT-2库。他本人预告,即将上线新课。
仅用1000行纯C语言训完GPT-2。
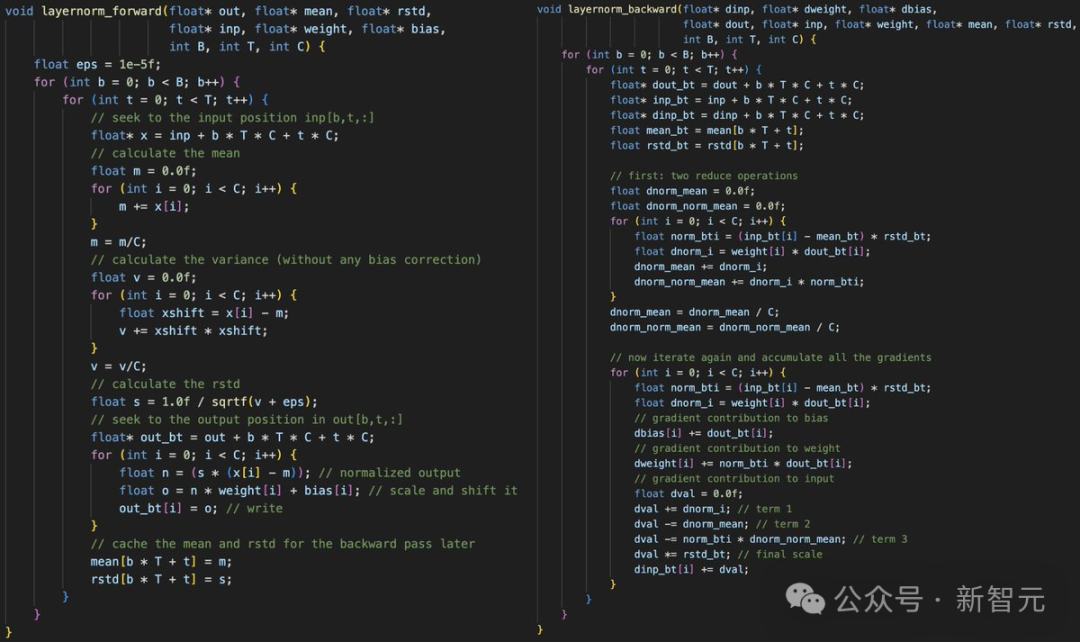
想象一下,如果我们能够不依赖于庞大的PyTorch(245MB)和cPython(107MB)库,仅仅使用纯C语言就能训练大型语言模型(LLM),那会怎样? 现在,借助llm.c,这件听起来似乎不太可能的事,已经成为了现实! 这个项目的亮点在于,它仅用约1000行简洁的C代码,就实现了在普通计算机处理器(CPU)上训练GPT-2模型的能力。 而且,这份代码不仅可以立即编译运行,其训练结果也和PyTorch版本的GPT-2完全一致。 之所以选择GPT-2作为起点,是因为它标志着大型语言模型发展史上的一个重要里程碑,是第一次以我们现在所熟悉的形式整合了这样的技术栈,并且模型权重也是公开可获取的。






千行C代码训完GPT-2
快速入门
python prepro_tinyshakespeare.py
Saved 32768 tokens to data/tiny_shakespeare_val.binSaved 305260 tokens to data/tiny_shakespeare_train.bin
python train_gpt2.py
gpt2_124M.bin,其中包含了可用于在C语言环境中加载模型的原始权重;
gpt2_124M_debug_state.bin,其中包含了额外的调试信息,如输入数据、目标、logits和损失。
make train_gpt2
OMP_NUM_THREADS=8 ./train_gpt2
[GPT-2]max_seq_len: 1024vocab_size: 50257num_layers: 12num_heads: 12channels: 768num_parameters: 124439808train dataset num_batches: 1192val dataset num_batches: 128num_activations: 73323776val loss 5.252026step 0: train loss 5.356189 (took 1452.121000 ms)step 1: train loss 4.301069 (took 1288.673000 ms)step 2: train loss 4.623322 (took 1369.394000 ms)step 3: train loss 4.600470 (took 1290.761000 ms)(trunctated) ...step 39: train loss 3.970751 (took 1323.779000 ms)val loss 4.107781generated: 50256 16773 18162 21986 11 198 13681 263 23875 198 3152 262 11773 2910 198 1169 6002 6386 2583 286 262 11858 198 20424 428 3135 7596 995 3675 13 198 40 481 407 736 17903 11 329 703 6029 706 4082 198 42826 1028 1128 633 263 11 198 10594 407 198 2704 454 680 1028 262 1027 28860 286 198 3237 323step 40: train loss 4.377757 (took 1366.368000 ms)
import tiktokenenc = tiktoken.get_encoding("gpt2")print(enc.decode(list(map(int, "50256 16773 18162 21986 11 198 13681 263 23875 198 3152 262 11773 2910 198 1169 6002 6386 2583 286 262 11858 198 20424 428 3135 7596 995 3675 13 198 40 481 407 736 17903 11 329 703 6029 706 4082 198 42826 1028 1128 633 263 11 198 10594 407 198 2704 454 680 1028 262 1027 28860 286 198 3237 323".split()))))
打印内容如下:
Running Away,Greater conquerWith the Imperial bloodthe heaviest host of the godsinto this wondrous world beyond.I will not back thee, for how sweet after birthNetflix against repounder,will notflourish against the earlocks ofAllay
测试
make test_gpt2./test_gpt2
教程
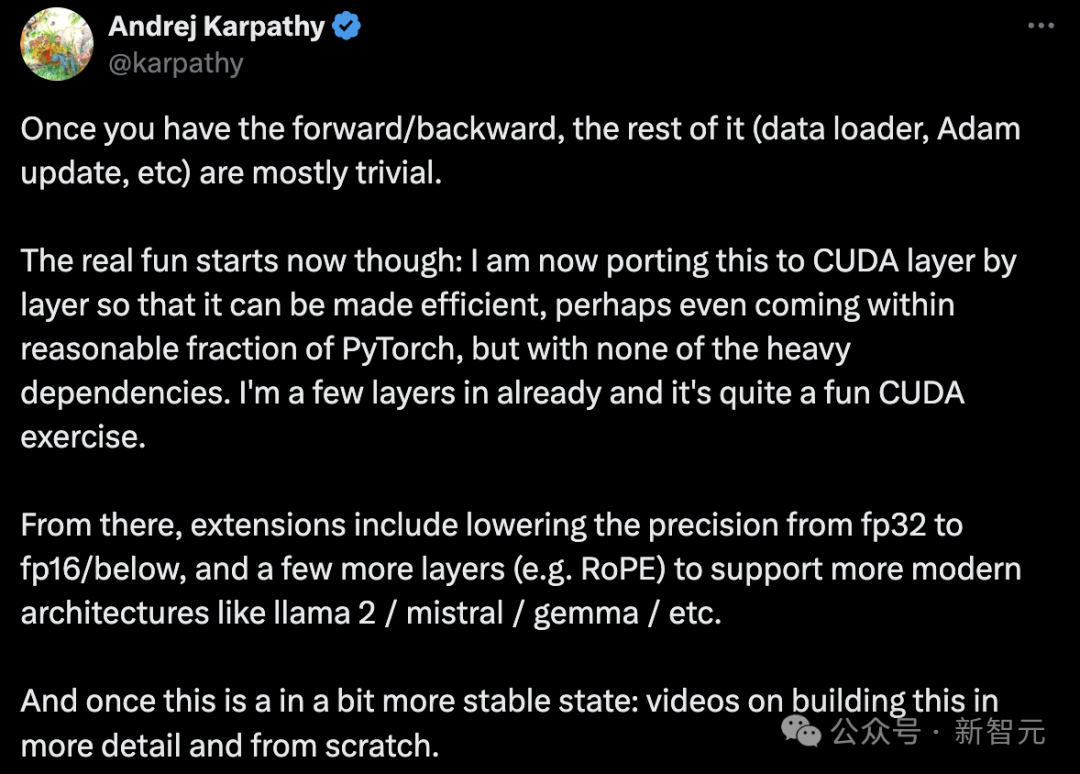
纯CUDA也可训

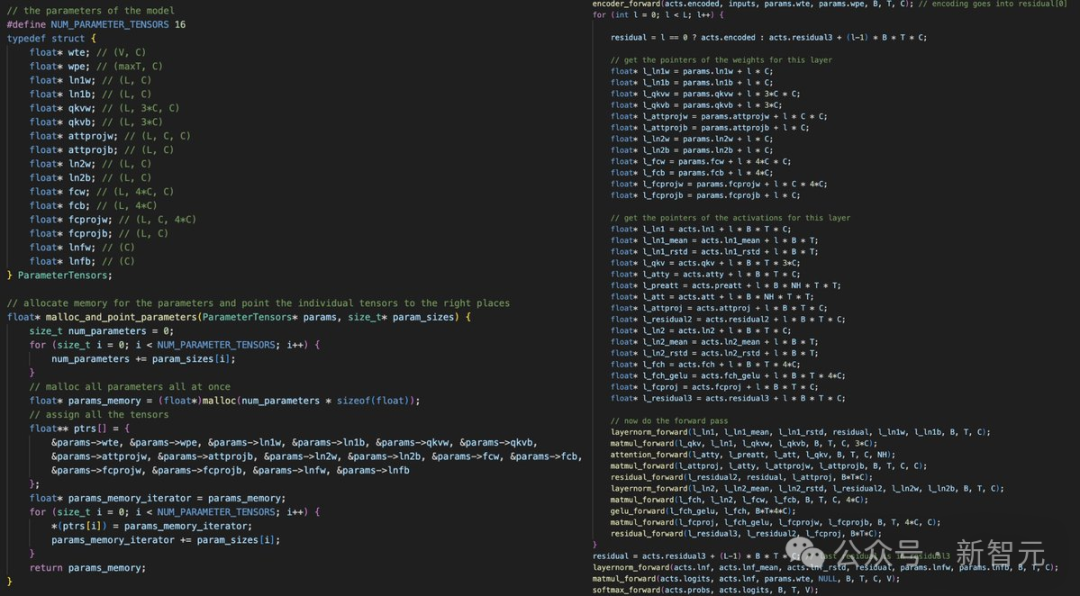
左图:在内存中分配一个一维数组,然后将所有模型的权重和激活指向它



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢