元象发布XVERSE-MoE-A4.2B大模型 ,采用业界最前沿的混合专家模型架构 (Mixture of Experts),激活参数4.2B,效果即可媲美13B模型。该模型全开源,无条件免费商用,让海量中小企业、研究者和开发者可在元象高性能“全家桶”中按需选用,推动低成本部署。
- 极致压缩:用相同语料训练2.7万亿token,元象MoE实际激活参数量4.2B,效果“跳级”超越XVERSE-13B-2,仅用30%计算量,并减少50%训练时间。
- 超凡性能:在多个权威评测中,元象MoE效果大幅超越新晋业界顶流谷歌Gemma-7B和Mistral-7B、Meta开源标杆Llama2-13B等多个模型、并接近超大模型Llama1-65B。
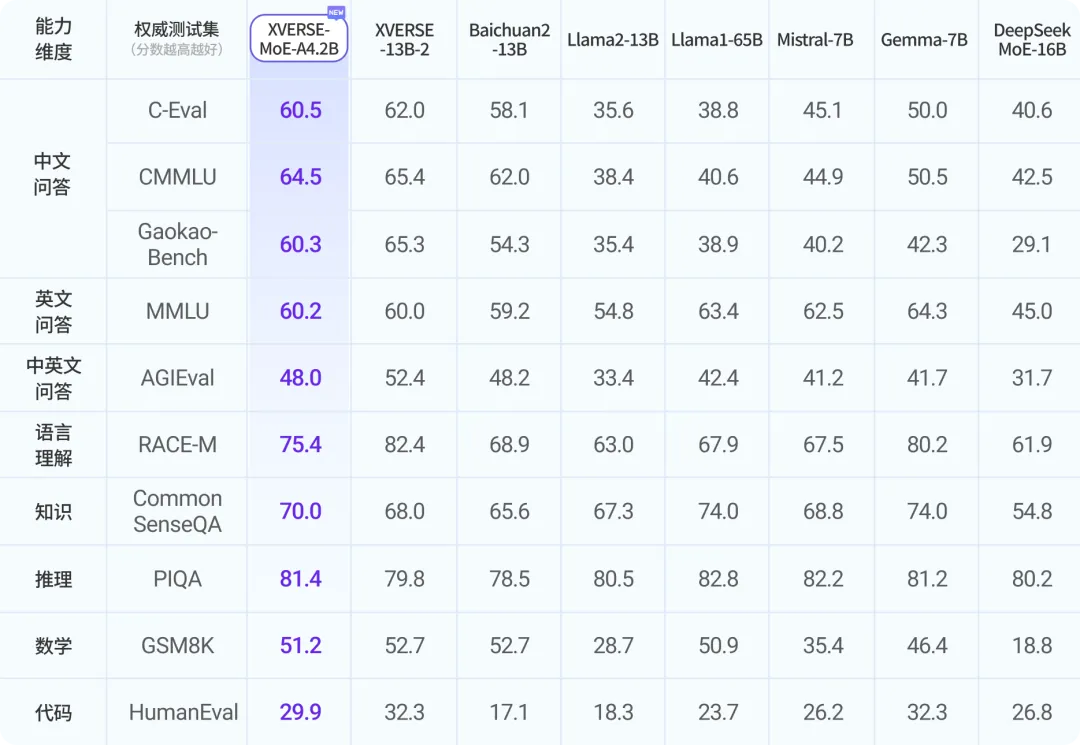
权威测试集评测结果
MoE模型采用的稀疏激活(Sparsely Activated)技术,正逐渐成为大模型研究领域最前沿。该技术打破了传统规模理论(Scaling Law)的局限,在扩大模型规模的同时,可以不显著增加训练和推理的计算成本,并保持模型性能最大化。但由于技术较新,在国内开源和学术研究领域尚未普及。商业应用上,元象大模型是广东最早获得国家备案的模型之一,可向全社会提供服务。元象大模型去年起已和多个腾讯产品,包括QQ音乐、虎牙直播、全民K歌、腾讯云等,进行深度合作与应用探索,为文化、娱乐、旅游、金融领域打造创新领先的用户体验。免费下载大模型
Hugging Face:https://hf.co/xverse/XVERSE-MoE-A4.2B
ModelScope魔搭:https://modelscope.cn/models/xverse/XVERSE-MoE-A4.2B
Github:https://github.com/xverse-ai/XVERSE-MoE-A4.2B
问询发送:opensource@xverse.cn
商业合作
微信添加:lixing_lixing
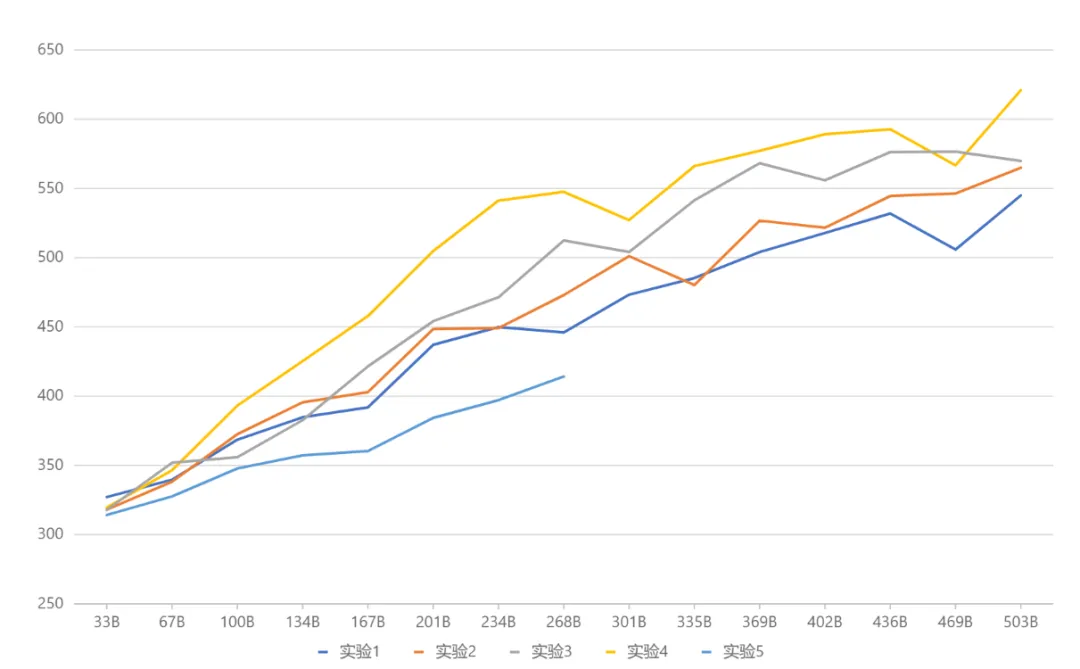
MoE是目前业界最前沿的模型框架,由于技术较新,国内开源模型或学术研究尚未普及。元象自主研发了MoE的高效训练和推理框架,并在三个方向创新:性能上,针对MoE架构中独特专家路由和权重计算逻辑,研发一套高效融合算子,显著提升了计算效率;针对MoE模型高显存使用和大通信量挑战,设计出计算、通信和显存卸载的重叠操作,有效提高整体处理吞吐量。架构上,与传统MoE(如Mixtral 8x7B)将每个专家大小等同于标准FFN不同,元象采用更细粒度的专家设计,每个专家大小仅为标准FFN的四分之一,提高了模型灵活性与性能;还将专家分为共享专家(Shared Expert)和非共享专家(Non-shared Expert)两类。共享专家在计算过程中始终保持激活状态,而非共享专家则根据需要选择性激活。这种设计有利于将通用知识压缩至共享专家参数中,减少非共享专家参数间的知识冗余。训练上,受Switch Transformers、ST-MoE和DeepSeekMoE等启发,元象引入负载均衡损失项,更好均衡专家间的负载;采用路由器z-loss项,确保训练高效和稳定。架构选择则经过一系列对比实验得出(下图),在实验3与实验2中,总参数量和激活参数量相同,但前者的细粒度专家设计带来了更高的性能表现。实验4在此基础上,进一步划分共享和非共享两类专家,使得效果显著提升。实验5探索了专家大小等于标准FFN时,引入共享专家的做法,效果不甚理想。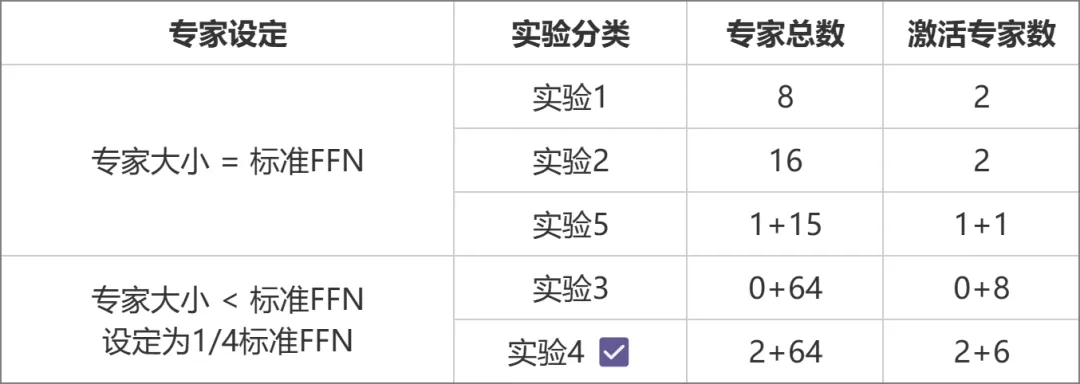
综合试验结果(下图),元象最终采用实验4对应的架构设置。展望未来,新近开源的Google Gemma与X(前Twitter)Grok等项目采用了比标准FFN更大的设定,元象也将在后续继续深入探索相关方向探索研,保持技术引领性。
本文由 Hugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。了解更多请关注公众号:
如果你有与开源 AI、Hugging Face 相关的技术和实践分享内容,以及最新的开源 AI 项目发布,希望通过我们分享给更多 AI 从业者和开发者们,请通过下面的链接投稿与我们取得联系:https://hf.link/tougao
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢