

新智元报道
新智元报道
【新智元导读】ChatGPT也能用上最强的GPT-4 Turbo了!今天,新版GPT-4 Turbo再次重夺大模型排行榜王座,超越了Claude 3 Opus。而且,新模型在处理64k长上下时,性能直接达到了旧版在26k时的性能。

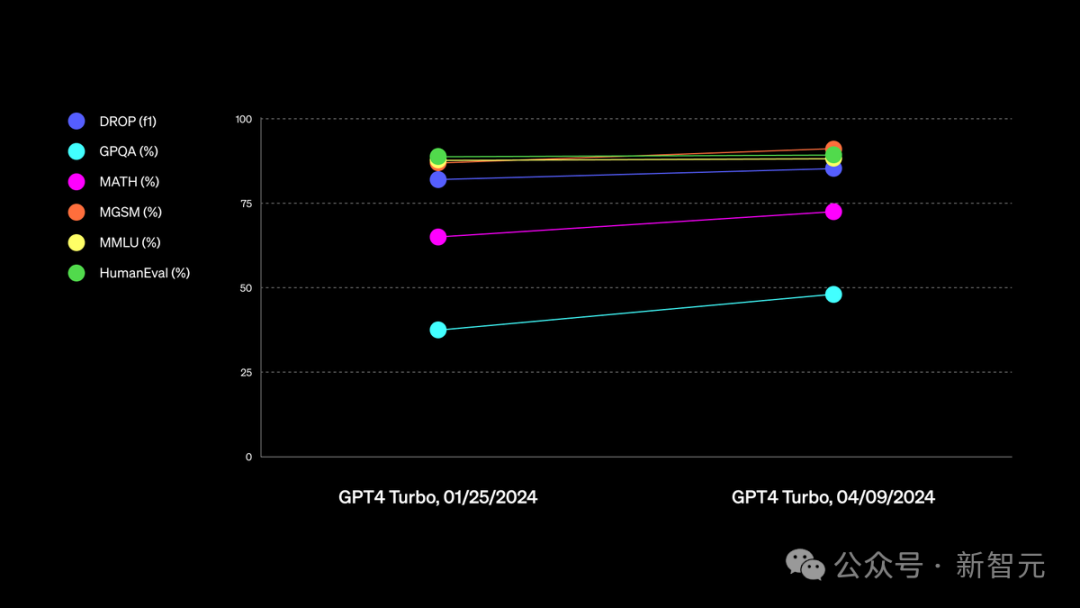


数学性能提升近10%
在官方公开GitHub上,OpenAI放出了gpt-4-turbo-2024-04-09最新的评估结果。 主要在以下七大基准上,对模型完成了评估: MMLU(测量大规模多任务语言理解)
MATH(使用MATH数据集测量数学问题解决能力)
GPQA(研究生级别的谷歌防护问答基准)
DROP(需要对段落进行离散推理的阅读理解基准)
MGSM(多语言小学数学基准):语言模型作为多语言思维链推理者
HumanEval(评估在代码上训练的大型语言模型)
MMMU(用于专家通用人工智能的大规模多学科多模态理解和推理基准)
在这个GitHub库中,OpenAI主要使用零样本、CoT设置,并采用简单的指令,如「解决以下多项选择题」。 这种提示方式更能真实反映模型在实际使用中的表现。 具体结果如下所示: 最新的gpt-4-turbo比以往的GPT-4系列,在性能上有着明显的提升。 尤其数学方面,能力实现了近10%的跃阶。 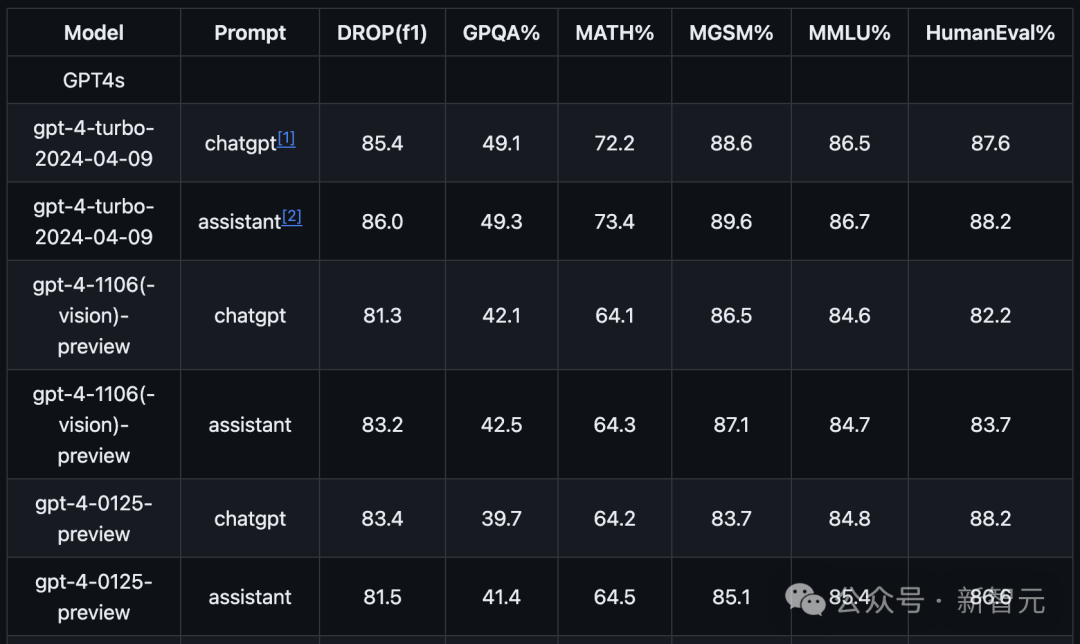
而在整体的比较中,新模型也基本上实现了对Claude 3 Opus和Gemini Pro 1.5的全面超越。 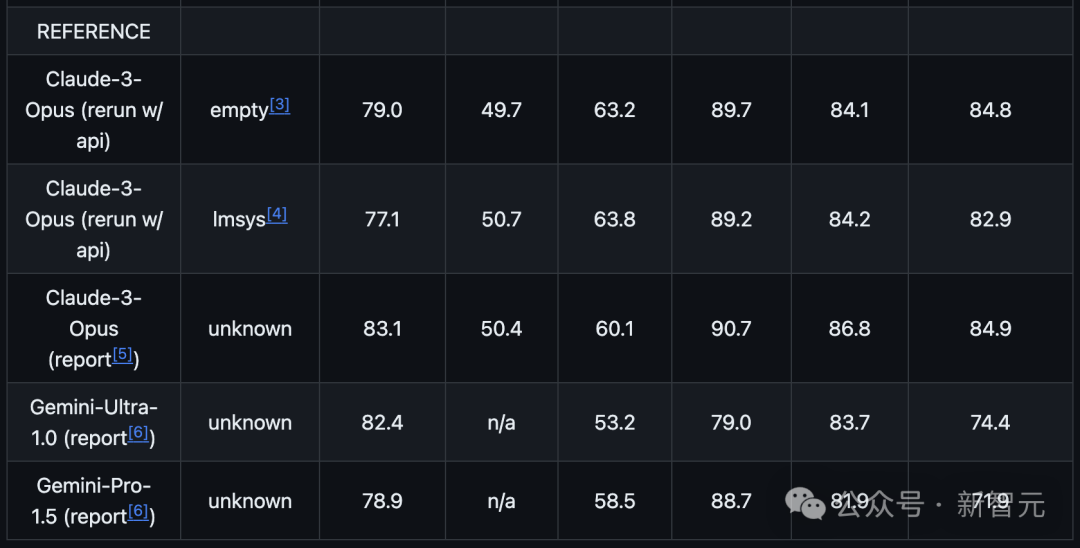
大海捞针比初代GPT-4提升4.3倍
MMLU(测量大规模多任务语言理解)
MATH(使用MATH数据集测量数学问题解决能力)
GPQA(研究生级别的谷歌防护问答基准)
DROP(需要对段落进行离散推理的阅读理解基准)
MGSM(多语言小学数学基准):语言模型作为多语言思维链推理者
HumanEval(评估在代码上训练的大型语言模型)
大海捞针比初代GPT-4提升4.3倍
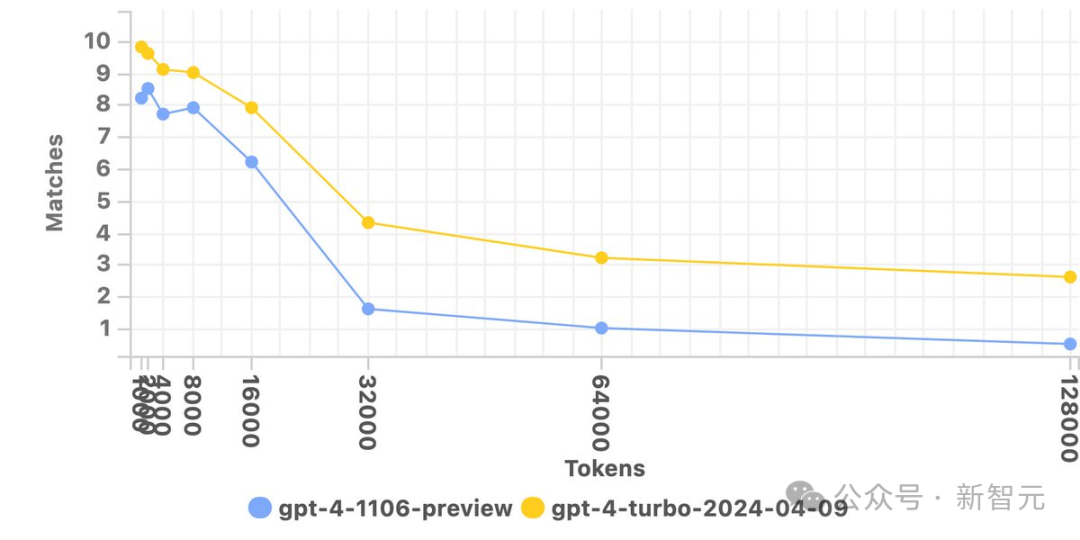
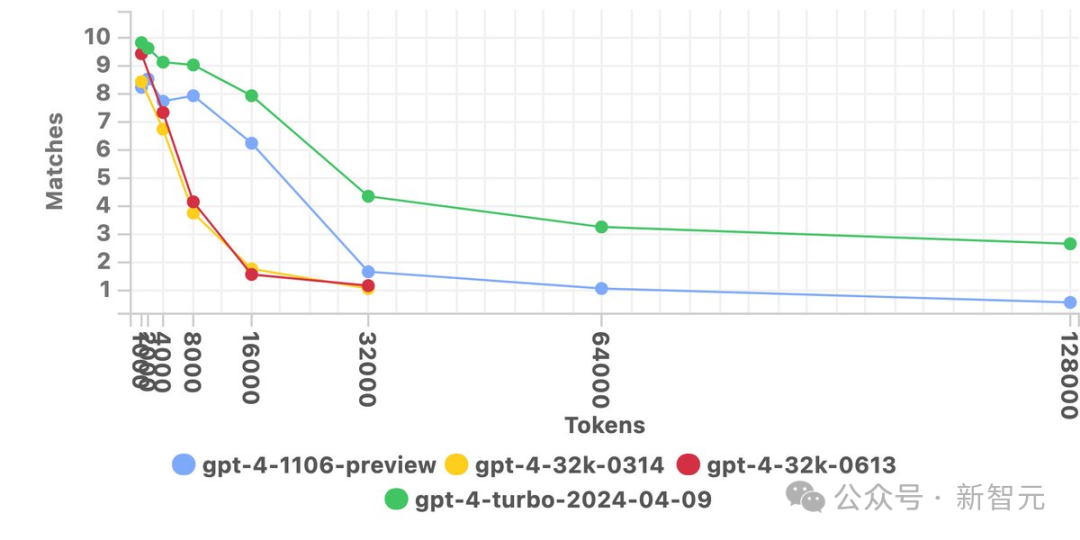
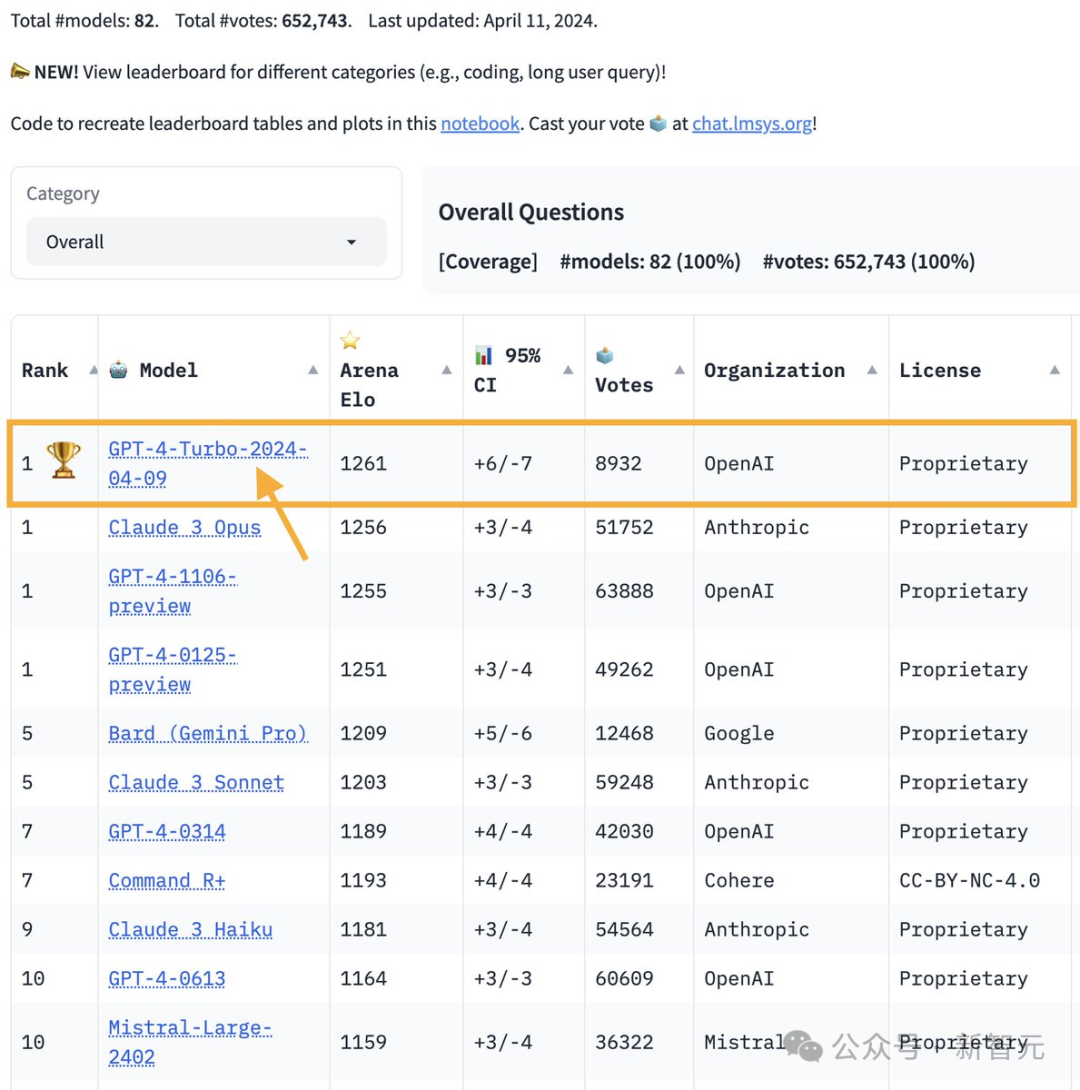
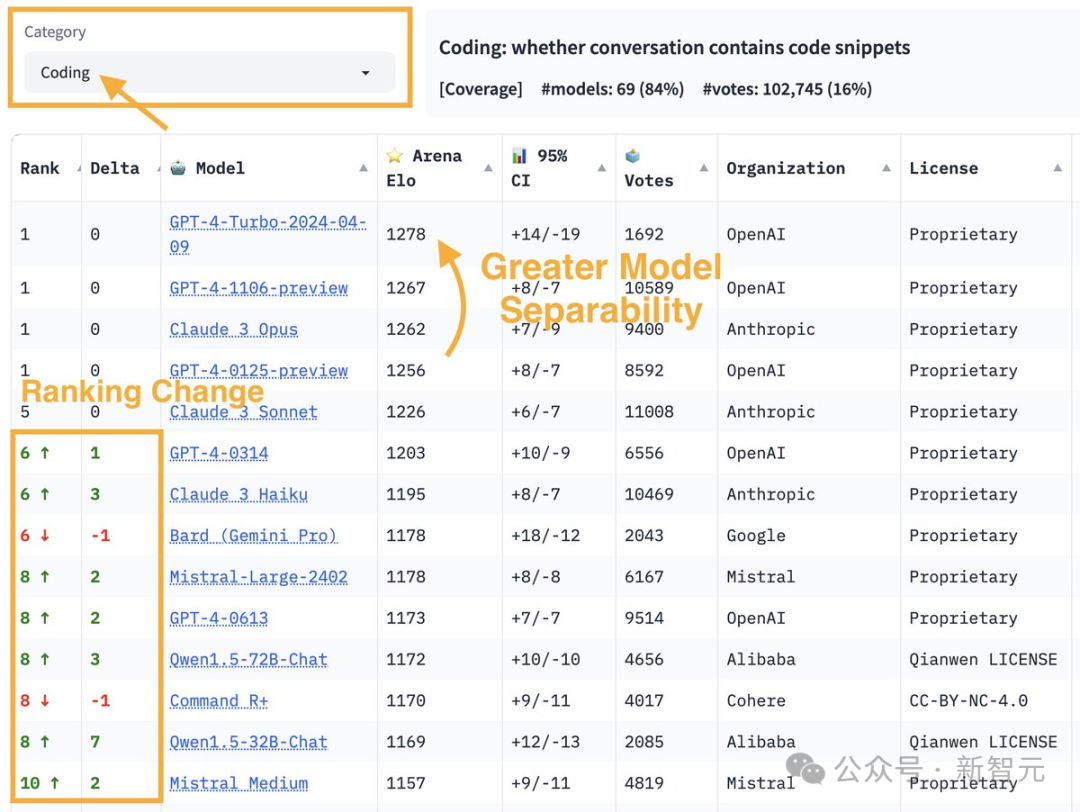
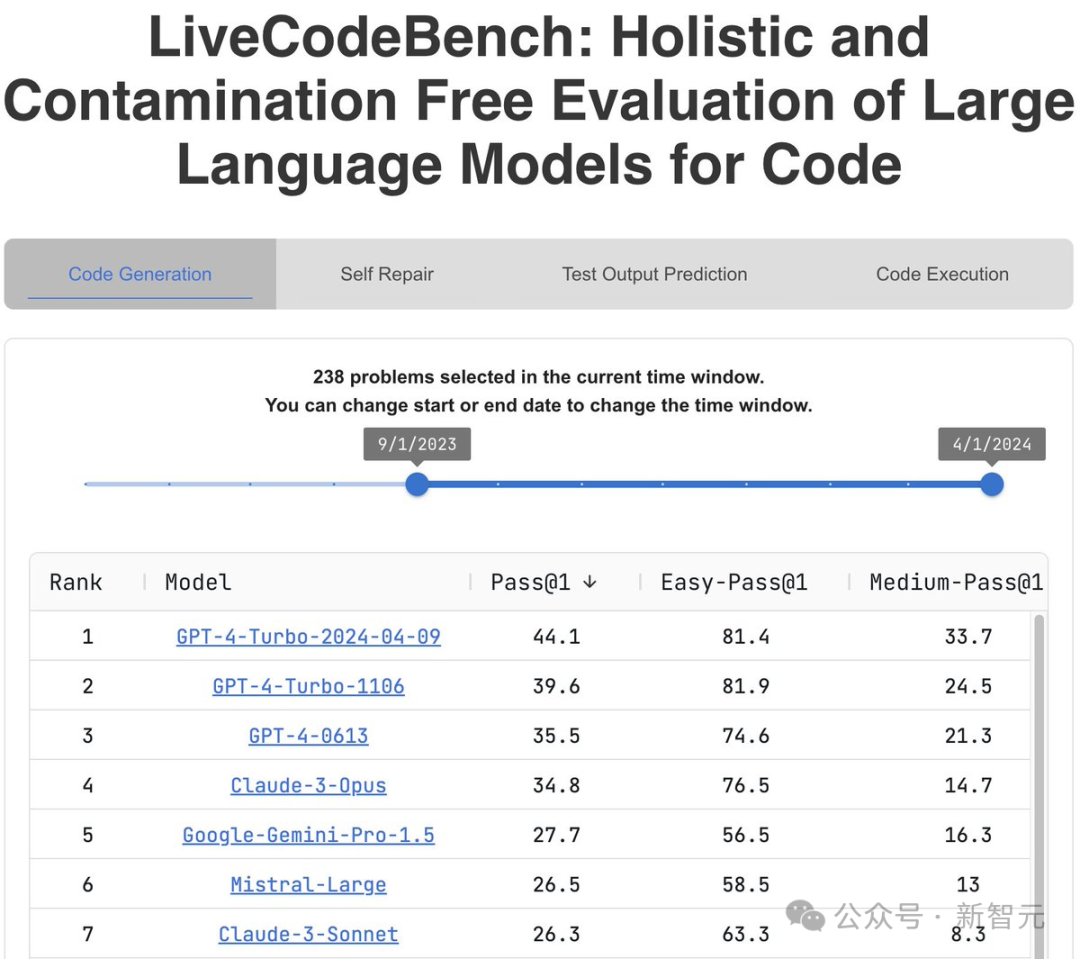
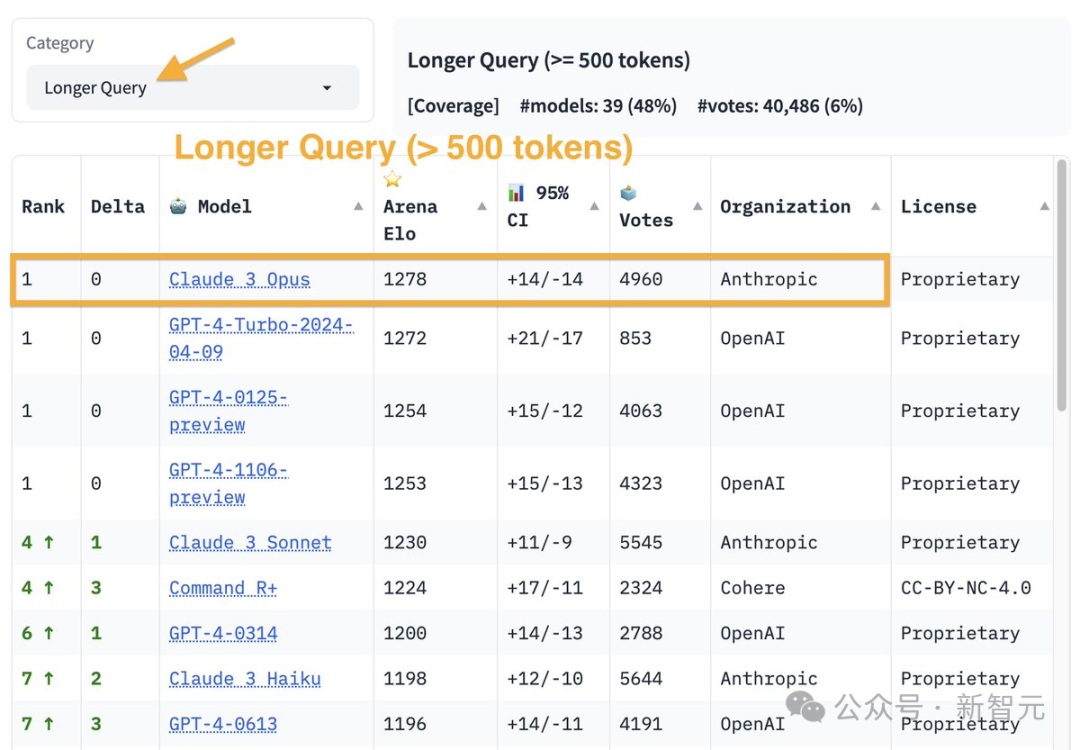
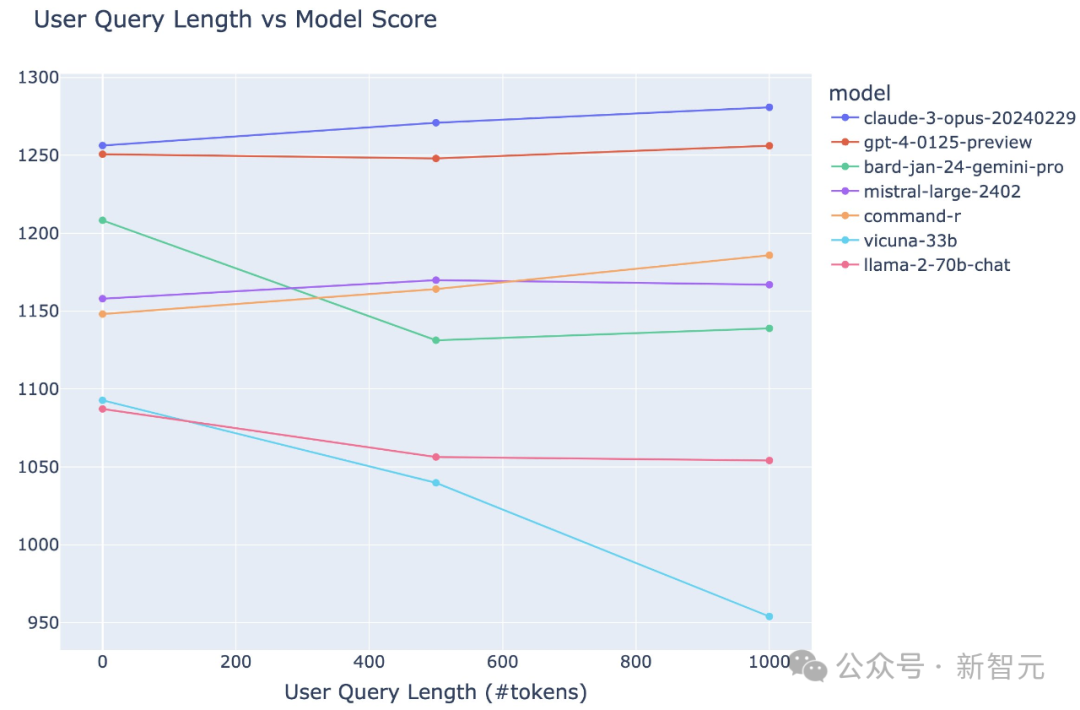
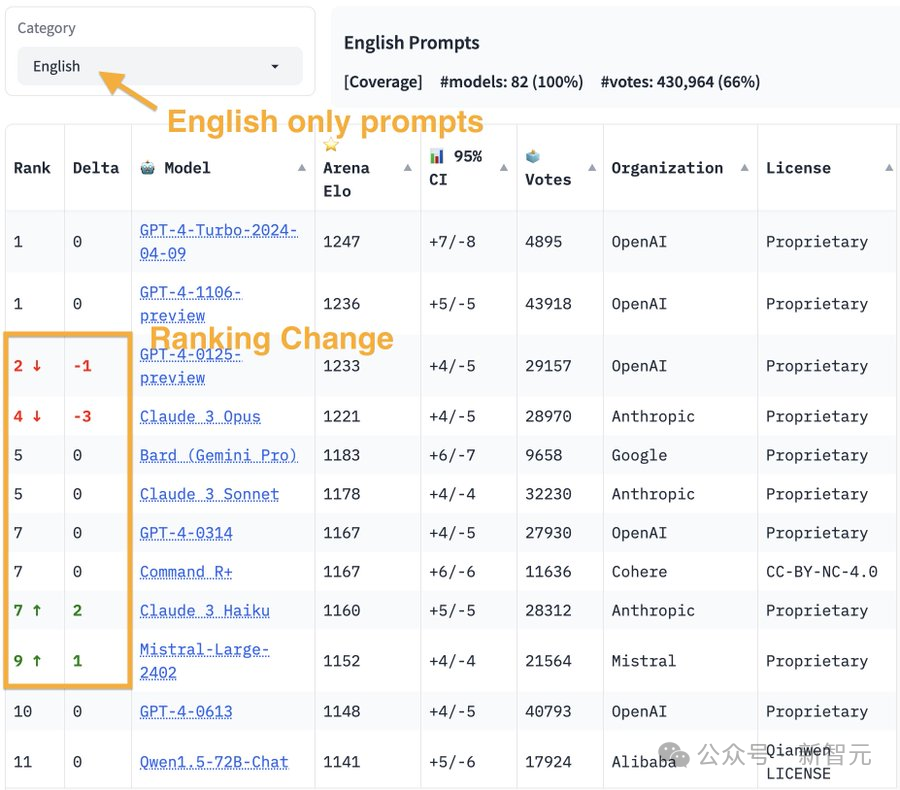
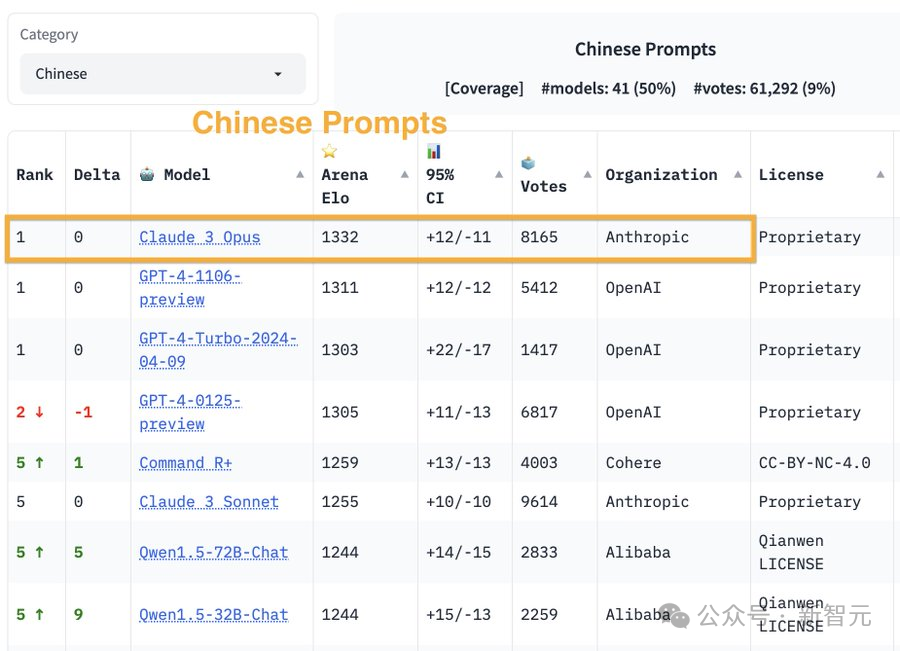
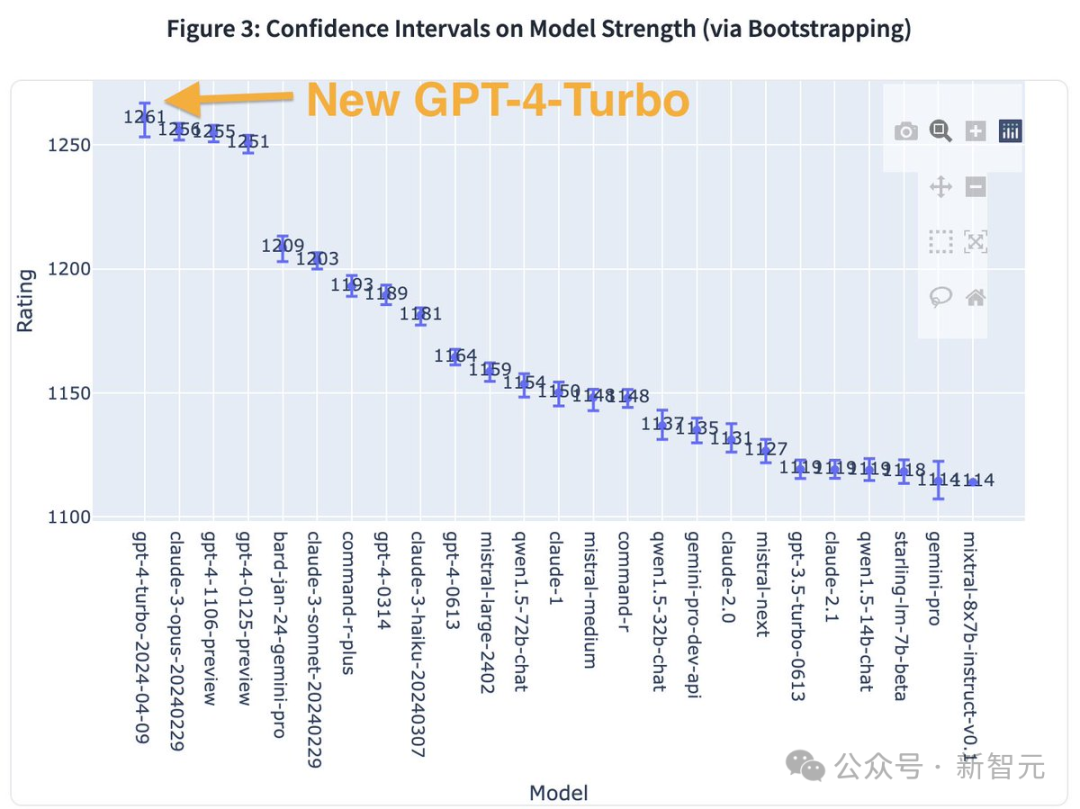
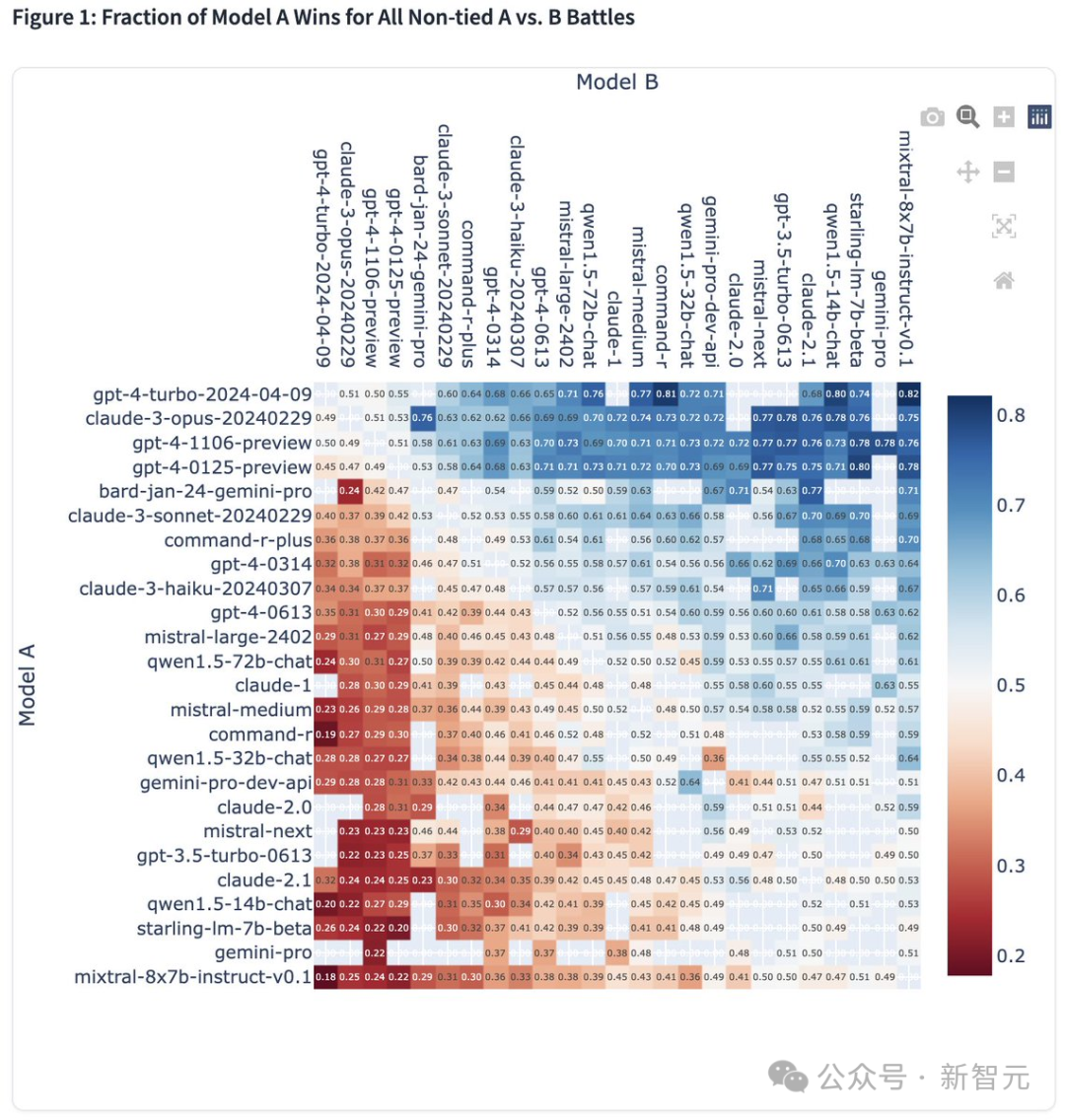
GPT-4 Turbo重回王座



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢