- 超越 Transformer:Google DeepMind 提出高效开放语言模型
- 仅用 10 万美元!MIT 训了一个 Llama2 级的大模型
- 英伟达推出音频、音乐理解对话数据集 Audio Dialogues
- 微软、厦大、清华提出 Rho-1:不是所有 token 都是你需要的
- 微软、上交大推出CoVoMix:实现多个对话者的多轮对话
- Transformer 的可解释性会转移到 RNN 吗?
- 苹果新研究 Ferret-UI:基于多模态 LLM 的移动 UI 理解
- CT-LLM:仅 20 亿参数,基于中文的大型语言模型
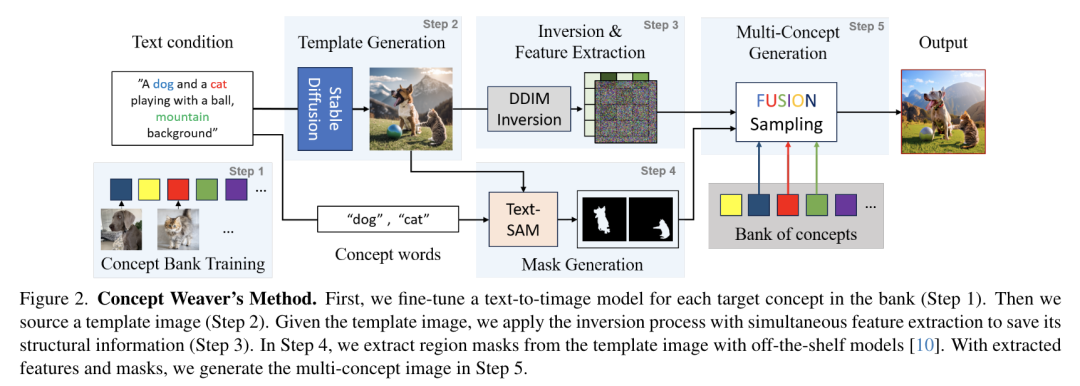
- Concept Weaver:在文本到图像模型中实现多概念融合
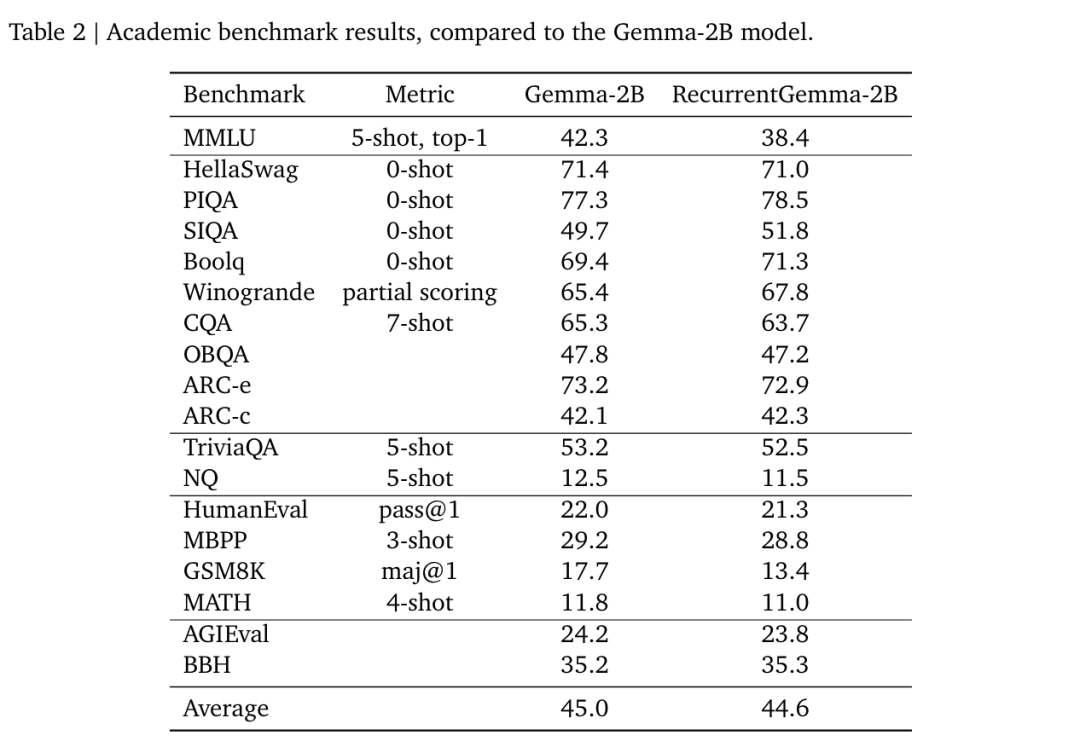
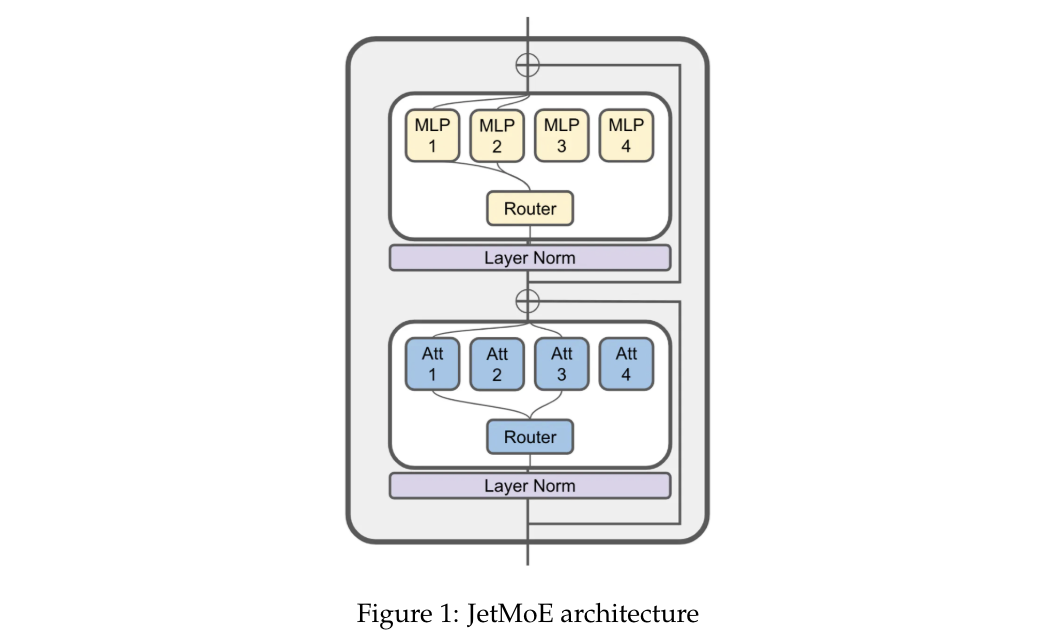
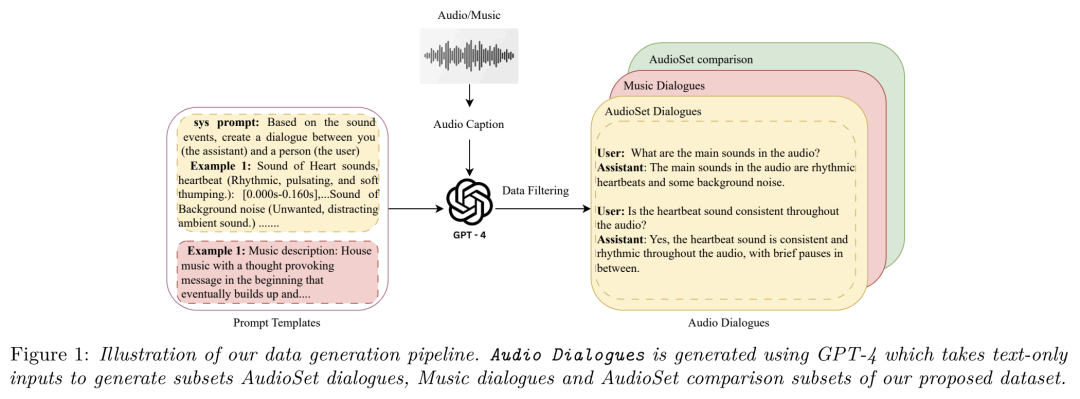
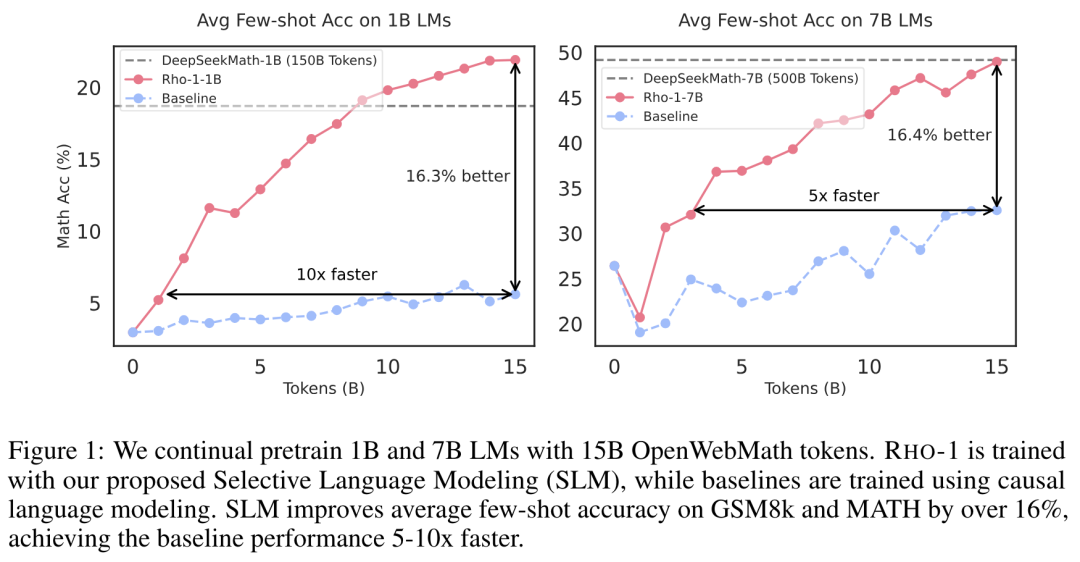
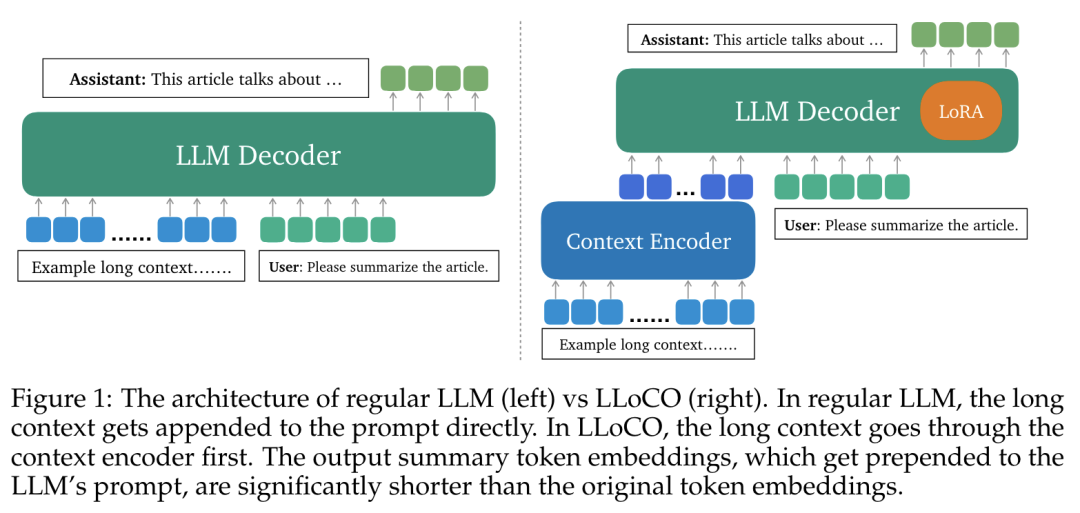
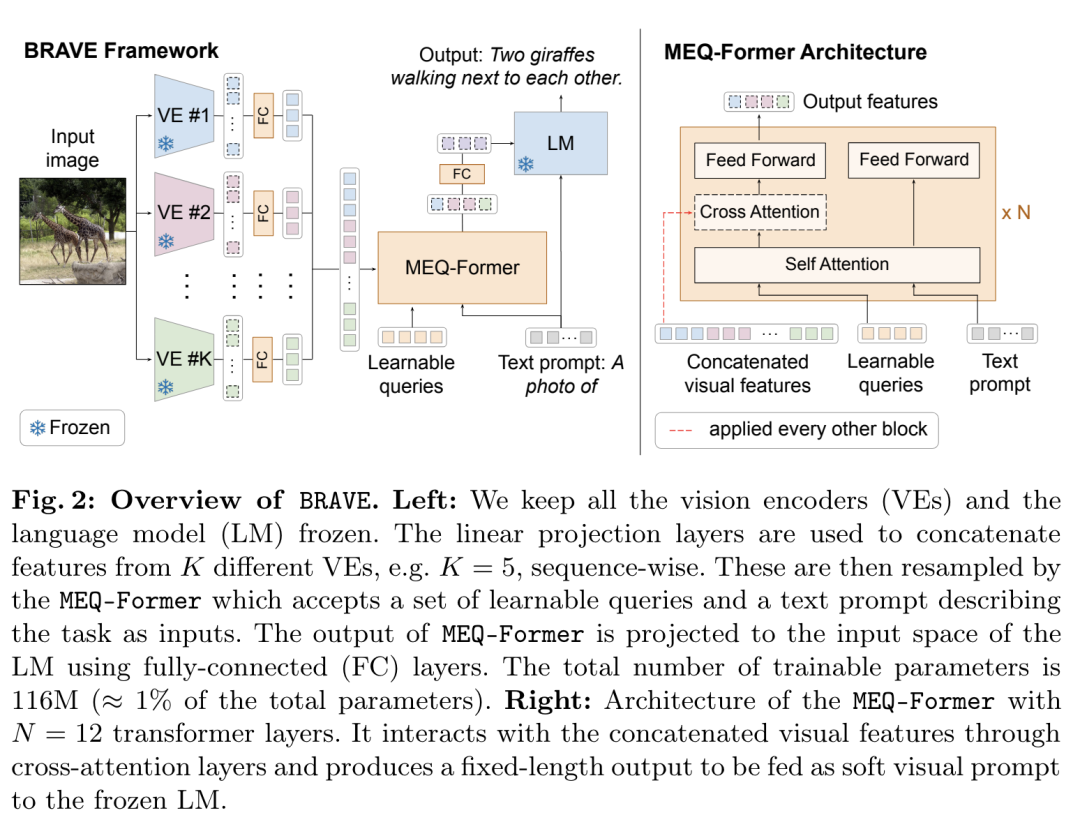
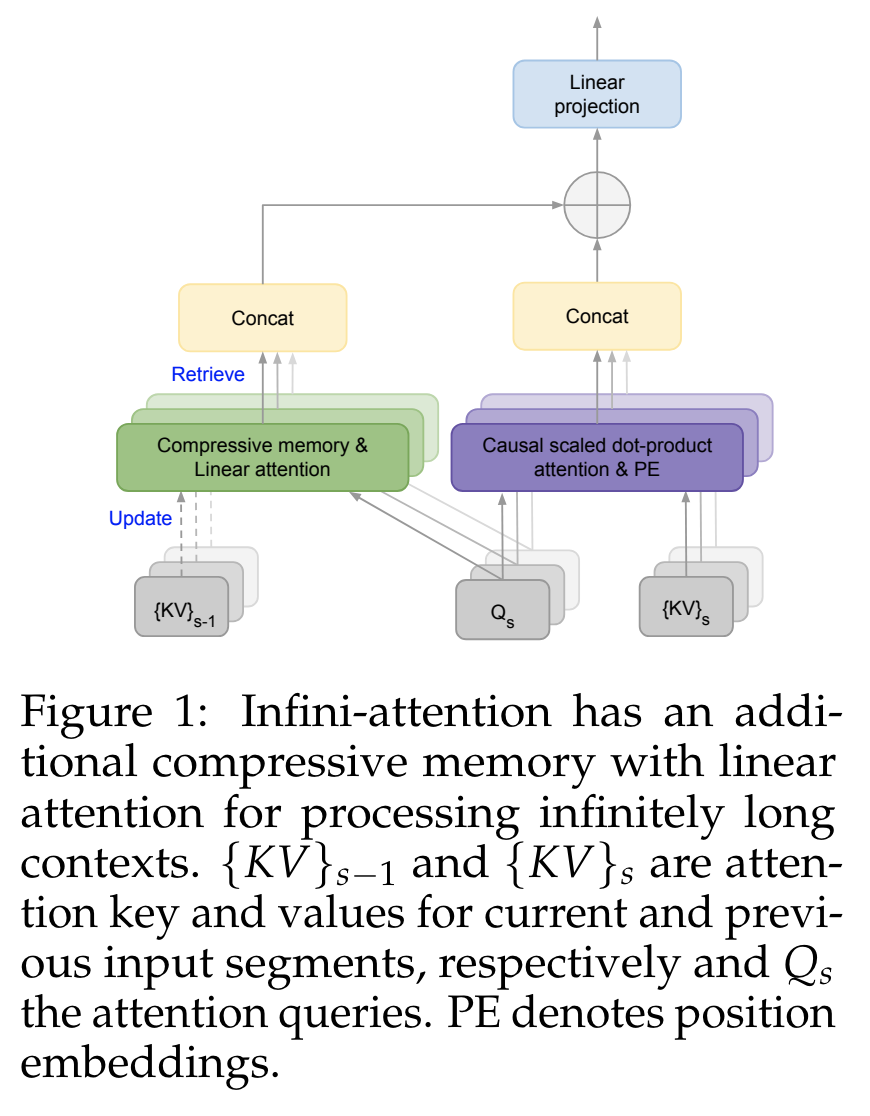
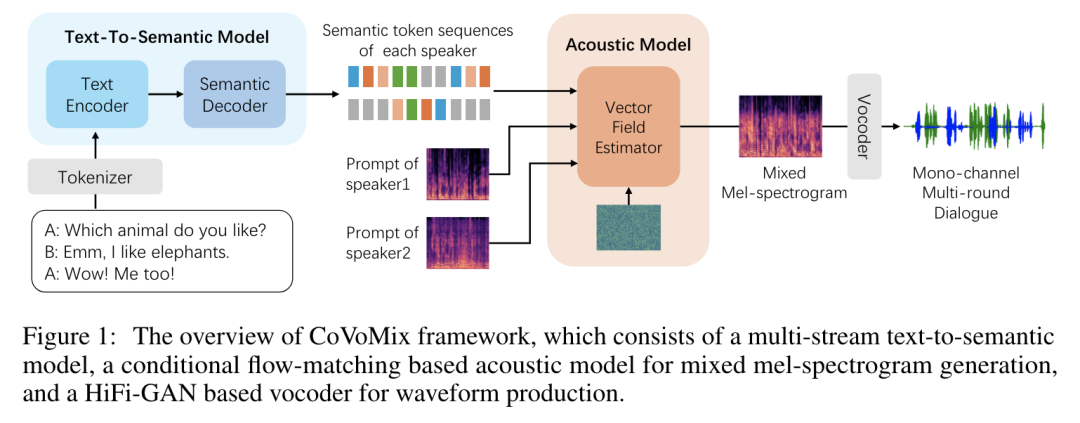
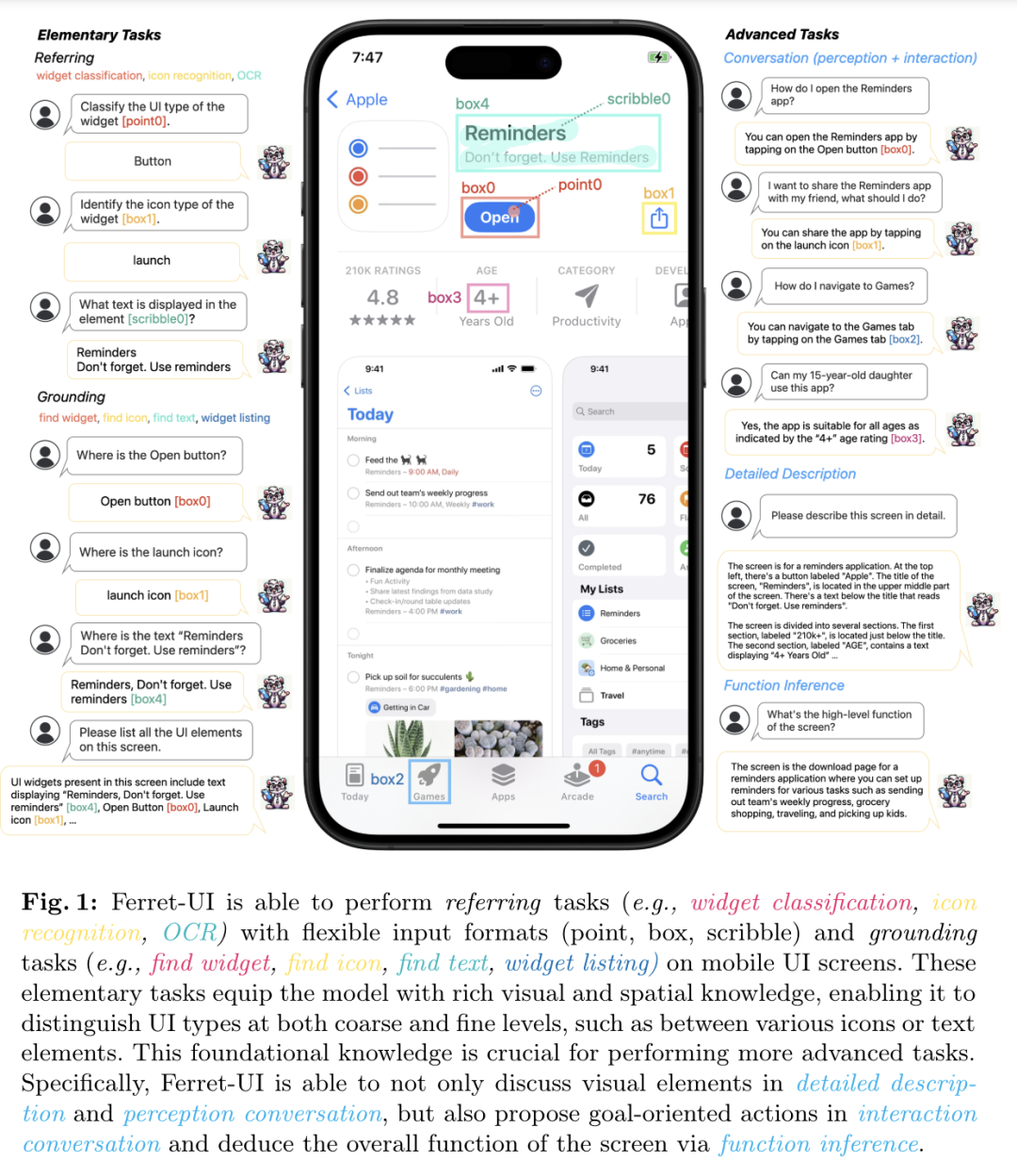
Google DeepMind 提出高效开放语言模型Google DeepMind 团队提出了 RecurrentGemma,一个使用谷歌 Griffin 架构的开放语言模型。Griffin 将线性递归与局部注意力相结合,在语言上取得了优异的性能。它具有固定大小的状态,从而减少了内存使用,并能够对长序列进行有效的推理。此外,他们提出了一个具有 2B 非嵌入参数的预训练模型和一个指令微调的变体。尽管在更少的 token 上进行训练,但这两个模型都取得了与 Gemma-2B 相当的性能。https://arxiv.org/abs/2404.078392.仅用 10 万美元!MIT 训了一个 Llama2 级的大模型大型语言模型(LLMs)已经取得了显著的成果,但其日益增长的资源需求已经成为发展强大和可访问的超人类智能的主要障碍。来自麻省理工大学和普林斯顿大学的研究团队提出了 JetMoE-8B,这是一种训练费用不到 10 万美元的新的 LLM,使用来自精心混合的开源语料库的 1.25T token 和 30000 个 H100 GPU 小时进行训练。尽管成本低,但 JetMoE-8B 表现出了令人印象深刻的性能,它超过了 Llama2-7B 模型,JetMoE-8B-chat 超过了Llama2-13B-Chat 模型。结果表明,LLM 训练可能比通常认为的更具成本效益。JetMoE-8B 基于高效的稀疏门控专家混合(SMoE)架构,由注意力和前馈专家组成。这两层都是稀疏激活的,允许 JetMoE-8B 具有 8B 参数,而每个输入 token 仅激活 2B,与 Llama2-7B 相比,减少了约 70% 的推理计算。此外,JetMoE-8B 是高度开放和学术友好的,只使用公共数据集和训练代码。该团队详细介绍了所有训练参数和数据混合,从而促进未来开发开放式基础模型的努力。这种透明度旨在鼓励在可访问和高效的 LLMs 领域的合作和进步。https://arxiv.org/abs/2404.07413https://github.com/myshell-ai/JetMoE3.英伟达推出音频、音乐理解对话数据集 Audio Dialogues现有的音频理解数据集主要集中在单回合交互(即音频字幕、音频问答)上,用于以自然语言描述音频,从而限制了通过交互式对话理解音频。为了解决这一差距,英伟达研究团队提出了一个包含 163.8k 样本的多回合对话数据集——Audio Dialogues,用于一般音频和音乐。除了对话,Audio Dialogues 还具有问答对,可以一起理解和比较多个输入音频。Audio Dialogues 利用基于提示的方法和来自现有数据集的标题注释,使用大型语言模型(LLM )生成多回合对话。在所提出的数据集上评估了现有的音频增强的大型语言模型,从而证明音频对话的复杂性和适用性。https://arxiv.org/abs/2404.07616https://audiodialogues.github.io/以往的语言模型(LMs)预训练方法对所有训练 tokens 统一应采用 next-token 的预测损失。然而,来自厦门大学、清华大学和微软的研究团队认为“并不是语料库中的所有 token 对语言模型训练都同样重要”。他们初步分析深入到语言模型的 token-level 训练动态,揭示了不同 token 的不同损失模式。利用这些见解,他们提出了名为 Rho-1 的新语言模型。与学习预测语料库中每下一个 token 的传统 LMs 不同,Rho-1 使用选择性语言建模(SLM),它选择性地训练与期望分布一致的有用 tokens。这种方法包括使用参考模型对预训练 token 进行评分,然后将集中损失的语言模型训练在具有较高超额损失的 token 上。在 15B OpenWebMath 语料库中进行持续预训练时,Rho-1 在 9 个数学任务中的少样本准确率绝对提高了 30%。经过微调,Rho-1-1B 和 7B 在 MATH 数据集上分别取得了 SOTA,仅用 3% 的预训练 tokens 匹配 DeepSeekMath。此外,当对 80B 个通用 tokens 进行预训练时,Rho-1 在 15 个不同的任务上实现了 6.8% 的平均增强,提高了语言模型预训练的效率和性能。https://arxiv.org/abs/2404.07965https://github.com/microsoft/rho5.UC 伯克利提出 LLoCO:离线学习长上下文目前,由于自注意力机制的二次计算和内存开销以及生成过程中大量的 KV 缓存大小等问题,处理长上下文对于大型语言模型(LLMs)来说仍然是一个挑战。加州大学伯克利分校团队提出了一种新的方法来解决这个问题,通过上下文压缩和域内高效参数微调来离线学习上下文。该方法使 LLM 能够创建原始上下文的简明表示,并有效地检索相关信息以准确回答问题。他们提出了 LLoCO——一种使用 LoRA 结合上下文压缩、检索和参数高效调优的技术。他们的方法扩展了 4k token LLaMA2-7B 模型的有效上下文窗口,以处理多达 128k 的 tokens。他们在几个长上下文问答数据集上评估了该方法,证明 LLoCO 在推理期间使用的 token 在减少 30 倍的情况下,显著优于上下文学习。LLoCO 实现了高达 7.62 倍的加速比,并极大地降低了长文档问答的代价,是一种高效的长文本问答解决方案。https://arxiv.org/abs/2404.07979视觉语言模型(VLM)通常由一个视觉编码器(如 CLIP)和一个语言模型组成,前者解释编码特征,后者解决下游任务。然而,由于视觉编码器的能力限制,VLM 仍然存在一些缺陷,如对某些图像特征“视而不见”、视觉幻觉等。在这项工作中,来自谷歌、洛桑联邦理工学院的研究团队探讨了如何拓宽 VLM 的视觉编码能力。他们对解决 VLM 任务的几种具有不同归纳偏差的视觉编码器进行了全面的基准测试,他们发现,没有一种编码配置能在不同任务中始终保持最佳性能,而具有不同偏置的编码器的性能却惊人地相似。受此启发,他们提出了一种名为 BRAVE 的方法,其能将来自多个冻结编码器的特征整合为一种更通用的表示方法,可直接作为输入输入到冻结 LM 中。BRAVE 在广泛的字幕和 VQA 基准上实现了 SOTA,并显著减少了 VLMs 的上述问题;与现有方法相比,它所需的可训练参数数量更少,表示形式也更紧凑。https://arxiv.org/abs/2404.07204https://brave-vlms.epfl.ch/谷歌团队提出了一种高效的方法,可将基于 Transformer 的大型语言模型(LLM)扩展到无限长的输入,同时限制内存和计算量。该方法的一个关键组成部分是一种新的注意力技术——Infini-attention。据介绍,Infini-attention 在 vanilla 注意力机制中加入了压缩记忆,并在单个 Transformer 块中建立了掩码局部注意力和长期线性注意力机制。他们在长上下文语言建模基准、50 万长度的书籍摘要任务(1B 和 8B LLM)上证明了该方法的有效性。https://arxiv.org/abs/2404.07143大规模的高质量训练数据对于提高模型的性能非常重要。在使用具有理由(推理步骤)的数据进行训练后,模型将获得推理能力。然而,由于标注成本较高,高质量推理数据集相对稀缺。为了解决这个问题,华为团队提出了自我激励学习(Self-motivated Learning)框架。该框架激励模型本身在现有数据集上自动生成理由。基于多个理由的正确性固有排名,该模型通过学习生成更好的理由,从而提高推理能力。具体来说,他们利用等级来训练奖励模型,从而评估推理的质量,并通过强化学习来提高推理的性能。Llama2 7B 在多个推理数据集上的实验结果表明,该方法显著提高了模型的推理能力,甚至在某些数据集上优于 text-davinci-002。https://arxiv.org/abs/2404.07017近来,零样本文本到语音(TTS)建模技术的进步推动了高保真和多样化语音的生成,然而,对话生成以及实现类似人类的自然语音仍然是该领域的一项挑战。在这项工作中,来自微软和上海交通大学的研究团队,提出了一种用于零样本、类人、多扬声器、多轮对话语音生成的新型模型——CoVoMix。据介绍,CoVoMix 能够首先将对话文本转换成多个离散的 token 流,每个 token 流代表单个对话者的语义信息。然后,将这些 token 流输入一个基于流匹配的声学模型,生成混合旋律谱图。最后,使用 HiFi-GAN 模型生成语音波形。另外,他们还设计了一套衡量对话建模和生成效果的综合指标。实验结果表明,CoVoMix 不仅能生成自然、连贯、类似人类的对话,还能让多个对话者进行多轮对话。这些在单通道中生成的对话具有无缝语音转换(包括重叠语音)和其他语言行为(如笑声)的特点。https://arxiv.org/abs/2404.0669010.Transformer 的可解释性会转移到 RNN 吗?目前,循环神经网络架构的最新进展,如 Mamba 和 RWKV,使 RNN 在语言建模复杂性和下游评估方面的性能达到或超过等尺寸 transformer ,这表明未来的系统可能建立在全新的架构上。EleutherAI 研究了原本为 transformer 语言模型设计的部分可解释性方法是否能够迁移到这些新兴的循环架构。具体来说,他们重点研究了通过对比激活加法引导模型输出、通过调整透镜激发潜在预测,以及从微调模型中激发潜在知识,从而在特定条件下产生错误输出。结果表明,这些技术中的大多数在应用于 RNN 时都很有效,同时,利用 RNN 的压缩状态可以改进其中的一些技术。https://arxiv.org/abs/2404.05971最近,多模态大型语言模型(MLLMs)有一些新的进展。然而,这些通用领域的 MLLMs 在理解用户界面(UI)屏幕并与之有效交互的能力方面往往存在不足。苹果团队提出了 Ferret-UI,这是一种为增强对移动 UI 屏幕的理解而量身定制的新型 MLLM,具有参考、基础和推理能力。考虑到 UI 屏幕通常呈现出更长的宽高比,并且包含比自然图像更小的感兴趣的对象(如图标,文本),他们在 Ferret 上合并了 “任意分辨率” 来放大细节并利用增强的视觉功能。具体来说,每个屏幕根据原始宽高比划分为 2 个子图像(即纵向划分为纵向划分为横向划分为纵向划分为纵向划分)。两个子图像在发送到 LLM 之前分别进行编码。他们从广泛的基本 UI 任务中精心收集训练样本,查找文本和小部件列表。这些示例都经过格式化,以便使用区域注释进行指导,从而方便精确的参考和基础。为了增强模型的推理能力,他们进一步编译了高级任务的数据集,包括详细描述、感知、交互对话和功能推理。经过对策划数据集的训练,Ferret-UI 达到了 SOTA。对于模型评估,他们建立了一个包含上述所有任务的综合基准。https://arxiv.org/abs/2404.05719来自开源研究社区 Multimodal Art Projection、复旦大学和香港科技大学的研究团队及其合作者,推出了一个 20 亿参数的大型语言模型(LLM)——CT-LLM。据介绍,CT-LLM 主要采用中文文本数据,并使用了由 12000 亿个 token 组成的庞大语料库,其中包括 8000 亿个中文 token、3000 亿个英文 token 和 1000 亿个代码 token。这种策略性组合有助于该模型更好地理解和处理中文,并通过对齐技术进一步增强了这一能力。结果显示,CT-LLM 在 CHC-Bench 上表现出色,在中文任务中有不俗的表现,并通过 SFT 展示了其在英文任务中的能力。这项研究挑战了目前主要在英语语料库中训练 LLM,然后将其应用于其他语言的模式。https://arxiv.org/abs/2404.04167虽然在定制“文生图”模型方面取得了重大进展,但生成结合了多个个性化概念的图像仍然具有挑战性。在这项工作中,来自韩国科学技术院和 Adobe 的研究团队,提出了一种在推理时组成定制文本到图像扩散模型的方法——Concept Weaver。具体来说,该方法将整个过程分为两个步骤:创建与输入提示语义一致的模板图像,然后使用概念融合策略对模板进行个性化处理。融合策略将目标概念的外观融入模板图像,同时保留其结构细节。结果表明,与其他方法相比,该方法可以生成多个自定义概念,并具有更高的身份保真度。此外,该方法还能无缝处理两个以上的概念,并密切遵循输入提示的语义,而不会混合不同主体的外观。https://arxiv.org/abs/2404.03913这项工作研究了大型语言模型(LLMs)的后训练(post-training),利用来自强大 oracle 的偏好反馈来帮助模型迭代改进自身。后训练 LLM 的典型方法是人类反馈强化学习(RLHF),这种方法传统上将奖励学习和后续策略优化分开。然而,这种奖励最大化方法受限于“按点计算”奖励的性质(如 Bradley-Terry 模型),无法表达复杂的不等式或循环偏好关系。虽然 RLHF 的研究进展表明,奖励学习和策略优化可以合并为一个单一的对立目标,从而实现稳定性,但它们仍然受制于奖励最大化框架。最近,新一轮研究避开了奖励最大化的假设,转而直接对“成对”(pair-wise)或一般偏好进行优化。微软研究院团队提出了一种可证明、可扩展的算法“直接纳什优化”(DNO),其将对比学习的简单性和稳定性与优化一般偏好的理论通用性结合在一起。由于 DNO 是一种使用基于回归目标的批量 on-policy 算法,因此其实现简单高效。此外,DNO 还能在迭代过程中实现单调改进,这有助于其超越强大的“教师模型”(如 GPT-4)。结果显示,由 DNO 对齐的 7B 参数 Orca-2.5 模型在 AlpacaEval 2.0 上对 GPT-4-Turbo 的胜率达到了 33%(即使在控制了响应长度之后),比初始化模型的高出 26%(7% 到 33%)。它甚至优于参数更多的模型,包括 Mistral Large、Self-Rewarding LM(70B 参数)和旧版本的 GPT-4。https://arxiv.org/abs/2404.03715
内容中包含的图片若涉及版权问题,请及时与我们联系删除





评论
沙发等你来抢