

自 2003 年首次组装人类基因组以来,人工智能和生物学都在以惊人的速度进步,而且往往是协同的。高通量技术创造了一个机会,可以利用应用于大量数据集的新颖计算技术来重新设想生物学和医学。深度学习已经开始影响生物学研究,因为它能够从大规模数据中学习任意复杂的关系。然而,这些进步带来了新的挑战:我们如何解决模型预测并将其纳入现有的知识和范式?我们如何能够像计算机预言一样使用神经网络模型来评估假设并指导实验?我们如何安全地部署深度学习系统并与需要保证和决策理由的研究人员和从业者建立信任?
本文试图分两部分来解答这些问题。在第一部分中,我们重点关注转录因子 (TF) 结合的深度学习模型,该模型在核苷酸分辨率的体内结合建模方面取得了惊人的成功。我们提出了 AffinityDistillation,它利用神经网络模型进行大规模的新型计算机边缘化实验,以提取 TF-DNA 相互作用的热力学亲和力,从而生成可在后续体外实验中进行测试的定量预测。除了提供神经网络预测的生物物理解释之外,AffinityDistillation 还可以使用神经网络模型(如计算机生物物理预言)来评估某些体外现象如何/是否在体内表现出来。
本文的第二部分重点关注深度学习系统的安全部署,以确保它们能够适应分布变化,特别是标签变化。标签偏移是指先验类别概率 p(y) 在训练分布和测试分布之间变化,而条件概率 p(x|y) 保持固定的现象。标签转移出现在生物医学环境中,其中经过训练来预测给定症状的疾病的分类器必须适应疾病基线患病率不同的情况。在这里,我们(1)表明,将最大似然与一种称为偏差校正校准的校准相结合,在不同的数据集和分布变化上优于以前的方法,(2)证明最大似然目标是凹的,以及(3)引入原则策略 用于估计源域先验,提高对不良校准的鲁棒性。此外,通过使用校准概率作为真实类别标签的代理,我们可以估计由于弃权而导致的任意指标的变化。利用这一点,我们提出了一个通用的弃权框架,可用于优化任何感兴趣的指标,适用于测试时的标签移动,并且可以与任何可校准的分类器一起开箱即用。
总而言之,本论文开发的计算方法对于理解基因组和改善人类健康具有一定的用途。

作者:Amr Mohamed.
类型:2023年博士论文
学校:Stanford University(美国斯坦福大学)
下载链接:
链接: https://pan.baidu.com/s/1QbLqYZzVr_YVT_dYowCDWg?pwd=b7sm
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
生物学和医学深度学习面临的挑战
“机器能思考吗?”这个问题在艾伦·图灵的开创性论文中以模仿游戏的形式得到了形式化,该论文通过机器令人信服地参与对话的能力来评估机器的智能。虽然图灵测试仍未通过,但机器智能领域已经复苏。自动驾驶汽车、实时翻译以及在自己的比赛中击败世界冠军,这些都令人震惊地展示了机器学习的潜力。与此同时,使用下一代分析、移动传感器、可穿戴设备和医疗设备收集的基因组、分子、暴露组、生物识别和化学数据呈指数增长,正在改变生物研究和生物医学。由于这些转变,生物数据变得过于复杂,如果没有智能计算机系统的帮助就无法准确理解。因此,机器学习技术,尤其是深度学习,正在引起生物学家和临床医生的关注。与上述领域相比,生物数据对人类来说可能很棘手,部署的模型不仅要做出推论,还要提供人类无法提供的见解。
虽然机器学习作为一个工程领域取得了巨大进步,但这些进步并不总是立即转移到科学环境中。科学的目的是为了理解。对深度学习以及机器如何从数据中学习模式的原理和局限性的更深入理解仍然缺乏基本的理论基础。但即使超越深度学习理论,将成功的深度学习方法移植到生物环境中也存在许多挑战。其中一些挑战与解释相关,并且涉及深度学习模型及其预测如何适应现有框架。深度学习模型因无法解释的黑匣子而闻名。有人可能会说,用托马斯·库恩的术语 [2],AlphaFold 的成就是史无前例的,“正常科学”不能反对它,因为它是一种无法解释的新颖性,颠覆了其基本承诺。尽管如此,随着深度学习方法变得更加准确并作为预测模型取得成功,它们必须被整合并在成熟的科学中解释它们的预测。需要做很多工作来解决新旧问题并使之协调一致。
另一组挑战与鲁棒性相关,涉及在生物或临床环境中部署深度学习模型的困难。如今,深度神经网络能够在某些受限环境中超越人类的表现。例如,给定一个大型标记图像数据集,这些图像都具有固定尺寸并且属于一组有限的可能类别,并且每个类别在训练集中都有丰富的表示,并且测试数据来自相同的基础分布 作为训练数据,深度神经网络可以接近人类的表现。不幸的是,现实世界很少存在,尤其是在处理像活细胞和有机体这样动态的东西时。真实的生物或临床数据通常反映具有随时间变化的轨迹的过程。我们只能在固定时间点收集关于变量子集的有限数量的测量结果,且精度不理想,同时,甚至某些输入数据和标签也可能存在噪声、损坏或完全丢失。使事情进一步复杂化的是,模型用作推理引擎的目标分布可能会偏离标记训练数据采样的源分布。如果没有关于这种差异性质的信息,问题就无法明确。因此,我们留下了多种假设,所有这些假设都与观察结果兼容,同时暗示着不同的现象或暗示着不同的干预措施。
此外,模型的预期不仅是推断,而且是对复杂过程或可行干预的洞察。随着深度学习算法的科学和社会影响的增长,这一目标不再是一种学术追求,而是一种迫切的需要。在生物医学环境中部署基于脆弱的深度学习模型的决策系统可能会违反道德原则并造成伤害。
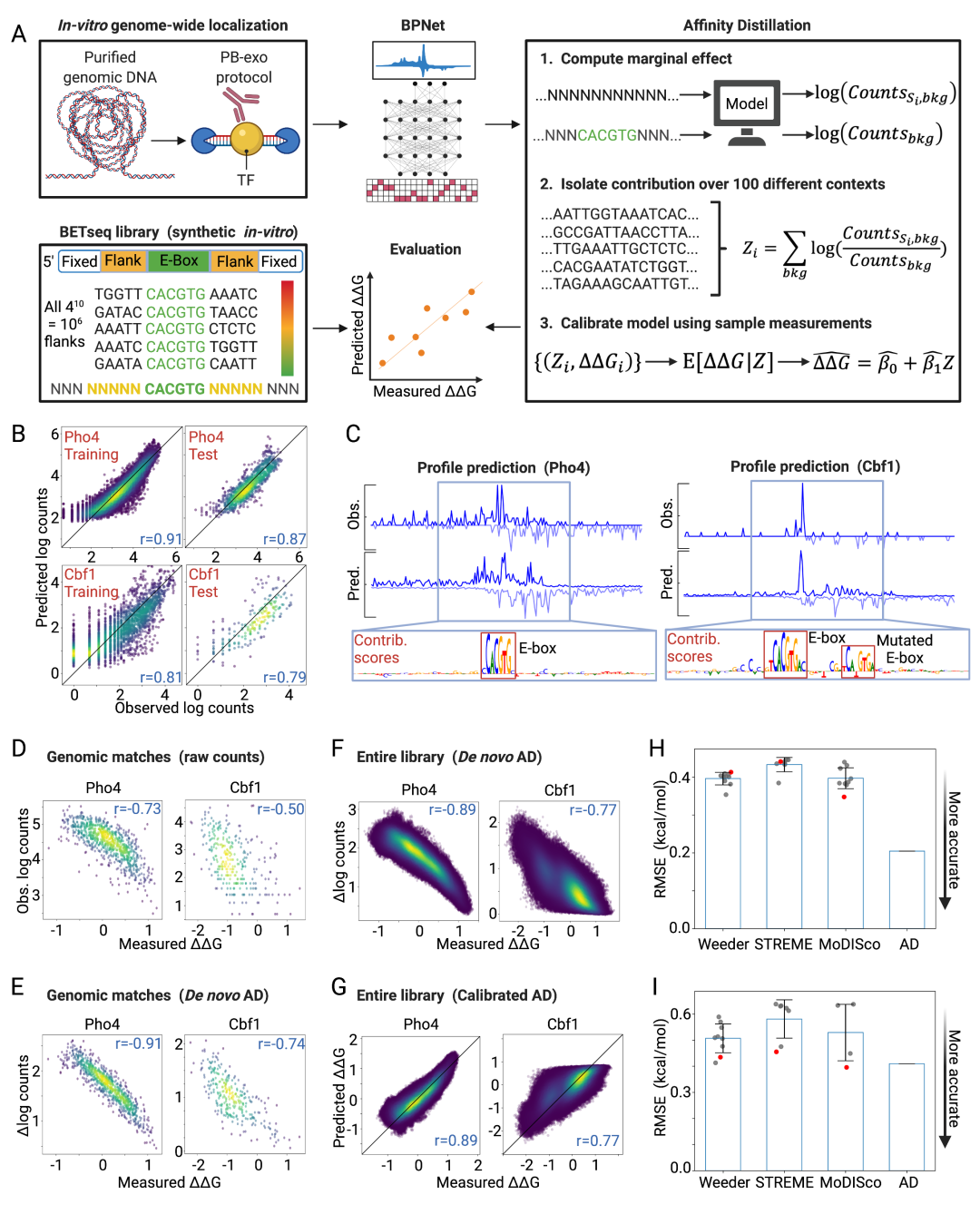
图 2.1:亲和力蒸馏从酵母中的 PB-exo 模型中提取亲和力。(A) 流程概述:BPNet 模型在 Pho4 和 Cbf1 的 PB-exo 数据上进行训练,A!nityDistillation (AD) 提取亲和力,并将 AD 输出与 BETseq 测量的 Pho4 和 Cbf1 结合 1,048,576 的所有 NNNNNCACGTGNNNNN 的“G”进行比较 序列。(B) 训练(左)和保留测试染色体(右)的 Pho4(上)和 Cbf1(下)的预测和观察到的对数转换读数计数的比较。(C) 位于保留测试染色体上的样本区域的观察 (Obs) 和预测 (Pred) PB-exo 图谱;贡献分数突出显示了绑定区域内已知的 CACGTG 共识位点。(D) 两个实验中存在的 NNNNNCACGTGNNNNN 序列的测量的对数转换的 PB-exo 读取计数与测量的“G”(Pho4 和 Cbf1 的 884 和 294 序列)。(E) AD 预测的边缘化分数与两个实验中存在的 NNNNNCACGTGNNNNN 序列的测量“G”。(F) AD 预测的边缘化分数与所有 1,048,576 个 NNNNNCACGTGNNNNN 序列的测量“G”。(G) 校准后的 AD 预测与测量了所有 1,048,576 个 NNNNNCACGTGNNNNN 序列的“”G。 (H) Pho4 的预测与观测值的校准后 RMSE。 灰色标记表示各个主题的表现; 红色标记表示每种算法顶部输出的性能; 蓝色条表示平均值; 误差线表示标准偏差。 (I) 与 Cbf1 的 H 相同。






微信群 公众号


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢