- 微软发布 Phi-3 技术报告:手机上的高功能语言模型
- Google DeepMind:先进人工智能模型的整体安全与责任评估
- MIT CSAIL 推出多模态自动可解释性智能体 MAIA
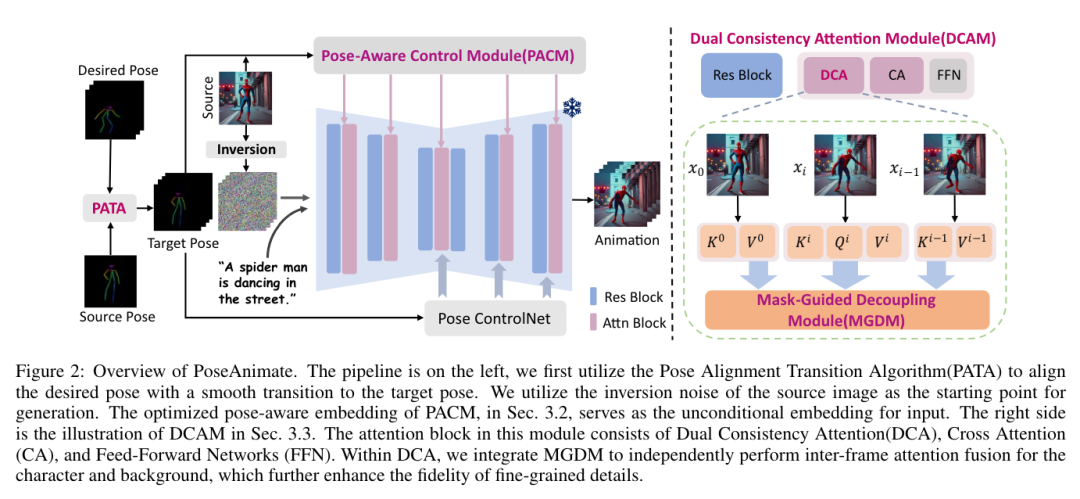
- 复旦、OPPO 提出 PoseAnimate:零样本高保真姿势可控角色动画生成
- 清华、Meta提出文生图定制生成新方法 MultiBooth
或点击“阅读原文”,获取「2024 必读大模型论文」合集(包括日报、周报、月报,持续更新中~)。
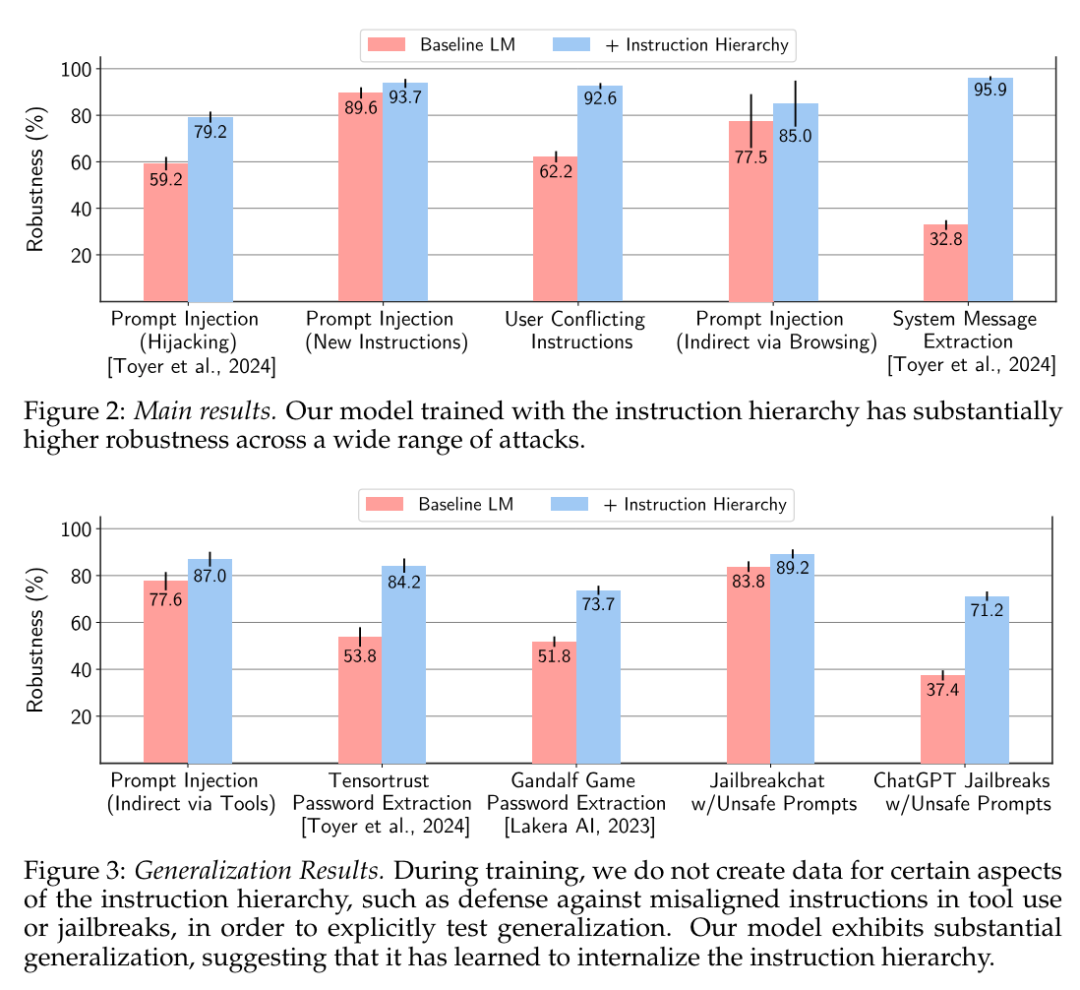
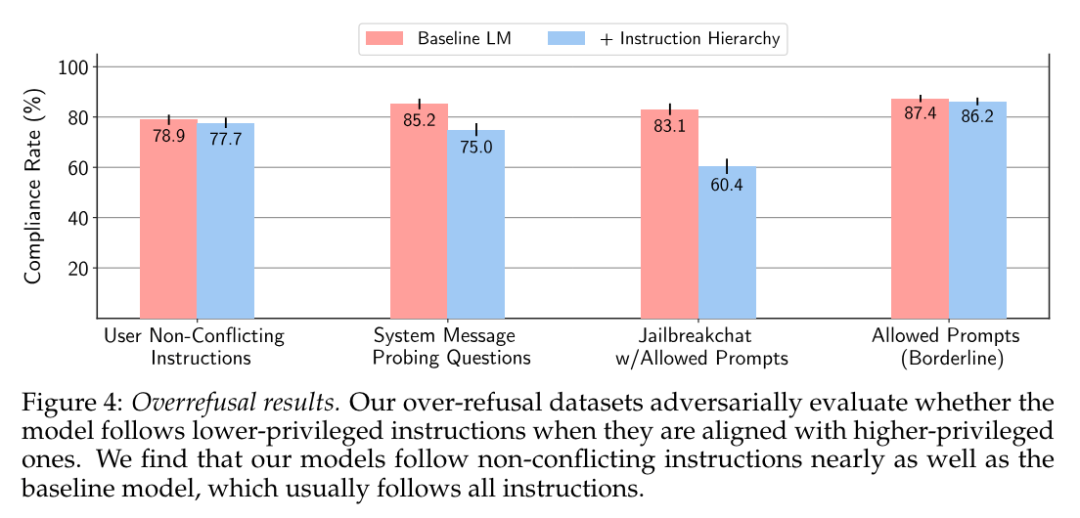
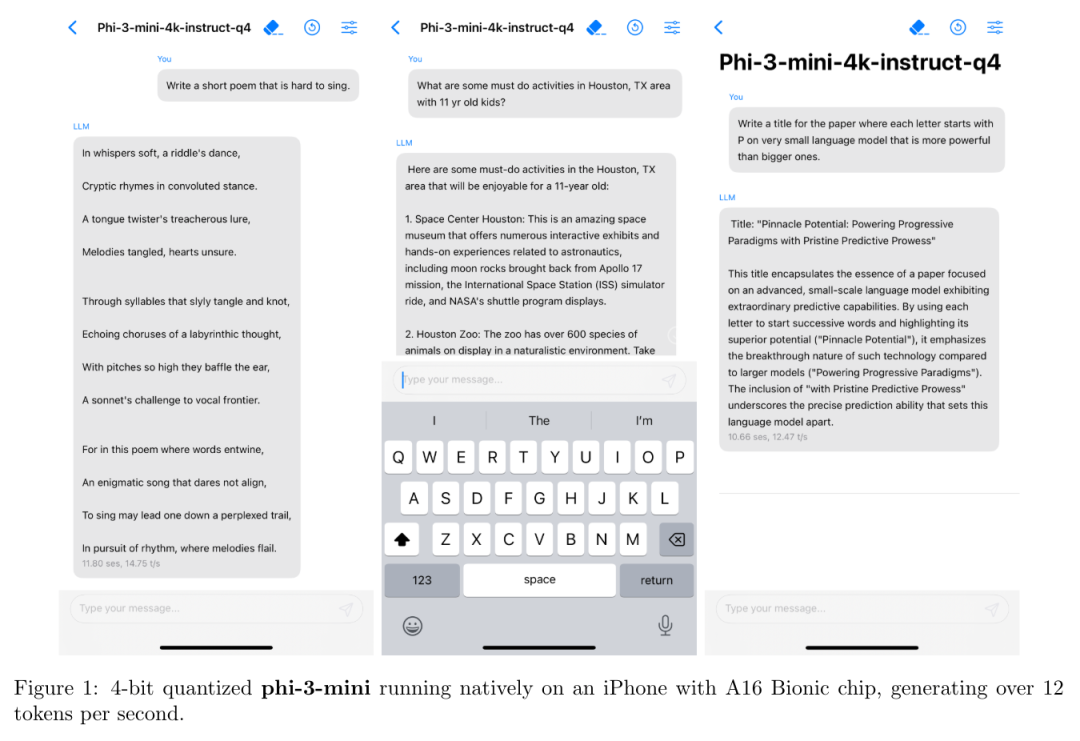
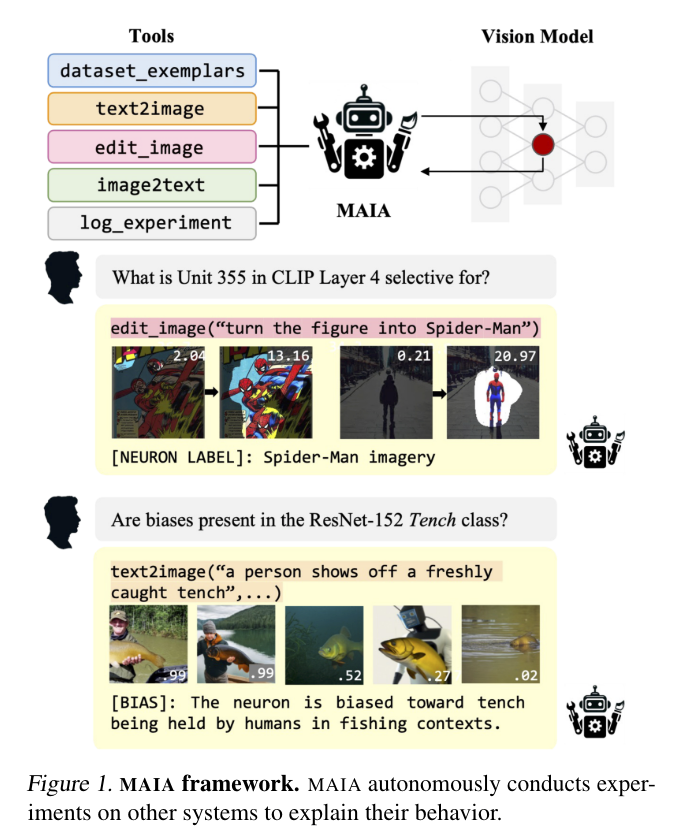
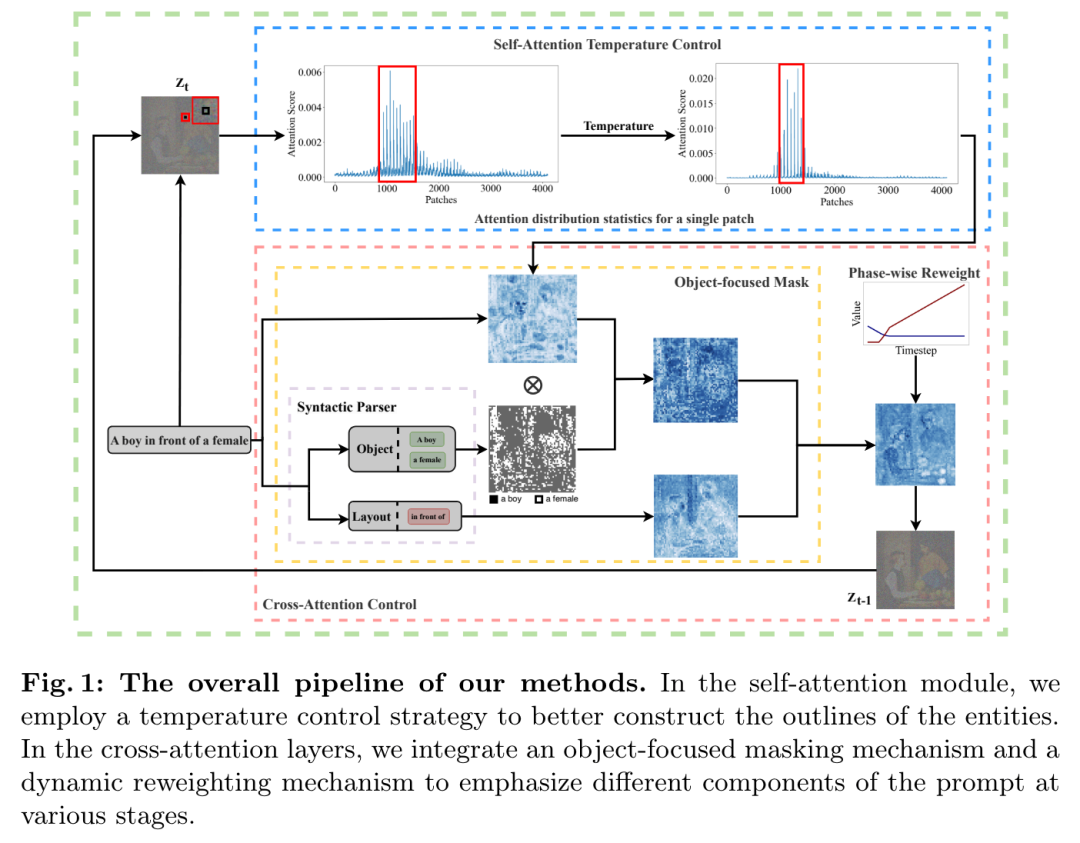
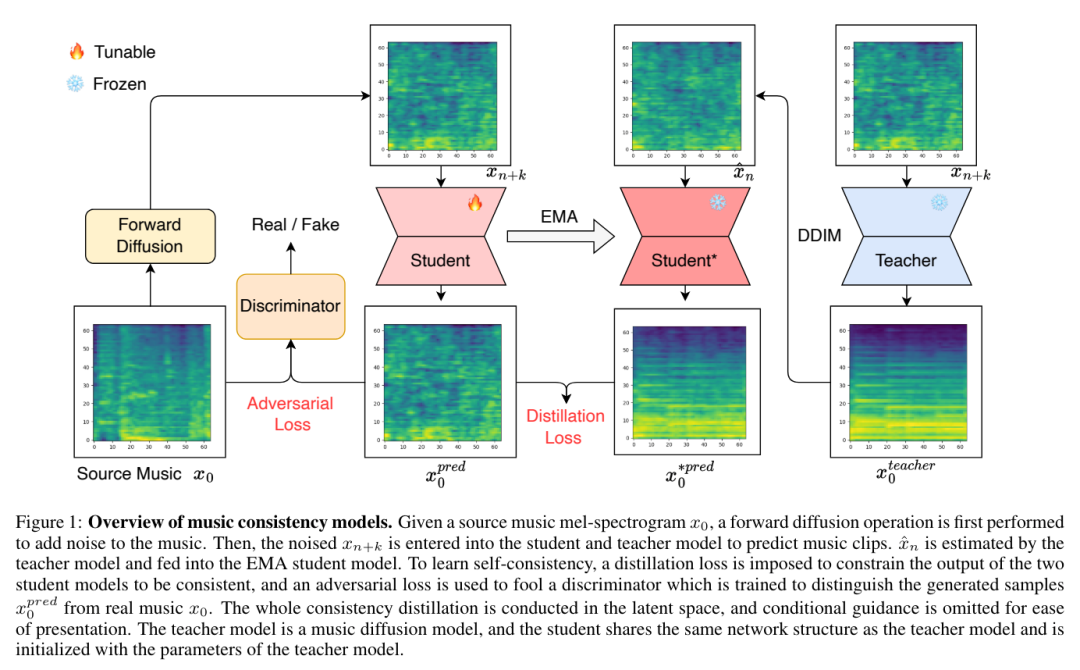
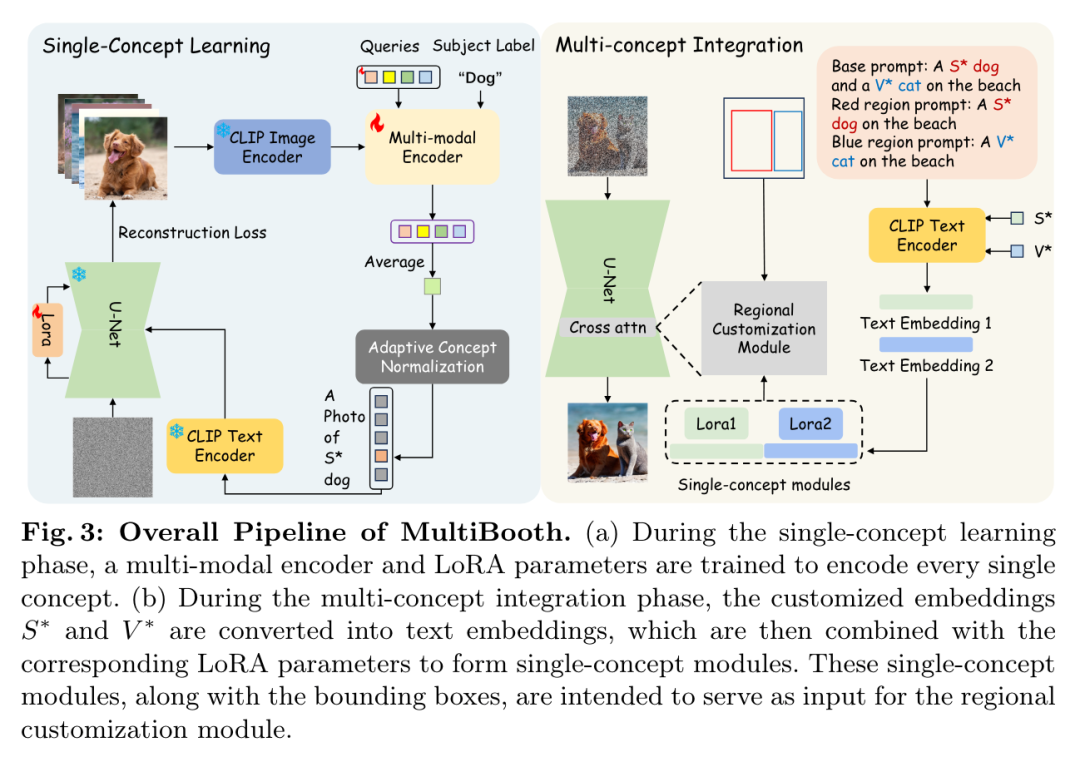
当前的大型语言模型(LLM)容易受到提示注入、越狱攻击和其他攻击的影响,这些攻击允许攻击者用他们自己的恶意提示覆盖模型的原始指令。OpenAI 研究团队认为,这些攻击的主要漏洞之一是 LLMs 经常将系统提示(比如来自应用程序开发人员的文本)与来自不可信用户和第三方的文本视为相同的优先级。为此,他们提出了一种指令层次(instruction hierarchy)结构,明确定义了当不同优先级的指令冲突时模型应该如何选择。然后,他们提出了一种数据生成方法来演示这种分层指令跟随的行为,该方法指导 LLMs 有选择地忽略低特权指令。他们将这种方法应用于 GPT-3.5,结果表明它大大提高了模型的鲁棒性——即使对于在训练过程中未见过的攻击类型也是如此,同时对标准能力的影响降到最低。https://arxiv.org/abs/2404.132082.微软发布Phi-3技术报告:手机上的高功能语言模型微软发布了 Phi-3 系列模型,包括 phi-3-mini、phi-3-small 和 phi-3-medium。其中,phi-3-mini 是一个基于 3.3 万亿个 token 训练的 38 亿参数语言模型,根据学术基准和内部测试结果,其总体性能可与 Mixtral 8x7B 和 GPT-3.5 等模型相媲美(例如,phi-3-mini 在 MMLU 上的得分率为 69%,在 MT-bench 上的得分率为 8.38),而且体积很小,可以部署在手机上。微软团队表示,Phi-3 系列模型的创新点在于他们的训练数据集,它是 phi-2 所用数据集的放大版,由经过大量过滤的网络数据和合成数据组成。他们还进一步调整了模型的鲁棒性、安全性和聊天格式。此外,他们还提供了一些初步的参数缩放结果,包括针对 4.8T token 训练的 7B 和 14B 模型,即 phi-3-small 和 phi-3-medium,这两个模型的能力都明显高于 phi-3-mini(例如,在 MMLU 上分别为 75% 和 78%,在 MT-bench 上分别为 8.7 和 8.9)。https://arxiv.org/abs/2404.142193.Google DeepMind:先进人工智能模型的整体安全与责任评估先进人工智能模型(AI)的安全性和责任评估是一个关键但尚在发展中的研究和实践领域。在 Google DeepMind 开发高级 AI 模型的过程中,他们创新并应用了一系列安全评估方法。他们总结并分享了他们不断发展的方法以及供广大受众参考的经验教训,其中包括:首先,理论基础和框架对于组织风险领域、模式、形式、指标和目标的重要性是非常宝贵的;其次,安全评估发展的理论和实践都能从合作中受益,从而明确目标、方法和挑战,并促进不同利益相关者和学科之间的见解交流;第三,类似的关键方法、教训和机构适用于责任和安全方面的各种问题 —— 包括既有的和新出现的危害。因此,从事安全评估和安全研究的广泛参与者必须共同努力,开发、完善和实施新的评估方法和最佳实践。报告最后概述了快速推进评估科学、将新的评估纳入 AI 的开发和治理、建立科学依据的规范和标准,以及促进强大的评估生态系统的明确需求。https://arxiv.org/abs/2404.140684.MIT CSAIL推出多模态自动可解释性智能体 MAIAMIT 计算机科学与人工智能实验室团队提出了一个多模态自动可解释性智能体—— MAIA。MAIA 是一个使用神经模型来自动完成神经模型理解任务(比如特征解释和故障模式发现)的系统。它为预训练的视觉语言模型配备了一系列工具,从而支持对其他模型的子组件进行迭代实验,从而解释其行为。这些工具包括人类研究人员常用的工具:合成和编辑输入,计算来自真实世界数据集的最大激活示例,以及总结和描述实验结果。MAIA 提出的可解释性实验将这些工具组合在一起,用于描述和解释系统行为。他们评估了 MAIA 在计算机视觉模型上的应用。他们首先描述了 MAIA 在图像学习表示中描述(神经元级)特征的能力。在几个经过训练的模型和一个具有配对 ground-truth 描述的合成视觉神经元新数据集上,MAIA 产生的描述与专家人类实验者生成的描述相当。此外,MAIA 可以帮助完成两个额外的可解释性任务:降低对虚假特征的敏感性,以及自动识别可能被错误分类的输入。https://arxiv.org/abs/2404.14394https://multimodal-interpretability.csail.mit.edu/maia/近来,基于大型语言模型(LLM)的智能体引起了研究界和工业界的广泛关注。与原始 LLM 相比,基于 LLM 的智能体具有自进化(self-evolving)能力,这是解决现实世界中需要长期、复杂的智能体-环境交互问题的基础。支持智能体与环境交互的关键要素是智能体的记忆。虽然以往的研究提出了许多有前景的记忆机制,但这些机制散见于不同的论文中,缺乏系统的综述,无法从整体的角度对这些工作进行总结和比较,也无法抽象出通用而有效的设计模式来启发未来的研究。为此,来自中国人民大学和华为的研究团队对基于 LLM 的智能体的记忆机制进行了全面研究。具体来说,他们首先讨论了基于 LLM 的智能体的“记忆是什么”和“为什么需要记忆”;然后,系统地回顾了以往关于如何设计和评估内存模块的研究;此外,还介绍了许多智能体应用,其中内存模块发挥了重要作用;最后,分析了现有工作的局限性,并指出了未来的重要方向。https://arxiv.org/abs/2404.13501https://github.com/nuster1128/LLM_Agent_Memory_Survey大型语言模型(LLM)在各个领域和智能体应用中都取得了显著的进步。然而,目前从人类或外部模型监督中学习的 LLM 成本高昂,而且随着任务复杂性和多样性的增加,可能会面临性能上限的问题。为了解决这个问题,使 LLM 能够自主获取、完善和学习模型自身产生的经验的自我进化(self-evolving)方法正在迅速发展。这种受人类经验学习过程启发的新训练范式为 LLM 向超级智能发展提供了可能。为此,来自北京大学、阿里巴巴和南洋理工大学的研究团队全面研究了 LLM 的自我进化方法。他们首先提出了自我进化的概念框架,并将进化过程概述为由经验的获取、完善、更新和评估四个阶段组成的迭代循环;其次,对 LLM 和基于 LLM 的智能体的进化目标进行了分类;然后,总结了相关文献,并为每个模块提供了分类和见解;最后,指出了现有的挑战,并提出了改进自我进化框架的未来方向。https://arxiv.org/abs/2404.14387https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/Awesome-Self-Evolution-of-LLM大型语言模型(LLM)因其在各种任务中的出色表现而受到广泛关注。然而,LLM 推理需要大量的计算和内存,这给在资源有限的情况下部署 LLM 带来了挑战。该领域一直致力于开发旨在提高 LLM 推理效率的技术。来自清华大学的研究团队及其合作者全面考察了有关高效 LLM 推理的现有文献。他们首先分析了 LLM 推理效率低下的主要原因,即模型规模过大、二次复杂性注意力操作和自动回归解码方法;然后,提出了一个全面的分类法,将目前的文献整理为数据级、模型级和系统级优化;此外,还对关键子领域中的代表性方法进行了比较实验,从而提供定量见解;最后,进行了一些知识总结,并讨论了未来的研究方向。https://arxiv.org/abs/2404.14294在文本到图像的生成任务中,扩散模型的进步提高了生成结果的保真度。然而,这些模型在处理包含多个实体和属性的文本提示时遇到了挑战。注意力分布不均会导致实体泄漏和属性错位问题。要解决这个问题,从头开始训练需要大量的标注数据,而且非常耗费资源。为此,来自新加坡国立大学、山东大学的研究团队提出了一种属性聚焦(attribution-focusing)机制,这是一种通过调节扩散模型的注意力来实现的免训练分阶段机制。他们的核心理念之一是引导模型在不同的时间步集中于提示的相应句法成分。为此,他们在自注意力模块的早期阶段加入了温度控制机制,从而缓解实体泄漏问题。另外,他们在交叉注意模块中集成了以对象为中心的屏蔽方案和分阶段动态权重控制机制,使模型能够更有效地辨别实体之间的语义信息关联。各种配准场景的实验结果表明,该模型能以最小的额外计算成本实现更好的图像-文本对齐。https://arxiv.org/abs/2404.138999.复旦、OPPO提出PoseAnimate:零样本高保真姿势可控角色动画生成图像到视频(I2V)生成的目的是从单张图像创建视频序列,这要求与源图像具有高度的时间一致性和视觉保真度。此外,这些方法还需要大量的视频数据来进行训练,这可能会在计算上造成困难。针对这些局限性,来自复旦大学、OPPO AI Center 的研究团队及其合作者,提出了一个用于角色动画的新型零样本 I2V 框架—— PoseAnimate。PoseAnimate 包含三个关键组件:1)Pose-Aware Control Module(PACM)将各种姿势信号纳入条件嵌入,从而保留与角色无关的内容,并保持动作的精确对齐2)Dual Consistency Attention Module(DCAM)增强了时间一致性,保留了人物身份和复杂背景细节;3)Mask-Guided Decoupling Module(MGDM)细化了鲜明特征感知,通过解耦人物和背景来提高动画保真度。他们还提出了 Pose Alignment Transition Algorithm(PATA)来确保动作的平滑转换。大量实验结果表明,这一方法在角色一致性和细节保真度方面优于最先进的基于训练的方法。此外,它还能在整个生成的动画中保持高度的时间一致性。https://arxiv.org/abs/2404.13680一致性模型在促进高效图像-视频生成方面表现出了非凡的能力,可以用最少的采样步骤进行合成。事实证明,它在减轻与扩散模型相关的计算负担方面具有优势。然而,一致性模型在音乐生成中的应用很大程度上仍未得到探索。为了填补这一空白,来自昆仑万维的研究团队提出了音乐一致性模型——Music Consistency Models,它利用一致性模型的概念高效地合成音乐片段的旋律谱图,在保持高质量的同时尽量减少采样步骤的数量。在现有文本到音乐扩散模型的基础上,MusicCM 模型结合了一致性提炼和对抗性判别器训练。此外,他们还发现,通过结合具有共享约束条件的多个扩散过程,有利于生成扩展的连贯音乐。实验结果揭示了该模型在计算效率、保真度和自然度方面的有效性。值得一提的是,MusicCM 只需四个采样步骤就能实现无缝音乐合成,例如每分钟只需采样音乐片段的一秒钟,展示了实时应用的潜力。https://arxiv.org/abs/2404.1335811.清华、Meta提出文生图定制生成新方法MultiBooth来自清华大学和 Meta 的研究团队提出了一种用于从文生图的多概念定制的新型高效技术—— MultiBooth。尽管定制生成方法取得了长足的进步,特别是随着扩散模型的快速发展,但由于概念保真度低和推理成本高,现有方法在处理多概念场景时依然困难。为了解决这些问题,MultiBooth 将多概念生成过程分为两个阶段:单一概念学习阶段和多概念整合阶段。在单概念学习阶段,他们采用多模态图像编码器和高效的概念编码技术,为每个概念学习一个简明且具有辨别力的表征;在多概念整合阶段,他们使用边界框来定义交叉注意图中每个概念的生成区域。这种方法可以在指定区域内创建单个概念,从而促进多概念图像的形成。这一策略不仅提高了概念的保真度,还降低了额外的推理成本。在定性和定量评估中,MultiBooth 都超越了各种基线,展示了其卓越的性能和计算效率。https://arxiv.org/abs/2404.14239https://multibooth.github.io/
内容中包含的图片若涉及版权问题,请及时与我们联系删除




评论
沙发等你来抢