
✍🏻 本文作者:云芑、因尘、岁星、也鹿
1. 背景
随着AI生成内容(AIGC)技术如Diffusion的飞速进展,现如今,大家已能够轻易地使用Stable Diffusion(SD)[1]等文生图的模型或工具,将心中所想仅凭语言描述(prompt)即转化为具体图像。基于此,我们不禁思考:是否有可能进一步发展该技术,允许用户通过描述来为商品定制特定背景,从而协助商家快速且轻松地打造理想的商品图像?例如,为一个包生成一个室内桌面摆放的背景,或是为某款连衣裙创造出站在海边的、气质甜美的模特形象等。
正是出于这样的设想,我们基于SD和一些图像控制模型(如controlNet[2])成功实现了这一功能,并推出了AI创意生产工具——万相实验室(https://agi.taobao.com/),生成效果如下图所示,页面上轻松点选,短短几分钟,同一个商品便可以轻松拥有千变万化的背景场景,服装模特也可以调整各种肤色发型。

然而在这一过程中,我们在商品/元素控制、模特控制、背景控制上也遇到了一系列挑战。如商品特征不准确、控制局部元素和背景虚化间存在trade off、模特属性与描述不匹配、模特手部畸形、指定颜色的纯色背景生成困难等问题。为了达到更好的效果,我们进行了一番探索并总结出了若干有效的控制方法。在接下来的文章中,我们将围绕各个问题进行详细阐述。

2. 商品/元素控制
为了实现商品换背景这一功能,最直接的方法是采用图像修复(inpainting)技术。具体来说,我们可以结合使用SD模型与inpainting controlNet,将抠出的商品视作图像的前景部分,而将其余区域视为待处理的背景。然后通过prompt精准地指导背景的修复内容。然而,直接应用开源模型容易导致商品的过度补全问题,商品特征难以正确保持。如下图展示的例子,一瓶精华液上长出了一个多余的盖子,这显然是难以接受的。为了解决这个问题,我们提出了两种方法:一是进行实例掩模(instance mask)训练,二是在推理时引入基于掩码的Canny边缘控制网络(Masked Canny ControlNet,详见论文>>https://arxiv.org/abs/2404.14768)。

2.1 Instance Mask训练
从普通inpainting模型的训练过程中,可以分析出商品过度补全的主要原因在于,在数据构造过程中,会在图像上随机圈出一个区域生成mask(如下图所示),以该mask划分前背景来训练,图上的物体很容易被这个mask给截断,因此训出的模型倾向于对物体外观形状进行联想补全。为了减少这种现象,更好地生成商品图,我们收集了一批淘宝商品图像,通过牛皮廯过滤、美观度打分等操作过滤出较为优质的数据,再通过分割模型得到商品前景的mask(如下图所示),以这种instance mask构建数据集并训练inpainting模型。

2.2 Masked Canny ControlNet推理
在使用了Instance Mask训练后,商品过度补全的现象有明显缓解,但还是有一定概率出现,于是我们在推理时加入了Canny ControlNet来帮助控制商品形状。但由于Canny ControlNet在训练时是以全图canny为条件控制训练的,直接叠加Canny ControlNet,背景区域会因为Canny图中无梯度而在生成图中虚化严重,与prompt描述不符。为此,我们提出了一种training-free的策略,如下图所示(Text Encoder和Inpainting ControlNet省略),在Canny ControlNet与U-net结合时,我们增加了一个商品前景的mask,并对该mask进行膨胀,与ControlNet的输出进行点乘,得到的结果再输入到U-net的decoder中。这一操作利用了latent与像素空间的位置一致性和controlNet训练模式的特殊性,有效地控制了商品的边缘轮廓,且排除了canny图背景区域对prompt控制的干扰。
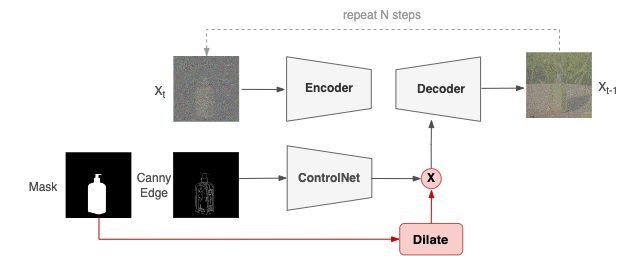
2.3 效果
使用上述两个方法后,商品过度补全的现象有明显缓解,对比如下所示。

此外,Masked Canny ControlNet还能作用到"自由元素"构图上,即为了增强画图的控制准确性,用户可以拖动一些元素(如展台、蛋糕等)的canny图到画布中,该策略将mask由前景其余扩展到前景+元素区域,可保证前景和元素的正确生成,同时避免其余背景区域过于虚化或简单,能够按promopt生成,效果如下图所示。

3. 模特属性控制
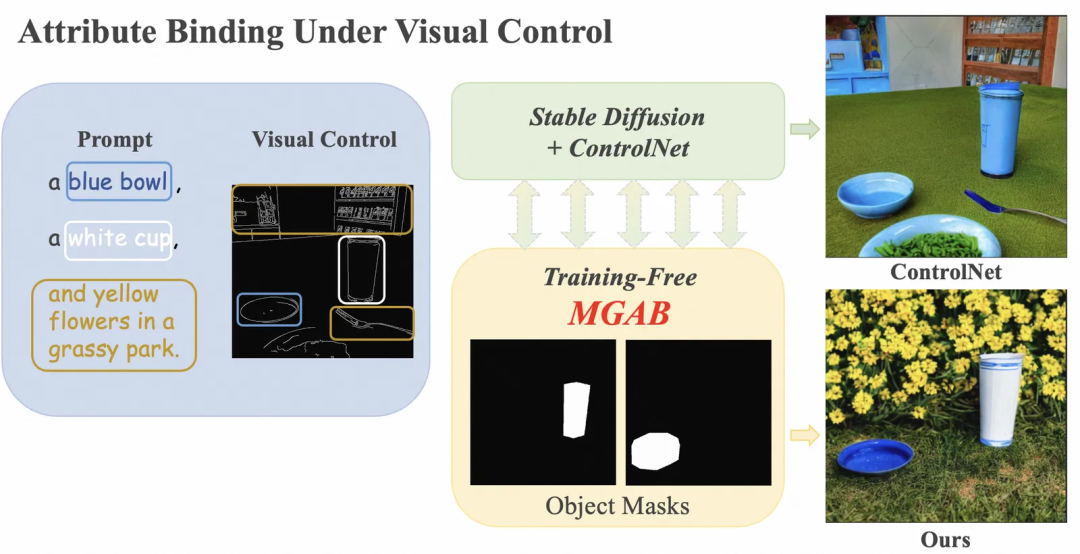
为了准确地控制视觉效果,大家经常会在prompt中给要生成的模特或者背景物体加上一些属性约束,例如红色的头发、白色的桌面等,但结果往往不尽如意,模型并不能生成指定的属性(下文简称为属性绑定问题)。如下图所示,输入prompt “a blue bowl, a white cup, and yellow flowers in a grassy park”和视觉控制条件Canny Edge, 结果如右上角所示,prompt中相关部分为“a white cup”,但SD+ControlNet错误地将杯子的颜色生成了蓝色。
目前已有文章[3]分析属性绑定问题主要是在于属性和物体的attention map重合度不高,于是有了许多training-free方法[4-6]在text-to-image文生图场景来解决这个问题。但将这些方法应用到我们的场景中时,发现图像控制图像导致其效果大打折扣,要么属性绑定失败率较高,方法失效;要么容易违背视觉条件的控制,产生用户不想要的结果或者artifacts。为此,我们提出了一种新的training-free的方法“Mask-guided Attribute Binding”(MGAB,详见论文>>https://arxiv.org/abs/2404.14768),在有图像控制的条件下实现精准的属性绑定。
3.1 解决方案
首先,我们可以通过语法分析得到物体及要绑定的属性。然后,在生图过程中,我们引入了object mask来代表视觉控制中需要绑定属性的物体区域,同时设计了简单而有效的目标函数,在视觉控制条件和object mask的双重约束下,在隐空间拉近属性词与物体词attention map分布的距离。具体来说,如下图所示,文本提示和图像条件作为图像控制生成的基本输入,其中表示提示的长度。此外,还提供了相关的object mask集合 ,其中表示与和中描述的第个对象相关联的mask。我们用设计的损失函数,在去噪过程中的每个时间步迭代地去噪并更新噪声的latent变量。
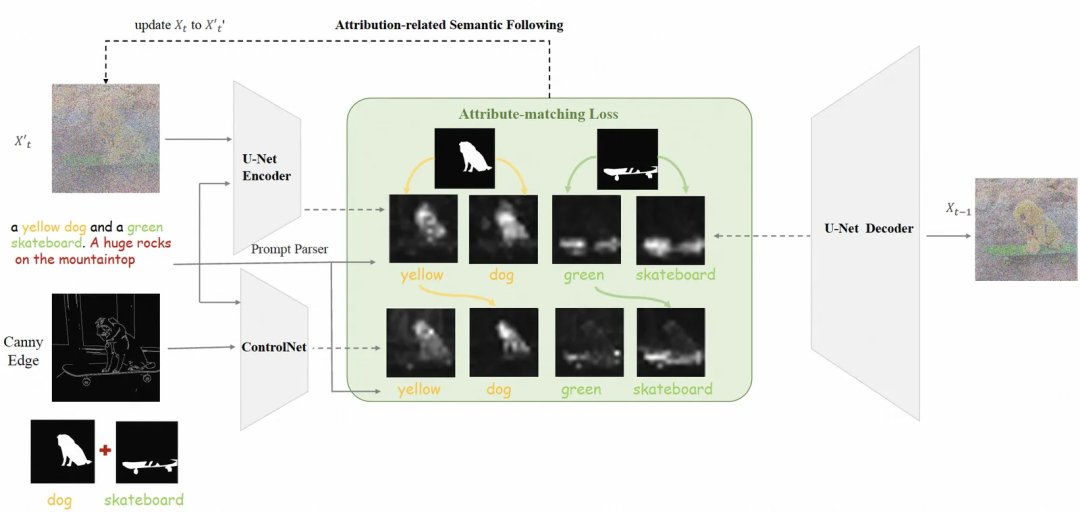
我们使用依存关系解析器spaCy来分析文本prompt,并提取出所有的属性词-物体词组合。中包含对组合,和分别表示物体词和对应属性词索引。和分别代表prompt中与视觉控制条件匹配/不匹配两部分的关系集合。在前向降噪过程中,我们可以分别从SD和ControlNet中获得与promopt的cross attention map,分别命名为和,代表了文本prompt中的词与视觉像素之间的相关程度。对于prompt提示词,attention map的计算公式如下:
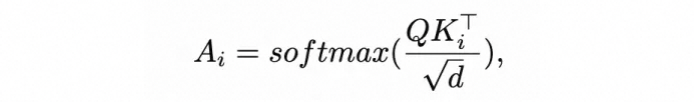
其中,和分别来自于和的embedding变形后表示。我们的主要目标是,在视觉控制和object mask的条件下,最小化中属性词-物体词组合 的attention map的分布距离。为此,我们设计了一个损失函数,Language-guided loss。
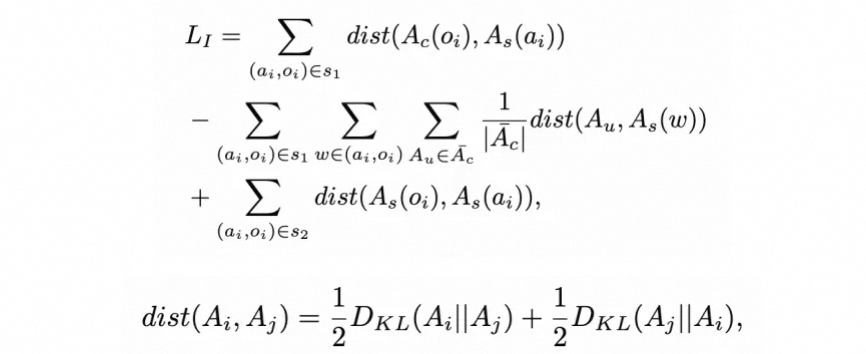
其中,是一个计算attention maps之间距离的函数,代表和之间的KL散度。这个loss将在每一步降噪中,不断拉近物体词在中的attention map与属性词在中的attention map的距离,同时将,的attention map与跟它们不相关的提示词对应的attention map拉远。
更进一步的,我们还提出了另一个Mask-guided loss ,将目标物体和它对应的属性词的attention map的关注的区域都最大程度的限制在object mask区域内:
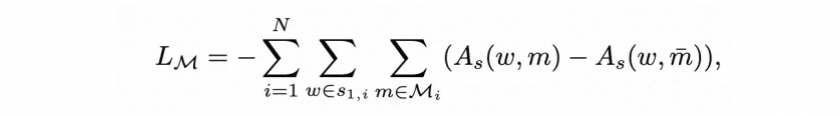
其中,等式右侧括号的两个对象,前者代表提示词对应的里attention map在object mask 里的权重,后者则代表在object mask 外的权重。显然,在迭代过程中,前者将越来越大,后者反之。
最终,Language-guided loss和Mask-guided loss将结合起来,在前向降噪的每一步通过更新zt来拉近物体词和对应属性词attention map的分布。
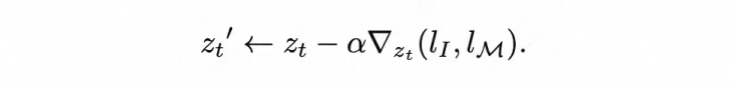
3.2 效果展示
我们分别结合四种不同类型的ControlNet,复现了各种提升属性绑定准确度的方法,并与我们的方法在coco上进行实验和对比。可以看到我们的方法在属性绑定、与prompt的匹配程度等方面均有比较明显的提升,且并不会对成图质量产生明显的负面影响。

在业务场景,我们提出的这个方法也有较好的表现。如下图所示,第一列为商品前景,第二列为优化前效果,第三列为属性绑定优化后效果。



4. 模特手部控制
在生成模特的过程中,手部畸形也是常见的一个问题。我们关注到社区中现有的几种优化方案,包括Negative Prompt、Negative Embedding[7]、LoRA[8]等轻量级方案。如下图所示,我们尝试了以上方法,发现相比于直接生成手部图像,使用这些方法只能带来极其有限的改进效果。
仅依赖扩散模型自身的能力并不能保证手部区域的稳定正确生成,这可能是因为手部结构精细、手势变化万千但又具有特定的物理规律。借鉴脸部修复的思路,我们考虑采用后处理的方式,先生成图像,再检测畸形手,将畸形手区域进行局部放大和重绘。但手势比脸部五官的模式更为复杂,直接重绘容易出现手腕、手势和原图对应不上等问题,且畸形率仍然很高,因此我们引入了额外的结构控制来保持一致性。

4.1 解决方案
为了引入手部结构的控制,我们对可控制结构的各种controlNet进行了分析。
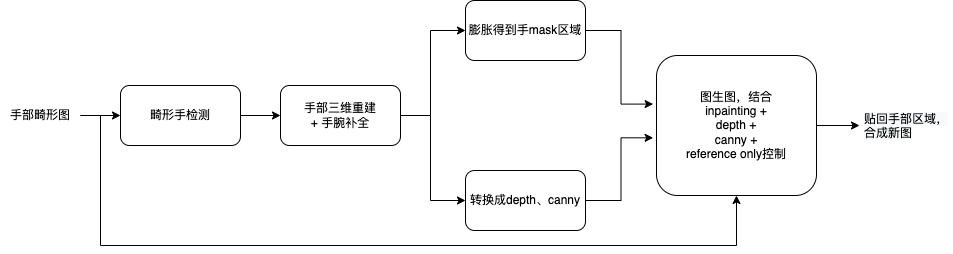
如下图所示,我们从原始的模特图像中提取或预估出五种结构控制图像。可以发现,softedge、canny包含边界信息但无手指前后位置关系信息,depth与normal包含深度信息但边界不明显,同时从图像中提取的手部区域控制信息噪声较大,较难实现对结构的精准控制。pose预估模型由于包含手部结构的先验,使得pose中的手部结构是预估出的五种控制图像中最为清晰完整的,但它仅包含二维的手部结构骨架,难以表示如手指粗细、前后关系等信息,用于结构控制时效果不佳。且从原图直接提取的这些控制条件,因为原图手部畸形,难免都会陷入控制准确度和手部结构正确度之间的trade off。

那么我们能否找到这样的理想控制图像呢?它即能利用手部结构的先验,从原图提取出位置和手势与原手基本一致且正确的手部结构,又能表示出如手指粗细、前后关系等精准关键信息以加强控制。为实现这一目标,如下图所示,我们首先对畸形手部图像使用了三维手部重建,即在手部结构先验的约束下,从二维RGB图像中预估出三维参数化手部模型,手部结构的一致性和正确性得到较好保证;接着,我们将三维重建结果渲染并转换为depth与canny图,以形成对手形状、深度等各维度的强控制,配合ControlNet利用扩散模型的局部重绘能力修复手部结构。
4.2 效果
通过以上方法,畸形手修复的成功率大幅提高,下面是一些修复结果。

5. 纯色背景控制
在万相实验室服务过程中,我们观测到服饰类商家对纯色背景的需求很大,且希望能够指定纯色背景的色系。但对sd而言,生成指定颜色的纯色背景是比较困难的[9],容易产生如下图所示的背景颜色不均匀、人物头发被"染色"等现象。

为了解决模型难以生成指定的纯色背景的问题,我们提出先 Shuffle Controlnet 结合 local mask 的方式 及 基于LoRA的方式 进行控制以生成白底背景,并引入后处理操作以生成指定颜色的纯色背景。
5.1 白底背景生成
为了生成具有较好光影感的白底图,我们采用对图像的风格参考较强的Shuffle ControlNet 进行控制,输入为一张纯白色的参考图;同时为了避免影响前景部分的生成效果,我们同上文所述的Masked Canny ControlNet一样,引入mask 来控制 Shuffle ControlNet 仅作用于背景区域。此外,我们优化了生图时的 prompt,使得结果图在白底的基础上具有一定的光影效果。
为了提高白底图的效果稳定性,我们还使用了一种基于LoRA的方案。我们收集了大量高视觉美观度的纯色棚拍图,为提高LoRA与Inpainting ControlNet的兼容性,我们对图像进行分割处理,获得人物前景与背景,配合Inpainting ControlNet训练一个LoRA来生成纯色背景。
5.2 指定颜色后处理
在此基础上,为了生成指定颜色的背景,我们首先对白底图进行前景分割,然后以color matcher[10]的方式对背景进行颜色变换,具体来说,color matcher会接受一张颜色参考图和白底图的背景,并通过线性变换的方式将白底图背景映射为参考图的颜色。最后我们将前景和变换后的背景结合起来得到最终的结果图。
5.3 效果
基于这种两步法,我们能比较稳定地实现指定颜色的纯色背景生成,效果如下所示:

6. 总结与展望
我们通过SD和一些图像控制模型实现了商品换背景换模特功能,并通过一些方法加强了商品/元素控制、模特控制、纯色背景控制,使得生成控制更精准、视觉效果更好,目前这一功能已上线了万相实验室供广大商家使用。但在商品图生成上仍有很多值得去探索优化的地方,比如diffusion模型生图速度慢、前背景光线融合感不够强等,我们将持续优化模型能力和产品使用体验,为广大商家提供更方便更高效的智能创意制作能力。
▐ 关于我们
我们是阿里妈妈智能创作与AI应用团队,专注于图片、视频、文案等各种形式创意的智能制作与投放,产品覆盖阿里妈妈内外多条业务线,欢迎各业务方关注与业务合作。同时,真诚欢迎具备CV、NLP相关背景同学加入,一起拥抱 AIGC 时代!感兴趣的同学欢迎投递简历加入我们。
✉️ 简历投递邮箱:alimama_tech@service.alibaba.com
▐ 参考文献
团队论文:
Hongyu Chen, Yiqi Gao, Min Zhou, Peng Wang, Xubin Li, Tiezheng Ge, Bo Zheng. Enhancing Prompt Following with Visual Control Through Training-Free Mask-Guided Diffusion, arXiv preprint arXiv:2404.14768, 2024.
其他论文:
[1] https://stability.ai/news/stable-diffusion-public-release
[2] Lvmin Zhang, Anyi Rao, Maneesh Agrawala. Adding Conditional Control to Text-to-Image Diffusion Models. ICCV2023: 3813-3824
[3] aphael Tang, Linqing Liu, Akshat Pandey, Zhiying Jiang, Gefei Yang, Karun Kumar, Pontus Stenetorp, Jimmy Lin, and Ferhan Ture. What the daam: Interpreting stable diffusion using cross attention. ACL 2023: 5644-5659
[4] Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or.Attend-and-excite:Attention-based semantic guidance for text-to-image diffusion models.ACM Transactions on Graphics (TOG), 42(4):1–10, 2023.
[5] Royi Rassin, Eran Hirsch, Daniel Glickman, Shauli Ravfogel, Yoav Goldberg, and Gal Chechik. Linguistic binding in diffusion models: Enhancing attribute correspondence through attention map alignment. NeurIPS 2023.
[6] Weixi Feng, Xuehai He, Tsu-Jui Fu, Varun Jampani, Arjun Akula, Pradyumna Narayana, Sugato Basu, Xin Eric Wang, and William Yang Wang. Training-free structured diffusion guidance for compositional text-to-image synthesis. arXiv preprint arXiv:2212.05032, 2022.
[7] https://civitai.com/models/56519/negativehand-negative-embedding
[8] https://civitai.com/models/200255/hands-xl-sd-15
[9] Shanchuan Lin, Bingchen Liu, Jiashi Li, Xiao Yang. Common Diffusion Noise Schedules and Sample Steps are Flawed. WACV2024: 5392-5399
[10] F. Pitie and A. Kokaram, "The linear Monge-Kantorovitch linear colour mapping for example-based colour transfer," 4th European Conference on Visual Media Production, London, 2007, pp. 1-9, doi: 10.1049/cp:20070055.

也许你还想看
丨ACM MM’23 | 4篇论文解析阿里妈妈广告创意算法最新进展
丨营销文案的“瑞士军刀”:阿里妈妈智能文案多模态、多场景探索
丨CVPR 2023 | 基于无监督域自适应方法的海报布局生成

喜欢要“分享”,好看要“点赞”哦ღ~
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢