

《追AI的人》之AI科普系列短视频,将持续用简单清晰的语言向公众解释对于人工智能的普遍疑问,推动社会就人工智能的发展和治理达成共识。

从前面的分析得知,很多风险是从训练使用的数据,以及训练方法引入的;而且由于深度神经网络的不可解释性,我们无法确定网络中哪部分参数对应这些风险,也没有技术手段在生成阶段禁止模型生成风险内容。这决定了以工程化的风险治理视角分析,结合国内外法规和倡导性意见,生成式人工智能的风险治理需要贯穿产品的全生命周期——模型训练、服务上线、内容生成、内容发布与传播各阶段。同时,训练数据和模型参数规模巨大、深度神经网络的不可解释性,为鼓励新技术的发展,结合国际治理实践,又需要对可能出现的风险保持审慎包容的态度。
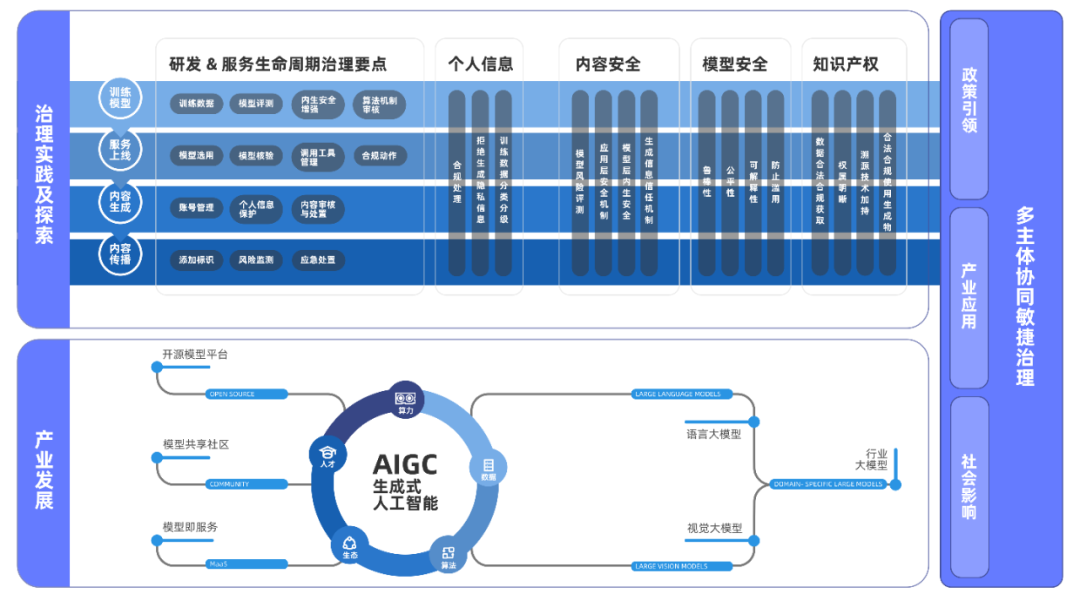

训练阶段奠定了模型的能力基础,也决定了模型自身的安全性;这个阶段会涉及到数据和模型,不会和用户发生关联。相应的风险治理工作包括:
2.1.1 训练数据的筛选和过滤
采集时对数据源进行审核,选择可信度高、正确导向的数据源合法进行采集;采集后对数据进行清洗、安全过滤,剔除含有风险的数据。在有监督微调阶段、基于人类偏好的强化学习阶段涉及到标注的数据,需要进行机器和人工相结合的审核。数据的质量在很大程度上决定了模型能力和安全性的上限。
针对生成式人工智能的特点,进行风险定义,建设Benchmark和评测能力,对模型风险做全面深入的评测。Benchmark的构建,需要考虑多个维度:风险分类、对模型的诱导方式、事实幻觉,以及针对特定领域Query的识别。风险分类包括但不限于内容安全、个人信息、模型安全等;诱导方式包括但不限于直接提问、多轮问答、角色扮演、安全否定、信息投毒等;事实幻觉考察大模型生成内容与事实是否符合;针对医疗、投资等特定领域的评测,对公众提供服务时回答这些领域的问题可能需要相关资质。
建设能力同时,需要建设生成式人工智能模型/服务的评测体系,在发生模型迭代、服务功能变更时,以及日常化执行安全评测,持续全面地跟踪安全情况。
2.1.3 模型对齐与内生安全增强
首先,通过技术手段将人类价值观量化并嵌入模型,令生成式人工智能“理解”人类的价值,保障在运行实施阶段能够遵循。针对评测中发现的问题,采取技术手段在模型迭代时增强内生安全能力。模型内生安全能力能够从根本上保障模型的安全性,能够有效减轻外部安全措施的压力,降低风险内容生成的可能性。内生安全的增强,可以贯穿模型训练的三个阶段,在每个阶段有不同的方式。
2.1.4 算法机制机理审核
企业内的风险管理团队需要在生成式大模型构建的早期就介入,围绕生成式人工智能产品全生命周期的潜在风险要素,对模型的目的、采用的技术、使用的数据、干预的方式等重要因素开展审核,对不合规、不合理的部分提出具体可实施的整改要求,并监督有关部门尽快落实,将安全隐患遏制于研发阶段。
| 2.2 服务上线阶段的风险治理
在算法服务上线阶段,服务提供者需要选择安全有效的模型作为基座构建完整的算法服务。在这个阶段并不涉及模型的训练、使用的数据,但是会决定对模型的核验、对模型的使用方式、调用的工具集等。
模型选用:在模型能力满足业务需求的前提下,服务提供者可以选用具有良好资质和声誉的技术支持者提供的模型,模型应尽可能满足鲁棒性、可解释性、可追溯性等指标要求。
模型核验:服务提供者在使用前对模型进行核验,完成多维度安全评测。服务提供者并不一定具备进行多维度安全评测的能力,需要由中立的第三方机构提供评测服务。
服务需要使用的工具集(Tool-plugin):服务提供者根据业务目的明确在服务过程中调用哪些工具,验证其合理性和必要性;决定工具集返回信息的使用方式;进行安全测试,确保工具提供的信息不会导致模型产生违法不良信息、错误倾向等内容。
合规动作:企业自行开展算法安全自评估,对算法目的、使用的数据、模型、训练方法、评测过程、干预策略等进行评审。根据主管部门的管理办法要求,技术提供者和服务提供者需要向主管机关做相关的算法备案、向用户提供用户协议、公示算法机制机理等,在运行过程中根据审计要求建立完善的日志。
| 2.3 内容生成阶段的风险治理
大模型生成的内容是用户和模型交互的结果。用户的输入,以及模型对用户之前输入的反馈,都影响到模型当前的生成。用户使用生成式人工智能服务的目的、是否主观上给出恶意输出和诱导,很大程度上决定了模型输出内容的安全性。生成式人工智能服务,是用户达成目的的工具。实践中,内容安全的风险很大程度上是来自于用户的恶意输入和诱导,从用户维度进行管控也是非常有效的手段之一。这就意味着,服务提供者对生成内容的风险管理并不局限在内容维度,还需要扩展到用户维度。具体的工作包括:
2.3.1 账号管理
按照相关法规,完成账号的注册、身份核验、安全管控、账号的分类分级等管理工作。对于用户的身份核验,《互联网信息服务深度合成管理规定》中明确指出:“深度合成服务提供者应当基于移动电话号码、身份证件号码、统一社会信用代码或者国家网络身份认证公共服务等方式,依法对深度合成服务使用者进行真实身份信息认证,不得向未进行真实身份信息认证的深度合成服务使用者提供信息发布服务”。《生成式人工智能服务管理暂行办法》没有做进一步的要求,但参考相关定义,生成式人工智能服务提供者也应当遵守包括《互联网用户账号信息管理规定》在内的相关法律法规规定,在前端对账号进行管理,降低生成内容的风险。
2.3.2 个人信息保护
《互联网信息服务深度合成管理规定》中明确指出:深度合成服务提供者和技术支持者提供人脸、人声等生物识别信息编辑功能的,应当提示深度合成服务使用者依法告知被编辑的个人,并取得其单独同意。《生成式人工智能服务管理暂行办法》中要求,在模型训练过程中涉及个人信息的,应当取得个人同意;(技术、服务)提供者不得收集非必要个人信息,不得非法留存能够识别使用者身份的输入信息和使用记录,不得非法向他人提供使用者的输入信息和使用记录。提供者应当依法及时受理和处理个人关于查阅、复制、更正、补充、删除其个人信息等的请求。
2.3.3 内容审核与处置
审核机制:建立内容审核的制度、专职团队;对用户输入信息、模型输出信息进行安全审核;对不同时效要求的业务场景采取不同的审核方式。
内容分类分级:对于涉及生物特征,包含特殊含义物体,新闻等生成内容进行更严格的审核。
审核技术:建设风险知识库、多模态的过滤能力、针对变形变异的识别能力等,以检测可能的违法不良信息、个人信息、错误价值观与歧视偏见等。
正向引导:针对底线及原则问题,需要建设标准答案库。一方面避免因为模型的行为不可控性做出错误的回答,另一方面也可以通过标准答案传递主流价值观,进行正向引导。
不当内容处置:建立阻断机制;对于模型生成不适宜内容的情况,具备应急处理的技术手段等。
| 2.4 内容传播阶段的风险治理
内容的传播方式和途径、范围是风险的决定性因素之一。在传播环节出现的风险,需要建立相应的风险治理技术手段和工作机制。
2.4.1添加标识
《互联网信息服务深度合成管理规定》明确定义,深度合成服务可能导致公众混淆或者误认的,应当在生成或者编辑的信息内容的合理位置、区域进行显著标识,向公众提示深度合成情况。这些场景包括:
智能对话、智能写作等模拟自然人进行文本的生成或者编辑服务;
合成人声、仿声等语音生成或者显著改变个人身份特征的编辑服务;
人脸生成、人脸替换、人脸操控、姿态操控等人物图像、视频生成或者显著改变个人身份特征的编辑服务;
沉浸式拟真场景等生成或者编辑服务;
其他具有生成或者显著改变信息内容功能的服务。
为了实现对生成合成内容的确认和溯源,推荐对生成内容添加隐藏标识,记录服务提供者、服务使用者、生成时间等信息。隐藏标识应具备足够的抗攻击能力、溯源能力。目前,针对图像、视频的隐藏标识在技术上比较成熟,达到实践中可用的程度;针对文本的隐藏标识能力技术上尚未成熟。《生成式人工智能服务管理暂行办法》要求,(技术、服务)提供者应当按照《互联网信息服务深度合成管理规定》对图片、视频等生成内容进行标识。
2.4.2 风险监测
信息监测:建立舆情监测、前台内容巡检等工作机制。
举报投诉:建立举报投诉入口,并及时处理。
2.4.3 应急处置
建立辟谣机制,建立应急处理响应机制并做演练。在虚假信息传播时,尽早进行处置可以有效控制传播范围和深度。








关注公众号发现更多干货❤️



内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢