
最近,扩散模型(Diffusion Model)在图像生成领域取得了显著的进展,为图像生成和视频生成任务带来了前所未有的发展机遇。尽管取得了令人印象深刻的结果,扩散模型在推理过程中天然存在的多步数迭代去噪特性导致了较高的计算成本。近期出现了一系列扩散模型蒸馏算法来加速扩散模型的推理过程。这些方法大致可以分为两类:i) 轨迹保持蒸馏;ii) 轨迹重构蒸馏。然而,这两类方法会分别受到效果天花板有限或者或输出域变化这两个问题的限制。
为了解决这些问题,字节跳动技术团队提出了一种名为 Hyper-SD 的轨迹分段一致性模型并开放了权重。Hugging Face CEO Clem Delangue 也发了推文向全球社区成员介绍。
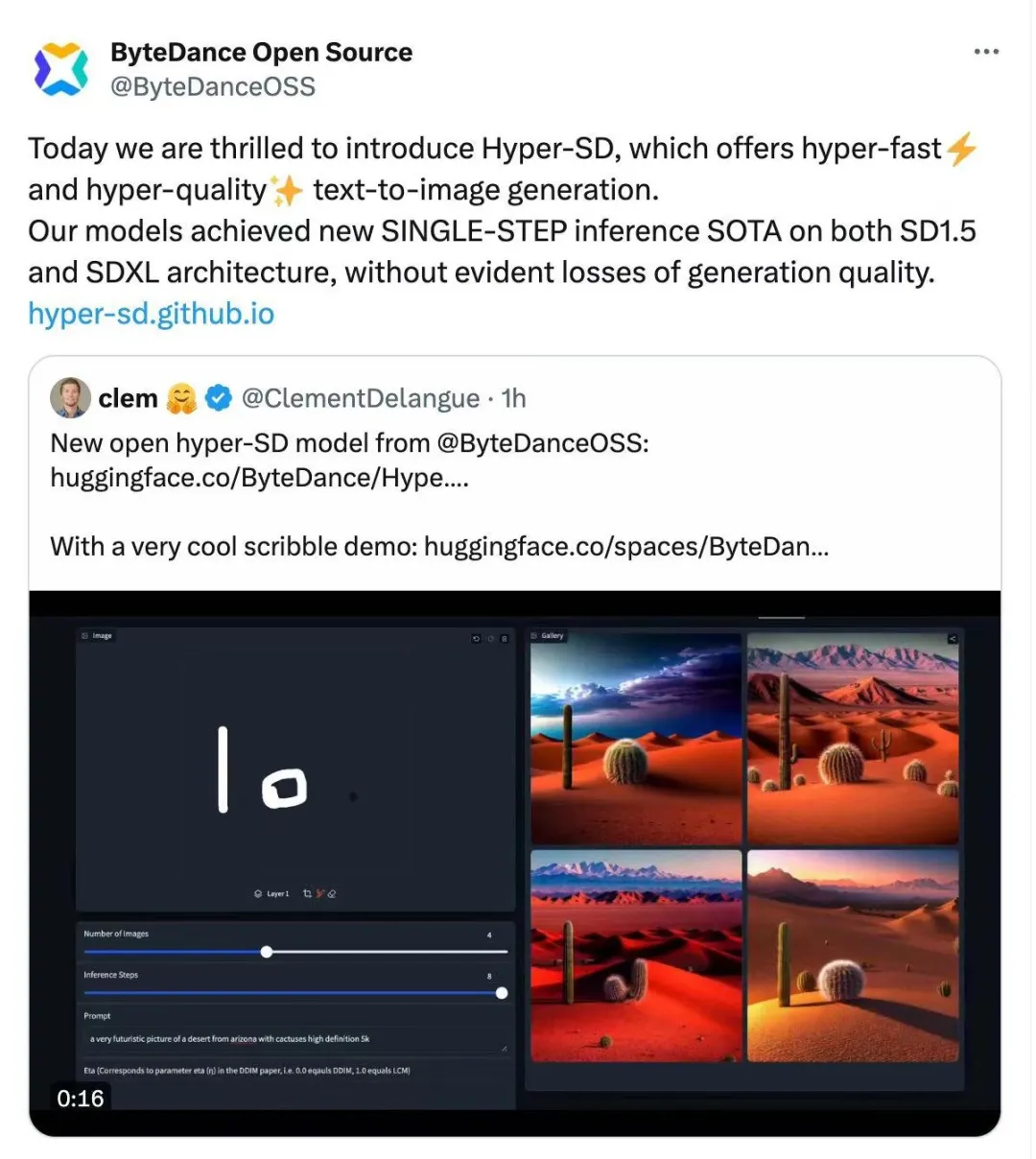
该模型是一种新颖的扩散模型蒸馏框架,结合了轨迹保持蒸馏和轨迹重构蒸馏两种策略的优点,在压缩去噪步数的同时保持接近无损的性能。与现有的扩散模型加速算法相比,该方法取得了卓越的加速效果。经过大量实验和用户评测的验证,Hyper-SD 在 SDXL 和 SD1.5 两种架构上都能在 1 到 8 步生成中实现 SOTA 级别的图像生成性能。

项目主页:https://hyper-sd.github.io/
论文链接:https://arxiv.org/abs/2404.13686
Hugging Face 链接:
https://hf.co/ByteDance/Hyper-SD单步生成 Demo 链接:
https://hf.co/spaces/ByteDance/Hyper-SDXL-1Step-T2I实时画板 Demo 链接:
https://hf.co/spaces/ByteDance/Hyper-SD15-Scribble
引言
现有用于扩散模型加速的蒸馏方法大致可以分为两大类:轨迹保持蒸馏和轨迹重构蒸馏。轨迹保持蒸馏技术旨在维持扩散对应的常微分方程(ODE)的原始轨迹。其原理是通过迫使蒸馏模型和原始模型产生相似的输出来减少推理步骤。然而需要注意的是,尽管能够实现加速,由于模型容量有限以及训练拟合过程中不可避免的误差,这类方法可能导致生成质量下降。相比之下,轨迹重构方法则直接利用轨迹上的端点或真实图像作为监督的主要来源,忽略了轨迹的中间步骤,能够通过重建更有效的轨迹来减少推理步骤的数量,并在有限的步骤内探索模型的潜力,将其从原始轨迹的约束中解放出来。然而,这通常会导致加速模型与原始模型的输出域不一致,从而得到不理想的结果。
本论文提出了一种结合轨迹保持和重构策略优点的轨迹分段一致性模型(简称 Hyper-SD)。具体而言,该算法首先引入轨迹分段一致性蒸馏,在每个段内强制保持一致性,并逐渐减少段的数量以实现全时一致性。这一策略解决了由于模型拟合能力不足和推理误差累积导致的一致性模型性能次优的问题。随后,该算法利用人类反馈学习(RLHF)来提升模型的生成效果,以弥补加速过程中模型生成效果的损失,使其更好地适应低步数推理。最后,该算法使用分数蒸馏来增强一步生成性能,并通过统一的 LORA 实现理想化的全时间步数一致扩散模型,在生成效果上取得了卓越的成果。
方法
1. 轨迹分段一致性蒸馏
一致性蒸馏(CD)[24] 和一致性轨迹模型(CTM)[4] 都旨在通过一次性蒸馏将扩散模型转换为整个时间步范围 [0,T] 的一致性模型。然而,由于模型拟合能力的限制,这些蒸馏模型往往达不到最优性。受到 CTM 中引入的软一致性目标的启发,我们通过将整个时间步范围 [0, T] 划分为 k 段并逐步执行分段一致模型蒸馏来细化训练过程。
在第一阶段,我们设置 k=8 并使用原始扩散模型来初始化 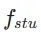 和
和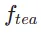 。起始时间步
。起始时间步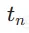 是从
是从 中均匀随机采样的。然后,我们对结束时间步
中均匀随机采样的。然后,我们对结束时间步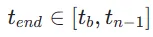 进行采样,其中
进行采样,其中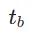 计算如下:
计算如下:
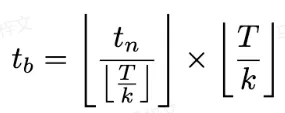
训练损失计算如下:
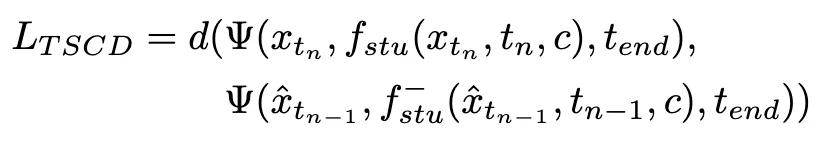
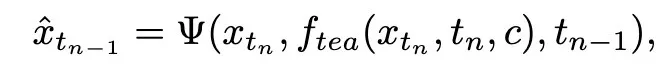
其中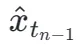 通过公式 3 进行计算,
通过公式 3 进行计算,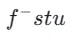 表示学生模型的指数滑动平均(EMA)。
表示学生模型的指数滑动平均(EMA)。
随后,我们恢复上一阶段的模型权重并继续训练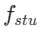 ,逐渐将 k 减少到 [4,2,1]。值得注意的是,k=1 对应于标准 CTM 训练方案。对于距离度量 d,我们采用了对抗性损失和均方误差 (MSE) 损失的混合。在实验中,我们观察到,当预测值和目标值接近时(例如,对于 k=8, 4),MSE 损失更为有效,而对抗性损失则随着预测和目标值之间的差异增加而变得更加精确(例如,对于 k=2, 1)。因此,我们在整个训练阶段动态增加对抗性损失的权重并减少 MSE 损失的权重。此外,我们还集成了噪声扰动机制来增强训练稳定性。以两阶段轨迹分段一致性蒸馏(TSCD)过程为例。如下图所示,我们第一阶段在
,逐渐将 k 减少到 [4,2,1]。值得注意的是,k=1 对应于标准 CTM 训练方案。对于距离度量 d,我们采用了对抗性损失和均方误差 (MSE) 损失的混合。在实验中,我们观察到,当预测值和目标值接近时(例如,对于 k=8, 4),MSE 损失更为有效,而对抗性损失则随着预测和目标值之间的差异增加而变得更加精确(例如,对于 k=2, 1)。因此,我们在整个训练阶段动态增加对抗性损失的权重并减少 MSE 损失的权重。此外,我们还集成了噪声扰动机制来增强训练稳定性。以两阶段轨迹分段一致性蒸馏(TSCD)过程为例。如下图所示,我们第一阶段在 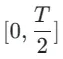 和
和 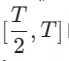 时间段内执行独立一致性蒸馏 ,然后基于之前的两段一致性蒸馏结果,进行全局一致性轨迹蒸馏。
时间段内执行独立一致性蒸馏 ,然后基于之前的两段一致性蒸馏结果,进行全局一致性轨迹蒸馏。
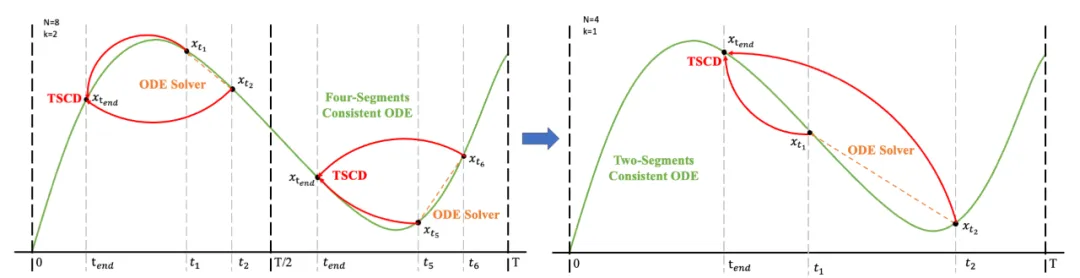
完整的算法流程如下:

2. 人类反馈学习
除了蒸馏之外,我们进一步结合反馈学习以提高加速扩散模型的性能。具体来说我们通过利用人类审美偏好和现有视觉感知模型的反馈来提高加速模型的生成质量。对于审美反馈,我们利用 LAION 审美预测器和 ImageReward 中提供的审美偏好奖励模型来引导模型生成更具美感的图像,如下所示:
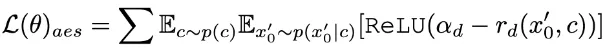
其中 是审美奖励模型,包括 LAION 数据集和 ImageReward 模型的审美预测器,c 是文本提示,
是审美奖励模型,包括 LAION 数据集和 ImageReward 模型的审美预测器,c 是文本提示, 与ReLU函数一起作为铰链损失 。除了来自审美偏好的反馈之外,我们注意到嵌入有关图像的丰富先验知识的现有视觉感知模型也可以作为良好的反馈提供者。根据经验,我们发现实例分割模型可以指导模型生成结构合理的物体。具体来说,我们首先将潜在空间中图像
与ReLU函数一起作为铰链损失 。除了来自审美偏好的反馈之外,我们注意到嵌入有关图像的丰富先验知识的现有视觉感知模型也可以作为良好的反馈提供者。根据经验,我们发现实例分割模型可以指导模型生成结构合理的物体。具体来说,我们首先将潜在空间中图像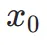 上的噪声扩散到
上的噪声扩散到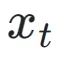 ,之后,类似于 ImageReward,我们执行迭代去噪,直到 特定时间步
,之后,类似于 ImageReward,我们执行迭代去噪,直到 特定时间步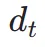 并直接预测
并直接预测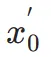 。随后,我们利用感知实例分割模型通过检查真实图像实例分割标注与去噪图像的实例分割预测结果之间的差异来评估结构生成的性能,如下所示:
。随后,我们利用感知实例分割模型通过检查真实图像实例分割标注与去噪图像的实例分割预测结果之间的差异来评估结构生成的性能,如下所示:
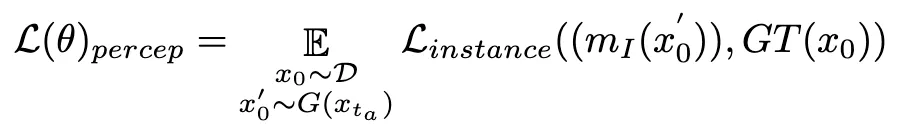
其中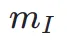 是实例分割模型(例如 SOLO)。实例分割模型可以更准确地捕获生成图像的结构缺陷并提供更有针对性的反馈信号。值得注意的是,除了实例分割模型之外,其他感知模型也适用。这些感知模型可以作为主观审美的补充反馈,更多地关注客观生成质量。因此,我们用反馈信号优化扩散模型可以定义为:
是实例分割模型(例如 SOLO)。实例分割模型可以更准确地捕获生成图像的结构缺陷并提供更有针对性的反馈信号。值得注意的是,除了实例分割模型之外,其他感知模型也适用。这些感知模型可以作为主观审美的补充反馈,更多地关注客观生成质量。因此,我们用反馈信号优化扩散模型可以定义为:
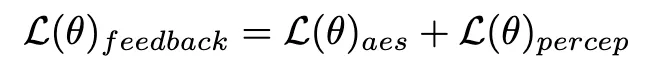
3. 一步生成强化
由于一致性损失的固有限制,一致性模型框架内的一步生成并不理想。正如 CM 中分析的那样,一致性蒸馏模型在引导位置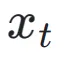 处的轨迹端点
处的轨迹端点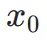 方面表现出卓越的准确性。因此,分数蒸馏是一种合适且有效的方法来进一步提升我们的 TSCD 模型的一步生成效果。具体来说,我们通过优化的分布匹配蒸馏(DMD)技术来推进一步生成。DMD 通过利用两个不同的评分函数来增强模型的输出:来自教师模型分布
方面表现出卓越的准确性。因此,分数蒸馏是一种合适且有效的方法来进一步提升我们的 TSCD 模型的一步生成效果。具体来说,我们通过优化的分布匹配蒸馏(DMD)技术来推进一步生成。DMD 通过利用两个不同的评分函数来增强模型的输出:来自教师模型分布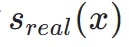 和来自假模型的
和来自假模型的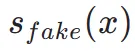 。我们将均方误差 (MSE) 损失与基于分数的蒸馏结合起来,以提高训练稳定性。在这个过程中,前面提到的人类反馈学习技术也被集成进来,用来微调我们的模型以有效地生成具有保真度的图像。
。我们将均方误差 (MSE) 损失与基于分数的蒸馏结合起来,以提高训练稳定性。在这个过程中,前面提到的人类反馈学习技术也被集成进来,用来微调我们的模型以有效地生成具有保真度的图像。
通过集成这些策略,我们的方法不仅能够实现在 SD1.5 和 SDXL 上都实现卓越的低步数推理效果(并且无需 Classifier-Guidance),同时能够实现理想的全局一致性模型,无需针对每个特定的步数训练 UNet 或者 LoRA 实现统一的低步数推理模型。
实验
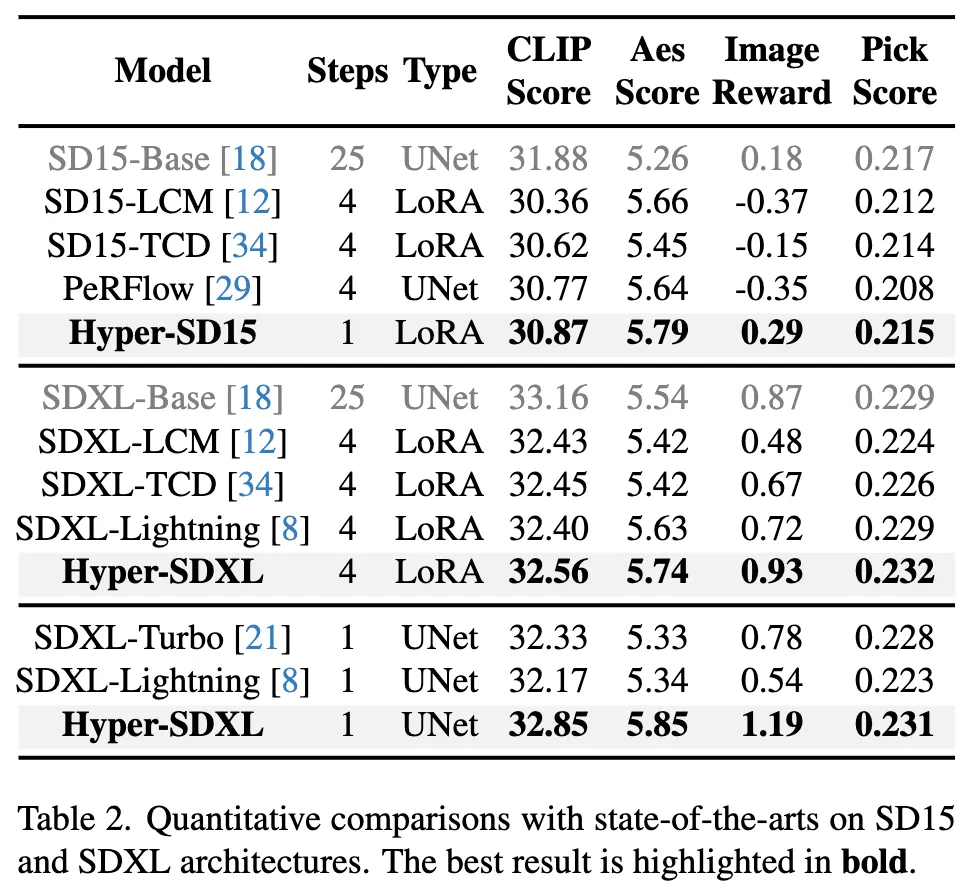
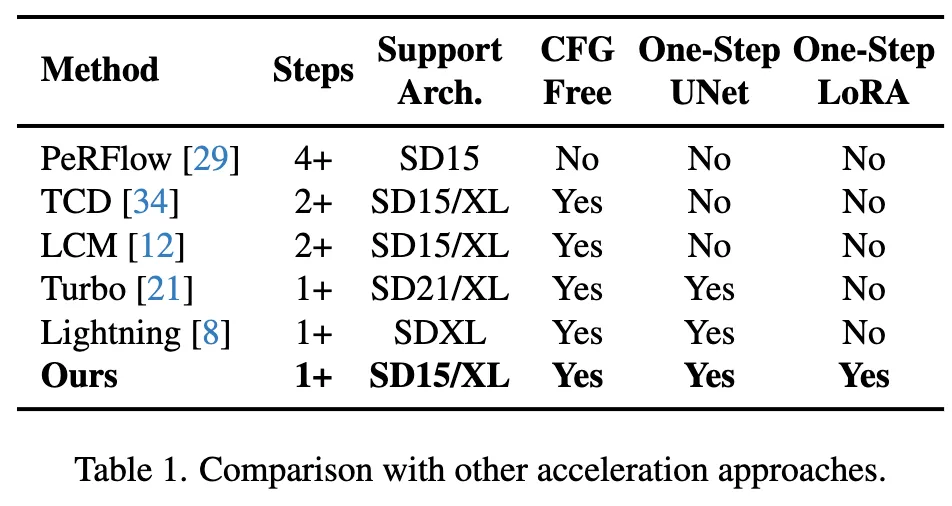
在 SD1.5 和 SDXL 上和目前现有的各种加速算法的定量比较,可以看到 Hyper-SD 显著优于当前最先进的方法
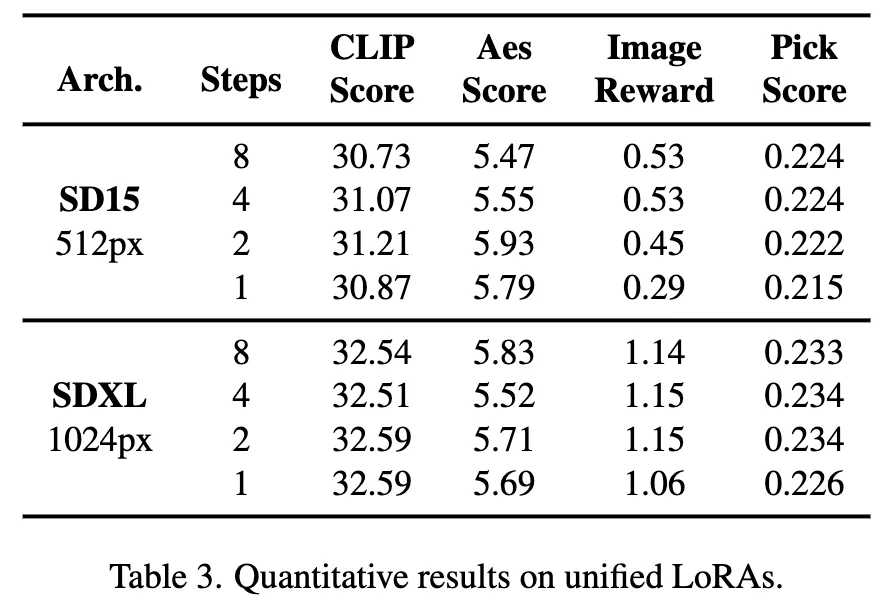
此外,Hyper-SD 能够用一个模型来实现各种不同低步数的推理,上面的定量指标也显示了我们方法在使用统一模型推理时的效果。


在 SD1.5 和 SDXL 上的加速效果可视化直观地展示了 Hyper-SD 在扩散模型推理加速上的优越性。
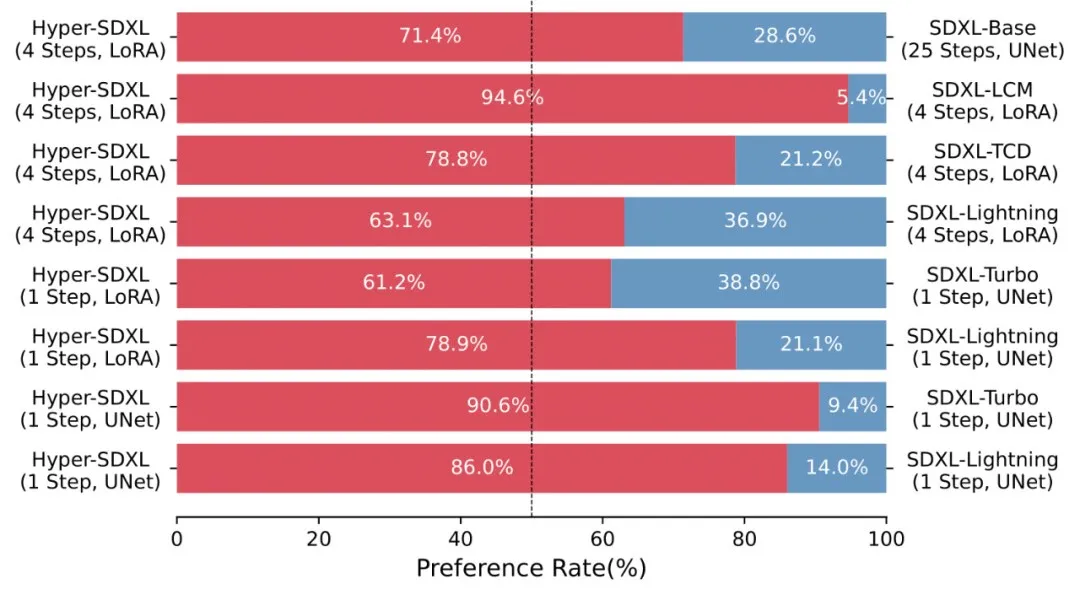
大量的 User-Study 也表明 Hyper-SD 相较于现有的各种加速算法的优越性。

Hyper-SD 训练得到的加速 LoRA 能够很好地兼容不同的风格的文生图底模。
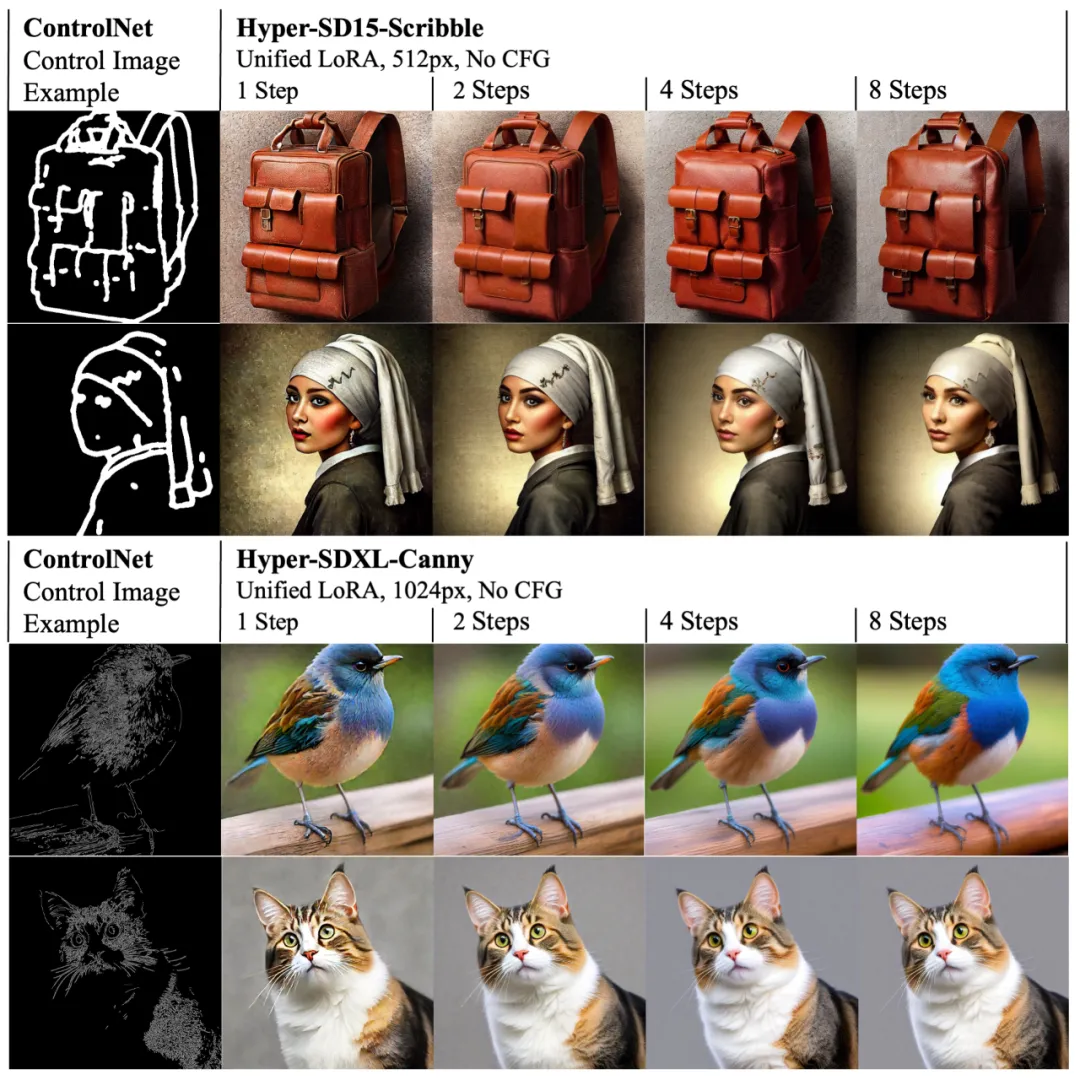
同时,Hyper-SD 的 LoRA 也能适配现有的 ControlNet,实现低步数下高质量的可控图像生成。
总结
论文提出了 Hyper-SD,一个统一的扩散模型加速框架,可以显著提升扩散模型的在低步数情况下的生成能力,实现基于 SDXL 和 SD15 的新 SOTA 性能。该方法通过采用轨迹分段一致性蒸馏,增强了蒸馏过程中的轨迹保存能力,实现接近原始模型的生成效果。然后,通过进一步利用人类反馈学习和变分分数蒸馏提升模型在极端低步数下的潜力,从而产生了更优化、更高效的模型生成效果。论文还开源了用于 SDXL 和 SD15 从 1 到 8 步推理的 Lora 插件,以及专用的一步 SDXL 模型,旨在进一步推动生成式 AI 社区的发展。
本文由 Hugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。
本文转发自 机器之心,点击阅读原文查看模型的 HF 页面。
如果你有与开源 AI、Hugging Face 相关的技术和实践分享内容,以及最新的开源 AI 项目发布,希望通过我们分享给更多 AI 从业者和开发者们,请通过下面的链接投稿与我们取得联系:
https://hf.link/tougao
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢