

1.介绍
在许多实际应用中,从局部点云中恢复完整的点云成为不可或缺的任务。本文提出了一种将点云补全重整为集合到集合转换问题的新方法,并设计了一种称为PoinTr的新模型,该模型采用Transformer编码器-解码器架构进行点云补全。通过将点云转换为一系列点代理,使用Transformer生成点云。为了方便Transformer更好地利用点云三维几何结构的感应偏差,本文进一步设计了一个几何感知模块,可以显式地模拟局部几何关系。
2.方法
PoinTr的整体框架如图1所示,首先对输入的部分点云进行下采样以获得中心点。然后使用轻量级DGCNN来提取中心点周围的局部特征。将位置嵌入添加到局部特征后,使用 Transformer 编码器-解码器架构来预测缺失部分的点代理。使用简单的 MLP 和 FoldingNet 以从粗到细的方式完成基于预测点代理的点云。
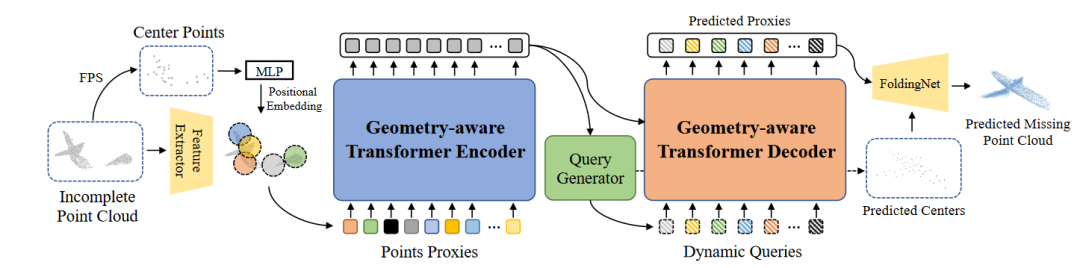
图2 PoinTr
2.1使用 Transformer 进行set-to-set转换
本文方法的主要目标是利用Transformer架构令人印象深刻的序列到序列生成能力来完成点云完成任务。首先将点云转换为一组特征向量,即点代理,它们表示点云中的局部区域。通过类比语言翻译管道,将点云补全建模为一组到一组的翻译任务,其中转换器将部分点云的点代理作为输入,并生成缺失部分的点代理。
编码器-解码器架构分别由编码器和解码器中的LE和LD多头自注意力层组成。编码器中的自注意力层首先使用长距离和短距离信息更新代理特征。然后,前馈网络使用 MLP 架构进一步更新代理功能。解码器利用自注意力和交叉注意力机制来学习结构知识。自注意力层使用全局信息增强局部要素,而交叉注意力层则探索编码器的查询和输出之间的关系。为了预测缺失部分的点代理,本文使用动态查询嵌入,这使得解码器更加灵活,可以针对不同类型的对象及其缺失信息进行调整。
2.2 点代理
要使3D点云适用于Transformer,第一步是将点云转换为一系列向量。一个微不足道的解决方案是将 xyz 坐标序列直接馈送到Transformer。然而,由于Transformer的计算复杂度与序列长度呈二次方关系,因此该解决方案将导致不可接受的成本。因此,本文将原始点云表示为一组点代理。点代理表示点云的局部区域。首先进行最远点采样(FPS),以在部分点云中定位固定数量的N个中心点{q1,q2,...,qN }。然后使用具有分层下采样的轻量级DGCNN从输入点云中提取点中心的特征。点代理Fi是一个特征向量,用于捕获qi周围的局部结构,可以计算为:
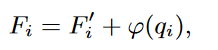
其中F’i 是使用DGCNN模型提取的点qi特征,φ是另一个捕获点代理位置信息的MLP。
2.3几何感知Transformer模块
将Transformer应用于视觉任务的主要挑战之一是 Transformer 中的自注意力机制缺乏一些传统视觉模型(如CNN和点云网络)固有的归纳偏差,这些模型可以明确地模拟视觉数据的结构。为了方便Transformer更好地利用点云的三维几何结构的感应偏置,本文设计了一个几何感知模块来模拟几何关系,它是一个即插即用的模块,可以与任何Transformer架构中的注意力模块合并。提出模块的详细信息如图 2 所示。与使用特征相似性来捕获语义关系的自注意力模块不同,本文使用kNN模型来捕获点云中的几何关系。给定查询坐标pQ,根据键坐标pk查询最近键的特征。然后通过线性层的特征聚合来学习局部几何结构,然后进行最大池化操作。然后将几何特征和语义特征连接起来并映射到原始尺寸以形成输出。

图2 几何感知Transformer模块
2.4查询生成器
查询Q用作待预测代理的初始状态。为了确保查询正确反映已完成的点云的草图,本文提出了一个查询生成器模块来生成基于编码器输出的动态条件的查询嵌入。具体来说,首先在最大池化操作之后使用线性投影来总结,直接使用线性投影层生成M×3维特征,这些特征可以重塑为缺失点云中心点坐标{c1,c2,...,cM}。最后将编码器的全局特征和坐标连接起来,并使用 MLP 生成查询嵌入。
2.5多尺度点云生成
本文的编码器-解码器网络的目标是预测不完整点云的缺失部分。但是目前只能从transformer解码器中获得缺失代理的预测。因此,本文提出了一种多尺度的点云生成框架,以全分辨率恢复缺失的点云。为了减少冗余计算,本文重用查询生成器生成的坐标作为缺失点云的局部中心。然后利用FoldingNet f 来恢复以预测代理为中心的详细局部形状:

其中Pi是以ci为中心的相邻点的集合。根据之前的工作,本文只预测点云的缺失部分,并将它们与输入点云连接起来,以获得完整的对象。
3.实验
3.1 ShapeNet55
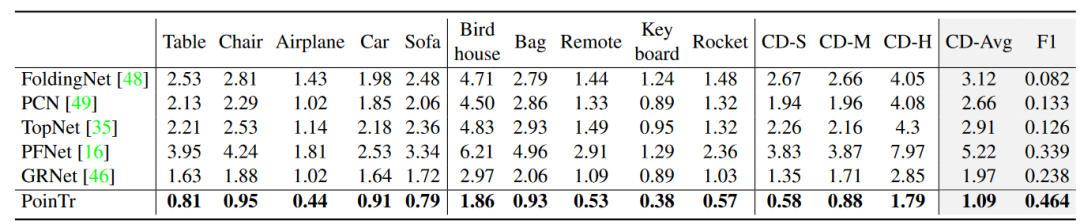
本文首先在ShapeNet-55上进行实验,它由55个类别的对象组成。首先研究现有方法和本文的方法在有更多类别的对象时如何执行。表1的最后四列表明,本文的PoinTr可以更好地应对不同视点、不同对象类别、不同不完全模式和不同不完全性水平的不同情况。与SOTA方法GRNet相比,在三种设置(简单、中等和困难)下,CD-l2分别提高了0.58、0.6和0.69。本文将样本充足的类别放在表1的前五列中,将样本不足的类别放在以下五列中。还报告了三个难度的平均 CD 结果。令人惊讶的是,这两种类别的结果之间没有明显的差异。然而,除了PoinTr和SOTA方法GRNet外,训练样本数量的不平衡导致样本不足的类别中的CD相对较高。
表1 ShapeNet55
3.2 ShapeNet34
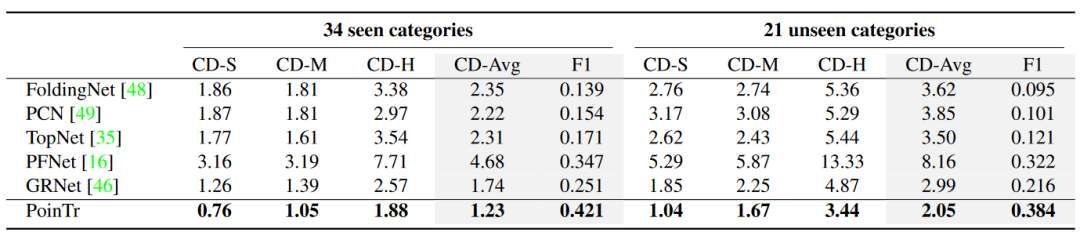
在ShapeNet-34上,本文还与其他五种最先进的方法进行了实验。结果如表2所示。对于34个可见的类别,可以看到本文的方法优于所有其他方法。对于21个看不见的类别,使用在34个可见类别上训练的网络来评估其他21个未出现在训练阶段的新对象的性能。可以看到,提出的方法在这种更具挑战性的环境中也能实现最佳性能。当难度级别增加时,可见类别和未可见类别之间的性能差距会显着增加。
表2 ShapeNet34
3.3 PCN数据集
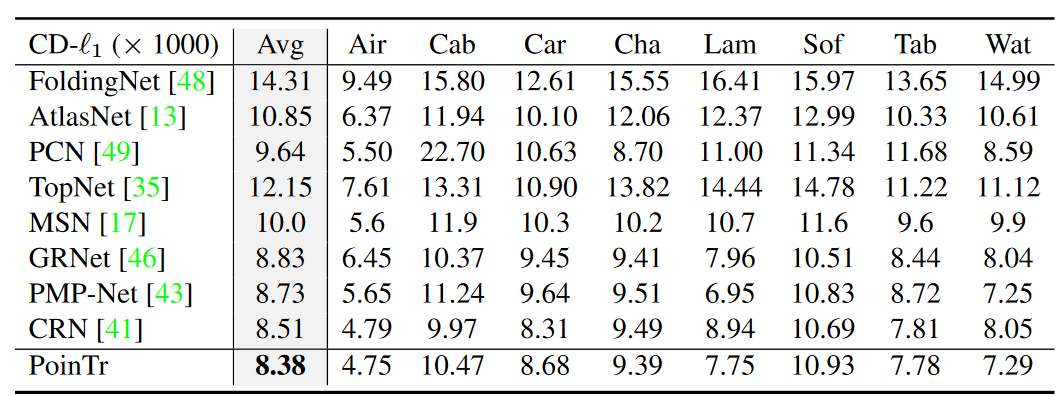
PCN数据集是点云补全任务中使用最广泛的基准数据集之一。为了验证提出的方法在现有基准上的有效性,并将其与更先进的方法进行比较,本文按照先前工作中使用的标准协议和评估指标对该数据集进行了实验。结果如表3所示。可以看到本文的方法在很大程度上改进了以前的方法,并在这个数据集上建立了新的状态。
表3 PCN数据集
3.4 KITTI数据集
为了展示提出的方法在真实场景中的性能,本文在ShapeNetCars [49]上微调了模型,并评估了本文的模型在KITTI数据集上的性能,该数据集包含来自LiDAR扫描的真实场景中汽车的不完整点云。在表4中报告了Fidelity和MMD指标,提出的方法实现了更好的定性和定量性能。
表4 KITTI数据集

3.5 消融实验
为了检验本文设计的有效性,对PoinTr的关键成分进行了详细的消融研究。结果总结在表5中。基线模型A是用于点云补全的普通Transformer模型,它使用带有标准Transformer模块的编码器-解码器架构。然后,模型B添加查询生成器在编码器和解码器之间。可以看到查询生成器将倒角距离的基线提高了0.34。当使用DGCNN从输入点云(模型C)中提取特征时,能够观察到显著地提升到8.69。通过将几何模块添加到所有Transformer模块(模型D)中,性能可以进一步提高,这清楚地证明了模块学习的几何结构的有效性。在编码器和解码器中,仅将几何模块添加到第一个Transformer模块中可以导致性能稍好(模型E),这表明几何模块的作用是引入归纳偏置,添加更多模块可能会导致过度拟合。
表5 消融实验

4.结论
本文提出了一种适合点云补全任务的PoinTr模型,将Transformer引入到点云补全任务中,并且设计了几何感知模块用于显式地模拟局部几何关系,这使本文的模型能够更好地学习结构知识并保留详细信息以补全点云,在已有的合成数据集与真实数据集上取得了目前最好性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢