

Meta 新研究:大模型的端到端推理加速 超越思维链(CoT),“Chain-of-X”范式调查 微软、清华团队提出多头混合专家 MH-MoE BattleAgent:再现历史事件,对历史战役进行多模态动态模拟 OpenAI 最新论文:如何让大模型免受恶意攻击? 综述:大型语言模型的高效推理 谷歌 274 页论文:高级人工智能助手的伦理 清华、Meta 提出文生图定制新方法 MultiBooth 微软发布 Phi-3 技术报告:手机上的高功能语言模型 上海 AI Lab 推出开源多模态大模型 InternVL 1.5 Tele-FLM 技术报告 苹果推出开放语言模型 OpenELM Google DeepMind 新研究:减轻说服型生成式 AI 的危害 清华团队新研究:通过提示工程在 LLM 中整合化学知识 MIT CSAIL 推出多模态自动可解释性智能体 MAIA PhysDreamer:通过视频生成,与 3D 物体进行基于物理交互
想要第一时间获取每日最新大模型热门论文? 扫描下方二维码,加入「大模型技术分享群」。 或点击“阅读原文”,获取「2024 必读大模型论文」合集(包括日报、周报、月报,持续更新中~)。

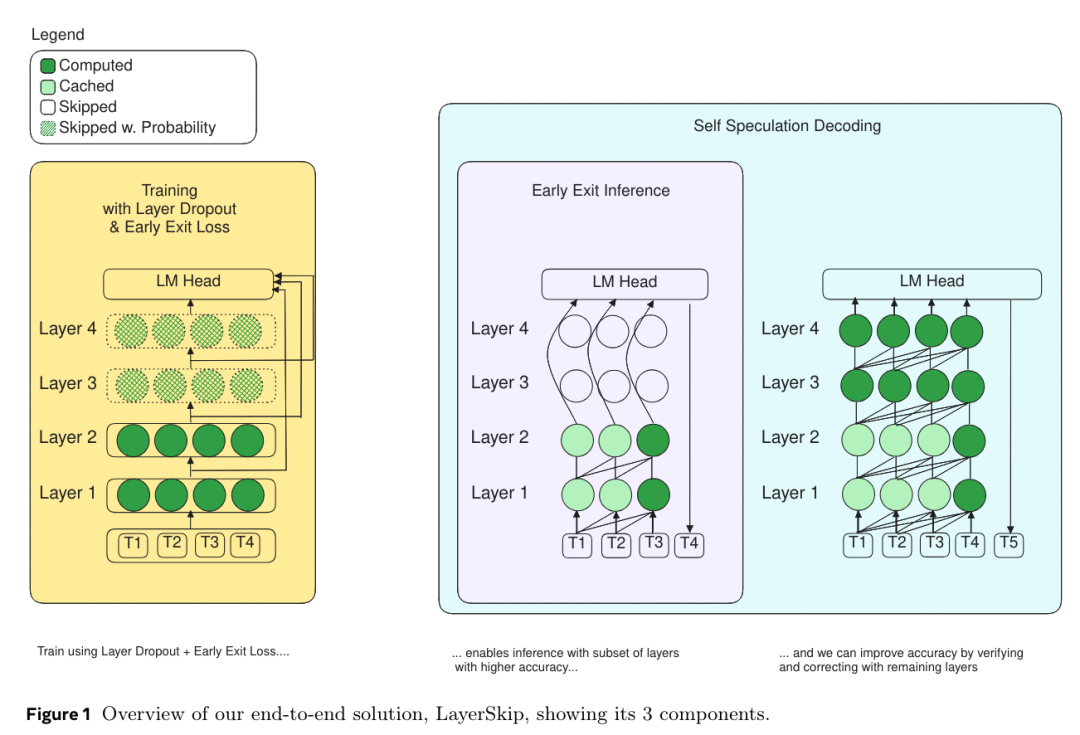
来自 Meta 的研究团队及其合作者,提出了一种端到端的大型语言模型(LLM)推理加速解决方案——LayerSkip。
首先,在训练过程中,他们采用了层间丢弃技术,早期层间丢弃率较低,后期层间丢弃率较高。其次,在推理过程中,他们证明这种训练方法提高了早期退出的准确性,而无需在模型中添加任何辅助层或模块。第三,他们提出了一种新型自我推测解码方案,即在早期层退出,并通过模型的其余层进行验证和校正。与其他推测式解码方法相比,该方法占用的内存更少,并能从共享计算以及草稿和验证阶段的激活中获益。
他们在不同大小的 Llama 模型上进行了不同类型的训练实验:从头开始预训练、持续预训练、针对特定数据域的微调以及针对特定任务的微调。他们验证了推理解决方案,结果表明,CNN/DM 文档的摘要处理速度提高了 2.16 倍,编码速度提高了 1.82 倍,TOPv2 语义解析任务的速度提高了 2.0 倍。
https://arxiv.org/abs/2404.16710
思维链(CoT)是一种被广泛采用的提示方法,能激发大型语言模型(LLM)令人印象深刻的推理能力。受 CoT 的顺序思维结构的启发,人们开发了许多 Chain-of-X (CoX) 方法,从而应对涉及 LLM 的不同领域和任务中的各种挑战。
在这项工作中,来自上海交通大学、加州大学圣地亚哥分校的研究团队及其合作者,全面考察了不同背景下的 LLMs Chain-of-X 方法。具体来说,他们按照节点分类法(即 CoX 中的 X)和应用任务对这些方法进行了分类。他们还讨论了现有 CoX 方法的发现和影响,以及潜在的未来方向。

https://arxiv.org/abs/2404.15676
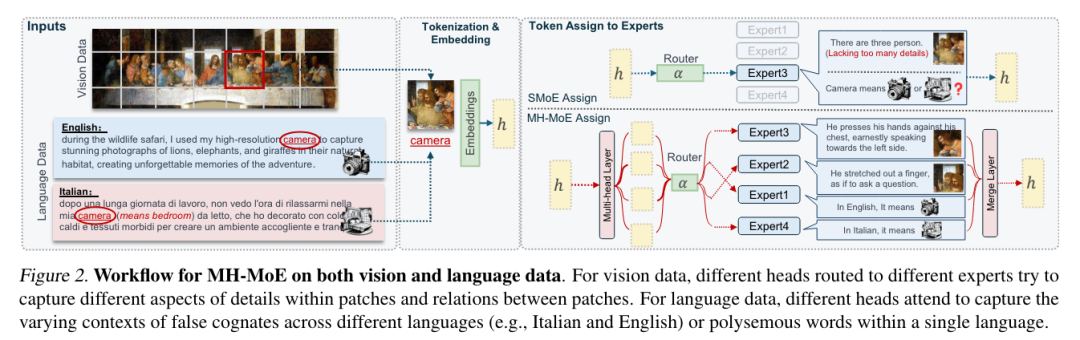
稀疏混合专家(SMoE)模型可在不显著增加训练和推理成本的情况下扩展模型容量,但存在以下两个问题:专家激活率低,只有一小部分专家被激活用于优化;缺乏对单个 token 中多个语义概念的细粒度分析能力。
来自微软、清华大学的研究团队提出了多头混合专家(MH-MoE),它采用多头机制将每个 token 分割成多个子 token。然后,这些子 token 被分配给一组不同的专家并由它们并行处理,然后无缝地重新整合为原始 token 形式。多头机制使模型能够集体关注不同专家的各种表征空间的信息,同时显著提高专家激活度,从而加深对上下文的理解并减轻过度拟合。此外,MH-MoE 易于实现,并与其他 SMoE 优化方法解耦,易于与其他 SMoE 模型集成,从而提高性能。
以英语为重点的语言建模、多语言语言建模和掩码多模态建模任务的大量实验,证明了 MH-MoE 的有效性。
论文链接:
https://arxiv.org/abs/2404.15045
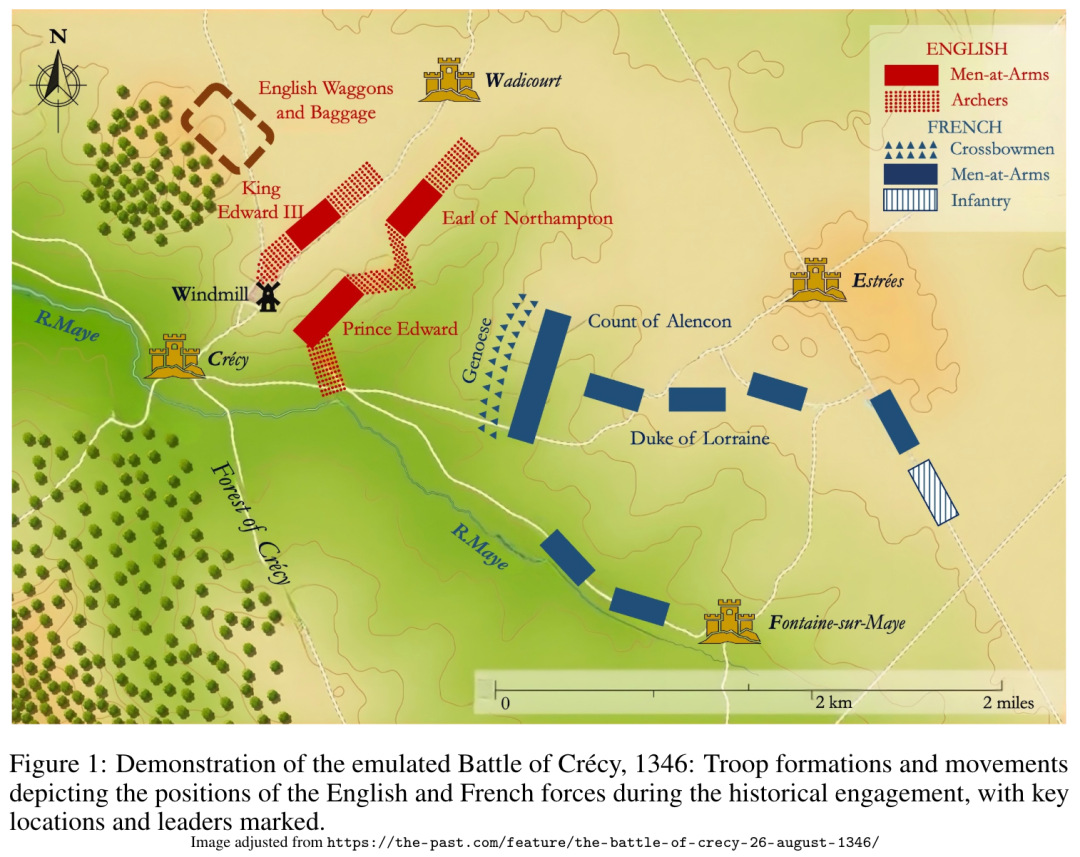
来自罗格斯大学的研究团队及其合作者提出了 BattleAgent,这是一个结合了大型视觉语言模型(LVLM)和多智能体(agent)系统的仿真系统,旨在模拟多个智能体之间以及智能体与其环境之间特定时间内的复杂动态互动。
它既能模拟领导者的决策过程,也能模拟士兵等普通参与者的观点,展示了当前智能体的能力,具有智能体与环境之间细粒度多模态交互的特点。它开发了可定制的智能体结构,从而满足特定的情境要求,例如侦察和挖掘战壕等各种与战斗相关的活动。这些组件相互协作,以生动全面的方式再现历史事件,同时从不同的视角洞察个人的思想和情感。
BattleAgent 为历史战役建立了详细和身临其境的场景,使单个智能体能够参与、观察和动态响应不断变化的战役场景。这种方法有可能大大加深我们对历史事件的理解,特别是通过个人叙述。由于传统的历史叙事往往缺乏文献记载,而且优先考虑决策者的观点,忽略了普通人的经历,因此这种举措也有助于历史研究。
论文链接:
https://arxiv.org/abs/2404.15532
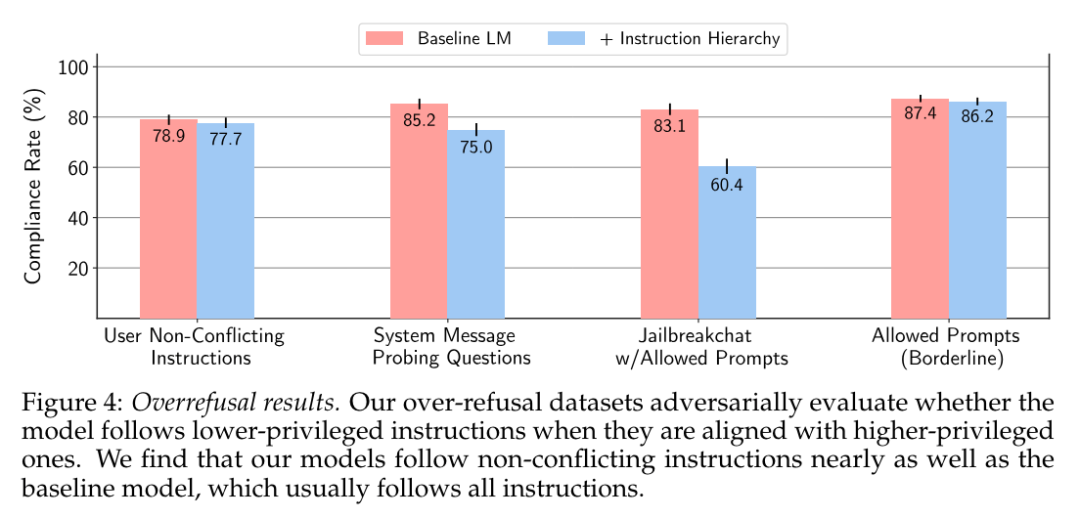
大型语言模型(LLM)因其在各种任务中的出色表现而受到广泛关注。然而,LLM 推理需要大量的计算和内存,这给在资源有限的情况下部署 LLM 带来了挑战。该领域一直致力于开发旨在提高 LLM 推理效率的技术。
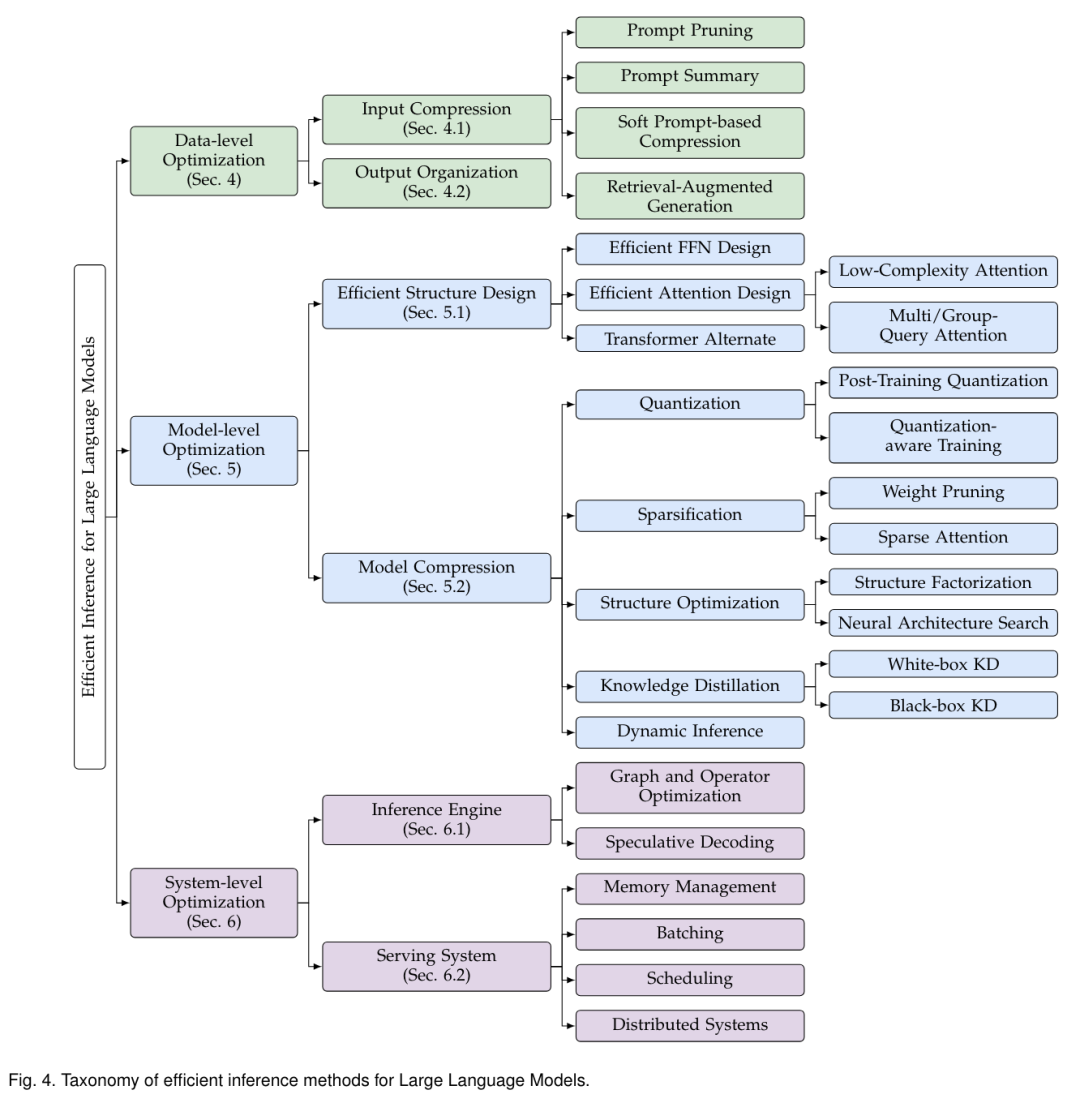
来自清华大学的研究团队及其合作者全面考察了有关高效 LLM 推理的现有文献。他们首先分析了 LLM 推理效率低下的主要原因,即模型规模过大、二次复杂性注意力操作和自动回归解码方法;然后,提出了一个全面的分类法,将目前的文献整理为数据级、模型级和系统级优化;此外,还对关键子领域中的代表性方法进行了比较实验,从而提供定量见解;最后,进行了一些知识总结,并讨论了未来的研究方向。
https://arxiv.org/abs/2404.14294

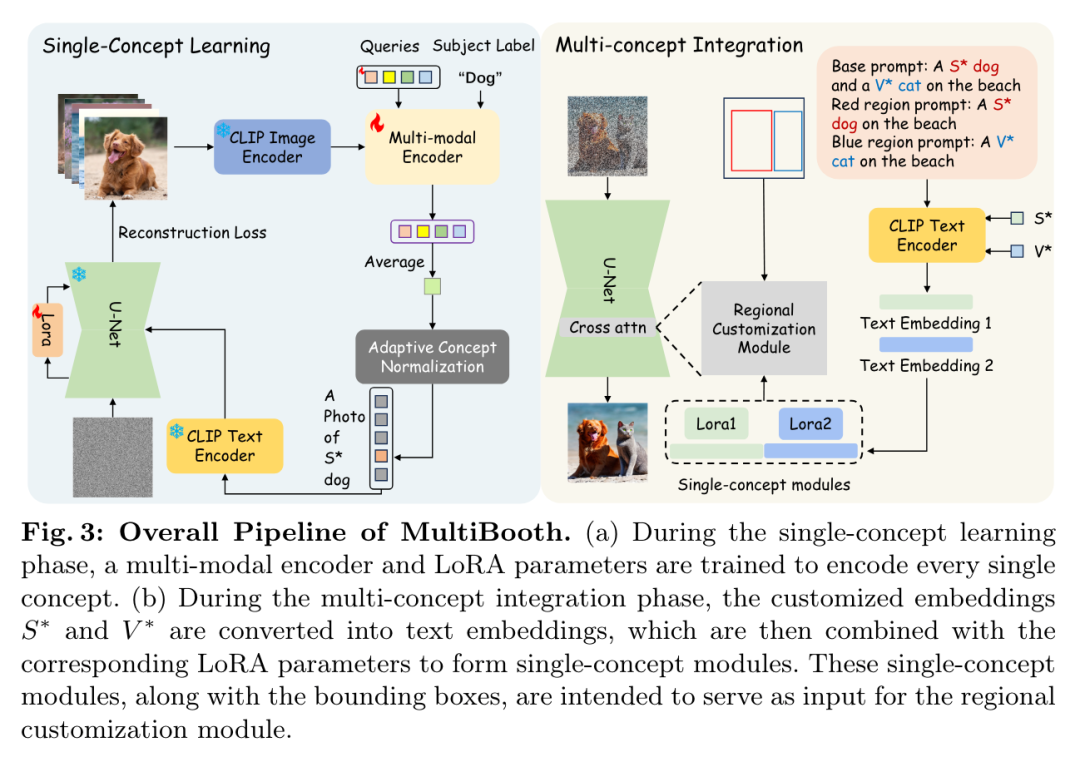
来自清华大学和 Meta 的研究团队提出了一种用于从文生图的多概念定制的新型高效技术—— MultiBooth。尽管定制生成方法取得了长足的进步,特别是随着扩散模型的快速发展,但由于概念保真度低和推理成本高,现有方法在处理多概念场景时依然困难。
为了解决这些问题,MultiBooth 将多概念生成过程分为两个阶段:单一概念学习阶段和多概念整合阶段。在单概念学习阶段,他们采用多模态图像编码器和高效的概念编码技术,为每个概念学习一个简明且具有辨别力的表征;在多概念整合阶段,他们使用边界框来定义交叉注意图中每个概念的生成区域。这种方法可以在指定区域内创建单个概念,从而促进多概念图像的形成。
这一策略不仅提高了概念的保真度,还降低了额外的推理成本。在定性和定量评估中,MultiBooth 都超越了各种基线,展示了其卓越的性能和计算效率。
https://arxiv.org/abs/2404.14239
项目地址:
https://multibooth.github.io/
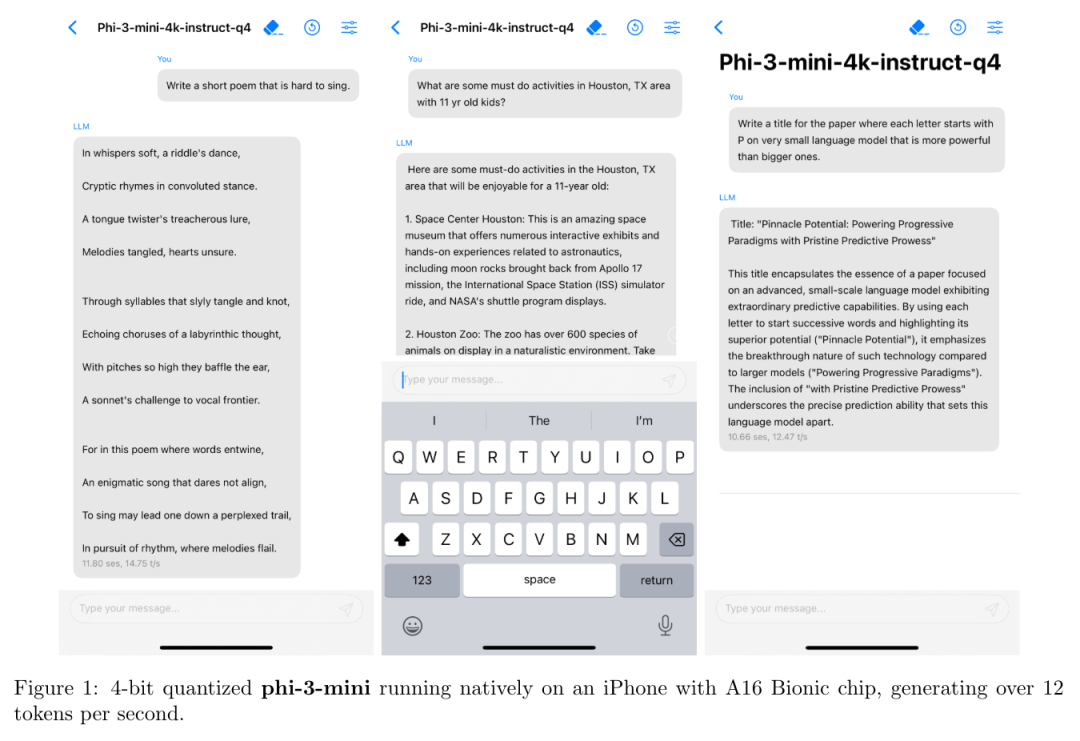
微软发布了 Phi-3 系列模型,包括 phi-3-mini、phi-3-small 和 phi-3-medium。
其中,phi-3-mini 是一个基于 3.3 万亿个 token 训练的 38 亿参数语言模型,根据学术基准和内部测试结果,其总体性能可与 Mixtral 8x7B 和 GPT-3.5 等模型相媲美(例如,phi-3-mini 在 MMLU 上的得分率为 69%,在 MT-bench 上的得分率为 8.38),而且体积很小,可以部署在手机上。
微软团队表示,Phi-3 系列模型的创新点在于他们的训练数据集,它是 phi-2 所用数据集的放大版,由经过大量过滤的网络数据和合成数据组成。他们还进一步调整了模型的鲁棒性、安全性和聊天格式。
此外,他们还提供了一些初步的参数缩放结果,包括针对 4.8T token 训练的 7B 和 14B 模型,即 phi-3-small 和 phi-3-medium,这两个模型的能力都明显高于 phi-3-mini(例如,在 MMLU 上分别为 75% 和 78%,在 MT-bench 上分别为 8.7 和 8.9)。
https://arxiv.org/abs/2404.14219
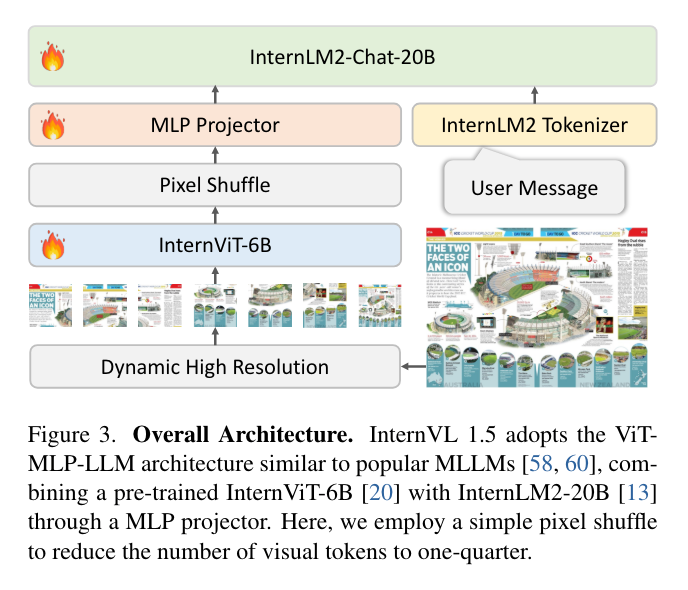
来自上海 AI Lab 的研究团队及其合作者,推出了一种开源多模态大型语言模型(MLLM)—— InternVL 1.5,其可弥合开源模型与专有商业模型在多模态理解方面的能力差距。
他们提出了三个简单的改进:1)强视觉编码器:他们探索了大规模视觉基础模型——InternViT-6B 的持续学习策略,增强了其视觉理解能力,并使其可以在不同的 LLLM 中转移和重用;2)动态高分辨率:根据输入图像的长宽比和分辨率,将图像划分为 1 至 40 块 448×448 像素的方块,最高支持 4K 分辨率输入;3)高质量的双语数据集:他们精心收集了高质量的双语数据集,涵盖了常见的场景、文档图像,并为其标注了中英文问答对,显著提高了 OCR 和中文相关任务的性能。
评估结果显示,与开源模型和专有模型相比,InternVL 1.5 在 18 个基准测试中的 8 个测试中取得了 SOTA。
https://arxiv.org/abs/2404.16821
GitHub 地址:
https://github.com/OpenGVLab/InternVL?tab=readme-ov-file
大型语言模型(LLMs)的可重复性和透明度,对于推进开放研究、确保结果的可信性、以及对数据和模型偏差以及潜在风险进行调查,至关重要。
苹果研究团队推出了一种先进的开放语言模型 OpenELM。OpenELM 使用分层缩放策略,在 transformer 模型的每一层中有效地分配参数,从而提高了准确性。例如,在参数预算约为 10 亿的情况下,OpenELM 的准确率比 OLMo 提高了 2.36%,而所需的预训练 token 却减少了 2 倍。
与之前只提供模型权重、推理代码以及在私有数据集上进行预训练的做法不同,OpenELM 包含了在公共可用数据集上对语言模型进行训练和评估的完整框架,包括训练日志、多个检查点和预训练配置。
此外,他们还发布了将模型转换为 MLX 库的代码,从而在苹果设备上进行推理和微调。

https://arxiv.org/abs/2404.14619
GitHub地址:
https://github.com/apple/corenet
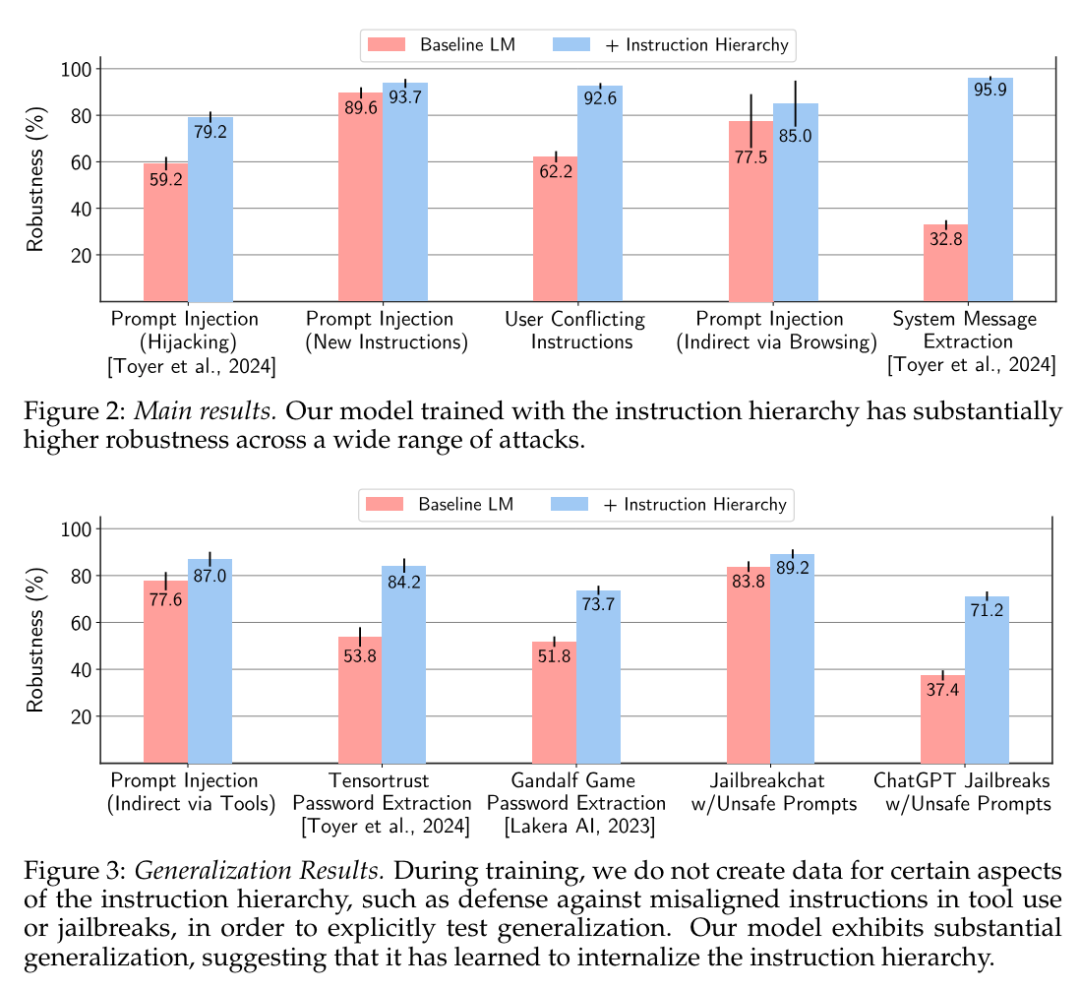
最近,生成式人工智能(AI)系统已经显示出更先进的说服能力,并逐渐渗透到可以影响决策的生活领域。
然而,由于互惠交换和长时间互动的机会,生成式 AI 呈现了一种新的说服风险。这导致人们越来越关注说服型生成式 AI 的危害,以及如何减轻这些危害,从而突出了对说服型生成式 AI 进行系统研究的必要性。目前说服型生成式 AI 的定义不明确,相关的危害也没有得到充分的研究。现有的减轻危害的方法优先考虑说服结果带来的危害,而不是说服过程带来的危害。
在这项研究中,Google DeepMind 团队及其合作者提出了说服型生成式 AI 的定义,并区分了理性说服型生成式 AI 和操纵型生成式 AI(manipulative generative AI),前者依赖于提供相关事实、合理推理或其他形式的可信证据,后者则依赖于利用认知偏差和启发式方法或歪曲信息。
他们还提出了服型生成式 AI 的危害,包括经济、物理、环境、心理、社会文化、政治、隐私的定义和例子。然后,他们提出了一幅导致说服危害的机制图,概述了可用于减轻说服过程危害的方法,包括操纵分类的提示工程和红队。他们未来的工作将使这些缓解措施具有可操作性,并研究不同类型说服机制之间的相互作用。

https://arxiv.org/abs/2404.15058
该论文介绍了一项关于整合提示工程中特定领域知识来提高科学领域大型语言模型(LLM)性能的研究。
来自清华大学和牛津大学的研究团队设计了一个基准数据集,包括了小分子错综复杂的物理化学特性,在药理学上的可药性,以及酶和晶体材料的功能属性,强调了其在生物和化学领域的相关性和适用性。通过对麦克米伦催化剂、紫杉醇和氧化钴锂等复杂材料的案例研究,证明了该方法的有效性。
研究结果表明,领域知识提示可以引导 LLM 生成更准确、更相关的回答,突出了 LLM 在配备特定领域提示后作为科学发现和创新的强大工具的潜力。研究还讨论了特定领域提示工程开发的局限性和未来方向。

https://arxiv.org/abs/2404.14467
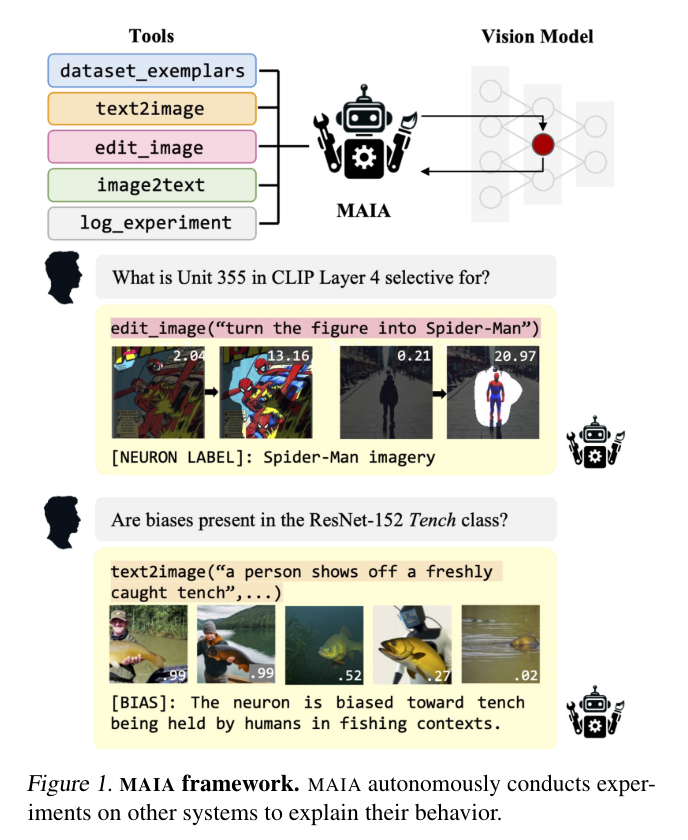
MIT 计算机科学与人工智能实验室团队提出了一个多模态自动可解释性智能体—— MAIA。
MAIA 是一个使用神经模型来自动完成神经模型理解任务(比如特征解释和故障模式发现)的系统。它为预训练的视觉语言模型配备了一系列工具,从而支持对其他模型的子组件进行迭代实验,从而解释其行为。这些工具包括人类研究人员常用的工具:合成和编辑输入,计算来自真实世界数据集的最大激活示例,以及总结和描述实验结果。MAIA 提出的可解释性实验将这些工具组合在一起,用于描述和解释系统行为。
他们评估了 MAIA 在计算机视觉模型上的应用。他们首先描述了 MAIA 在图像学习表示中描述(神经元级)特征的能力。在几个经过训练的模型和一个具有配对 ground-truth 描述的合成视觉神经元新数据集上,MAIA 产生的描述与专家人类实验者生成的描述相当。此外,MAIA 可以帮助完成两个额外的可解释性任务:降低对虚假特征的敏感性,以及自动识别可能被错误分类的输入。
https://arxiv.org/abs/2404.14394
项目地址:
https://multimodal-interpretability.csail.mit.edu/maia/
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢