处在生成式人工智能(GenAI)技术变革的浪潮上,人们对这一将降低成本和产生利润的强大工具充满了期待。然而,ChatGPT爆火一年后,GenAI产业还没有形成像当前云服务产业那样的价值结构,后者的上层应用占据价值链中的大部分比例,并获取了大部分利润,基础设施软件层的利润次之,而硬件层分到的“蛋糕”最少。
与之相反,在GenAI领域,硬件层却占据了近90%的利润率。蓦然回首,大家发现,整个产业链基本都在给GPU厂商英伟达“打工”。那么,当前这种GenAI经济模式是否还会持续下去?该领域未来的价值会在哪些方面累积,又该如何实现?本文对GenAI领域的当前的产业价值分层和利润分配进行了解读,并对未来发展作了预测。
(本文作者Apoorv Agrawal是Altimeter资本的投资人,此前是Palantir的工程师。本文经授权后由OneFlow编译发布,转载请联系授权。原文:https://apoorv03.com/p/the-economics-of-generative-ai)
翻译|张雪聃、宛子琳、杨婷
1
GenAI的价值累积在哪些方面?
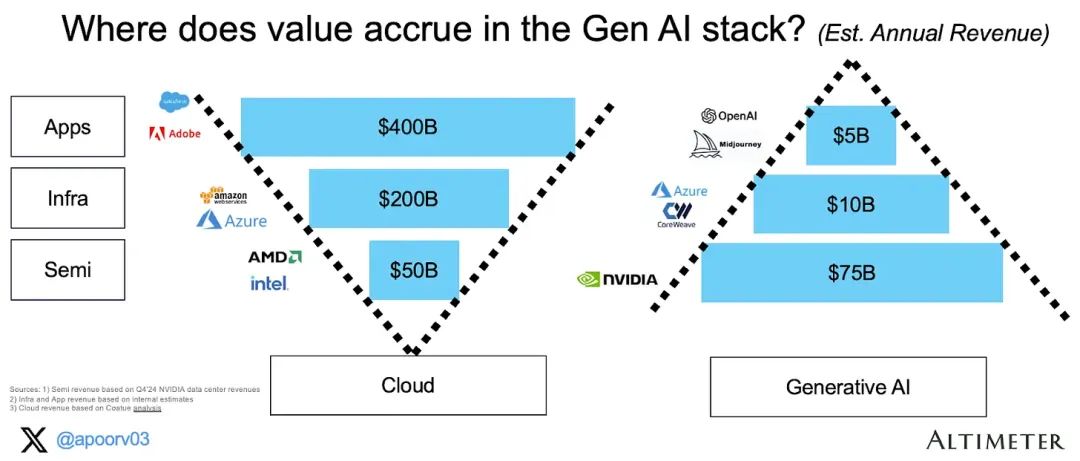
距“AI的iPhone时刻(2023年Nvidia创始人黄仁勋在GTC大会演讲中所述)”已经过去了18个月[1],但其发展的步伐并未放缓。我一直在思考一个重要的问题:当下以及未来,GenAI领域的价值累积在哪些方面?目前,GenAI的技术栈价值累积呈现出A字型的结构,而云服务则呈现V型[2]:我将技术栈分为三层:半导体层、基础设施层和应用层。以下是关于GenAI的收入统计:- 半导体层:Nvidia上个季度(截至2024年1月)的数据中心收入约为180亿美元,鉴于其拥有95%以上的市场份额,这部分的年收入预计约为750亿美元。
- 基础设施层:这一层包括超大规模计算供应商(AWS、GCP、Azure)和主要的推理云(Coreweave、Lambda等)供应商,粗略估算这一层的年收入约为100亿美元。
- 应用层:语言大模型(OpenAI、Anthropic、xAI等)、图像模型(Midjourney等)以及其他单纯的生成式AI应用。部分GenAI用例可能会将收入伪装成“软件”收入,因此我大胆估算这一层的年收入约为50亿美元。
相比之下,云经济展现出一种更符合“直觉”的价值分配——更靠近终端客户的应用能够赚取更多的价值。半导体层目前已经占据了GenAI技术栈年收入的约83%(900亿美元收入中的750亿美元),这远高于半导体在云技术栈中目前所占的约10%年收入!2
GenAI的利润累积在哪些方面?
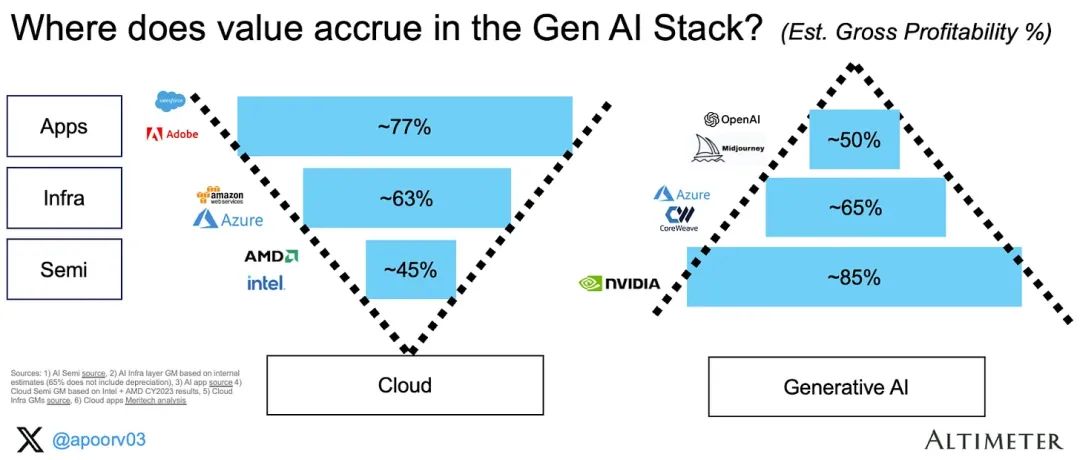
如下图,我们同样可以看到利润率的倒置结构,半导体层目前占据的份额最高[3]:应用层:据估计,Anthropic的毛利率约为50-55%。我假设整个应用层的毛利率相同。
基础设施层:我估计基础设施供应商的毛利率约为65%(不包括GPU折旧)。如果包含折旧率,这一数字将下降到25-30%。
半导体层:据估计,NVIDIA在其GenAI数据中心产品上的毛利率超过85%。
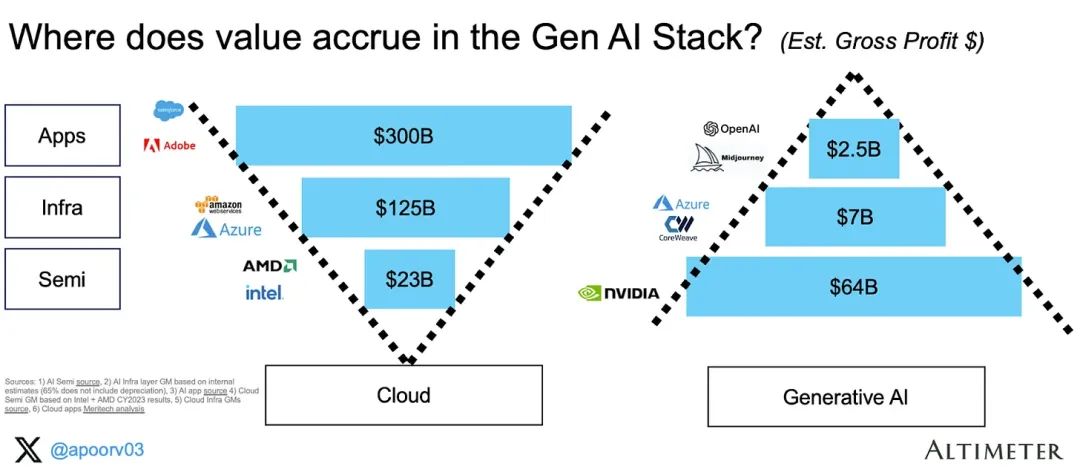
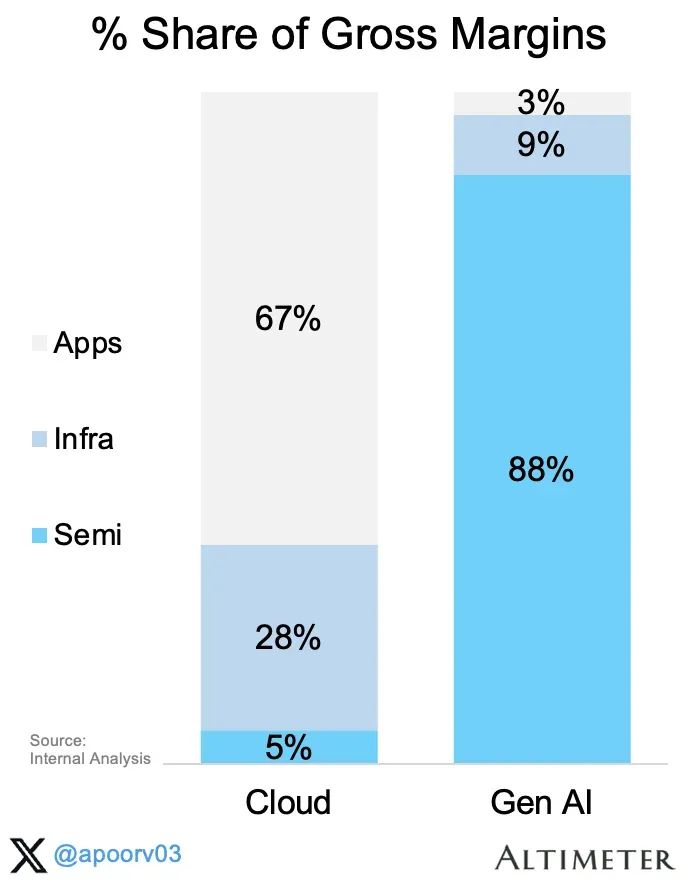
云技术栈的情况已经得到了深入研究,除了超大规模的毛利率。据估计,Azure的毛利率约为63%,我们假设这个数字适用于所有基础设施层。综合来看,总毛利润主要集中在半导体层,赚取了640亿美元(总计730亿美元)的利润。见以下图表(收入 x 毛利率 %):很有必要用条形图直观地展示这一惊人的相对比例。此处我们假设100%代表系统中的总毛利率。结论:半导体层目前已经占据了GenAI生态系统中约88%的全部毛利率(而在云技术栈中,半导体的毛利率仅占5%)。3
未来发展方向是什么?
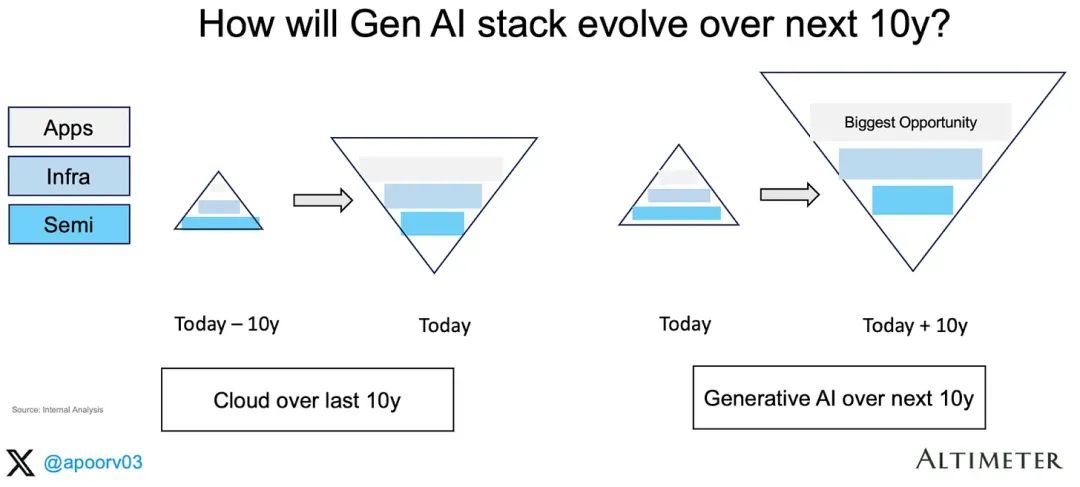
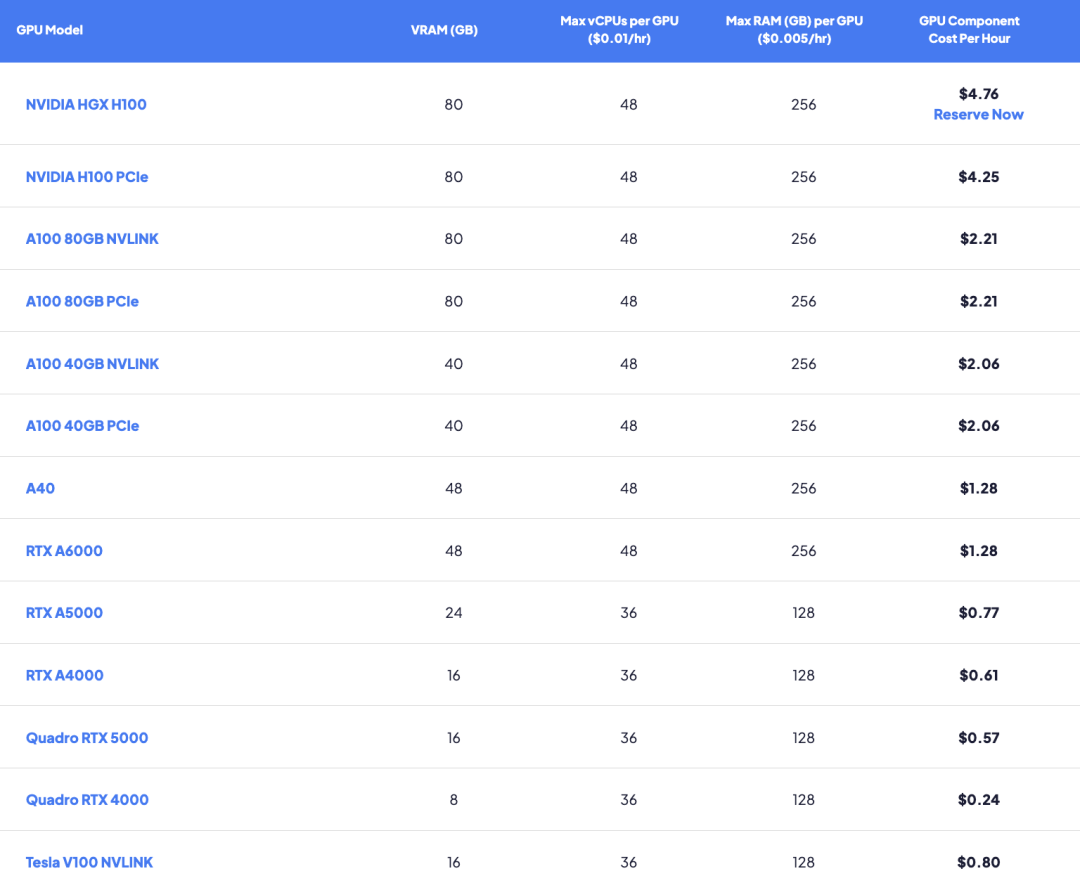
我们正处于一个平台转型的早期阶段,其中半导体产业获取了大部分价值,但我并不认为GenAI当前的收入结构(倒金字塔)会保持不变,我预计,应用层将在适当的时间内占据价值链中类似的高比例。以下是移动浪潮中关于价值积累的案例研究。在过去的十年里,移动智能领域的价值首先在半导体层积累,然后在基础设施层,最后在软件层:类似地,在云计算领域,我们首先见证了数据中心的建设,随后是云服务供应商的崛起。AWS始于2004年,并于2010-2012年获得了第一批客户(亚马逊在2010年转向了AWS,2012年Netflix加入了他们)。我预计,GenAI也会如此发展。我们当前处于第一阶段(半导体),预计将于2030年进入第三阶段(应用)。由此可推出,由于当前的基数较低,我认为,未来在应用层技术栈中存在的机会最多!A) NVIDIA的毛利率能否继续维持在85%以上?我认为不会。显然,NVIDIA的利润率已经达到峰值,并且呈下降趋势。据SemiAnalysis的分析:“我们认为,NVIDIA的利润率已经达到顶峰,预计B100和未来产品系列的毛利率会略微下降,并且在未来几个季度内,由于H200和H20的推出,H100的毛利率也将下降。”我关注的重要问题,也是NVIDIA占据主导地位的关键指标:(CoreWeave GPU Cloud Pricing)B) 云应用的毛利率为75-80%,而AI应用的毛利率为0-50%,未来将如何演变?我相信,AI应用的盈利能力会随着时间的推移而提高。以下几个因素将帮助AI应用在未来更好得盈利:- 更好的定价/价值对齐:众所周知,在某些情况下(https://news.ycombinator.com/item?id=37827955),AI应用根本不盈利——尤其对于重度用户来说,因为销售成本(COGS)与使用量挂钩。
- 通过定制芯片降低TCO:所有超大规模的云服务供应商都在研发自己的半导体体系(包括谷歌、微软、亚马逊和Meta)。这应该会降低总体拥有成本(TCO),因为它不仅能消除利润率叠加,还能让他们专注于工作负载。
- 改进模型架构:现在有很多非Transformer的架构,如状态空间模型(适用于长上下文窗口的用例,如编码),以及JEPA(适用于视频模型)等等。
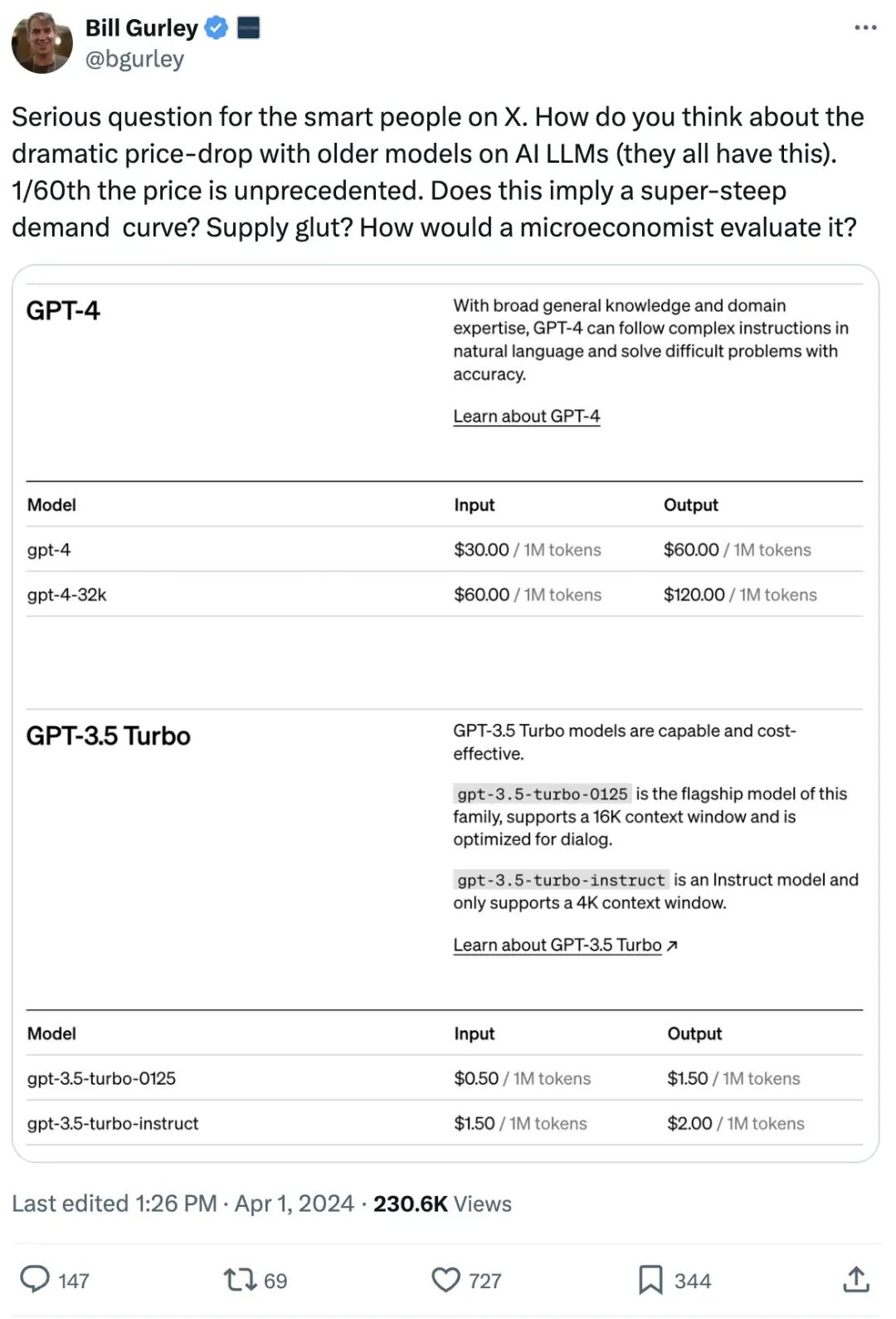
- 降低模型成本:通过批处理、蒸馏、量化、混合专家(MoE)等技术,模型的成本正迅速降低。正如Bill Gurley提到的:
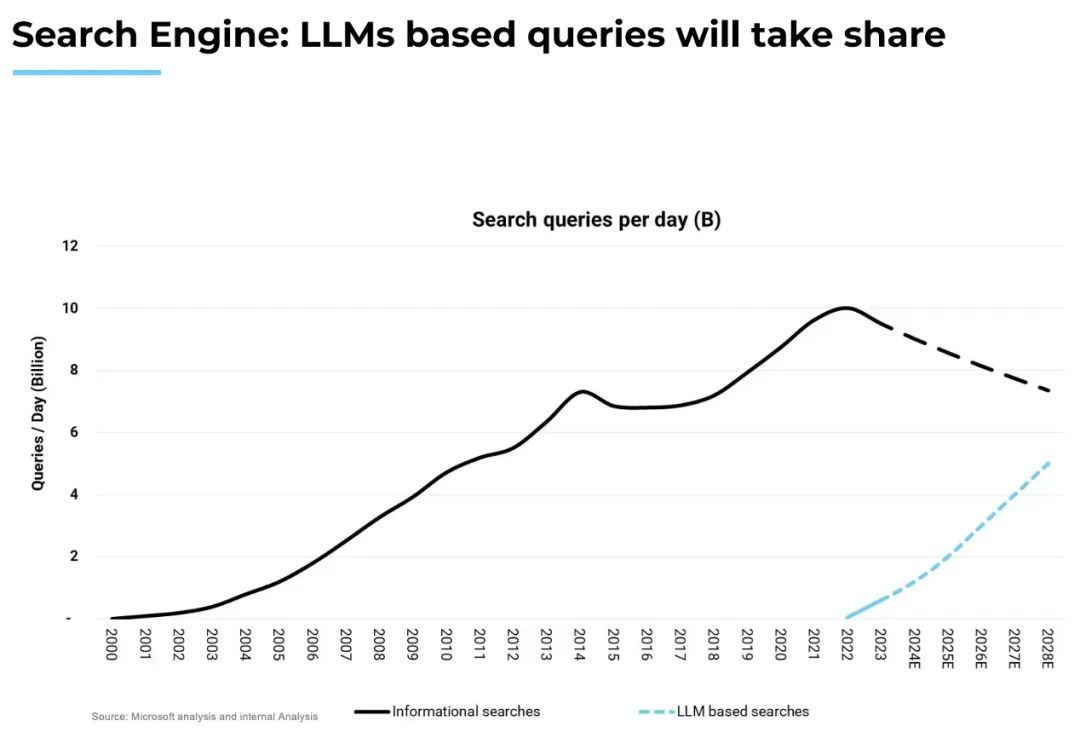
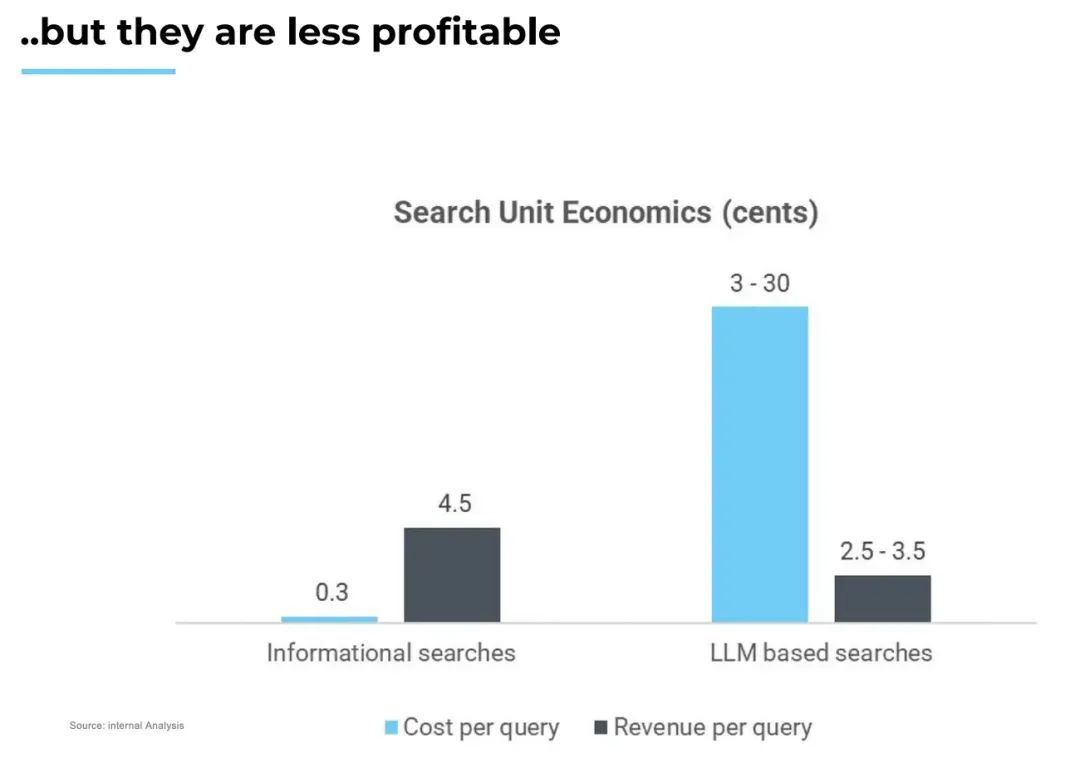
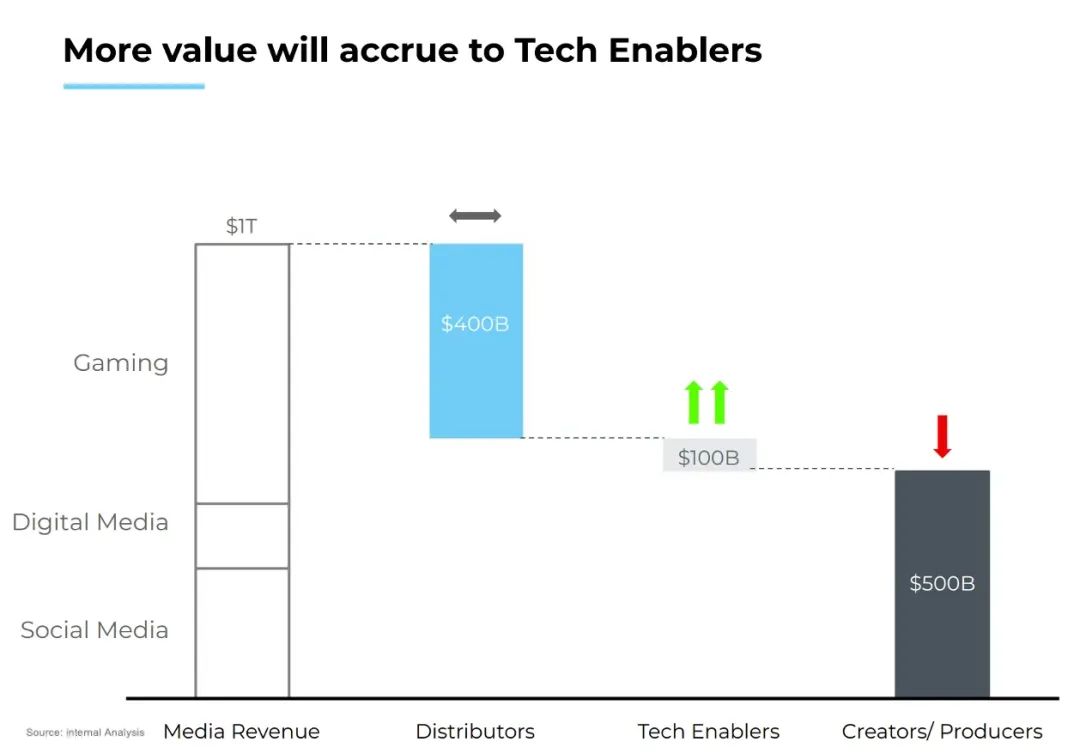
我预计,在消费级领域也会出现类似的转变,这会从硬件层开始。与数据中心一样,消费者设备也会升级为人工智能技术含量更高的产品,如AI PC、智能手机和其他新型的设备形态(如Meta眼镜、Humane Pin、Rabbit R1等)。消费者应用可分为三类:信息(搜索)、娱乐(游戏、媒体)和交易(旅行、电子商务等)。正如我的同事Vivek所分析的,搜索查询正逐渐从信息搜索转向基于LLM的搜索。娱乐行业也是如此:无论是游戏领域还是媒体领域,我们预计,价值创造的中心将从创作者/制造商转移到技术支持者。对此,Vivek的预测如下:感谢 Brad Gerstner、Sud Bhatija、Sanjiv Kalevar、Cobi B-Gantz、Omar Shaya、Jamin Ball、Vivek Goyal和Shreya Bhargava 对本文的贡献。[1] https://www.youtube.com/watch?v=3O4OujSFwt8[2] 1)根据英伟达2024财年第四季度数据中心收入(年化为184亿美元)计算的半导体层收入。2)基于内部估算的基础设施和应用层收入。3)https://www.coatue.com/blog/perspective/ai-the-coming-revolution-2023[3] 1),https://x.com/firstadopter/status/16916387279513970122)基于内部估算的人工智能基础设施层毛利率(65%不包括折旧费)3)https://www.theinformation.com/articles/anthropics-gross-margin-flags-long-term-ai-profit-questions?rc=5h8vss4)基于英特尔+ AMD CY2023结果的云计算半导体毛利率5)https://www.cnbc.com/2022/12/21/google-leaked-doc-microsoft-azure-losing-money-on-29-bln-in-revenue.html,6)https://www.meritechcapital.com/benchmarking/comps-table#/public-comparables/enterprise/valuation-metrics【语言大模型推理最高加速11倍】SiliconLLM是由硅基流动开发的高效、易用、可扩展的LLM推理加速引擎,旨在为用户提供开箱即用的推理加速能力,显著降低大模型部署成本,加速生成式AI产品落地。(技术合作、交流请添加微信:SiliconFlow01)

SiliconLLM的吞吐最高提升2.5倍,时延最高降低2.7倍
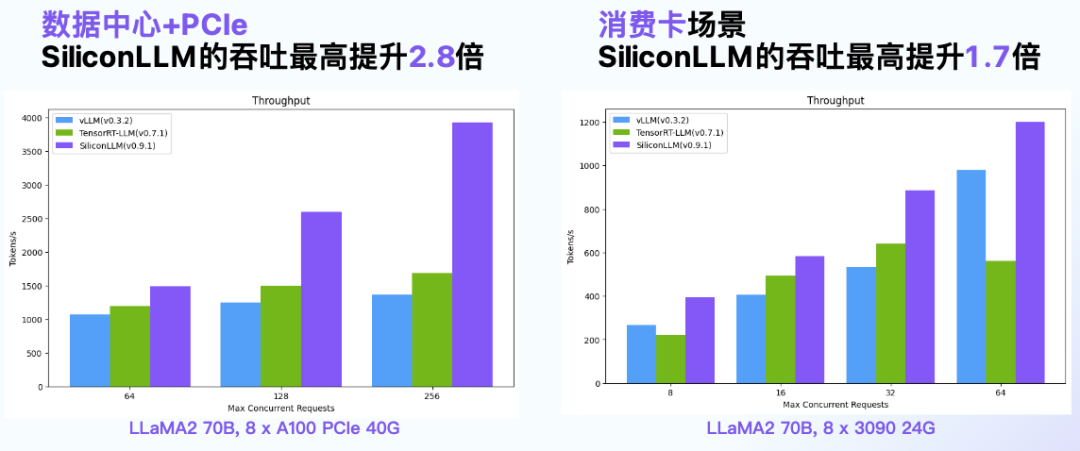
数据中心+PCIe:SiliconLLM的吞吐最高提升2.8倍;消费卡场景:SiliconLLM的吞吐最高提升1.7倍

System Prompt场景:SiliconLLM的吞吐最高提升11倍;MoE模型:推理 SiliconLLM的吞吐最高提升5倍

内容中包含的图片若涉及版权问题,请及时与我们联系删除




评论
沙发等你来抢