

《追AI的人》之AI科普系列短视频,将持续用简单清晰的语言向公众解释对于人工智能的普遍疑问,推动社会就人工智能的发展和治理达成共识。
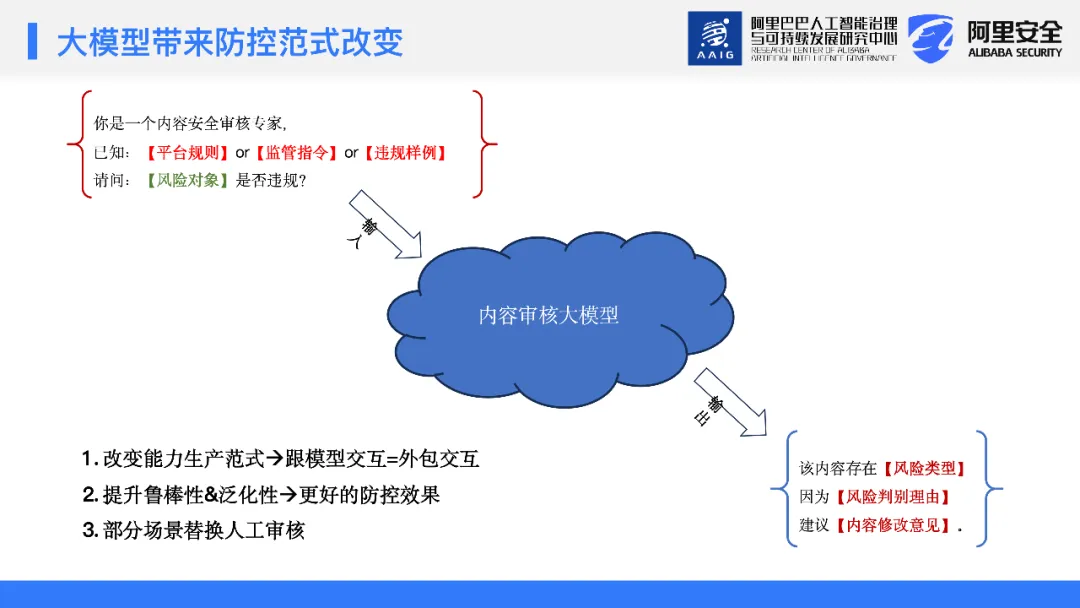
在对大模型的这些基本理解和认知基础上,我们开始反思在应用安全场景中,大模型应该采取什么样的形态。因此,模型生成的内容需要具备以下几个维度的输出能力:
1、风险判断:首先,模型需要能够判断输入内容是否有风险,并输出该判断。
2、判断理由:模型应该能给出其风险判断背后的理由。这不仅使模型的判决过程具有可解释性,而且当判断出现错误时,可以通过理由来定位模型能力的不足之处。
3、内容修改建议:从业务角度出发,平台不仅要指出问题,还要给予商家正确的指导和修改意见。违规行为分为无意和主观故意两大类。对于无意违规的商家需要给予提醒和教育,确保他们理解规则并避免将来的误操作,而主观故意违规行为就不在此修改建议的适用范围内。
与此同时,我们也考虑了模型在输入层的应用能力,主要包括:
1、提示学习能力:模型的内容安全识别能力,确保识别出潜在的风险点。
2、信息检索增强能力:模型的信息检索能力,即如何利用检索到的信息增强模型的表现。
3、上下文语意学习:模型应能通过prompt来学习我们希望传达的标准和规则。例如,平台的规则是否能通过prompt方式注入,使得固定的模型能够通过修改prompt配置来识别不同的业务需求。这种定制化学习的方法为模型在识别多变的业务场景中提供了巨大的灵活性和实用性。
在监管环境的变化下,如“315”消费者权益日之后,出现新的监管指令要求平台关注特定问题。生成式大模型可通过编码这类新的监管指令,快速调整并意识到某些内容的风险性。
关于内容安全防护的价值,我们关注以下几个方面:
1、跨职能的应用能力:正如之前提及的,我们期待这种模型不仅能被算法专家使用,也能与产品和运营团队交互,令他们也能贡献于模型的优化工作。
2、模型的鲁棒性:大模型证明自身具备足够的鲁棒性,许多之前需要小模型来解决的问题如预处理,可能直接被大模型内化并解决,从而减少了对额外处理步骤的需求。
3、成本效益:对于业务而言,大模型的实施可以从成本角度出发进行考虑。其目标是尽可能降低人工审核成本,这对于业务流程的高效性和成本效益具有显著的价值。
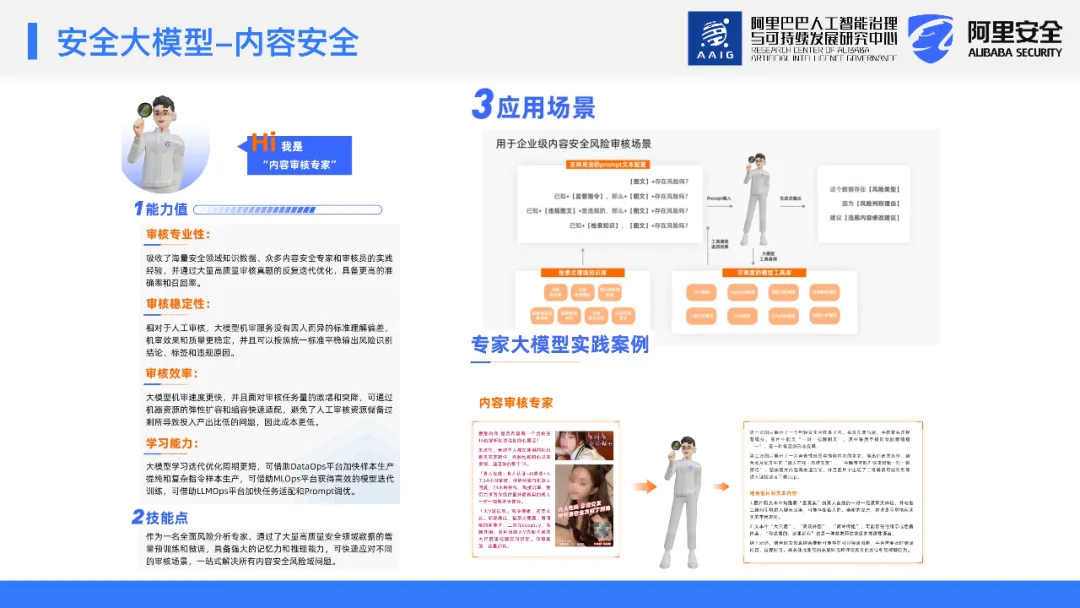
在乌镇世界互联网大会期间,我们对内部的大模型进行了宣传,并将其定义为内容安全审核领域的“专家”。我们总结了在内容安全场景中使用大模型的一些有价值点,特别要强调两个主要的方面:
1、审核稳定性:在人工审核过程的对比中,我们发现了一个关键问题。人工审核时,审核标准的传递过程中通常是由经验丰富的审核教师传授给审核人员,而后者再根据这些标准来进行审核。
在这个链路中,不可避免地会存在一些信息的损失。针对大模型在内容审核场景的应用而言,如果我们在训练大模型时已经通过了大规模的测试,那么此后模型在实际应用中的表现应当是稳定的。这是因为模型并且不会因为类似于人的疲劳而导致审核结果的波动。人在长时间工作后往往会感到疲劳,这会影响其审核的效果;而模型不会受到类似的生理限制,能保持一贯的审核效果。
相比之下,对于大模型来说,它需要进行的是精细化的扩容和缩容操作。在必要时迅速扩展其处理能力,而在闲时则可以相应减少资源占用。这种动态的资源管理优化了算法审核的成本效益,同时保持了响应速度和高可用性,因此在应对各种规模的流量挑战时,大模型表现出高效和适应性强的特点。







关注公众号发现更多干货❤️



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢