

编译 | 熊展坤
审核 | 王紫嫣
今天介绍的是ICLR 2024接收的论文:BIOBRIDGE: BRIDGING BIOMEDICAL FOUNDATION MODELS VIA KNOWLEDGE GRAPHS,该论文提出了一个参数高效的学习框架,以桥接独立训练的单模态模型以建立多模态行为。
基础模型(FMs)从大量未标记的数据中学习,以在广泛的任务中展示卓越的性能。然而,为生物医学领域开发的FMs在很大程度上仍然是单模态的,即独立训练并单独用于蛋白质序列、小分子结构或临床数据的任务。为了克服这一限制,作者提出了BioBRIDGE,一个参数高效的学习框架,以桥接独立训练的单模态模型以建立多模态行为。BioBRIDGE通过使用知识图(Knowledge Graphs, KG)来学习一个单模态FM与另一个单模态FM之间的转换,而无需对任何底层单模态FM进行微调。研究结果表明,在跨模态检索任务中,BioBRIDGE可以击败最佳基线KG嵌入方法(平均高出约76.3%)。作者还通过外推到KG中不存在的模态或关系来验证BioBRIDGE具有域外泛化能力。此外,实验还表明,BioBRIDGE作为一种通用检索器,可以帮助生物医学多模态问题的回答,并增强新药的引导生成。
在大量数据上训练的基础模型可以用于不同的领域。在生物医学领域,FMs被训练以获取科学文献中的文本语料库、序列和3d结构中的蛋白质数据、分子图和SMILES字符串以及关系图形式的蛋白质相互作用数据。与之前在较小数据集上训练的方法相比,这些预训练的生物医学FMs取得了显著的收益。在训练中引入多模态数据可以进一步提高FM的性能,特别是在few-shot/zero-shot预测设置中。在生物医学领域,对于药物文本、蛋白质文本和药物-蛋白质数据,通过联合优化单模态编码器来利用多模态数据。然而,当超出两种模态时,这个想法遇到了关键问题:一方面是计算成本。这些方法需要许多大小近似的单模态编码器,以避免相互阻碍。这种设置可能会导致模型大小随模态数量提升。另一方面是数据稀缺。它们需要相似大小的成对跨模态数据集,以确保稳定的训练,不可避免地导致数据稀缺。
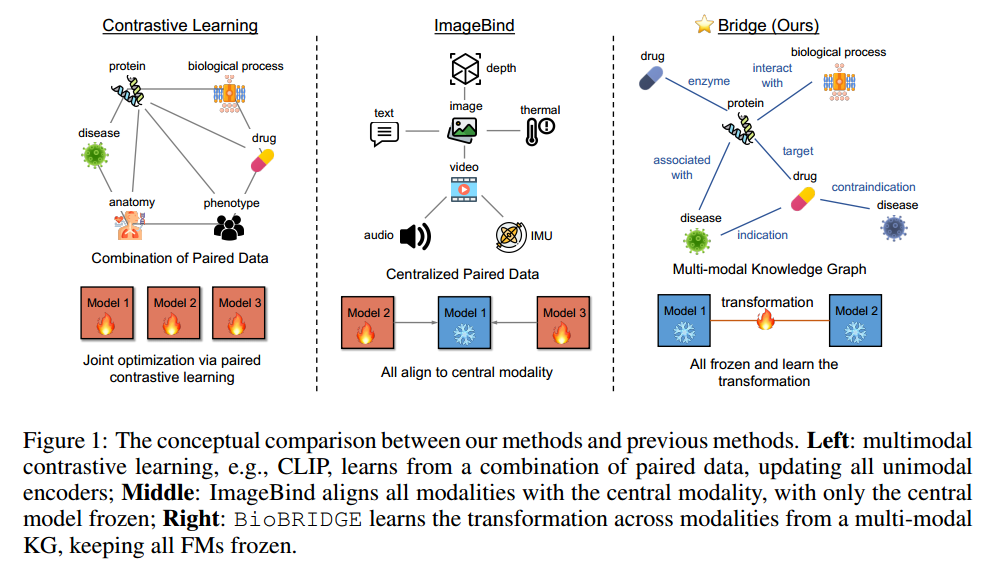
与ImageBind不同,ImageBind将图像设置为中心模态,并通过微调将所有其他编码器与图像对齐,所提出的BioBRIDGE将所有单模态FM保持固定,并学习桥接这些单模态FM。概念演示如上图所示。具体来说,BioBRIDGE从生物医学知识图(KGs)中学习跨模态转换。该方法通过利用以下见解来建模:数据充分性:通常收集单模态数据比从两个模态收集成对数据更容易。例如,接近250M个蛋白质序列和1.5B个分子结构可用于进行自监督预训练,而最大的生物多模态数据集之一只有441K个蛋白质-文本对。因此,与多模态编码器的联合训练相比,在单模态数据上进行大规模训练的桥接独立模型具有数据充足和效率高的优点。结构转换:多模态生物医学KG包含由头尾生物医学实体及其关系的三元组表示的结构信息。它涵盖了丰富的模态,如蛋白质、分子和疾病,这使得全面的生物医学分析和机器学习成为可能。作者利用KG三元组中的丰富结构,通过跨模态转换模型对齐单模态FMs的嵌入空间。
BioBRIDGE旨在创建一种通用的桥接机制,能够有效地连接任何对模态的表示。在技术上,利用知识图中丰富的结构信息对桥梁模块进行监督,同时对单模态模型进行冻结,提高了参数化和计算效率。实验表明:
•桥接的单模态模型在不同的跨模态预测任务中具有竞争力。
•BioBRIDGE可以外推到训练KG中不存在的节点,其性能与监督基线相当。
•BioBRIDGE能够推广到训练KG中不存在的关系,并且可以通过进一步的训练来提高性能。
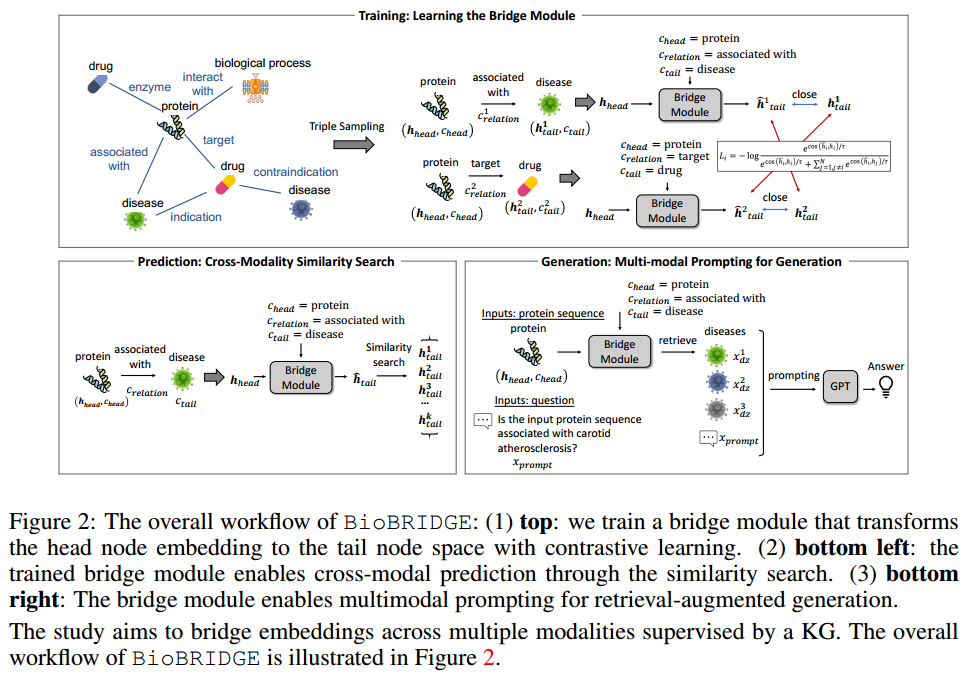
BioBRIDGE:的基本架构如上图所示。
在训练阶段,BioBRIDGE分别从两个模态和中采样连接和的三元组。桥接模块φ将头节点嵌入变换到模态空间,得到。具体来说,样本v = {x, c}的原始嵌入由模态特定的投影头p投影为,以确保所有嵌入都遵循相同的维度。作者还将、、作为分类变量,分别生成它们的嵌入、和,它们的维数都是d。对嵌入的投影头节点进行变换
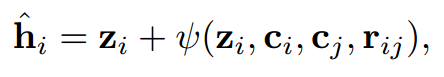 其中生成关系感知变换嵌入加到。
其中生成关系感知变换嵌入加到。
作者通过用其他{}替换尾部节点来扰动,其中来构建信息负样本。基于编码后的尾节点和转换后的头节点,如下: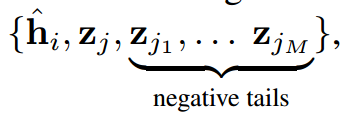 再使用InfoNCE loss进行对比学习:
再使用InfoNCE loss进行对比学习:
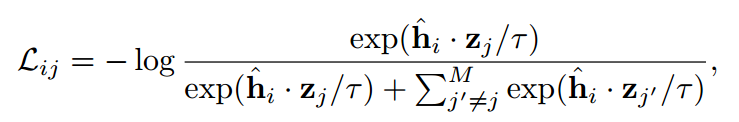 式中,M为采样的负反面个数;τ是一个标量温度,在传递到损失函数之前,所有嵌入都被它们的l2范数归一化。这种损失使接近正确的三元组尾。当基本单模态FM被冻结时,只更新变换模块ψ和模态特定的投影头的参数。
式中,M为采样的负反面个数;τ是一个标量温度,在传递到损失函数之前,所有嵌入都被它们的l2范数归一化。这种损失使接近正确的三元组尾。当基本单模态FM被冻结时,只更新变换模块ψ和模态特定的投影头的参数。
虽然训练中使用了从KG中提取的三元组,但BioBRIDGE并没有参考KG进行推理。例如,对于和目标模态,作者用基础模型FM g(·)来编码,并将它们投射到归一化嵌入。然后用基础模型FM f(·)对进行编码,并将其变换到C的嵌入空间中,得到归一化的。可以通过矩阵内积有效地比较与的相似度,如:。
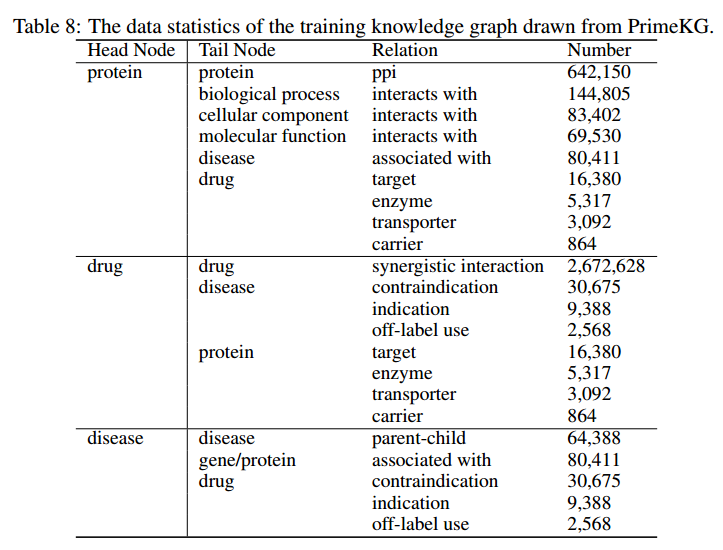
作者使用PrimeKG的一个子集来构建训练知识图。具体来说,作者从图中选择了六种主要节点类型:蛋白质、分子、疾病、生物过程(BP)、分子功能(MF)和细胞成分(CC),而不丢失一般性。训练KG中三组的统计数据见下表。准确的训练集根据下游评估数据集而变化,以避免实验中的数据泄漏。
作者将六种类型的节点分为三种模态:蛋白质序列、SMILES字符串和自然语言。技术上,作者利用ESM2-3B编码蛋白质,UniMol编码药物分子,PubMedBERT编码疾病、生物过程、分子功能和细胞成分。对于文本节点,作者将其名称和定义连接起来,形成PubMedBERT的输入。虽然有许多潜在的选项来构建转换,但作者为桥接模块ψ选择了一个普通的六层transformer模型,以验证该方法的合理性。具体来说,作者将, , 和堆叠起来,以构建transformer的输入。作者在transformer后的第一个位置上绘制嵌入作为ψ的输出,以添加到输入z上。
关于桥接模块的存在性和可学习性的具体理论分析细节见原文
在本节中,作者通过实验来测试BioBRIDGE的预测能力。 具体来说,预测任务可以分为:
•域内实体和关系类型。输入实体的类型和输入关系都存在于训练知识图中,作者在其中进行了两个系列的实验:跨模态检索任务和语义相似性推理。
•域内实体和域外关系类型。作者考虑目标关系在训练图中不存在的情况,即out域。作者对该类任务进行了蛋白-蛋白相互作用预测。
•域外实体和域内关系类型。作者还进行了域外实体但域内关系的实验:跨物种蛋白质-表型匹配。
BioBRIDGE能够通过将转换后的嵌入与目标模态嵌入空间中的候选样本进行匹配来执行跨模态检索。为了衡量转换后嵌入的质量,作者将BioBRIDGE与一系列知识图嵌入(KGE)方法进行了比较:TransE、TransD、TransH、TransR、ComplEx 、DistMult和RotatE,使用OpenKE实现。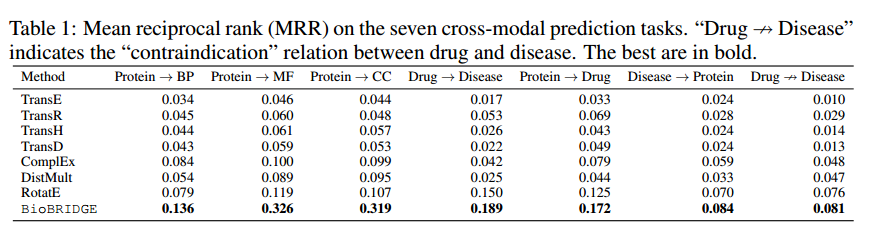
作者分别在上表中显示了七个任务的MRR。可以发现BioBRIDGE在KGE方法中一直名列前茅。专门的KGE算法完全基于KG从头开始学习节点和关系嵌入,而BioBRIDGE建立在已经拥有丰富先验知识的预训练FM上。因此,BioBRIDGE以更有效的数据方式连接各种模态。对不同任务的性能进行细分。作者观察到BioBRIDGE在使用较少的KG三元组的任务上获得了比基线更高的边际。例如,BioBRIDGE比“蛋白质→MF”的最佳基线好3倍左右,而“蛋白质→BP”的最佳基线好1.6倍左右,这表明BioBRIDGE在桥接具有有限数据的多模态任务的FMs方面优于从头训练多模态模型。
该分析的目的是评估编码蛋白嵌入在多大程度上可以捕获生物分子功能相似性,即生物过程(BP)、分子功能(MF)和细胞成分(CC)。作者以蛋白质的基因本体(GO)术语注释为目标。使用转换为BP, MF和CC空间的蛋白质嵌入作为评估的输入。计算编码蛋白嵌入的成对曼哈顿相似度作为预测。最终得分是通过计算预测结果与groundtruth矩阵之间的Spearman秩相关得到的,该秩相关越大越好。
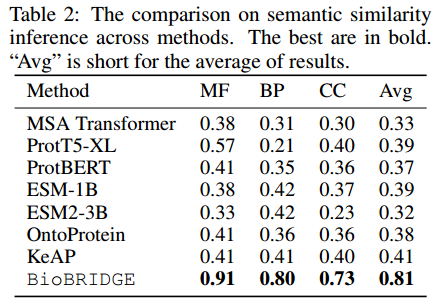 上表中的结果可以看出,BioBRIDGE产生了实质性的改进,平均比最佳基线好2倍左右。在基线上,可以观察到KG增强的方法,包括KeAP和OntoProtein,比其他方法产生更好的结果,这意味着KG连接蛋白质和生物属性增强了蛋白质表征学习。尽管如此,BioBRIDGE学会了将蛋白质嵌入转换为生物分子功能嵌入空间,从而更好地将蛋白质序列与功能-的语义对齐。此外,其他模态的参与,如来自KG的药物在训练中进一步丰富了对转化模型的监督。
上表中的结果可以看出,BioBRIDGE产生了实质性的改进,平均比最佳基线好2倍左右。在基线上,可以观察到KG增强的方法,包括KeAP和OntoProtein,比其他方法产生更好的结果,这意味着KG连接蛋白质和生物属性增强了蛋白质表征学习。尽管如此,BioBRIDGE学会了将蛋白质嵌入转换为生物分子功能嵌入空间,从而更好地将蛋白质序列与功能-的语义对齐。此外,其他模态的参与,如来自KG的药物在训练中进一步丰富了对转化模型的监督。
作者研究蛋白质-蛋白质相互作用(PPI)预测任务,因为它代表了第二种实验设置:域内实体和域外关系。PPI预测任务旨在对一对蛋白的7种相互作用类型进行分类:反应、结合、翻译后修饰、激活、抑制、催化和表达。虽然在PrimeKG中存在ppi关系,但它只代表物理相互作用(类似于7种类型中的“Binding”),而其他6种类型是域外的。作者使用基线预训练的蛋白质模型提取蛋白质嵌入,并将其作为在PPI网络上训练的图神经网络模型的输入。BioBRIDGE将蛋白质嵌入转化为具有ppi关系的蛋白质空间。作者展示了这个多类分类任务的F1分数。
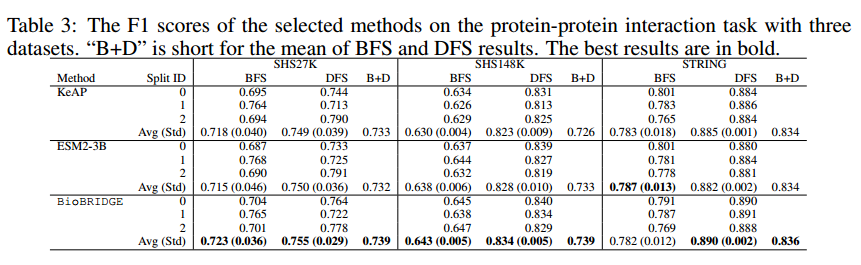
从上表的结果中可以观察到,尽管结果在不同的split中有所不同,但在大多数情况下,BioBRIDGE显示出对基线的一致改进。结果表明,ESM2-3B比现有的最先进的KeAP性能更好,这可归因于其在庞大的蛋白质数据库上进行的预训练。BioBRIDGE通过注入关系“ppi”进一步增强ESM2的嵌入,然后转换回蛋白质空间。BioBRIDGE在SHS27K等样本较少的数据集上表现出更大的效益,因为它利用蛋白质-蛋白质相互作用的本体信息丰富了蛋白质嵌入。当训练数据数量增加时,所有方法趋于收敛到同一水平,但基线仍然不如BioBRIDGE。
作者提出这个新任务来测试BioBRIDGE处理域外实体和域内关系的跨模态转换的能力。由于PrimeKG仅包含人类蛋白质,作者从小鼠基因组信息学(MGI)资源中构建了小鼠蛋白质和相关小鼠表型的数据集,作为域外实体。由于BioBRIDGE的训练数据中没有“表型”模态,因此作者将编码的小鼠蛋白嵌入转换为具有“关联”关系的“疾病”空间。作者使用一套排名指标来评估匹配性能,包括Recall@K、Precision@K和nDCG@K。
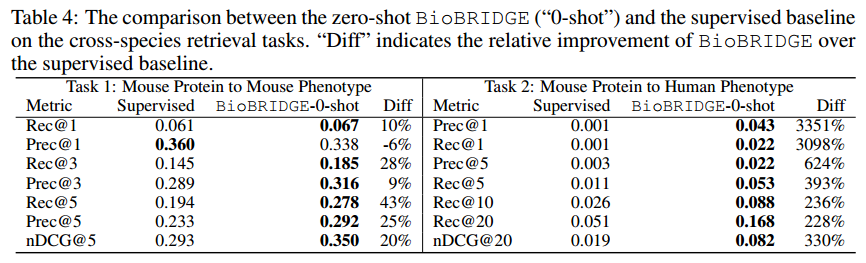 上表是该任务的结果,这是一项具有挑战性的任务,因为在训练数据中既没有使用小鼠蛋白质,也没有使用小鼠/人类表型。尽管如此,潜在的蛋白质FM在不同物种的蛋白质序列上进行了全面的预训练。随着BioBRIDGE学会架起人类蛋白质和人类疾病的桥梁,它展示了将小鼠蛋白质从蛋白质空间转化为文本空间中的小鼠表型的新兴能力。在任务1中,BioBRIDGE展示了对配对小鼠蛋白质和表型数据进行微调的监督基线上的较大裕度。这一观察结果强调了将BioBRIDGE转移到一个新的领域而无需进一步训练的可行性。在任务2中,尽管对配对的小鼠蛋白质和小鼠表型进行了学习,但监督基线未能推断出小鼠蛋白质与人类表型的匹配。然而,BioBRIDGE利用了蛋白质和人类疾病基础FMs的先验知识。这一鼓舞人心的结果暗示了通过跨模态匹配实现桥接FMs的新型生物信息学分析的潜力。
上表是该任务的结果,这是一项具有挑战性的任务,因为在训练数据中既没有使用小鼠蛋白质,也没有使用小鼠/人类表型。尽管如此,潜在的蛋白质FM在不同物种的蛋白质序列上进行了全面的预训练。随着BioBRIDGE学会架起人类蛋白质和人类疾病的桥梁,它展示了将小鼠蛋白质从蛋白质空间转化为文本空间中的小鼠表型的新兴能力。在任务1中,BioBRIDGE展示了对配对小鼠蛋白质和表型数据进行微调的监督基线上的较大裕度。这一观察结果强调了将BioBRIDGE转移到一个新的领域而无需进一步训练的可行性。在任务2中,尽管对配对的小鼠蛋白质和小鼠表型进行了学习,但监督基线未能推断出小鼠蛋白质与人类表型的匹配。然而,BioBRIDGE利用了蛋白质和人类疾病基础FMs的先验知识。这一鼓舞人心的结果暗示了通过跨模态匹配实现桥接FMs的新型生物信息学分析的潜力。
研究了单模态生物医学基础模型在多模态任务中的桥接。考虑到源模态和目标模态的类型以及它们之间的关系,作者发现BioBRIDGE可以有效地将嵌入转换为目标模态。它具有很高的参数效率:只需要训练桥接模块,而所有的基本模型都是固定的,并由生物医学知识图的关系信息来监督。作者还发现,BioBRIDGE可以通过外推域内/域外实体和关系来处理各种跨模态预测任务。在每个任务中,生成的性能与监督专家模型相当。此外,作者还演示了桥接FM如何支持具有多模态输入的生成任务。在未来,作者设想BioBRIDGE可以扩展到连接来自其他领域的预训练的FM,只要不同模态的实体可以在KG中表示。
论文:https://openreview.net/pdf?id=jJCeMiwHdH
代码:https://github.com/RyanWangZf/BioBridge
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢