
在缺少标注数据场景,SetFit 是解决的建模问题的一个有前途的解决方案,其由 Hugging Face 与
SetFit 仅需很少的标注数据就能达到较高的准确率,例如,在使用 3-示例提示时,SetFit
Intel 实验室 https://www.intel.com/content/www/us/en/research/overview.html UKP Lab https://www.informatik.tu-darmstadt.de/ukp/ukphome/index.en.jsp Sentence Transformers https://sbert.net/ SetFit 优于 GPT-3.5 https://arxiv.org/pdf/2311.06102.pdf
与基于 LLM 的方法相比,SetFit 有两个独特的优势:
🗣 无需提示或词-标签映射器:基于 LLM 的少样本上下文学习依赖于人工制作的提示,其对措辞比较敏感,且依赖用户的专业知识,因此效果比较脆弱。SetFit 直接从少量标注文本样本中生成丰富的嵌入,从而完全省去了提示。
🏎 训练速度快:SetFit 不依赖 GPT-3.5 或 Llama2 等 LLM 来实现高准确率。因此,训练和推理速度通常要快一个数量级 (或更多) 。
有关 SetFit 的更多详情,请参阅:
论文 https://arxiv.org/abs/2209.11055 博客 https://hf.co/blog/setfit 代码 https://github.com/huggingface/setfit 数据 https://hf.co/SetFit Hugging Face Hub 上的 SetFit 模型 https://hf.co/models?library=setfit
加速!
本文,我们将解释如何用 🤗
Optimum Intel https://github.com/huggingface/optimum-intel bfloat16 https://en.wikipedia.org/wiki/Bfloat16floating-pointformat Intel Extension for PyTorch https://github.com/intel/intel-extension-for-pytorch
使用 Optimum Intel 可以轻松对各种预训练模型进行加速,你可在
Optimum Intel 案例 https://hf.co/docs/optimum/main/en/intel/optimizationinc Notebook 版 https://github.com/huggingface/setfit/blob/main/notebooks/setfit-optimum-intel.ipynb
第 1 步:使用 🤗 Optimum Intel 量化 SetFit 模型
在对 SetFit 模型进行优化时,我们会使用
英特尔神经压缩器 https://www.intel.cn/content/www/cn/zh/developer/tools/oneapi/neural-compressor.html
量化是一种非常流行的深度学习模型优化技术,可用于提高推理速度。它通过将一组高精度数值转换为较低位宽的数据类型 (如 INT8) 。从而最大限度地降低神经网络的权重和/或激活所需的位数。另外,由于位宽较低,其计算速度也可能会更快。
本文,我们将使用训后静态量化 (PTQ) 。PTQ 仅需少量未标注校准数据,无需任何训练即可在保持模型的准确性的同时减低推理时的内存占用并降低延迟。首先请确保你已安装所有必要的库,同时确保 Optimum Intel 版本至少为 1.14.0 (因为 PTQ 功能是从该版本开始引入的) :
pip install --upgrade-strategy eager optimum[ipex]
准备校准数据集
校准数据集应能在数据分布上较好代表未见数据。一般来说,准备 100 个样本就足够了。在本例中,我们使用的是 rottentomatoes 数据集,其是一个电影评论数据集,与我们的目标数据集 sst2 类似。
首先,我们从该数据集中随机加载 100 个样本。然后,为了准备量化数据集,我们需要对每个样本进行标注。我们不需要 text 和 label 列,因此将其删除。
calibration_set = load_dataset("rotten_tomatoes", split="train").shuffle(seed=42).select(range(100))
def tokenize(examples):
return tokenizer(examples["text"], padding="max_length", max_length=512, truncation=True)
tokenizer = setfit_model.model_body.tokenizer
calibration_set = calibration_set.map(tokenize, remove_columns=["text", "label"])
量化
量化前,先要配置所需的量化方案,本例中为静态训后量化,再使用 optimum.intel 在校准数据集上运行量化:
from optimum.intel import INCQuantizer
from neural_compressor.config import PostTrainingQuantConfig
setfit_body = setfit_model.model_body[0].auto_model
quantizer = INCQuantizer.from_pretrained(setfit_body)
optimum_model_path = "/tmp/bge-small-en-v1.5_setfit-sst2-english_opt"
quantization_config = PostTrainingQuantConfig(approach="static", backend="ipex", domain="nlp")
quantizer.quantize(
quantization_config=quantization_config,
calibration_dataset=calibration_set,
save_directory=optimum_model_path,
batch_size=1,
)
tokenizer.save_pretrained(optimum_model_path)
就这样!现在,我们有了一个量化版的 SetFit 模型。下面,我们对其进行测试。
第 2 步:推理基准测试
我们在
使用 PyTorch 和 🤗 Transformers 库对 fp32 模型进行推理。 使用 Intel Extension for PyTorch https://github.com/intel/intel-extension-for-pytorch (IPEX) 对模型进行 bf16 推理,同时使用 TorchScript 对模型进行图优化。使用 Optimum Intel 对 int8 量化模型进行推理。
加载测试数据集 sst2,并使用 PyTorch 和 🤗 Transformers 库运行基准测试:
from datasets import load_dataset
from setfit import SetFitModel
test_dataset = load_dataset("SetFit/sst2")["validation"]
model_path = "dkorat/bge-small-en-v1.5_setfit-sst2-english"
setfit_model = SetFitModel.from_pretrained(model_path)
pb = PerformanceBenchmark(
model=setfit_model,
dataset=test_dataset,
optim_type="bge-small (transformers)",
)
perf_metrics = pb.run_benchmark()
第二个基准测试,我们将使用 bf16 精度和 TorchScript 两种优化手段,并使用
dtype = torch.bfloat16
body = ipex.optimize(setfit_model.model_body, dtype=dtype)
使用 TorchScript 进行图优化时,我们根据模型的最大输入长度生成随机序列,并从分词器的词汇表中采样词汇:
tokenizer = setfit_model.model_body.tokenizer
d = generate_random_sequences(batch_size=1, length=tokenizer.model_max_length, vocab_size=tokenizer.vocab_size)
body = torch.jit.trace(body, (d,), check_trace=False, strict=False)
setfit_model.model_body = torch.jit.freeze(body)
最后,我们对量化的 Optimum 模型运行基准测试。我们首先定义一个 SetFit 模型的包装类,该包装类在推理时会自动插入量化模型体 (而不是原始模型体) 。然后,我们用这个包装类跑基准测试。
from optimum.intel import IPEXModel
class OptimumSetFitModel:
def __init__(self, setfit_model, model_body):
model_body.tokenizer = setfit_model.model_body.tokenizer
self.model_body = model_body
self.model_head = setfit_model.model_head
optimum_model = IPEXModel.from_pretrained(optimum_model_path)
optimum_setfit_model = OptimumSetFitModel(setfit_model, model_body=optimum_model)
pb = PerformanceBenchmark(
model=optimum_setfit_model,
dataset=test_dataset,
optim_type=f"bge-small (optimum-int8)",
model_path=optimum_model_path,
autocast_dtype=torch.bfloat16,
)
perf_metrics.update(pb.run_benchmark())
Notebook 网址 https://github.com/huggingface/setfit/blob/main/notebooks/setfit-optimum-intel.ipynb IPEX https://github.com/intel/intel-extension-for-pytorch
结果
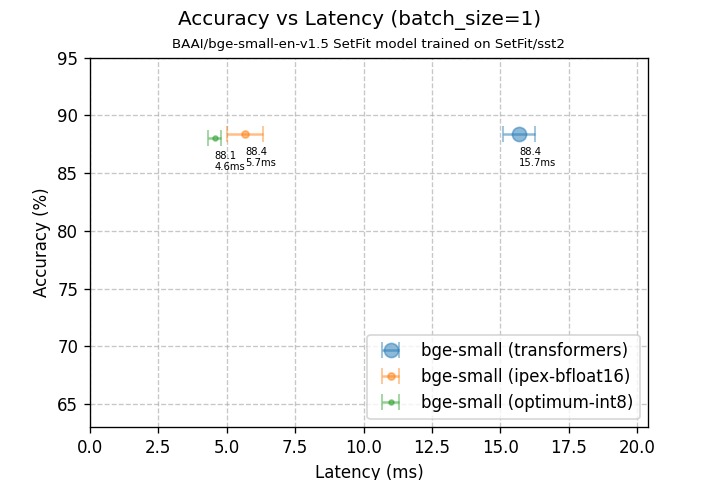
| bge-small (transformers) | bge-small (ipex-bfloat16) | bge-small (optimum-int8) | |
|---|---|---|---|
| 模型大小 | 127.32 MB | 63.74 MB | 44.65 MB |
| 测试集准确率 | 88.4% | 88.4% | 88.1% |
| 延迟 (bs=1) | 15.69 +/- 0.57 ms | 5.67 +/- 0.66 ms | 4.55 +/- 0.25 ms |
batch size 为 1 时,我们的优化模型将延迟降低了 3.45 倍。请注意,此时准确率几乎没有下降!另外值得一提的是,模型大小缩小了 2.85x。
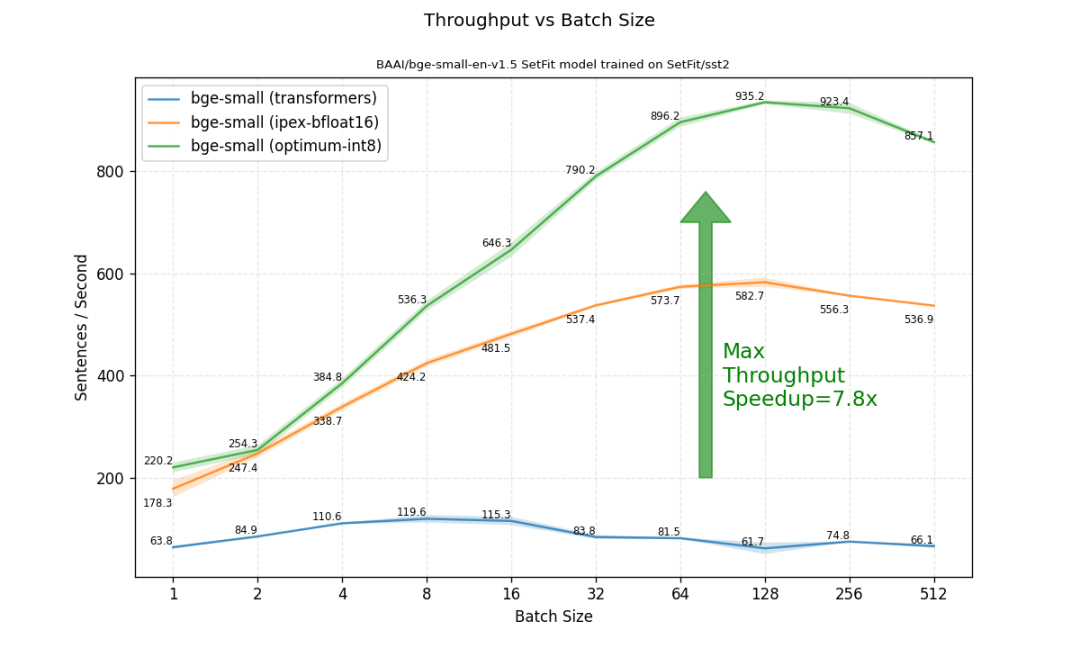
我们将焦点转向不同 batch size 下的吞吐量。这里,我们获得了更大的加速。如果比较最高吞吐量 (不限 batch size) ,优化后的模型比原始 transformers fp32 模型高 7.8 倍!
总结
我们展示了如何使用 🤗 Optimum Intel 中的量化功能来优化 SetFit 模型。在轻松快速地对模型完成训后量化后,我们观察到在准确度损失很小的情况下,推理吞吐量增加了 7.8 倍。用户可以使用这种优化方法在英特尔至强 CPU 上轻松部署任何现有 SetFit 模型。
参考文献
https://arxiv.org/abs/2209.11055
英文原文: https://hf.co/blog/setfit-optimum-intel
原文作者: Daniel Korat, Tom Aarsen, Oren Pereg, Moshe Wasserblat, Ella Charlaix, Abirami Prabhakaran
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢