

Machine Intelligence Research
创建大规模且标注完善的数据集来训练人工智能算法,对于肿瘤的自动检测和定位至关重要。然而由于资源有限,确定最佳的标签类型来标注大量数据是一项挑战。为了解决这一难题,约翰霍普金斯大学及苏黎世联邦理工学院的研究者们聚焦于结肠镜检查视频中的息肉和腹部CT扫描中的胰腺肿瘤。由于这些数据在时间和空间层面的高维性质,需要耗费大量精力和时间进行逐像素的标注。基于此,本文提出了一种名为拖放(Drag&Drop)的新标注策略,将标注过程简化为拖放操作。与其他弱标签(如逐像素、包围盒、线标签、椭圆和点)相比,这种策略更加高效,尤其是在时序和高维图像方面。此外,为了利用拖放标签,本文开发了一种基于分水岭算法的新型弱监督学习方法。实验结果表明,本文的方法在检测和定位性能上优于其他弱标签方法。更重要的是,其性能与基于逐像素标签训练的模型相当。值得注意的是,在资源有限的情况下,使用弱标签标注多样化的患者群体比仅对少量患者进行逐像素标注能提高模型对未知图像的鲁棒性。综上所述,本研究提出了一种用于肿瘤检测和定位的高效标注策略,虽然不及像素级标签精确,但对于在各种医疗模态数据中筛查肿瘤并创建大规模数据集具有重要意义。
项目主页:

图片来自Springer
全文下载:
Acquiring Weak Annotations for Tumor Localization in Temporal and Volumetric Data
Yu-Cheng Chou, Bowen Li, Deng-Ping Fan, Alan Yuille & Zongwei Zhou
https://link.springer.com/article/10.1007/s11633-023-1380-5
https://www.mi-research.net/en/article/doi/10.1007/s11633-023-1380-5
肿瘤检测和定位通常被视为语义分割任务,称为分割式检测。其假设是通过识别和分割肿瘤边界可以提高肿瘤检测率。然而,并非所有医疗场景都适用这个观点,尤其是在筛查中,预测肿瘤的大致位置和大小比准确分割肿瘤边界更为重要。例如,息肉检测只需要识别出息肉,然后在结肠镜检查过程中切除即可。在这种情况下,准确分割息肉边界可能并非必要。然而,大多数用于息肉检测的公开数据集都会为每个息肉提供非常耗时和昂贵的逐像素标签。类似的问题也出现在其他侧重于肿瘤检测,但采用逐像素标签的医学场景中。这凸显了使用分割式检测策略创建大规模标注数据集进行肿瘤检测时潜在的资源浪费。本文认为,对于某些检测任务来说,高精度的边界分割并不是关键,因此逐像素的标注可能并非必要。
相反,弱标签更具成本效益,所需时间也比逐像素标签少。本文假设弱标签比分割式检测策略更适合用于肿瘤检测和定位。本文从三个方面证明了这一点。首先,在固定的标注预算下,使用逐像素标注必然会因为高昂的标注成本而牺牲数据的多样性和样本数量。而弱标签允许更大的数据多样性,从而提高了在少数情况下(例如年龄)肿瘤检测率(表1和表2)。其次,分割式检测的肿瘤分割往往会产生许多假阳性预测。逐像素标注的数据集(如KiTS)只提供包含肿瘤的图像。这可能会造成一种偏差--AI算法在每张未知图像中都假定有肿瘤的出现(表3)。第三,逐像素标注需要大量的时间和资源。具体而言,对位于高维CT扫描中的胰腺肿瘤进行逐像素标注,每个受试者需要四分钟,而如果进行弱标注,每个受试者平均只需要两秒钟(表4)。同样,在息肉检测中,弱标注比逐像素标注快八倍(分别为2秒和16秒)。
尽管逐像素标注的成本和时间消耗令人望而却步,但它在肿瘤检测和定位任务中仍被广泛采用于训练和测试AI算法。本文通过利用跨维度的上下文信息,为时序和高维医学图像等多维数据设计了一种新的弱标注策略。本文称这种策略为"拖放"(Drag&Drop),因为此方法涉及点击肿瘤,然后拖动并释放以提供肿瘤的大致半径。这种标注策略足以捕捉每个肿瘤的大小和位置,而无需精确的边界分割。为了利用拖放标注,本文进一步开发了基于经典分水岭算法的弱监督框架,并利用拖放提供的近似肿瘤大小和位置约束进行了优化。本文的弱监督框架大大降低了逐像素标签中常见的肿瘤边界处噪声的影响。本文在实验中表明,通过使用拖放标签进行训练,AI算法在肿瘤检测和定位任务中可以达到与逐像素标签类似的性能。本文还证明了拖放标签相对于之前的弱标注策略(如线标签、点、包围盒和椭圆)在肿瘤检测和定位方面的优越性(表 4)。
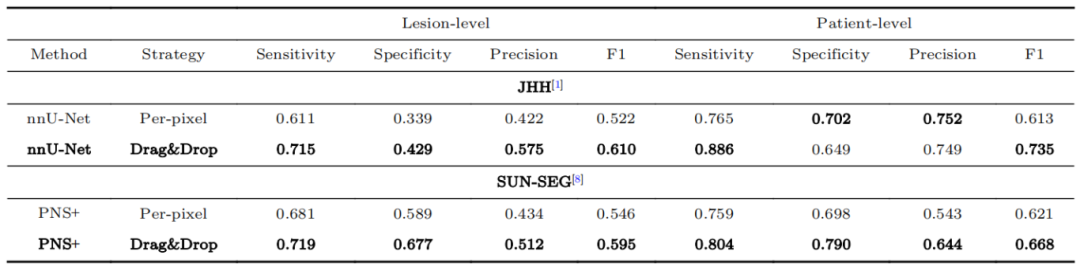
表1 在固定的标注预算下,本文的拖放策略在肿瘤检测和定位方面远远优于逐像素标签。更重要的是,与逐像素标签相比,拖放策略将肿瘤分割率从43%提高到54%(以DSC分数衡量)。

表2 JHH数据集上,根据年龄分布进行的病灶检测性能对比。本文的拖放策略实现了更高的多样性,从而提高了少数病例的检测率(以粗体标出)。本文使用了透过逐像素标签训练的nnU-Net。请注意,在45-50岁这个年龄段,检测结果为0,因为所有案例都是健康的,没有肿瘤。
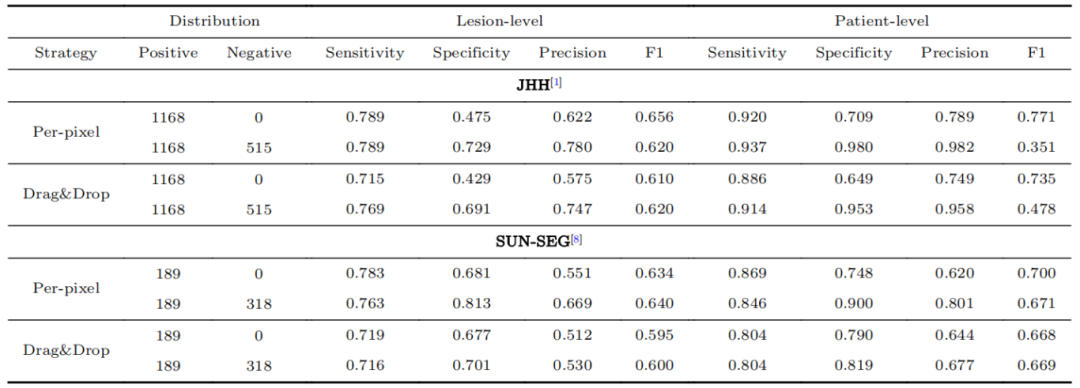
表3 正样本和负样本的训练数据分布。同时使用正负样本训练的方法通常能优于只使用正样本训练的方法。
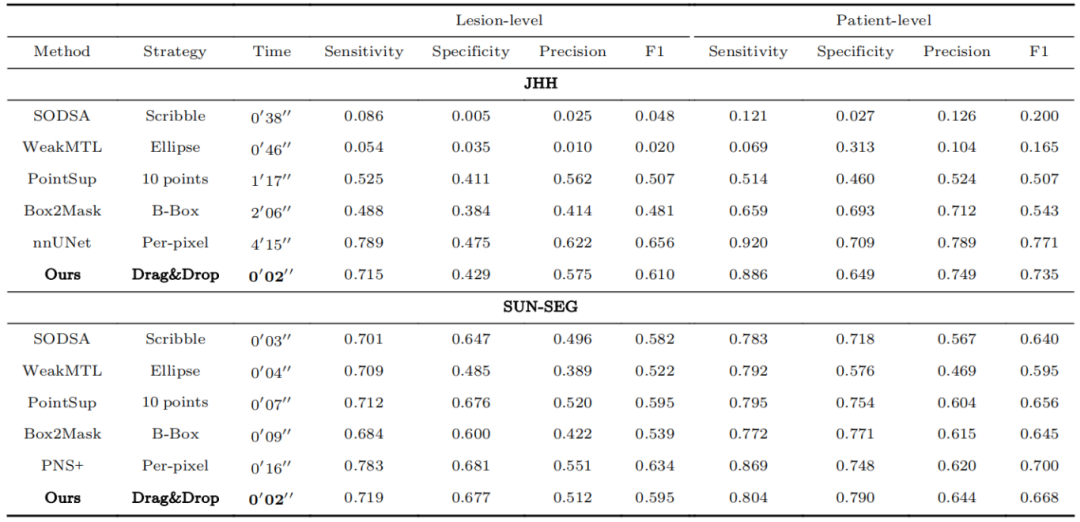
表4 本文列出了成本与准确度的权衡。需要注意的是,基线方法适用于低维标注策略,专门设计用于2D输入,导致在JHH数据集上的性能严重下降。相比之下,nnUNet对3D体积数据具有很强的适应性,因此取得了满意的结果。
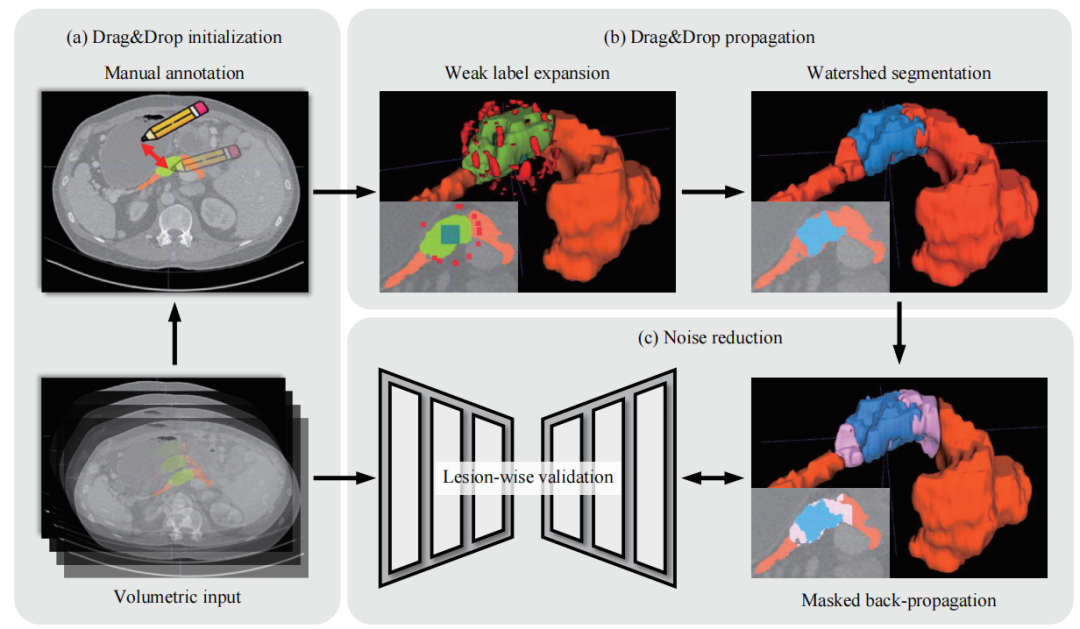
图1 本文提出的拖放标注和传播过程。胰腺和肿瘤分别用橙色和绿色表示。给定弱标签后,本文将其扩展为病变标记(青绿色)和背景标记(红色)。然后,本文利用基于标记的分水岭算法生成初始分割区域(蓝色),随后应用扩张的肿瘤(粉色)来计算掩码反向传播。
为了简化对时序和高维医学图像的标注,本文提出了一种名为拖放(Drag&Drop)的新标注策略和一个利用此类标签的弱监督框架。与逐像素标签相比,本文提出的策略在息肉和胰腺肿瘤检测任务中分别减少了87.5%和99.2%的标注工作量。实验结果表明,本文的框架实现了与逐像素标签相当的肿瘤检测率,而且比其他弱标注策略的检测率更高。更重要的是,本文表明,在固定的标注预算下,使用弱标签标注大量的数据比仅对小数据集进行逐像素标注能提高少数病例的模型泛化能力。本文希望此拖放(Drag&Drop)策略能简化和加快各种医疗模态中肿瘤检测和定位的标注过程。

全文下载:
Acquiring Weak Annotations for Tumor Localization in Temporal and Volumetric Data
Yu-Cheng Chou, Bowen Li, Deng-Ping Fan, Alan Yuille & Zongwei Zhou
https://link.springer.com/article/10.1007/s11633-023-1380-5
https://www.mi-research.net/en/article/doi/10.1007/s11633-023-1380-5
BibTex:
@Article {MIR-2023-07-135,
author={Yu-Cheng Chou, Bowen Li, Deng-Ping Fan, Alan Yuille, Zongwei Zhou },
journal={Machine Intelligence Research},
title={Acquiring Weak Annotations for Tumor Localization in Temporal and Volumetric Data},
year={2024},
volume={21},
issue={2},
pages={318-330},
doi={10.1007/s11633-023-1380-5}}
MIR为所有读者提供免费寄送纸刊服务,如您对本篇文章感兴趣,请点击下方链接填写收件地址,编辑部将尽快为您免费寄送纸版全文!
说明:如遇特殊原因无法寄达的,将推迟邮寄时间,咨询电话010-82544737
收件信息登记:
https://www.wjx.cn/vm/eIyIAAI.aspx#
关于Machine Intelligence Research
Machine Intelligence Research(简称MIR,原刊名International Journal of Automation and Computing)由中国科学院自动化研究所主办,于2022年正式出版。MIR立足国内、面向全球,着眼于服务国家战略需求,刊发机器智能领域最新原创研究性论文、综述、评论等,全面报道国际机器智能领域的基础理论和前沿创新研究成果,促进国际学术交流与学科发展,服务国家人工智能科技进步。期刊入选"中国科技期刊卓越行动计划",已被ESCI、EI、Scopus、中国科技核心期刊、CSCD等20余家国际数据库收录,入选图像图形领域期刊分级目录-T2级知名期刊。2022年首个CiteScore分值达8.4,在计算机科学、工程、数学三大领域的八个子方向排名均跻身Q1区,最佳排名挺进Top 4%。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢