
InstructPLM: 语言模型与逆向折叠的奇妙结合
InstructPLM
论文亮点
第一个用语言模型完成逆向折叠任务的蛋白序列设计算法 第一个算法在逆向折叠的同时,能够实现序列的插入删除(indels)设计 功能蛋白的从头设计,相对于ProGen原版成功率提高 相对于ProGen原版使用成本大大降低,ProGen的输入指令由适配器给出 在序列恢复率方面,在目前所有逆向折叠算法的SOTA 在序列同源性打分方面,InstructPLM在测试基线中同样表现为最优 同时InstructPLM也是对融入结构信息的语言模型,提出了一种解决方案
正文内容
Qwen-VL 如何帮助蛋白质设计?
我们从 Qwen-VL 学到的主要经验如下。在训练视觉-语言模型时,与其从头开始学习条件概率 P(text|image),不如先分别训练单模态基座模型来理解 P(text) 和 P(image),然后通过跨模态对齐技术将它们统一起来。
在蛋白质序列设计问题中,我们的目标是学习条件概率P(sequence∣structure)。我们发现可以做与 Qwen-VL 相同的事情:对齐一个预训练的蛋白质结构编码器和一个预训练的蛋白质序列解码器。
模型架构
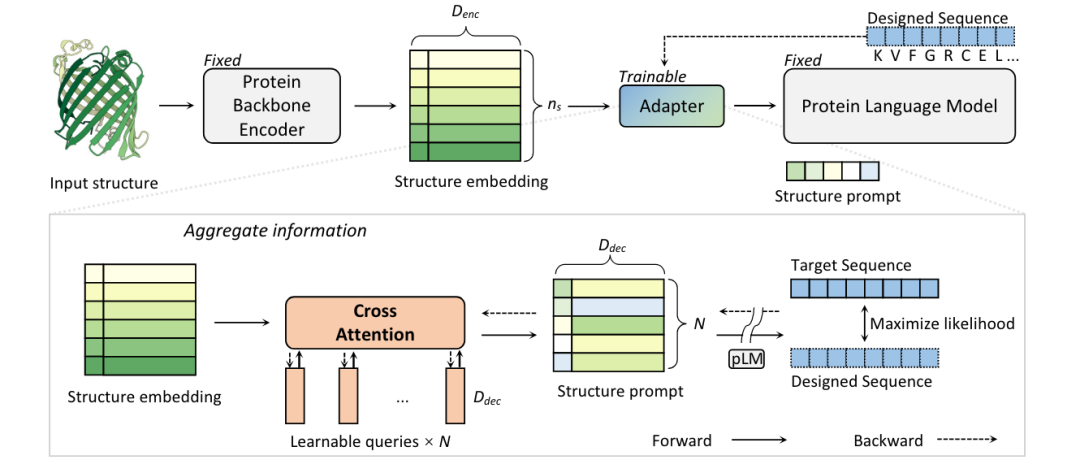
InstructPLM 的核心在于将生成式蛋白质语言模型与蛋白质的结构指令进行跨模态对齐。这一过程是通过跨模态对齐和指令微调技术实现的,这些技术都受到了 Qwen-VL 的启发。InstructPLM 能够生成一系列蛋白质序列,且鼓励每个序列都能够折叠成指定的结构,大大扩展了蛋白质工程的可能性。
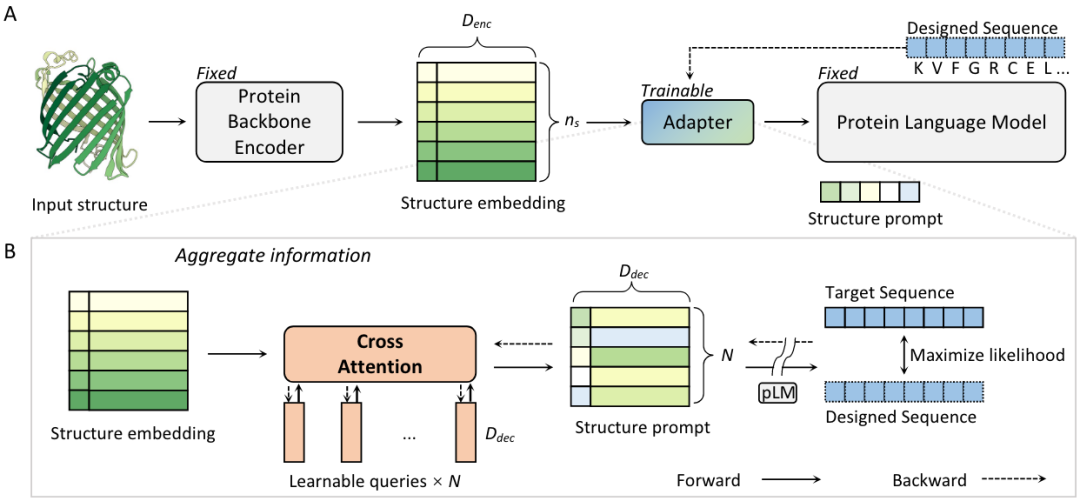
图1|InstructPLM的算法框架。(A)InstructPLM由蛋白骨架编码器、蛋白结构-序列适配器和蛋白序列解码器三部分构成。适配器是唯一可训练的部分,而结构编码器和序列解码器参数是固定的。(B) 结构-序列适配器的详细说明。该适配器采用结构嵌入作为输入,将结构信息与一组可学习的查询Quary结合起来。查询将作为结构提示指令,指导解码器的生成蛋白序列。
蛋白骨架编码器
蛋白语言模型解码器
InstructPLM采用ProGen2作为其蛋白语言模型。ProGen2模型是在Uniref90和BFD30数据库总计约2.3亿个蛋白序列进行预训练的,它是一个自回归语言模型 (AR),其模型参数范围从151M到6.4B。作者作了消融实验,发现随着模型参数量增加,序列困惑度随之下降的Scaling-law,于是选择最大6.4B参数的ProGen2模型。
蛋白结构-序列适配器
蛋白结构-序列适配器是 InstructPLM 的核心,不仅因为它负责将结构和序列的对齐,对齐到同一语义空间,还因为它包含 InstructPLM 的所有可训练参数。该适配器包含随机初始化的单层交叉注意模块(图1,橙色)。该模块使用了几个可训练的嵌入作为查询向量,蛋白骨架编码器的输出作为交叉注意力计算的键/值。该交叉注意力模块将蛋白质主干嵌入压缩为固定长度的结构指令(图1,structure prompt)。经过消融实验,作者将查询数量定为256(即结构指令长度)。此外,Qwen-VL还将一维绝对位置编码(图1,structure embedding的左边正方形)添加到交叉注意力模块中,以保证适配器在训练过程中保留蛋白一级结构信息。压缩的蛋白骨架特征序列随后作为软提示输入蛋白质语言模型(图1,右下方)。
模型表现
序列恢复率的表现
作者对InstructPLM进行了一系列的干实验评估,并与现有的最优模型如ProteinMPNN 和ESM-IF进行了比较。结果显示,InstructPLM 在困惑度上达到了 2.68,在序列恢复率上达到了 57.51%(图2),分别比ProteinMPNN高出 39.2% 和 25.1%。
生成可变长度的同源序列
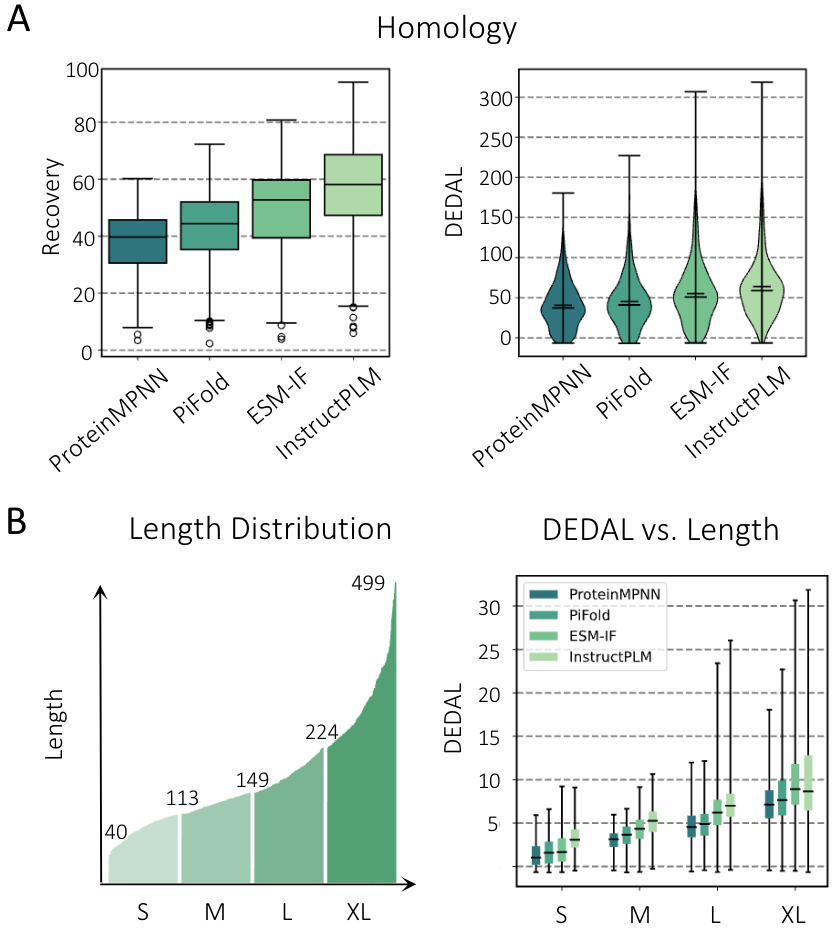
图2 |InstructPLM的干实验评估。(A) CATH4.2数据集测试序列恢复率(左),DEDAL同源性打分(右)。(B) 不同序列长度的DEDAL分数分布。
实验验证
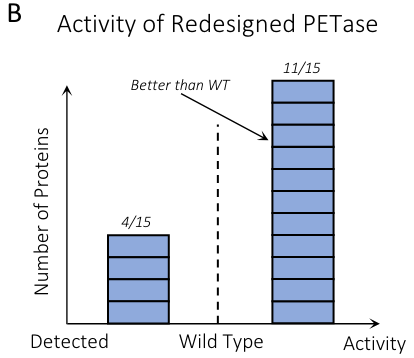
作者为了测试InstructPLM在具体蛋白设计场景的能力,选择了PDB代码为7SH6的塑料降解酶PETase,和仅有AF2预测结构的L-MDH蛋白进行实战。蛋白设计流程如图3A所示。
蛋白骨架结构作为输入,InstructPLM设计10,000个序列,T=0.8,p=0.9 ESMFold预测这10,000个序列的结构,使用DeepAlign计算TM-Score,评估结构相似性 最后排序选取top 15的序列进行实验。
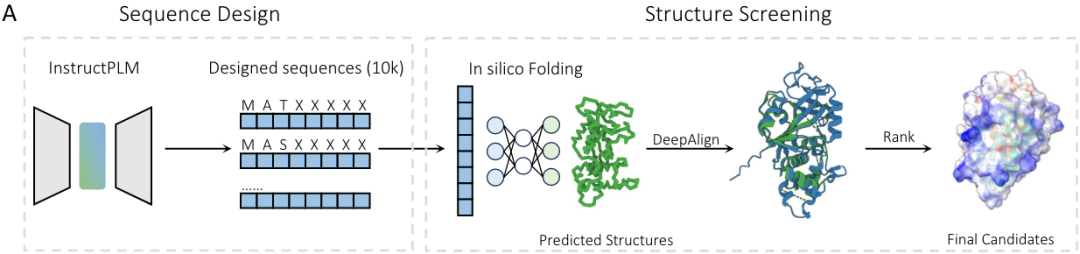
当在大肠杆菌中表达时,InstructPLM设计的所有15个序列均显示出良好的表达水平,且具有PET水解活性,其中11个序列优于野生型,如图3B所示。通过可视化分析,作者还发现InstructPLM设计的PETase,还具有催化三联体SER134-HIS212ASP180 和两个二硫桥(DS1和DS2),这些特征对PETase催化能力至关重要。
编者注:
InstructPLM这里的实验验证,并没有实现固定活性位点、保守区域,也不是简单的蛋白多位点突变,其实是更困难的功能蛋白的从头 (de novo) 设计,能有如此表现相当不俗。
现在蛋白设计的范式已经从蛋白结构的从头设计,转变为功能蛋白的从头设计。ProGen和InstructPLM等算法的表现,都在说明功能蛋白的从头设计不再是妄谈。
结语
展望未来,InstructPLM 的应用前景非常广阔。从设计用于特定药物递送的蛋白质到创造工业用酶,可能性只受限于我们的想象力。作者和 Qwen 团队一起,致力于不断拓展 InstructPLM 的潜力,我们对未来可能出现的突破充满期待。
代码文献
Qiu, Jiezhong, et al. "InstructPLM: Aligning Protein Language Models to Follow Protein Structure Instructions." bioRxiv (2024): 2024-04.
https://huggingface.co/InstructPLM/MPNN-ProGen2-xlarge-CATH42
https://github.com/Eikor/InstructPLM
往期文章
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢