
主动学习(AL)是一个迭代反馈过程,其能迭代性的从化学空间中识别有价值的数据,从而实现以较少的有标签数据高效的完成对空间的探索和开发。AL的这一特性正好与药物发现过程中所面临的探索空间不断扩大和有标签数据存在缺陷等问题互补,因此,AL已经被广泛的用于药物发现领域以推动药物发现的进程。最近,曹东升教授课题组和曾湘祥课题组在Drug Discovery Today上发表了一篇综述“The Present State and Challenges of Active Learning in Drug Discovery”,这篇综述首先介绍了AL工作流,然后对AL在药物发现领域中的应用进行了全面且系统的回顾,最后总结了AL在药物发现领域的研究现状和研究前景,具体见下文。

主动学习工作流的介绍
AL是一个迭代反馈的过程,其从一个小的初始训练数据集构建模型开始,然后,使用一定的查询策略迭代地从数据集中选择富含信息量的数据进行标注,这些新标注的数据被用于迭代性的更新模型,最后,在达到预定的目标后或者资源耗尽时,停止AL的过程。因此,AL通常主要由以下四个部分组成(如图1所示):
初始训练集:初始训练集作为AL的起始对AL的过程有重要的影响,大量的研究表明初始训练集选择的一个趋势:在前瞻性研究中,其通常是从各种数据库中直接提取或者处理过的历史数据;而在回顾性研究中,其通常是随机抽取的一个或者一组数据集。然而,无论初始数据集是如何选择的,AL都展现出了显著的优势。
ML算法:ML算法是AL工作流的重要组成部分,目前,各种ML算法均已成功的与AL相融合,包括传统的ML算法,深度学习算法以及一些更加精密的ML算法。这些ML算法的成功融合为专家在使用AL时有了更多的ML算法选择,同时也鼓励研究者将更加先进的ML算法与AL相融合,此外,需要注意的是,同一种ML算法在不同研究背景下表现出的性能是不同的,所以在解决特定问题时,研究人员必须仔细选择适合的ML算法。
查询策略:用于指导数据选择的查询策略是AL工作流的核心部分,其主要分为三类:开采性查询策略、探索性查询策略和平衡查询策略。开采性查询策略通常优先选择具有潜在理想特征的数据却不考虑他们对模型性能的影响;探索性查询策略则专注于选择可以为模型提供新见解的分子,即使它们不具有理想性质;平衡选择策略则致力于选择可以同时具有理想性质和提高模型性能的数据,以实现开采和探索之间的平衡,比如选择一半探索性数据和一半探索性数据。这些查询策略最后所能实现的目的不同,研究人员需要根据自己的研究目标去合理的选择查询策略以高效率的完成研究目标。
评估指标:
AL最后阶段是在合适的时间停止迭代,与这密切相关的是用于衡量AL效益的评估指标。
通常,这些评价指标可以分为两大类,一是基于分子的指标,其聚焦于选择的分子,比如选择到的活性分子数目或者活性分子的骨架数目;
二是基于模型的指标,其专注于模型的变化,比如模型性能的改变和特征重要性的变化。
然而,这两种指标都只能用于评估当前迭代的状态,而不能衡量进一步迭代可能获得的收益。
为了解决这一限制,研究人员也通过分析建模和统计方法去评估多一轮迭代的潜在效益以进一步确定是否需要进行下一次迭代。
研究人员可以根据这些指标确定何时停止AL工作流,使之与他们的研究目标相匹配。
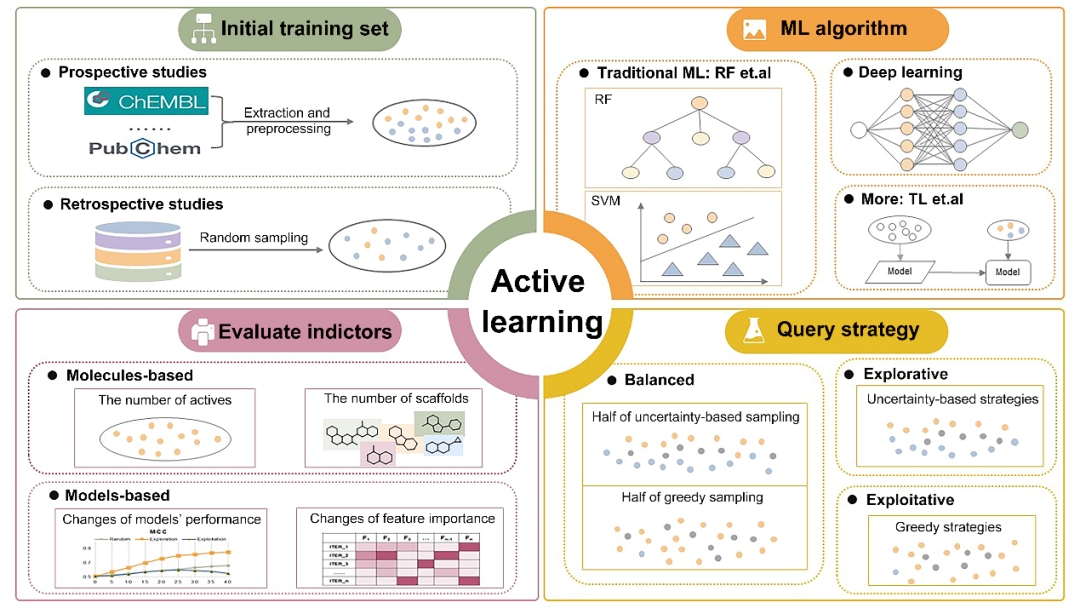
图一:AL工作流的概述图。
主动学习在药物发现中的应用
集成了各种的ML算法和查询策略的AL已经在药物发现的化合物-靶点相互作用(CTIs)预测、虚拟筛选(VS)、分子生成和优化以及分子性质预测这些关键阶段中被成功的用于解决各种问题(如图2所示)。下面这一部分将对AL在药物发现不同阶段的应用进行全面和系统的综述。
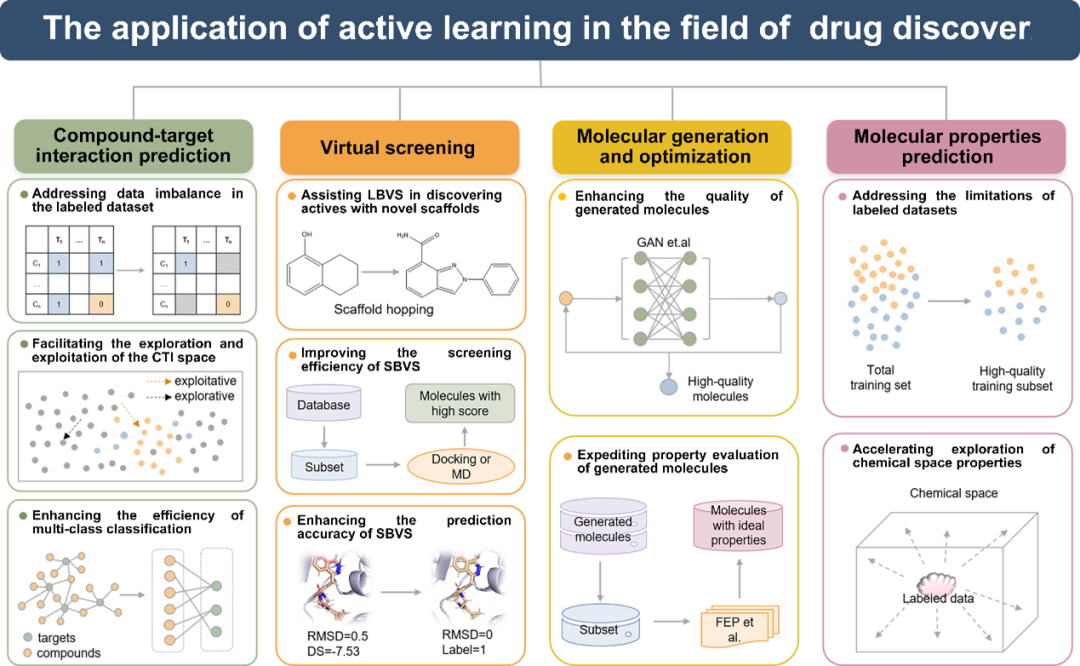
图2 AL在药物发现的各个阶段的主要应用。
分子-靶点相互作用预测
在CTI预测中存在有标签数据分布不平衡以及有标签数据缺乏不足以准确预测空间中所有的CTI等问题。此外,如何高效的解决与CTIs相关的复杂的多类别分类问题也是CTI研究需要解决的。使用不同分子查询策略的AL的融合可以有效的解决这些问题 (参见图3),目前这已经被大量的报道所证明。
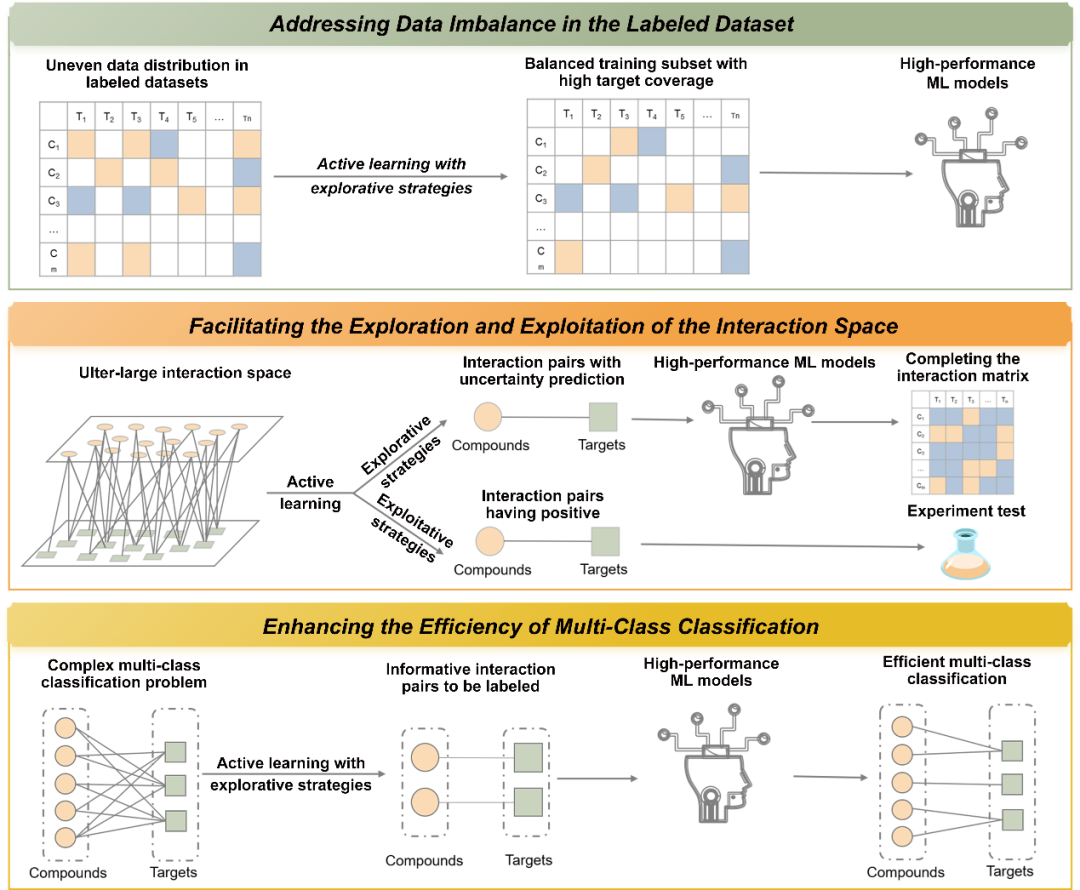
图3 通过引入AL来解决DTI预测中存在的一些棘手问题的示意图。
解决标记数据集中的数据不平衡问题:基于探索性选择策略的AL可以迭代性的从有标签数据集中选择富含信息量的数据加入训练集,从而构建相互作用对和非相互作用对比例平衡且靶点覆盖率高的训练集。Reker等人的研究证明了这点,他们使用基于不确定性的分子选择策略在每次迭代时选择了被模型预测不准确的相互作用对加入训练集,最终构建了一个相互作用对和非相互作用对比例平衡且靶点覆盖率较高的训练集。此外,Sharma等人的研究也表明通过AL迭代性的选择最接近预测边界的相互作用对加入训练集可以有效的解决数据不平衡问题。
加快CTI空间的探索和利用:基于探索性选择策略的AL可以快速的从相互作用空间中找到最富含信息量的相互作用对加入训练集,从而构建高质量的相互作用预测模型准确的预测相互作用空间中的CTIs,这已被很多研究所证明。比如,Naik等人通过迭代性的选择预测置信度低的相互作用对进行标注以扩充训练集和更新模型,最终实现了以较少的训练数据构建高质量的相互作用预测模型,从而准确的预测数据集中所有的CTI;Sun等人的研究也证明了通过基于探索性选择策略的AL可以快速的完成对相互作用空间的探索,实现以较少的样本构建高质量的相互作用模型,准确的预测空间中的CTIs。
基于开采性选择策略的AL 可以引导快速找到空间中具有相互作用的分子-靶点对,高效的完成对相互作用空间的开采,Kanga等人的研究就证明了这点,他们通过在每次迭代时使用贪婪选择策略选择被预测具有相互作用的分子-靶点对,最终快速的找到了空间中具有相互作用的分子-靶点对,从而高效的完成对相互作用空间的开采。此外,他们的研究也表明通过平衡性选择策略可以在快速找到具有相互作用的分子-靶点对的同时找到最富含信息量的相互作用对以快速的改进模型的性能,从而高效的完成对相互作用空间的开发和探索。
提高多类别分类的效率:基于探索性选择策略的AL可以迭代性的选择最有价值的数据快速的改进多类别分类模型性能,高效的解决与CTI相关的多类别分类问题,这已经被相关的研究所证明。比如Lang等人通过基于不确定性的选择策略在每次迭代时选择两个最高正概率之间差异最小的分子进行标注去扩充训练集,最后实现了以较少的样本构建高质量的模型准确的从多个靶点中找到每个分子结合的特定靶点;Rodríguez Pérez等人的研究通过基于熵的选择策略选择富含信息量的数据快速的构建高性能的模型,准确的将分子分到正确的结合位点上。
虚拟筛选
VS主要分为两种方法:基于配体的虚拟筛选(LBVS)和基于结构的虚拟筛选(SBVS)。LBVS方法是基于相似性的基本原理,所以很难发现骨架新颖的活性分子。SBVS 方法利用计算模拟来模拟配体与蛋白质的结合,可以有效识别骨架新颖的活性分子,但是其计算速度慢且会耗费大量计算资源。此外,最广泛应用的 SBVS 方法-分子对接,其也面临预测准确性低等问题。基于不同分子选择策略的AL可以有效的弥补这两种虚拟筛选方法的主要缺陷,如图 4 所示,这也被很多研究报道所证明。
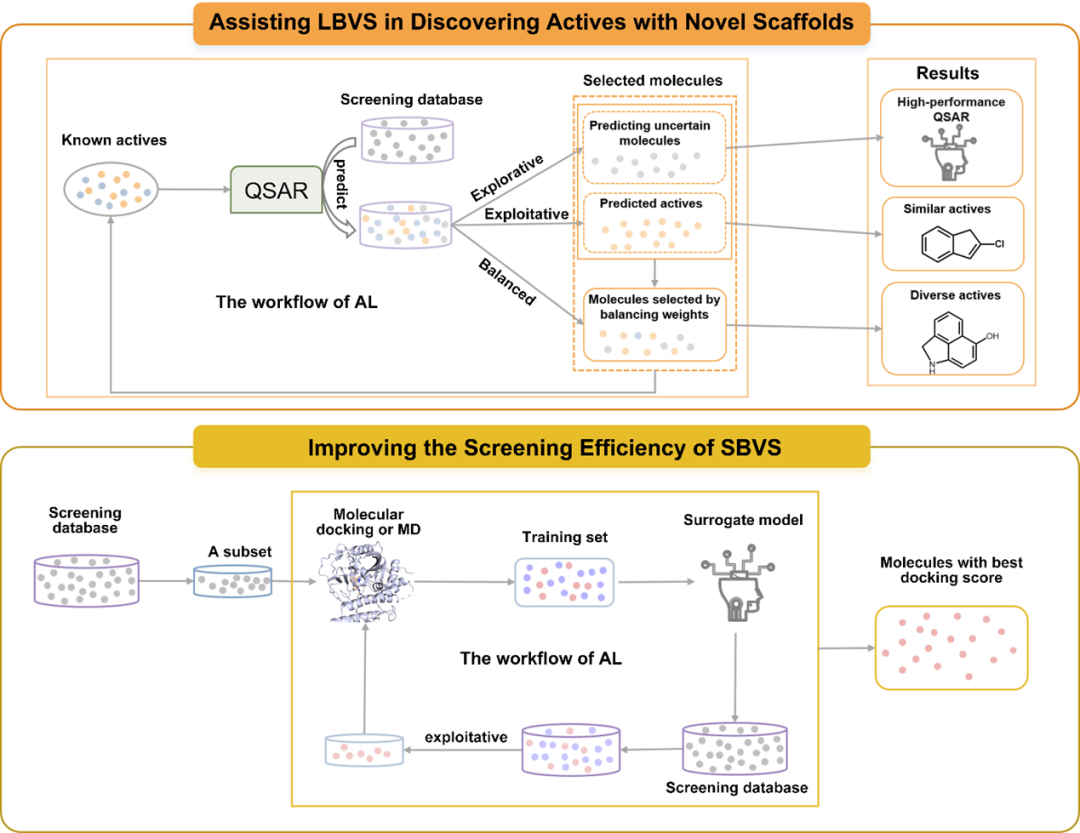
图4 AL缓解两种VS方法的主要缺点:帮助LBVS发现骨架新颖的活性分子和加速SBVS的示意图
辅助LBVS发现骨架新颖的活性分子:早期,Warmuth等人的研究表明通过基于开采性查询策略的AL可以引导快速的找到数据库中的活性分子;Czarnecki等人的研究则表明通过基于探索性选择策略的AL可以快速的找到富含信息量的分子快速的为模型添加新的信息。为此,Reker等人开始进一步的探索通过基于平衡性选择策略的AL是否可以找到骨架新颖的活性分子,他们通过迭代性的选择结构新颖且很可能具有活性的分子进行标注,最终引导找到了结构新颖的活性分子。这就表明通过平衡性选择策略的AL可以辅助LBVS方法找到骨架新颖的活性分子。
提高SBVS的筛选效率:基于开采性的AL可以迭代性的从数据集中选择最可能具有好的计算得分的分子进行SBVS计算,从而将SBVS计算聚焦于数据库中最有前景的那部分分子,避免了计算资源在得分差的分子上的浪费,这点已经被Graff 和Gusev等专家的研究所证明。在他们的研究中,他们通过迭代性的选择预测的计算得分好的分子进行SBVS计算,最终以较少的分子对接或分子动力学模拟计算快速的找到数据库中大多数对接得分好或结合自由能低的分子,即将计算资源成功的聚焦于数据库中最有前景的这部分分子。Schrodinger公司也据此开发了可以使这个过程自动化的程序:AL-Glide和AL-FEP+。
增强SBVS的预测准确性:
AL在改进SBVS的预测准确性上也发挥了重要的作用,Hsu等人的研究就表明通过基于探索性选择策略的AL可以迭代性的改进对接构象预测模型对新型蛋白质-配体结合构象的预测;
Wang等人的研究表明通过采用一种负向选择策略的AL可以改进基于机器学习打分函数的预测性能,降低筛选假阳性率;
César等人的研究表明通过基于开采性选择策略的AL可以引导FEP计算程序的参数选择,从而找到适合特定靶点FEP计算的参数设置,准确的进行FEP计算。
分子的生成和优化
分子的生成和优化过程主要包括两个关键步骤:一是使用生成模型生成可能具有所需属性的分子;二是使用实验或精确计算方法评估这些生成的分子,识别出真正具有理想特性的分子。AL已被证明可以通过增强生成分子的质量和加速对生成分子的性质评估来改进分子的生成和优化过程。
提高生成分子的质量:AL可以通过利用生成的分子迭代性的对生成模型进行反馈而改进模型的性能,提高生成分子的质量,这已经被一些报道证明了。比如Iovanac等人的报道表明通过AL迭代性的从生成的分子中选择具有理想性质的分子去迭代性的更新简单的生成模型,最终可以改进生成模型以生成更多的具有理想性质的分子;Bengio等人的研究也表明通过迭代性的利用生成的分子更新强化模型可以生成更多结构多样且对接得分好的分子。
加速对生成分子的性质评估:
正如在虚拟筛选部分中的AL提高SBVS的筛选效率所述,通过AL也可以加速对生成分子的性质评估,快速地从生成的分子中找到具有理想性质的分子,Konze等人的研究就证明了这一点,他们通过在每一次迭代时选择模型预测FEP+得分最好的分子进行FEP+计算,最后以较少的计算资源从生成的分子中快速的找到FEP+得分好的分子。
分子性质预测
在分子性质预测中,模型预测的准确性经常会受到有标签数据中存在的问题的影响,例如数据冗余。此外,现有的有标签数据有限,其构建的模型无法准确的预测日益扩大的空间中所有分子的性质。基于探索性查询策略的AL是解决这些挑战的一个解决方案,已有大量文献报导证明了它的有效性。
解决有标签数据集的局限性:基于探索性选择策略的AL可以从有标签数据集中迭代性的选择富含信息量的数据作为训练集,从而移除有标签数据集中存在的冗余数据,这点已经被Ding等人的研究所证明。在他们的研究中,他们通过基于不确定性选择策略的AL迭代性的从数据集中选择含信息量的数据构建模型,最终实现了以明显少的数据构建了与使用全部数据构建的模型性能相当或者更好的模型。
加速化学空间性质的探索:
基于探索性选择策略的AL可以迭代性地从化学空间中选择有代表性的数据向模型中添加新的信息,从而使之可以更加准确的预测空间中分子的性质,许多研究已经证明了这点。
比如Gubaev等人使用探索性查询策略选择与训练集数据差异较大的分子来扩充训练集,从而改进模型使之更加准确的预测空间中分子的性质;
Zhang等人也迭代性的选择预测不确定的分子去为模型添加新的信息使之更加准确的预测空间中分子的性质;
Hao等人也通过基于多样性的分子选择策略迭代性的选择分子扩充训练集使之更加准确的预测空间中的分子的性质。
现状和研究前景
整合更加先进的ML算法:目前很多先进的ML和自动化ML(Auto-ML)算法都已经成功的与AL相结合并在药物发现中得到了成功的应用,但是也有一些在其他领域成功融合的ML算法还没在药物发现领域得到成功的应用,例如多任务AL。此外,随着各种新的更加精进的算法的不断出现,如何将在其他领域成功融合的ML算法和新出现的更加精进的算法与AL相结合以促进药物发现的进程在未来仍需要进一步的探究。
开发或者迁移新型的分子选择策略:为了在改进模型性能的同时找到具有理想性质的分子,一系列致力于平衡开采和探索的平衡选择策略被开发出来了,但是如何精细的调节两者的比例以最大化收益仍是需要探索的;此外,在不同阶段采用不同的查询策略也可以实现改进模型性能和找到理想性质的活性分子的目的,但是在什么时候进行查询策略的转化可以最快的实现研究目标也是需要进一步研究的。此外,近年来,在其他领域也出现了一些新颖且成效显著的查询策略,将这些策略从其他领域直接迁移或者改编后迁移到药物发现领域以加速药物发现也是值得进一步研究的。
探索AL的新应用:
AL的常规应用是用于快速的改进模型的性能或者找到具有理想性质的分子,但是一些研究也展示了AL的新应用层面,比如使用AL迭代过程中的性能的提高程度或者生成分子多样性的变化去比较分子表征的信息含量或评估生成模型性能。
这就表明AL的用途也可以超出其传统作用方面,因此,进一步探索和开发AL在药物发现领域的新应用也是为了进一步需要研究的。
总结
AL引导的数据选择的优势与药物发现所面临的挑战刚好吻合,因此,AL在药物发现领域得到了广泛的应用。这篇综述通过对AL在药物发现的不同阶段的应用进行全面且系统的回顾,表明了结合不同ML算法和选择策略的AL可以有效的解决药物发现过程中所面临的各种挑战,从而加速药物发现的进程。它可以为后续药物研究人员进一步整合AL去加速药物发现进程提供一个有价值的见解和指导。
参考资料
Wang, Lei, Zhenran Zhou, Xixi Yang, Shaohua Shi, Xiangxiang Zeng, and Dongsheng Cao. "The present state and challenges of active learning in drug discovery." Drug Discovery Today (2024): 103985.
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢