

- ICRA 2024论文发布合辑-
科研成果速览

近期,清华大学交叉信息研究院人工智能方向的研究团队在国际知名的机器人与自动化学术盛会IEEE International Conference on Robotics and Automation (ICRA 2024)上,发表了一系列突破性的科研成果。陈建宇、高阳、吴翼、许华哲、弋力、赵行六位助理教授团队共发表8项创新科研进展,涵盖机器人运动控制、通用机器人操作、多模态对比学习,以及自动驾驶等多个前沿研究方向。另有6项工作将于ICRA workshop进行同步展示。
去中心化的复杂机器人控制算法—DEMOS
人形机器人的全身控制是一个具有挑战性的课题。陈建宇团队提出一种去中心化的复杂机器人控制算法DEMOS,在不牺牲任务性能的前提下,鼓励机器人在强化学习过程中自主发现可以解耦合的模块,同时保留必要合作模块之间的连接。该算法为机器人的设计和开发提供了新的视角,特别是在需要高度自主性和适应性的领域,如搜索和救援、探索和工业自动化。
01 Decentralized Motor Skill Learning for Complex Robotic Systems
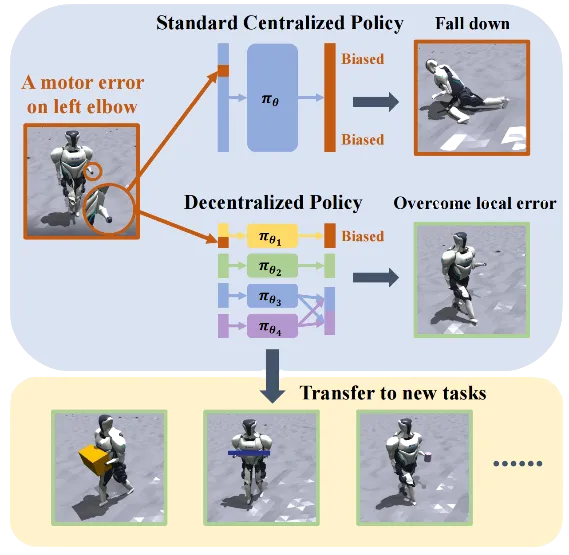
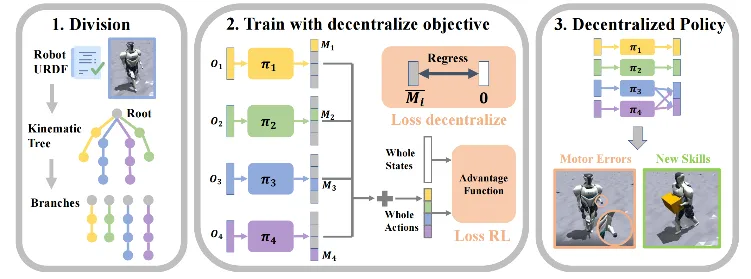
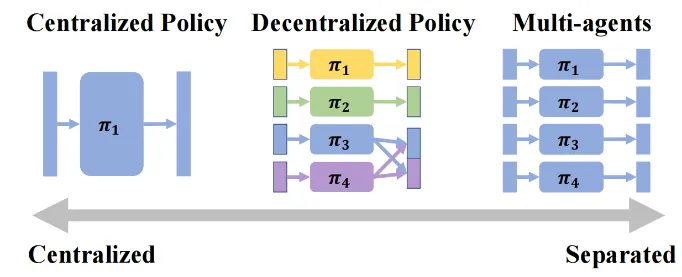
(上下滑动查看科研成果概要)
论文作者:
Yanjiang Guo, Zheyuan Jiang, Yen-Jen Wang, Jingyue Gao, Jianyu Chen
项目链接:
https://arxiv.org/pdf/2306.17411
机器人任务规划和执行领域系列进展 — VILA & CoPa
高阳团队在机器人任务规划和执行领域取得重要进展,在ICRA 2024 workshop 中将展示2项重要成果—CoPa和VILA算法框架。ViLa侧重于高层任务规划,CoPa侧重低层子任务执行,两个工作都基于视觉语言模型(VLM)GPT-4V。展示了在复杂和开放世界任务中,机器人能够如何利用先进的人工智能技术来提高其自主性和适应性。
01 ViLa: Look Before You Leap: Unveiling the Power of GPT-4V in Robotic Vision-Language Planning

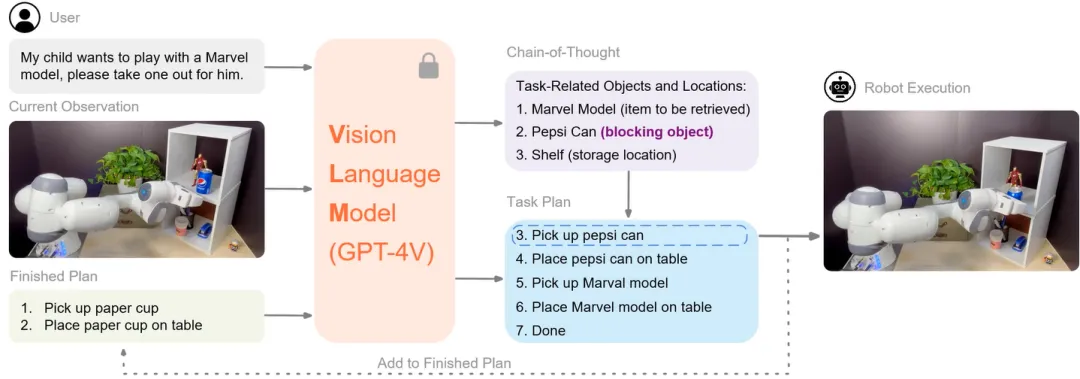
(上下滑动查看科研成果概要)
论文作者:
Yingdong Hu*, Fanqi Lin*, Tong Zhang, Li Yi, Yang Gao
项目链接:
https://robot-vila.github.io/
02 CoPa: General Robotic Manipulation through Spatial Constraints of Parts with Foundation Models

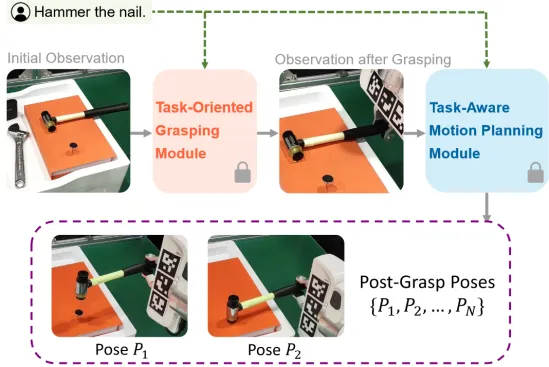

论文作者:
Haoxu Huang*, Fanqi Lin*, Yangdong Hu, Shenjie Wang, Yang Gao
项目链接:
https://copa-2024.github.io/
四足机器人双足运动控制
吴翼团队在四足机器人执行类人双足运动研究中取得重要进展,在ICRA 2024上发表2项成果。提出了一个分层框架,能够响应人类视频或自然语言指令,实现模仿拳击、芭蕾舞等动作,并与人类进行物理互动。提出了LAGOON系统,它使用预训练模型生成人类动作,然后通过强化学习在模拟环境中训练控制策略,以模仿生成的人类动作,并通过领域随机化将学习到的策略部署到真实世界的四足机器人上,实现了如“后空翻”、“踢球”等复杂行为。
01 Learning Agile Bipedal Motions on a Quadrupedal Robot



(上下滑动查看科研成果概要)
论文作者:
Yunfei Li, Jinhan Li, Wei Fu, Yi Wu
项目链接:
https://sites.google.com/view/bipedal-motions-quadruped/
02 Language-Guided Generation of Physically Realistic Robot Motion and Control
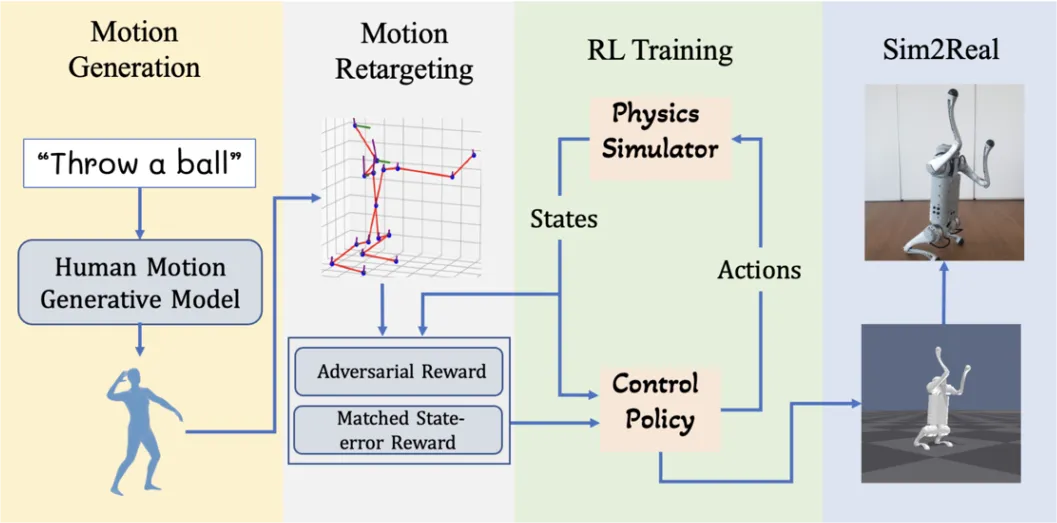


(上下滑动查看科研成果概要)
论文作者:
Shusheng Xu, Huaijie Wang, Jiaxuan Gao, Yutao Ouyang, Chao Yu, Yi Wu
项目链接:
https://sites.google.com/view/lagoon-text2control
用于可泛化操作的阵列式机器人&可穿戴机械手 —ArrayBot & HIRO Hand
许华哲团队在机器人学习与操作研究中取得重要进展,在ICRA 2024上发表2项成果。运用强化学习算法实现通用分布式操作的系统ArrayBot,通过触觉传感器进行操作学习,可用于真实世界的多种操作任务,展示了在模拟环境训练后无需领域随机化即可迁移至真实机器人的能力。提出了一种新型的手对手模仿学习可穿戴灵巧手HIRO Hand,它结合了专家数据收集和灵巧操作的实现,使操作者能够利用自己的触觉反馈来确定适当的力量、位置和动作,以执行更复杂的任务。
01 ArrayBot: Reinforcement Learning for Generalizable Distributed Manipulation through Touch
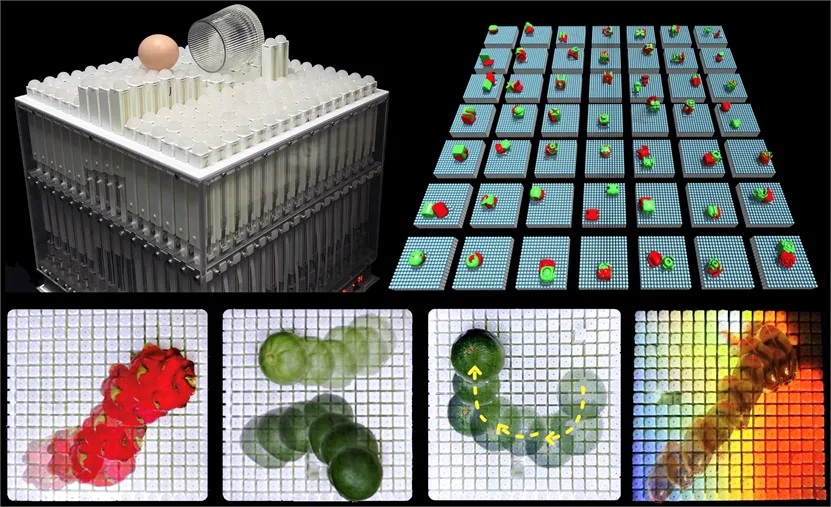
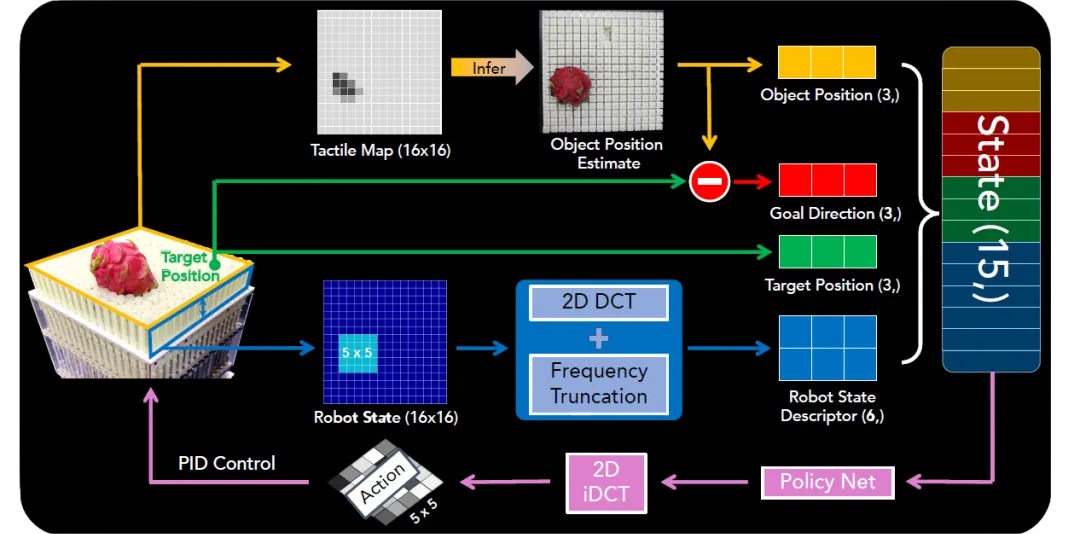
(上下滑动查看科研成果概要)
论文作者:
Zhengrong Xue*, Han Zhang*, Jingwen Cheng, Zhengmao He, Yuanchen Ju, Changyi Lin, Gu Zhang, Huazhe Xu
项目链接:
https://steven-xzr.github.io/ArrayBot/
02 A Wearable Robotic Hand for Hand-over-Hand Imitation Learning
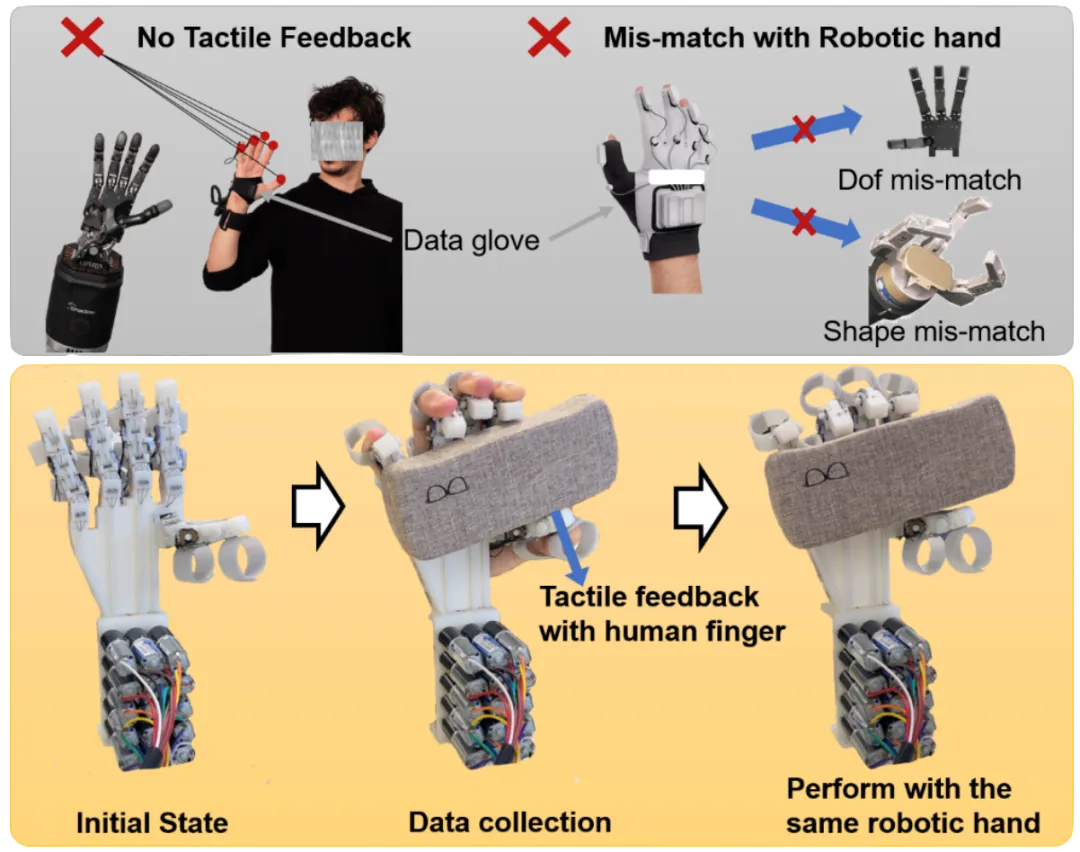
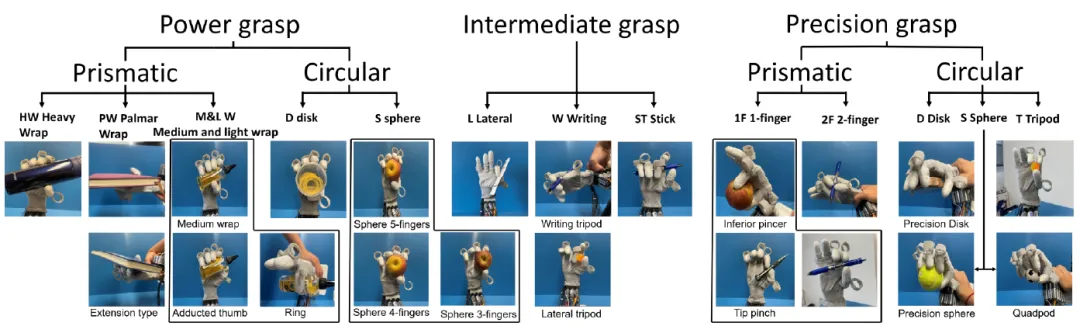
(上下滑动查看科研成果概要)
论文作者:
Dehao Wei, Huazhe Xu
项目链接:
https://sites.google.com/view/hiro-hand
自监督学习&多模态数据融合 —CrossVideo & TEG-Track
弋力团队在机器人视觉与触觉感知领域研究中取得重要进展,通过自监督学习和多模态数据融合来提升机器人对环境的理解和交互能力,在ICRA 2024上发表2项成果。提出了一种自监督的跨模态对比学习方法CrossVideo,通过模态内和跨模态的对比学习技术,提高点云视频理解的性能。团队提出了一种触觉增强的6D姿态跟踪系统TEG-Track,用于跟踪手中持有的未见过的物体。该方法在合成和真实世界场景中均能一致性地提升最先进的通用6D姿态跟踪器的性能。相关成果可运用推广到机器人导航、增强现实、自动化驾驶等领域。
01 CrossVideo: Self-supervised Cross-modal Contrastive Learning for Point Cloud Video Understanding
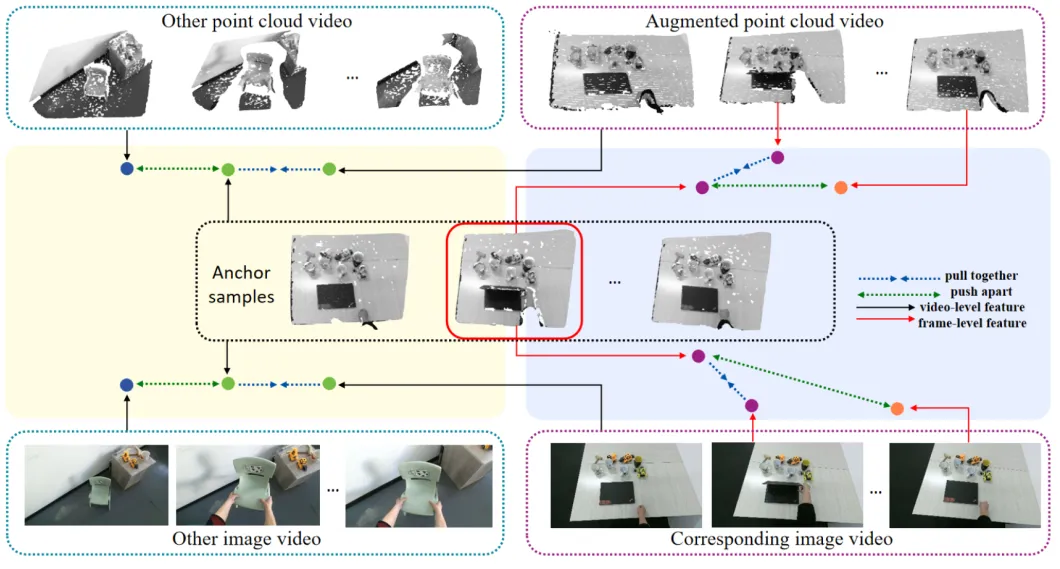
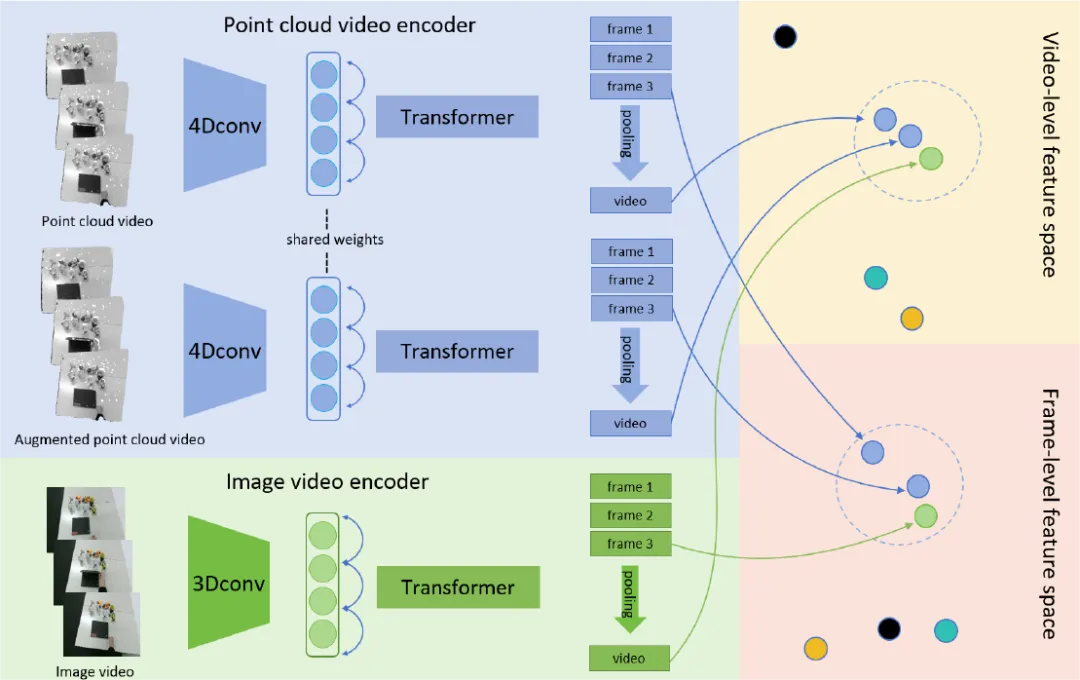
(上下滑动查看科研成果概要)
论文作者:
Yunze Liu, Changxi Chen, Zifan Wang, Li Yi
项目链接:
https://arxiv.org/abs/2401.09057
02 TEG-Track: Self-supervised Cross-modal Contrastive Learning for Point Cloud Video Understanding
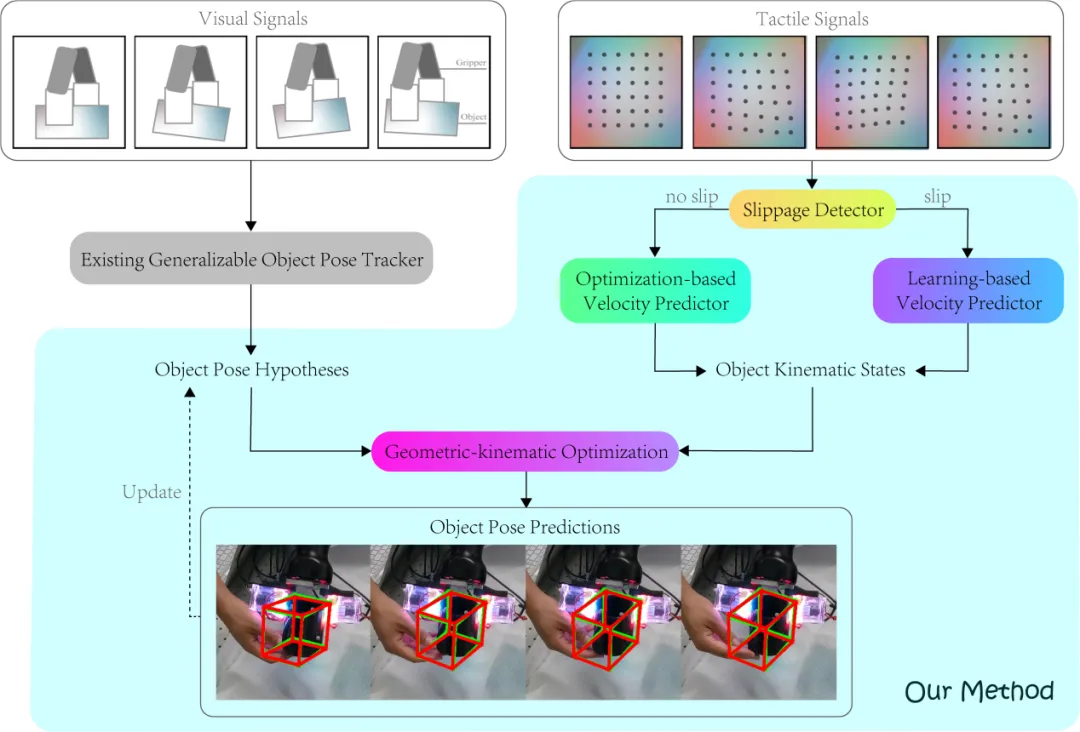
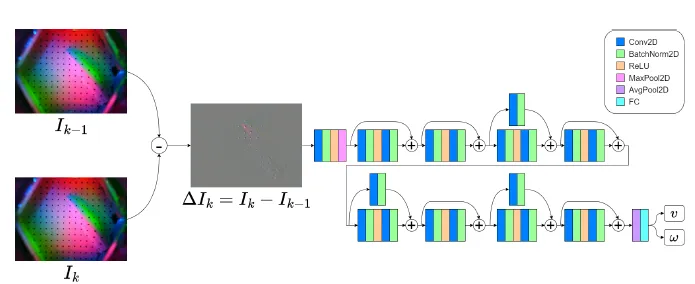

(上下滑动查看科研成果概要)
论文作者:
Yun Liu*, Xiaomeng Xu*, Weihang Chen, Haocheng Yuan, He Wang, Jing Xu, Rui Chen, Li Yi
数据集和代码:
https://github.com/leolyliu/TEG-Track
项目链接:
https://ieeexplore.ieee.org/abstract/document/10333330
促进自动驾驶的离线强化学习—HsO-VP
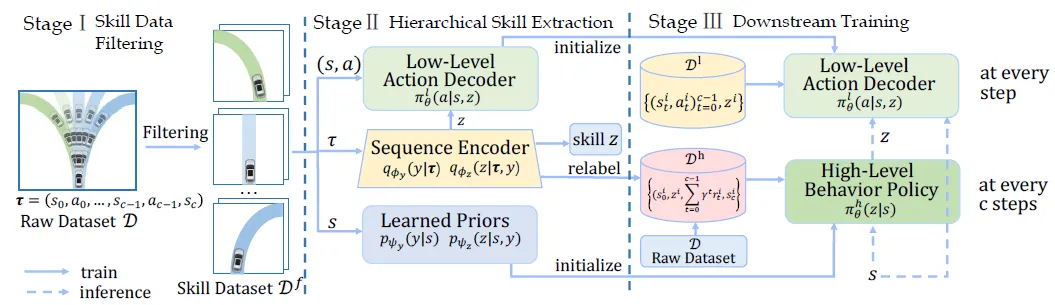
赵行团队在离线强化学习能够超越专家性能、无需危险环境交互的特性,提出了HsO-VP框架,实现了纯粹基于离线数据的长程运动规划。框架通过变分自编码器(VAE)从离线演示中学习技能,解决自动驾驶中的长期规划问题。设计了双分支序列编码器,有效应对后验坍塌问题。为自动驾驶车辆规划提供了一种新的强化学习方法。
Learning Agile Bipedal Motions on a Quadrupedal Robot
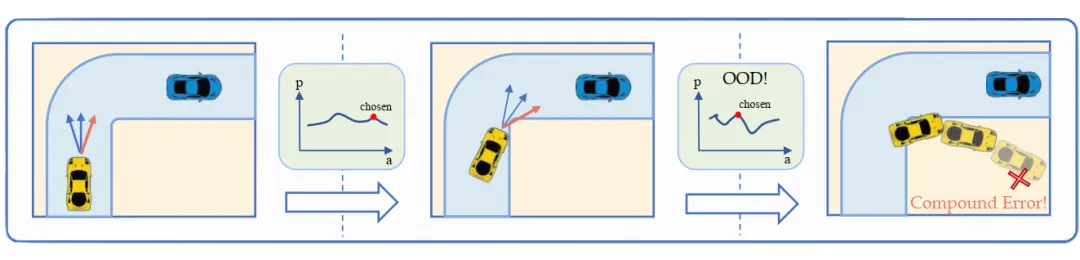
Traditional Offline RL Planner
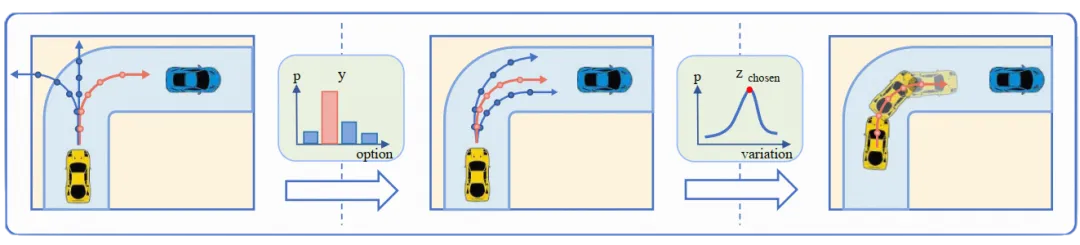
Hierarchical Skill-Based Planner
(上下滑动查看科研成果概要)
论文作者:
Zenan Li*, Fan Nie*, Qiao Sun, Fang Da, Hang Zhao
项目链接:
https://arxiv.org/abs/2309.13614
编辑 | 姜月亮
审核 | 吕厦敏

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢