
图表示学习旨在将图中节点映射到低维向量,同时保留图结构和实体关系。
背景
在文本数据中,单词在一个句子中连接在一起,并且它们在该句子中具有固定的位置。
在图像数据中,像素排列在有序的网格空间上,可以用网格矩阵表示。
但是,图中的节点和边是无序的,并且具有特征。这导致在保留图结构的同时,将图实体映射到潜空间并且保留邻近关系具有挑战性。
图表示学习模型分类
图表示学习主要分为五大类:图核模型 (graph kernels)、矩阵分解模型 (matrix factorization models)、浅层模型 (shallow models)、深度神经网络模型 (deep neural network models) 和非欧几里得模型 (non-Euclidean models)。
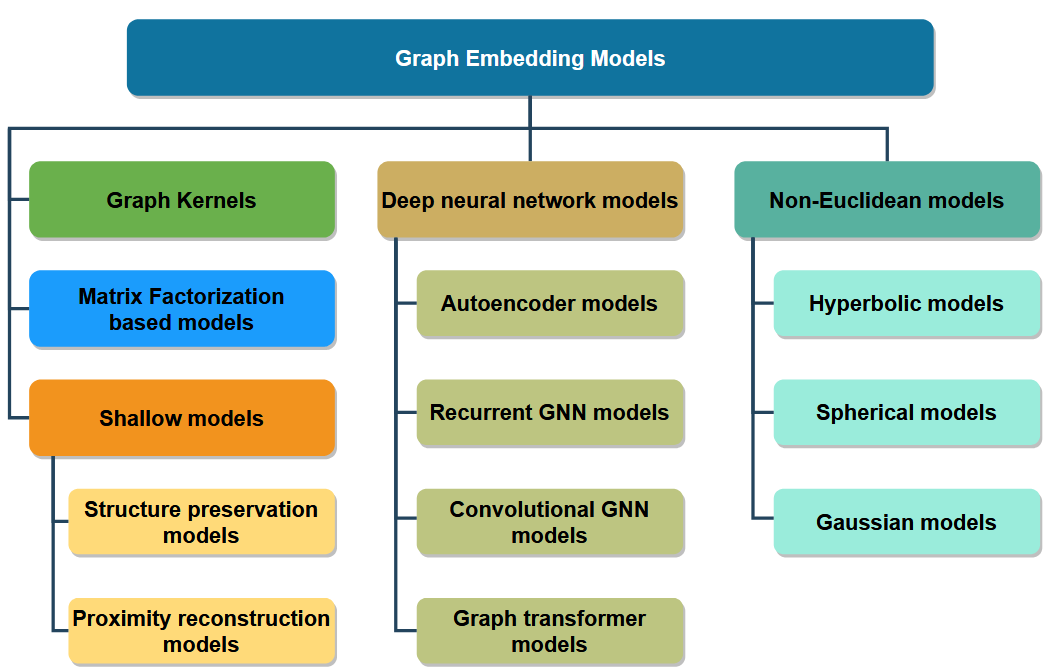
(1) 图核模型 (graph kernels)
图核模型是利用核函数,度量图与其实体之间的相似性, 图核的主要思想是将原始图分解为子结构,并基于子结构特征构造向量嵌入。
图核模型主要有两种类型:kernels for graphs 和 kernels on graphs。
- kernels for graphs:旨在测量图之间的相似性。
- kernels on graphs:旨在测量图节点之间的相似性。
局限性:图核模型处理大规模图时的计算复杂性较高,因为计算图核是一个 NP 难问题。
(2) 矩阵分解模型 (matrix factorization models)
矩阵分解模型的目标是将邻近矩阵分解为小规模矩阵的乘积,然后拟合其邻近性以学习节点嵌入。
矩阵分解模型主要有两种类型:拉普拉斯特征分解 (Laplacian eigenmaps) 和 节点邻近矩阵分解 (Node proximity matrix factorization)。
- Laplacian eigenmaps:旨在用拉普拉斯特征向量以及前k个特征值来表示每个节点。
- Node proximity matrix factorization:旨在通过奇异值分解获得节点嵌入。
局限性:矩阵分解模型由于计算复杂性而无法捕获高阶接近性。
(3) 浅层模型 (shallow models)
浅层模型是一种嵌入模型,旨在通过最大化目标节点的邻域概率学习节点嵌入,从而将图实体映射到低维向量空间。该模型通常使用采样技术来捕获图结构和邻近关系,然后基于浅层神经网络算法学习节点嵌入。
浅层模型根据学习嵌入的策略,可分为两类:结构保存模型和邻近性重建模型。
- 结构保存模型:旨在保留实体之间的结构连接,主要是定义一种采样策略可以在确定步长采样中捕获图的全局结构和局部结构信息(DeepWalk, Node2Vec )。
- 邻近性重建模型:旨在保持图中节点之间的邻近性 (LINE)
局限性:
- 浅模型专注于传导式学习,忽略了节点特征和标签。
- 不能学习新增节点的嵌入。
- 不能共享模型参数。
(4) 深度神经网络模型 (deep neural network models)
图神经网络 (GNN) 以归纳式学习节点嵌入。
Recurrent GNNs:旨在通过每个隐藏层中具有相同权重的递归层来学习节点嵌入,并递归运行直到收敛。不足:RGNN 模型的每个隐藏层使用相同的权重可能会导致模型无法区分局部结构和全局结构。
Graph autoencoder: 通过重构输入图结构来学习复杂的图结构, 图自动编码器由两个主要层组成:编码器层将邻接矩阵作为输入并压缩以生成节点嵌入,解码器层重建输入数据。
GCNs: 是在每个隐藏层中使用具有不同权重的卷积算子,捕获和区分局部结构和全局结构。
- spectral GCNs: 旨在将图数据转换到频域,并在频域学习节点嵌入。
- spatial GCNs: 通过直接在图上堆叠多个GNN层,模型可以有效地学习节点嵌入并捕获高阶结构信息。
GAT: 通过注意力机制在消息聚合的过程中为每个邻居节点分配不同的权重。
优点:
- 参数共享。
- 可以泛化看不见的节点。
局限性:大多数 GNN 在堆叠更多 GNN 层时,会遇到过度平滑的问题和来自相邻节点的噪声的问题。
Graph transformer models:将 transformer 架构应用于图域中。
Graph transformer models主要有三种类型:用于树状图的transformer (transformer for tree-like graphs),带GNN的 transformer (transformer with GNNs),和全局自注意力的transformer (transformer with global self-attention)。
- transformer for tree-like graphs:主要目的是学习节点分层排列的树状图中的节点嵌入,通过节点的相对位置和绝对位置对节点位置进行编码。
- transformer with GNNs:一些模型利用GNN作为计算注意力分数的辅助模块。一些模型将GNN层放在模型最上,以克服过度平滑问题,使模型关注局部结构特征。
- transformer with global self-attention:使用全局自注意力机制来学习节点嵌入,它独立实施自注意力机制,不需要来自邻居的约束,能直接在输入图上工作,并且可以通过全局自注意力捕获全局结构。
Graph transformer 的优点:
- 可以捕获长距离的依赖。
- 可以减轻出现的过度平滑和过度挤压的问题。
- 有更大的感受野。
(5) 非欧几里得模型 (non-Euclidean models)
由于现实世界中的图可能具有复杂的结构和不同的形式,因此欧几里得空间可能不足以表示图结构,并最终导致结构损失。
非欧几里得模型主要有三种:球面型 (spherical)、双曲型 (hyperbolic) 和高斯型(Gaussian)
- 球面型 (spherical):表示具有大型环状的图结构。
- 双曲型 (hyperbolic):适用于分层图结构。
- 高斯型(Gaussian):以处理空间信息未知和不确定性,将嵌入作为潜在空间的概率分布来学习。
参考资料
Hoang V T, Jeon H J, You E S, et al. Graph representation learning and its applications: a survey[J]. Sensors, 2023, 23(8): 4168.
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢