


由于神经网络在人工智能领域占据主导地位,一个试图了解其内部工作原理的研究分支领域应运而生。这个子领域的一个标准方法是将神经网络主要理解为代表人类可理解的特征。另一种探索较少的可能性是将它们理解为多步骤的计算机程序。这样做的一个先决条件似乎是某种形式的模块化:网络的不同部分独立运行,足以被孤立地理解,并实现不同的可解释子例程。
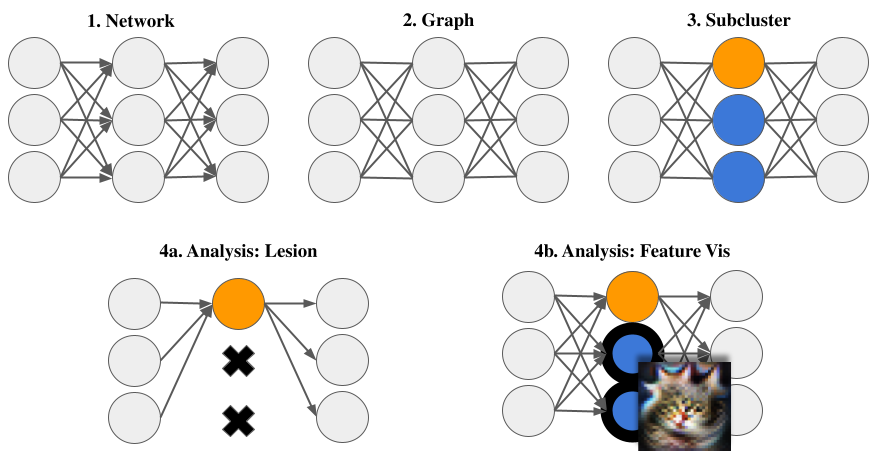
为了找到神经网络内部的模块化结构,我们首先使用图聚类工具。从这个意义上说,一个网络是可聚类的,如果它可以被分成内部连通性强但外部连通性弱的神经元组。我们发现,经过训练的神经网络通常比随机初始化的网络具有更强的可聚类性,并且通常相对于与训练网络具有相同权值分布的随机网络具有可聚类性。我们研究了促进集群性的因素,并针对这一目标开发了新的方法。
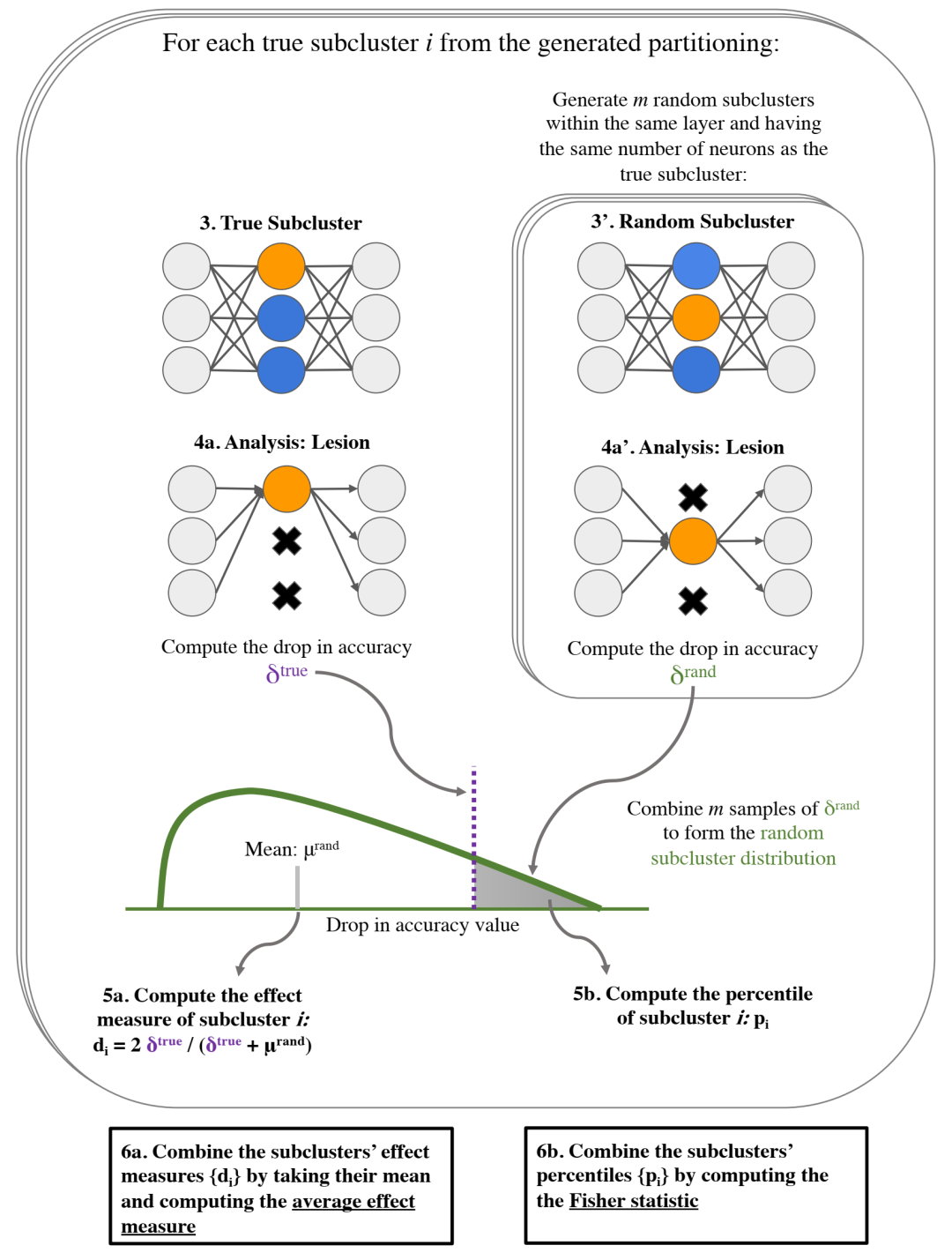
为了使模块化对理解神经网络有价值,它需要具有某种功能相关性。我们针对的功能关联类型是功能的局部专门化。神经网络是局部专门化的,其计算图的部分可以抽象地表示为执行与整体任务相关的一些可理解的子任务。我们提出了局部专门化的两个代理:重要性,它反映了神经元集对网络性能的价值;以及一致性,这反映了他们的神经元与输入特征的一致性。然后,我们使用通常用于解释单个神经元的技术来操作这些代理,将它们应用于由图聚类算法产生的神经元组。我们的研究结果表明,聚类能够成功地发现重要且连贯的神经元组,尽管并非所有发现的神经元组都是如此。
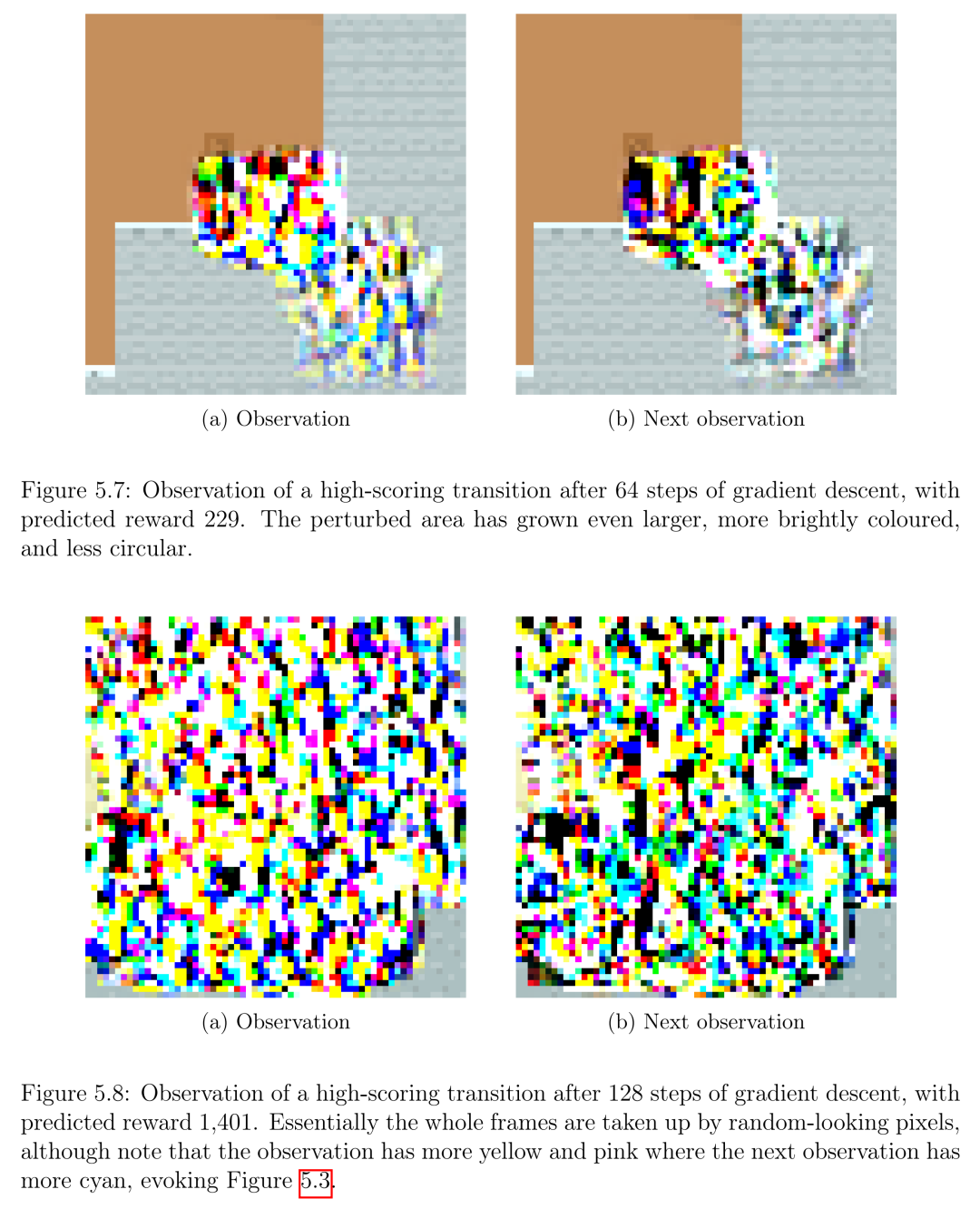
最后,我们使用了一个使用更标准的可解释性工具的案例研究,旨在理解激活空间中方向所代表的特征,并将其应用于分析基于游戏CoinRun的奖励函数训练的神经网络。尽管我们的网络实现了较低的测试损失,但可解释性工具的应用表明,网络不能充分表示相关特征,并且严重错误地预测了分布之外的奖励。也就是说,这些工具并不能清楚地显示网络实际执行的计算。这不仅说明了需要更好的可解释性工具来理解泛化行为,而且还激励了它:如果我们把这些网络作为通过强化学习训练的策略的“动机系统”模型,结论是,当部署在更丰富的环境中时,这些网络可能会有能力追求错误的目标,这表明需要可解释性技术来阐明泛化行为。

论文题目:Structure and Representation in Neural Networks
作者:Daniel Filan
类型:2024年博士论文
学校:University of California, Berkeley(美国加州大学伯克利分校)
下载链接:
链接: https://pan.baidu.com/s/1KglyRT5s70UE-obnqc0piw?pwd=pee7
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5



微信群 公众号


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢