
当然,狂欢之余,我们还是回到技术本身,谈谈2个问题。
一个是目前RAG都有哪些综述,四大综述?一个是关于行业大模型的一些有趣总结,关于一个技术报告,会是在产研上的一个总结性结论。
供大家一起参考。
问题1:目前RAG都有哪些综述,四大综述?
实际上,RAG当前的一些总结新性的论文越来越多,在同质化的同时,也有一些差一点。一路看过来,昨天已经达到了4个,几乎每个月一个,下面从时间先后顺序进行处理,大家可以看看。
1、2023年12月综述
《Retrieval-Augmented Generation for Large Language Models: A Survey》
这篇综合性综述论文对RAG范式的发展进行了详细的研究,包括Naive RAG、Advanced RAG和Modular RAG,仔细研究了RAG框架的三个基础概念,包括检索、生成和增强技术。该论文重点介绍了这些关键组件中蕴含的sota方案,以及最新的评估框架和基准。
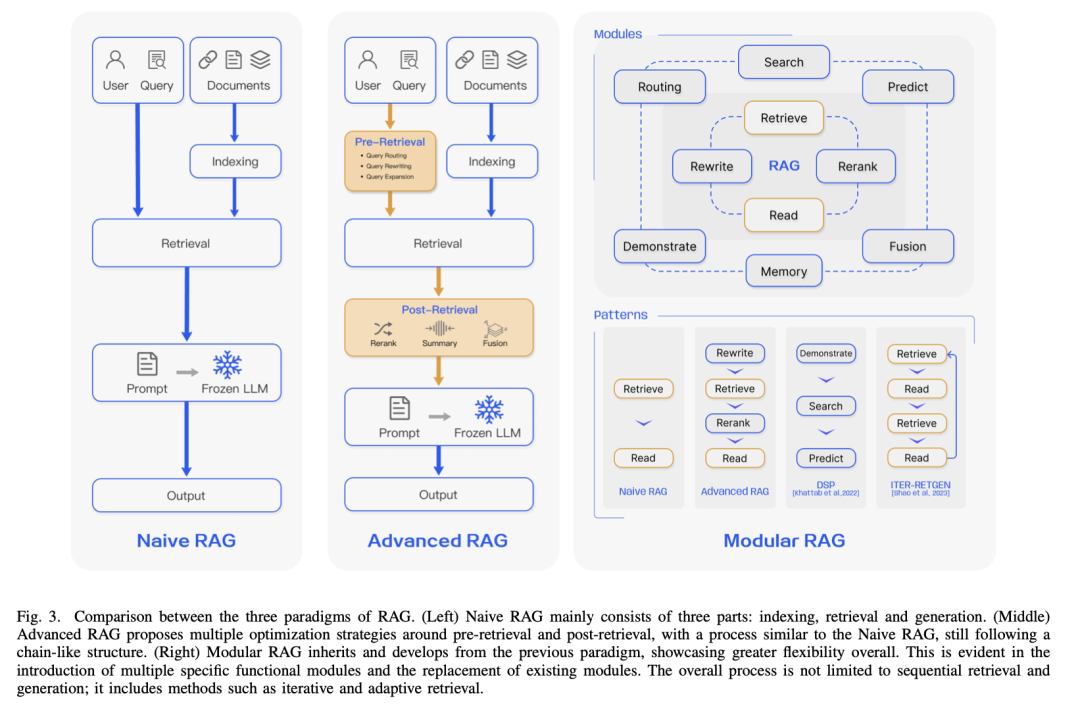
最后,该工作阐述了当前面临的挑战,并指出了未来的研究和发展方向。
地址:https://arxiv.org/abs/2312.10997
2、2024年2月综述
《Retrieval-Augmented Generation for AI-Generated Content: A Survey》
该工作全面回顾了将RAG技术整合到AIGC场景中的现有工作。首先根据检索器如何增强生成器对RAG基础进行分类,提炼出各种检索器和生成器增强方法的基本原理。
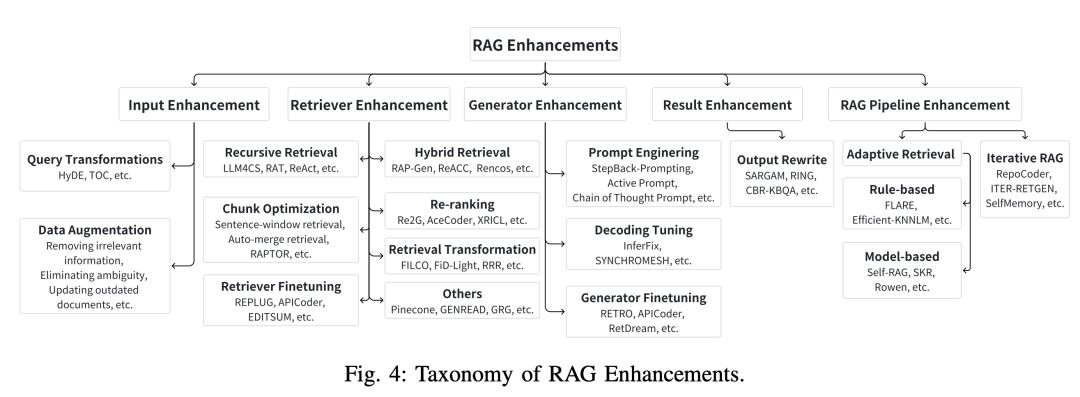
此外,总结了RAG的其他增强方法,以促进RAG系统的有效工程设计和实施。最后,还介绍了RAG的基准,讨论了当前RAG系统的局限性,并提出了未来研究的潜在方向。
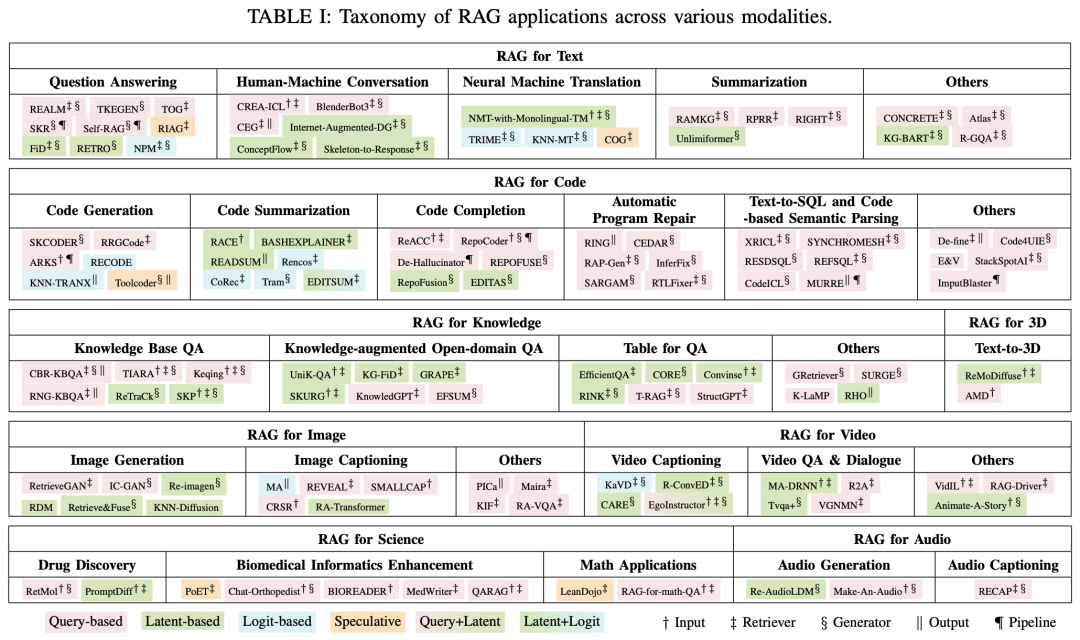
地址:https://arxiv.org/abs/2402.19473,https://github.com/hymie122/RAG-Survey
3、2024年4月综述
《A Survey on Retrieval-Augmented Text Generation for Large Language Models》
随着RAG的复杂性不断增加,并纳入了可能影响其性能的多个概念,该工作将RAG范式分为四个类别:检索前、检索、检索后和生成,从检索的角度提供了详细的视角。
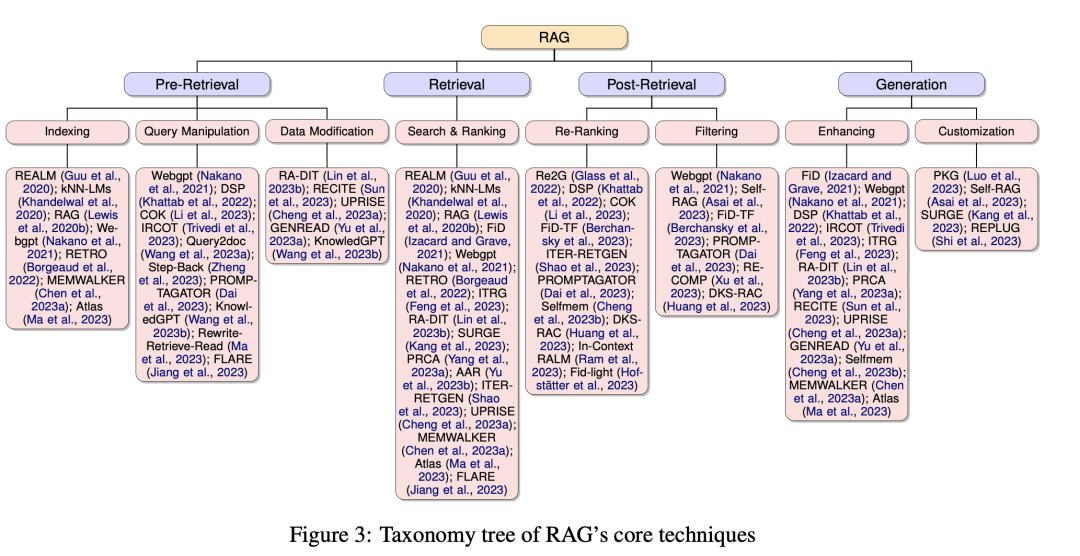
该工作首先概述了RAG的演变过程,并通过对重要研究的分析讨论了该领域的进展。此外,还介绍了RAG的评估方法,解决了面临的挑战,并提出了未来的研究方向。通过提供一个有条理的框架和分类,本研究旨在整合现有的RAG研究,澄清其技术基础,并强调其扩大LLM适应性和应用的潜力。
地址:https://arxiv.org/pdf/2404.10981
4、2024年5月份综述
《A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models》
该工作全面回顾了检索增强大型语言模型(RA-LLMs)方面的现有研究,涵盖了三个主要技术视角:架构、训练策略和应用。先简要介绍了LLM的基础和最新进展。然后,为了说明RAG对LLMs的实际意义,按应用领域对主流相关工作进行了分类,具体详述了每个领域所面临的挑战以及RA-LLMs(Retrieval-Augmented Large Language Models)的相应能力。
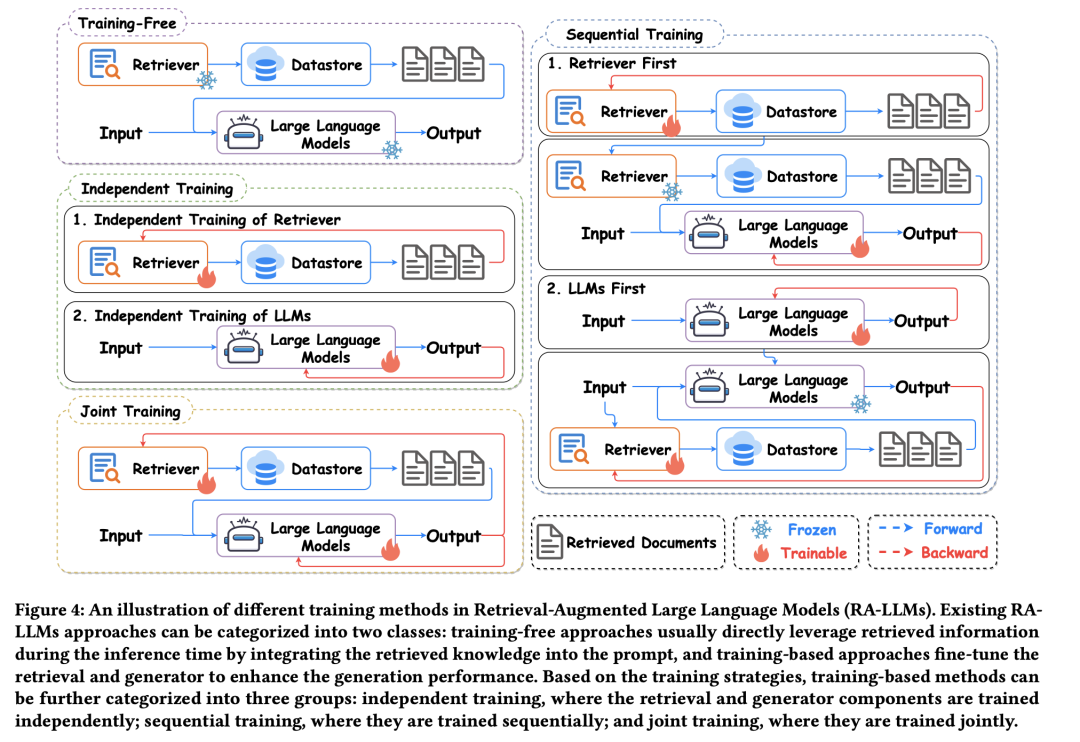
最后,为了提供更深入的见解,讨论了当前的局限性和未来研究的几个有前途的方向。
地址:https://arxiv.org/pdf/2405.06211
问题2:关于行业大模型的一些有趣总结
昨天看到腾讯研究院发布的《腾讯发布业界首份行业大模型调研报告:向 AI 而行,共筑新质生产力》(https://mp.weixin.qq.com/s/dxtKDqch3wMlW781exb51w),读下来,很有收获,推荐大家看看原文,其中有些重点可以看看。
行业大模型的构建和应用中,由于需求和目标不同,技术实现复杂性差异也较大。通过调研总结,目前机构在使用大模型适配行业应用过程中,从易到难主要有提示工程、检索增强生成、精调、预训练四类方式。
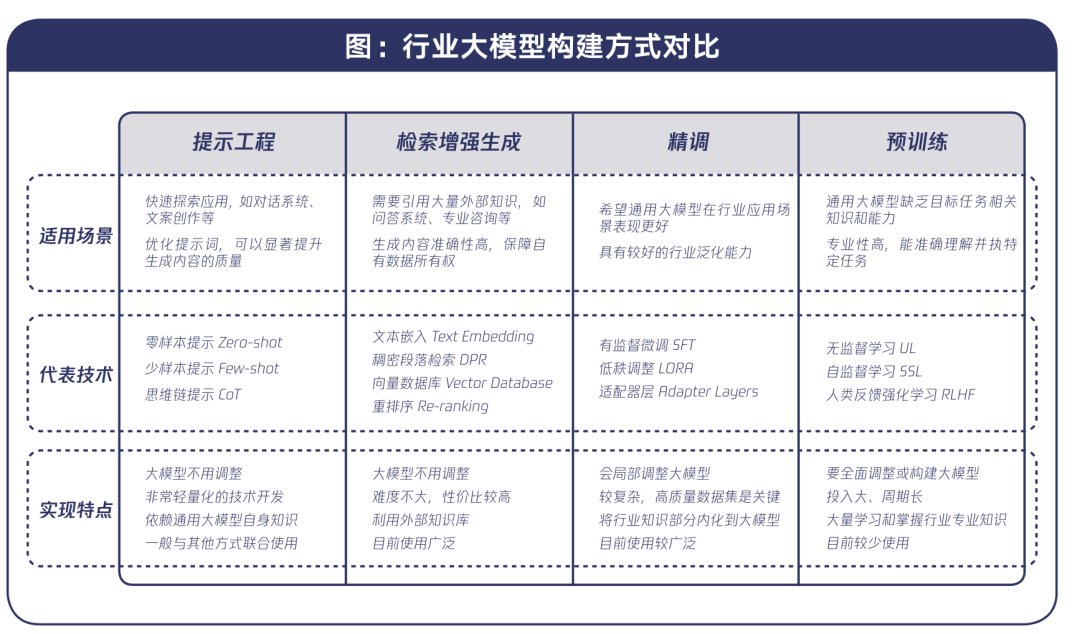
在机构的具体实践中,通常不会只用一种方式,而会组合使用,以实现最佳效果。例如,一个高质量的智能问答系统,会综合使用提示工程、检索增强生成和精调等方式。
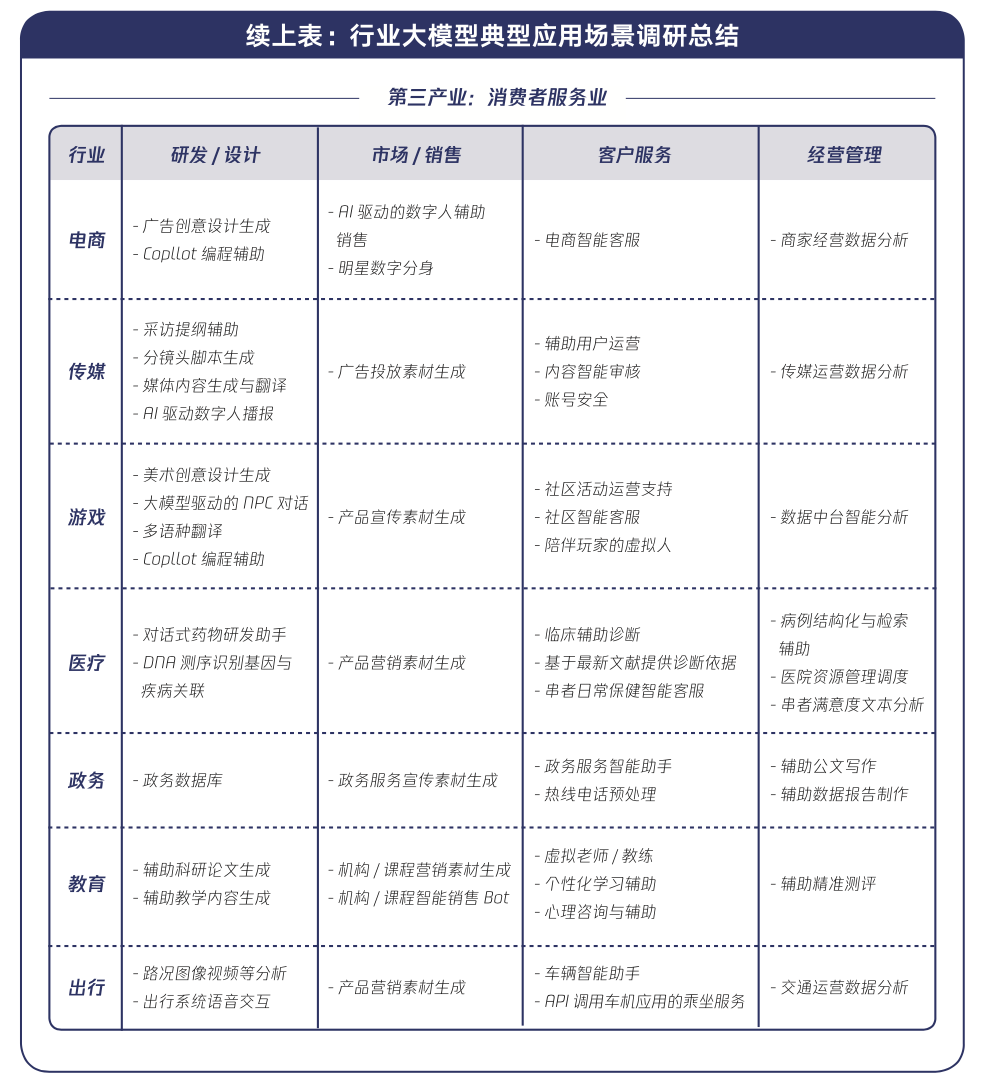
而在行业应用场景上,该报告也做了梳理,也很不错,如下:

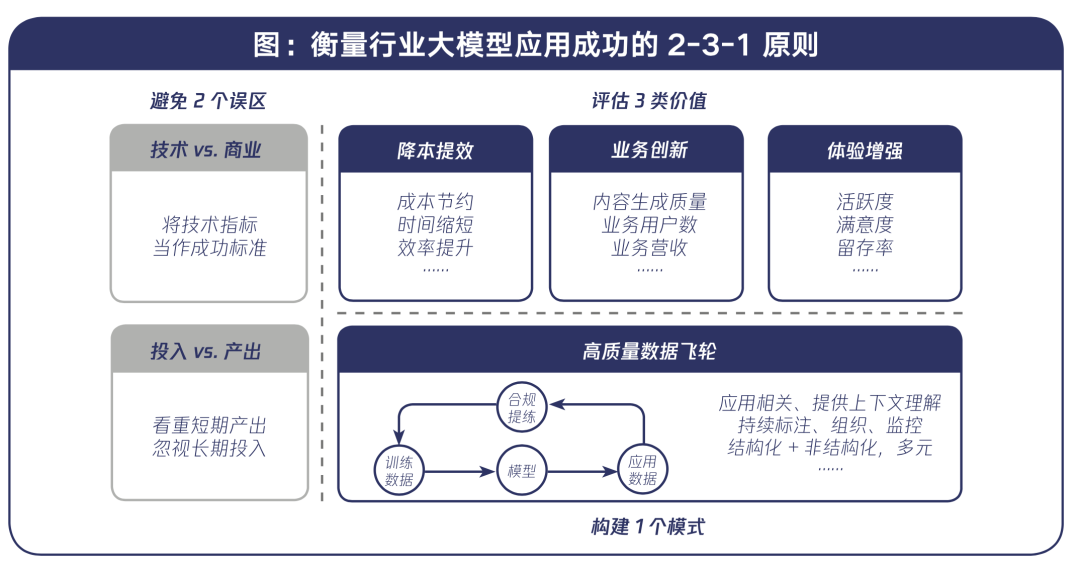
而怎么衡量一个行业模型是否成功,也可以进一步的总结成几个衡量原则,例如:
总结
本文主要围绕RAG综述以及行业模型的两个问题进行了总结,一个是目前RAG都有哪些综述,四大综述?一个是关于行业大模型的一些有趣总结。最近的总结都多了起来,并且都开始回归冷静。大家可以多看看,会有所收获。
参考文献
1、https://mp.weixin.qq.com/s/dxtKDqch3wMlW781exb51w
关于作者
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢