

ACL 2024

国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics,简称ACL)是自然语言处理(NLP)领域的顶级国际会议。ACL 2024 将于2024年8月11-16日在泰国曼谷举行。
近日,ACL 2024公布了论文入选结果。复旦大学数据智能与社会计算实验室共6篇论文被录用,其中1篇主会长文、1篇主会短文、4篇Findings 长文。
以下为6篇论文介绍(排序不分先后)

主会长文
Can LLMs Reason with Rules? Logic Scaffolding for Stress-Testing and Improving LLMs
作者:王思远,魏忠钰,Yejin Choi,Xiang Ren
类别:Long Paper,Main Conference
合作单位:南加州大学,AI2
GitHub主页:https://github.com/SiyuanWangw/ULogic
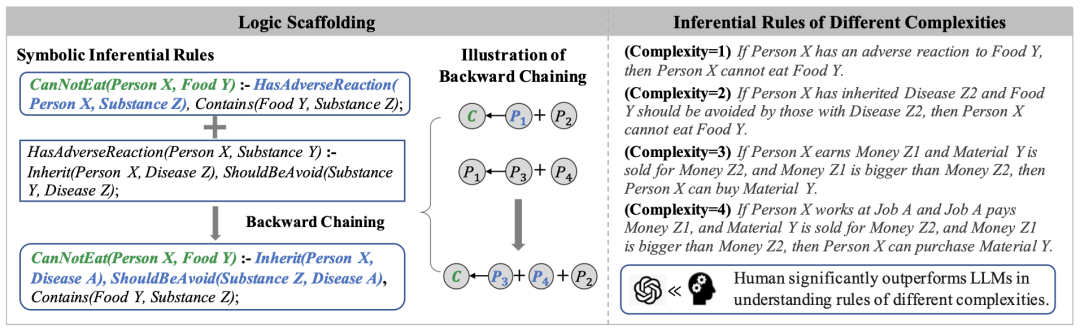
摘要:大语言模型(LLMs)在多种推理任务中表现出了接近人类的优异表现,但在掌握底层推理规则方面仍逊于人类。为探索此问题,我们提出了一个基于逻辑支架的推理规则生成框架,旨在构建一个包含五个领域的基础和组合规则的推理规则库ULogic。我们对GPT系列模型在一部分规则集上的分析显示,与人类相比,LLMs在理解逻辑规则方面存在显著差距,尤其是在那些包含偏见模式的复杂结构与组合规则上。我们进一步蒸馏这些规则,开发得到一个小规模推理引擎,以实现灵活的规则生成和增强下游推理能力。通过多重评估方式,我们的推理引擎在生成准确、复杂和抽象的结论和前提方面展现了有效性,并提升了各种常识推理任务的表现。总体而言,我们的研究揭示了LLMs在掌握推理规则方面的局限性,并提出了增强其逻辑推理能力的方法。

主会短文
EmbSpatial-Bench: Benchmarking Spatial Understanding for Embodied Tasks with Large Vision-Language Models
作者:杜梦飞,吴斌浩,李泽君,黄萱菁,魏忠钰
类别:Short Paper,Main Conference
GitHub主页:https://github.com/mengfeidu/EmbSpatial-Bench
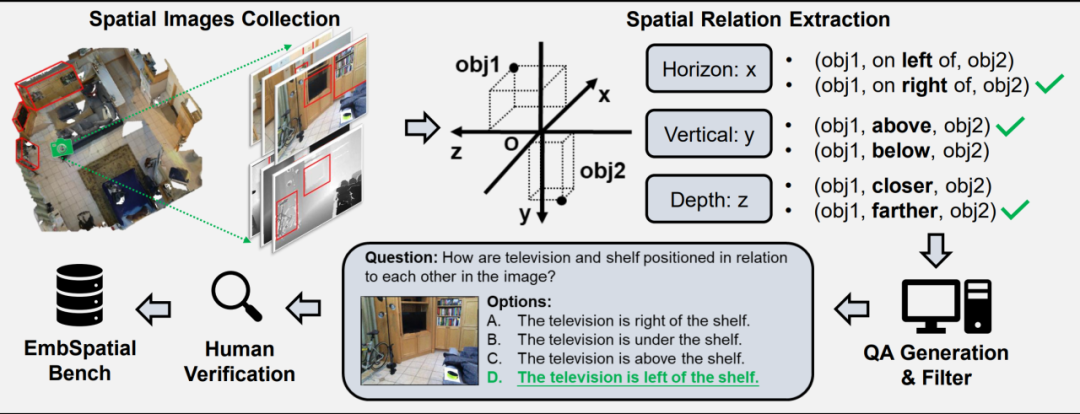
摘要:大视觉语言模型 (LVLM) 的快速发展体现了其在具身任务中的潜力。然而,其在具身环境中的空间理解能力尚未得到彻底评估,导致当前 LVLM 与合格的具身智能之间的差距尚不清楚。因此,我们构建了 EmbSpatial-Bench,这是评估 LVLM 具身空间理解能力的基准。该基准是从具身场景中自动化构建的,从以自我中心的角度覆盖了 6 种空间关系。实验揭示了当前 LVLM(甚至 GPT-4V)在该方面的能力不足。我们进一步构建了 EmbSpatial-SFT,一个旨在提高 LVLM 具身空间理解能力的指令微调数据集。
Findings 长文
SoMeLVLM: A Large Vision Language Model for Social Media Processing
作者:张辛农,旷皓予,牟馨忆,闾涵加,吴焜,陈思明,罗杰波,黄萱菁,魏忠钰
类别:Long Paper,Findings
合作单位:美国罗切斯特大学
GitHub主页:https://somelvlm.github.io/
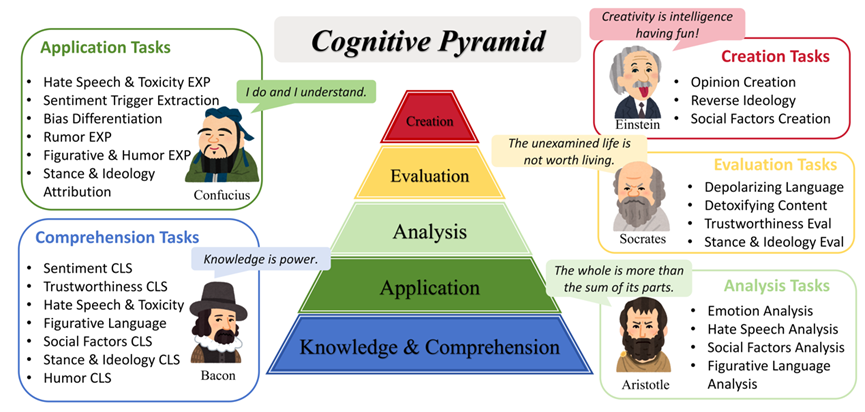
摘要:以多模态为一大特点的社交媒体内容的增长引起了各种现象和挑战,这需要一种有效的方法来统一解决自动化任务。强大的大型视觉语言模型(Large Vision Language Models,LVLM)使得同时处理各种任务成为可能,但即使使用精心设计的提示方法,通用领域模型往往难以与社交媒体任务的独特语言风格和上下文对齐。在本文中,我们介绍了一种用于社交媒体处理的大型视觉语言模型(SoMeLVLM),这是一个具有五大关键能力的认知框架,包括知识与理解、应用、分析、评估和创造。SoMeLVLM旨在理解和生成真实的社交媒体行为。我们开发了一个包含65.4万条多模态社交媒体指令微调数据集,以支持我们的认知框架并微调我们的模型。我们的实验表明,SoMeLVLM在多个社交媒体任务中实现了最先进的性能。进一步的分析显示,其在认知能力相对于基线模型具有显著优势。
Unveiling the Truth and Facilitating Change: Towards Agent-based Large-scale Social Movement Simulation
作者:牟馨忆,魏忠钰,黄萱菁
类别:Long Paper,Finding
GitHub主页:https://xymou.github.io/social_simulation/
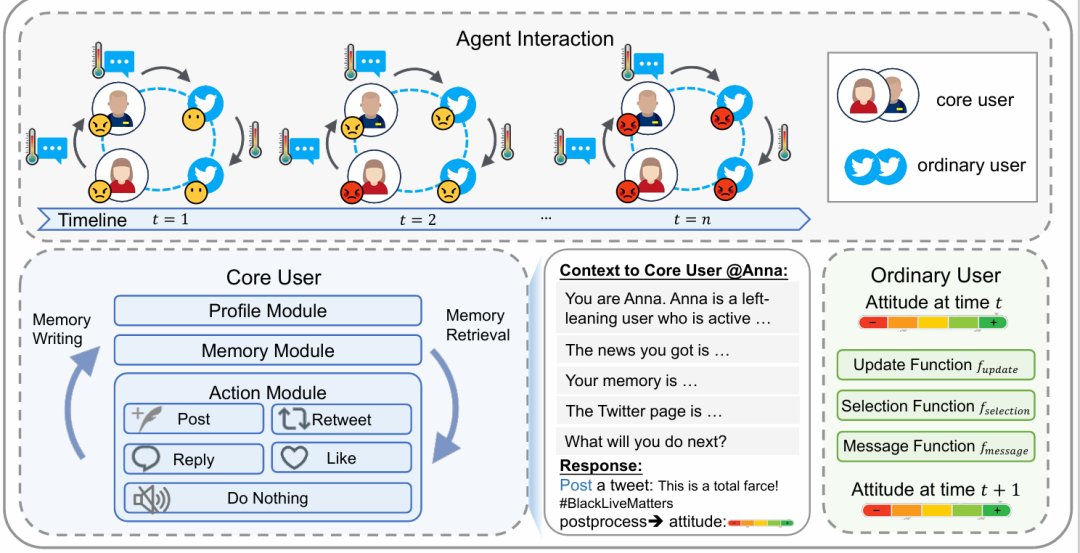
摘要:社交媒体是社会运动的基石,在推动社会变革中发挥了重要影响,模拟公众反应和预测潜在影响变得越来越重要。然而,现有的模拟方法在捕捉社会运动参与者行为的有效性和效率方面面临挑战。在本文中,我们介绍了一种社交媒体用户模拟的混合框架,其中用户分为两类。核心用户由大语言模型驱动,而大部分普通用户则由传统的基于智能体的模型进行模拟。我们构建了一个基于Twitter的社交媒体平台的环境,以观察用户在突发事件后的观点动态。为了验证模拟的有效性,我们构建了一个多方面的基准SoMoSiMu-Bench进行评估,在三个真实世界数据集上进行了实验。实验结果表明了我们方法的有效性和灵活性。
ALaRM: Align Language Models via Hierarchical Rewards Modeling
作者:赖昱行,王思远,刘书隽,黄萱菁,魏忠钰
类别:Long Paper, Findings
GitHub主页:https://alarm-fdu.github.io/
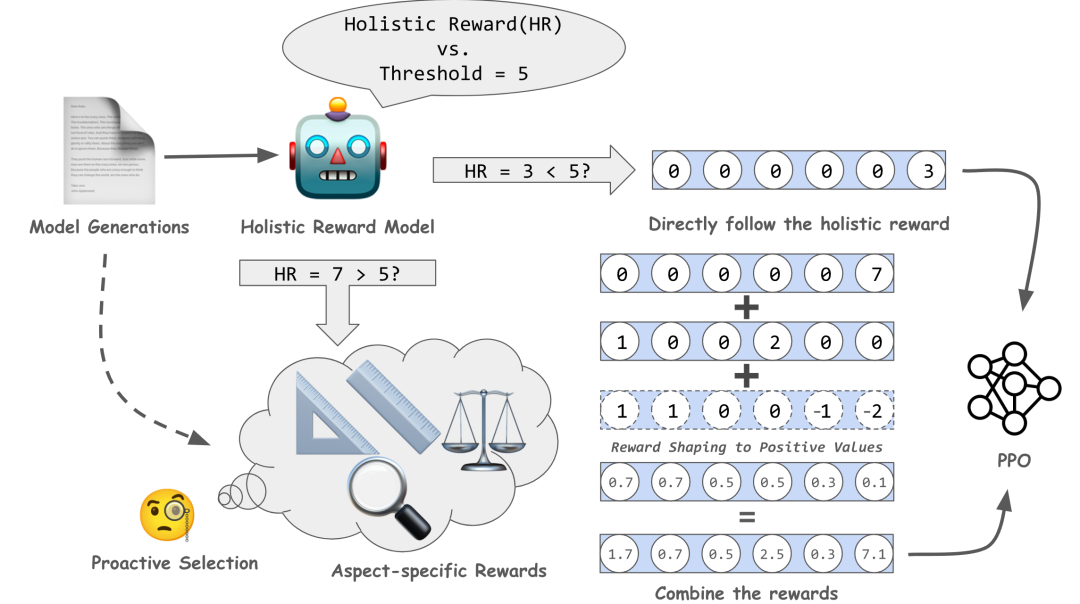
摘要:我们引出ALaRM,这是第一个在人类反馈强化学习(RLHF)中建模层次化奖励的框架,旨在提升大语言模型(LLM)与人类偏好的对齐。该框架希望解决当前对齐方法在处理人类监督信号的一致性和稀疏性方面存在的困难。ALaRM通过整合整体奖励和特定方面的奖励,提供更精确和一致的训练信号,特别是在复杂和开放的文本生成任务中。通过基于一致性的预先筛选和多种奖励的组合,该框架提供了一种可靠的机制来提升模型对齐。我们在长篇问答和机器翻译任务中的应用验证了我们方法的有效性,显示出了相对于现有基准的改进。我们的工作强调了层次化奖励建模在强化学习微调LLM训练中,更好地对齐人类偏好方面的有效性。
Debatrix: Multi-dimensional Debate Judge with Iterative Chronological Analysis Based on LLM
作者:梁敬聪,叶蓉,韩萌,赖若飞,张新宇,黄萱菁,魏忠钰
类别:Long Paper,Findings
合作单位:华为泊松实验室
GitHub主页:https://github.com/ljcleo/debatrix
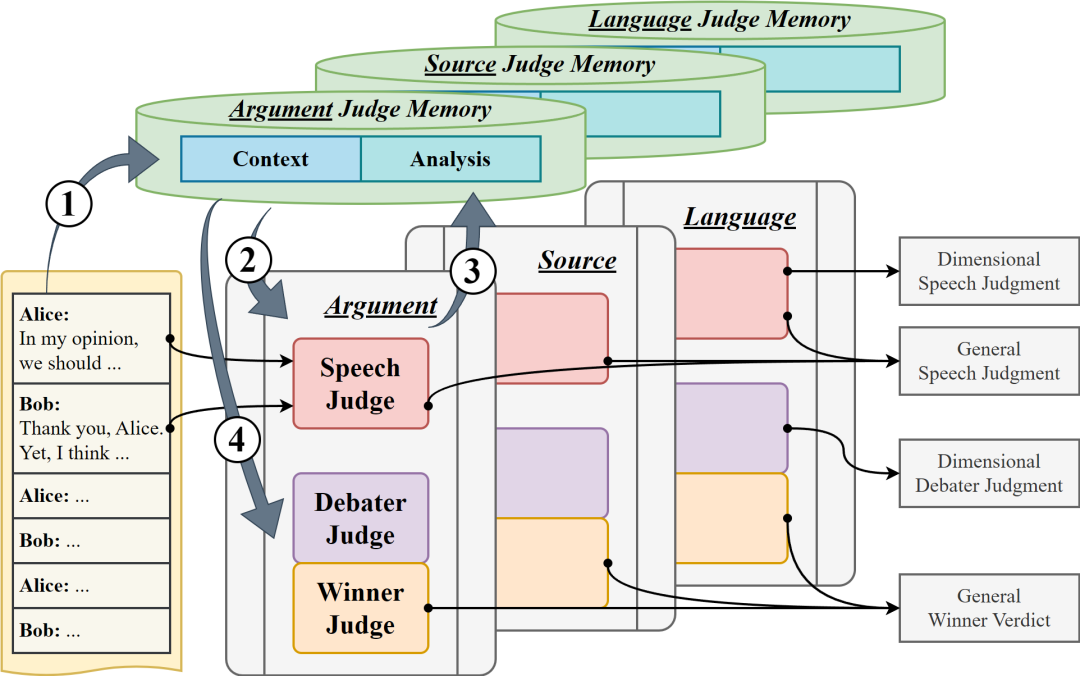
摘要:我们怎样才能构建一个自动辩论评委,以评估一场广泛、生动、多回合的辩论?这项任务极具挑战性,因为评判一场辩论需要处理冗长的文本和错综复杂的论证关系,并实现多维度的评估。同时,目前的研究主要集中在短对话上,很少涉及对整场辩论的评估。通过利用大型语言模型,我们提出了 Debatrix,使多回合辩论的分析和评估更符合多数人的偏好。具体来说,Debatrix 从两个维度分解辩论评估:纵向地按时间顺序迭代分析,以及横向地多维度协作评估。为了与真实辩论场景保持一致,我们构建了 PanelBench 评测基准,将我们系统的性能与实际辩论结果进行比较。研究结果表明,与直接使用大模型进行辩论评估相比,我们的系统性能有了显著提高。
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disc_imcs@163.com
地址:复旦大学邯郸校区计算中心
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢