- 斯坦福大学新研究:多模态基础模型的多样本上下文学习
- Meta 推出 Chameleon:早期融合 token 的混合模态模型
- 谷歌新研究:利用多视图扩散模型创建任何 3D 内容
- UC 伯克利新研究:利用强化学习微调大型视觉语言模型
- MIT 推出 STAR Benchmark:真实世界视频中的情景推理
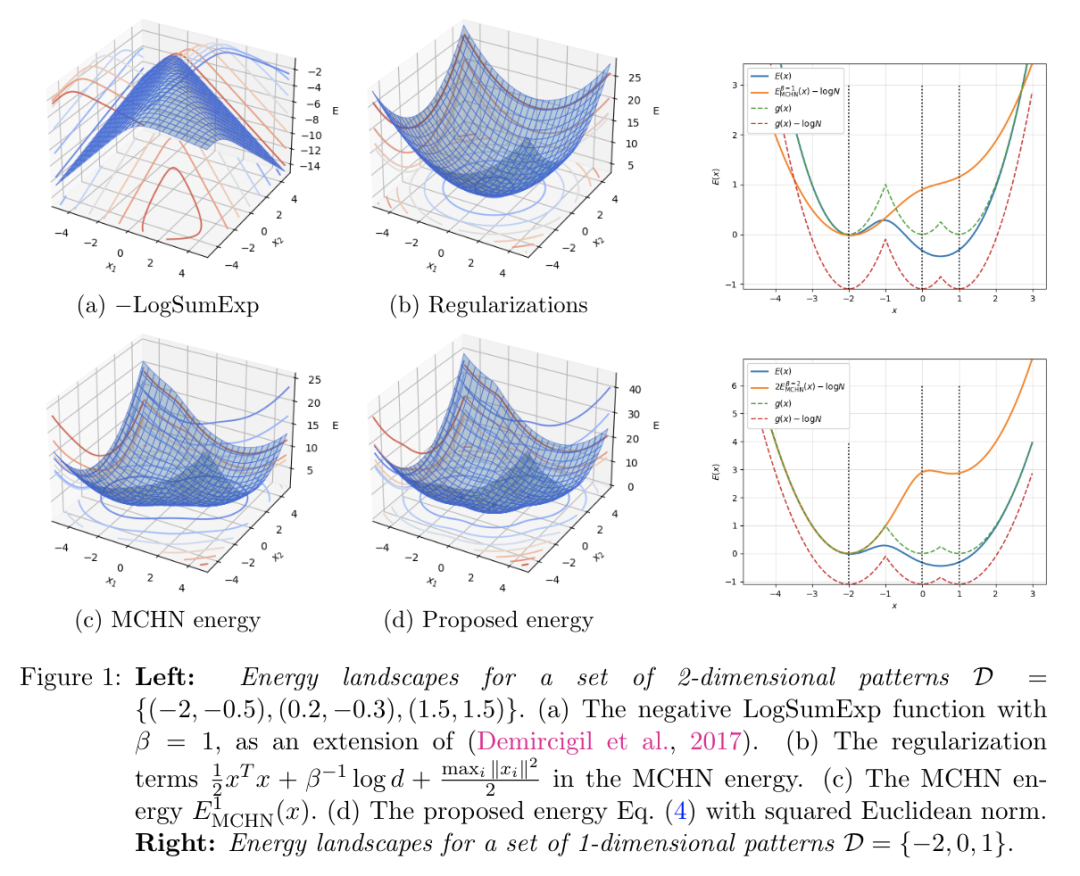
- 华为新研究:超越 Scaling Law,利用关联记忆了解 transformer 性能
- VidProM:首个大规模文本到视频扩散模型数据集
- Hugging Face 推出视觉语言模型 Idefics2
- Word2World:通过大型语言模型生成故事和世界
或点击“阅读原文”,获取「2024 必读大模型论文」合集(包括日报、周报、月报,持续更新中~)。
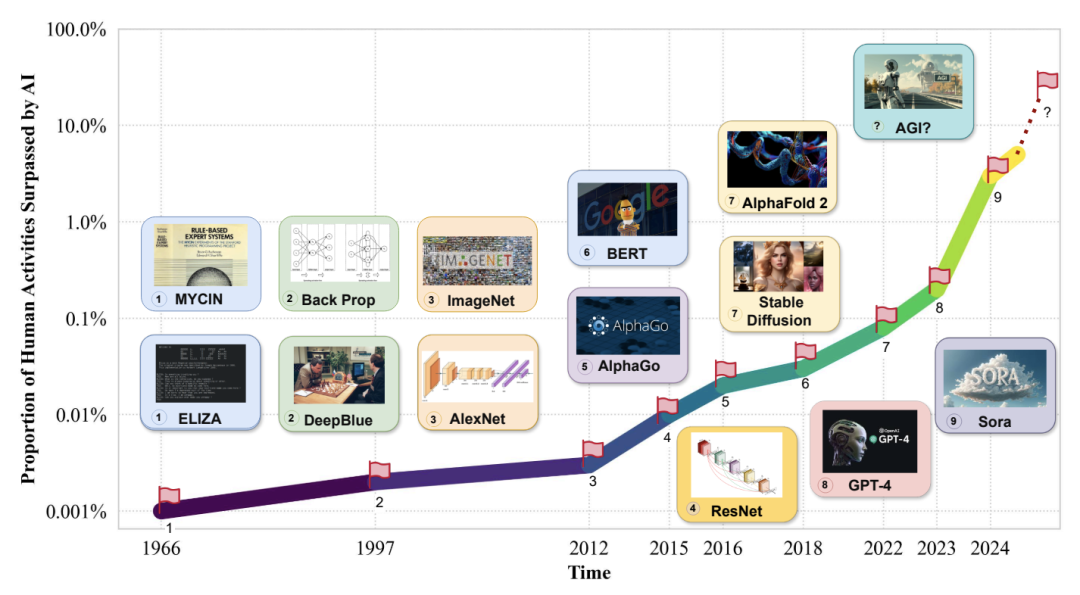
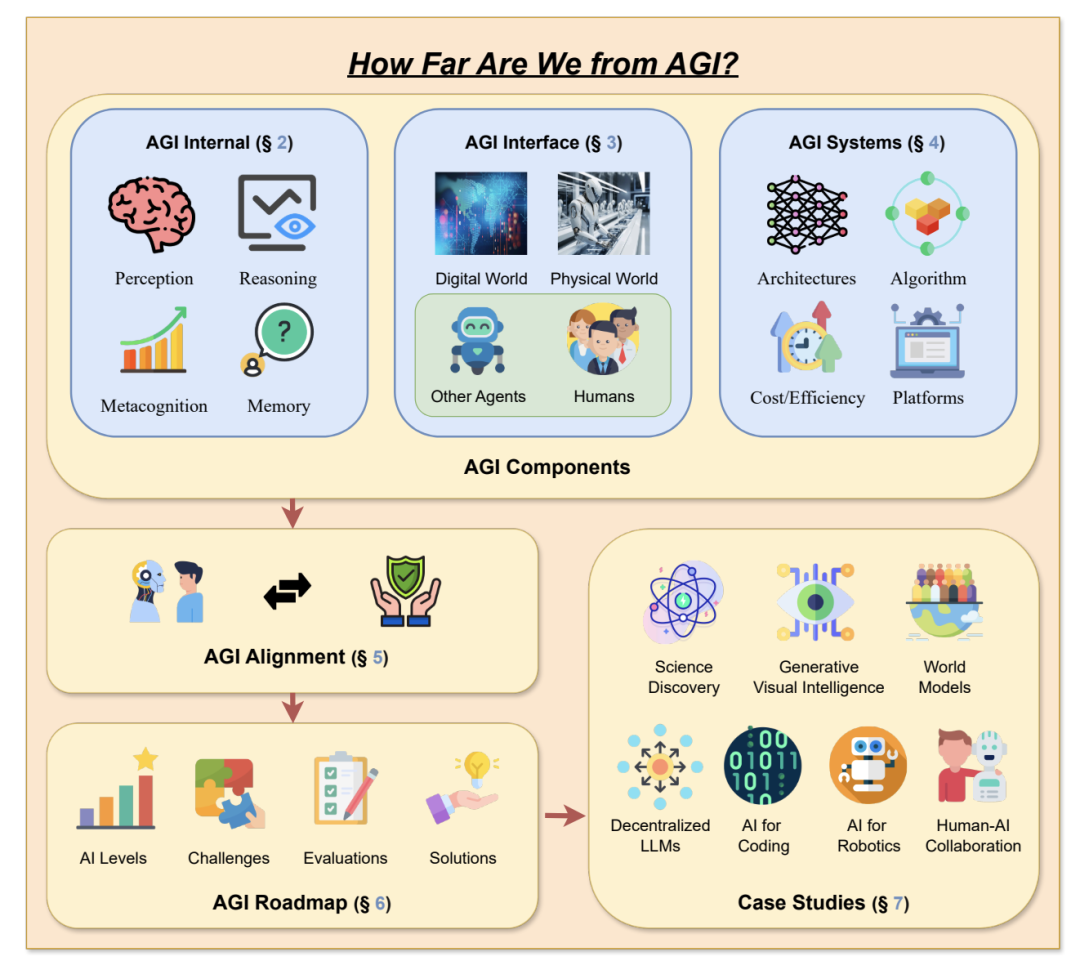
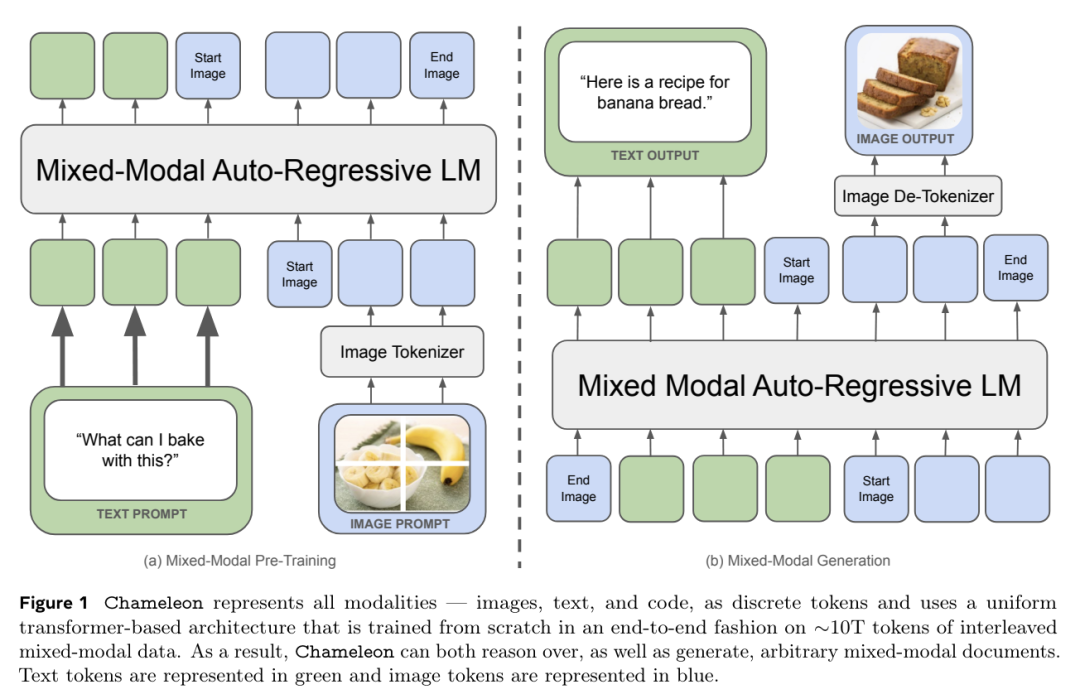
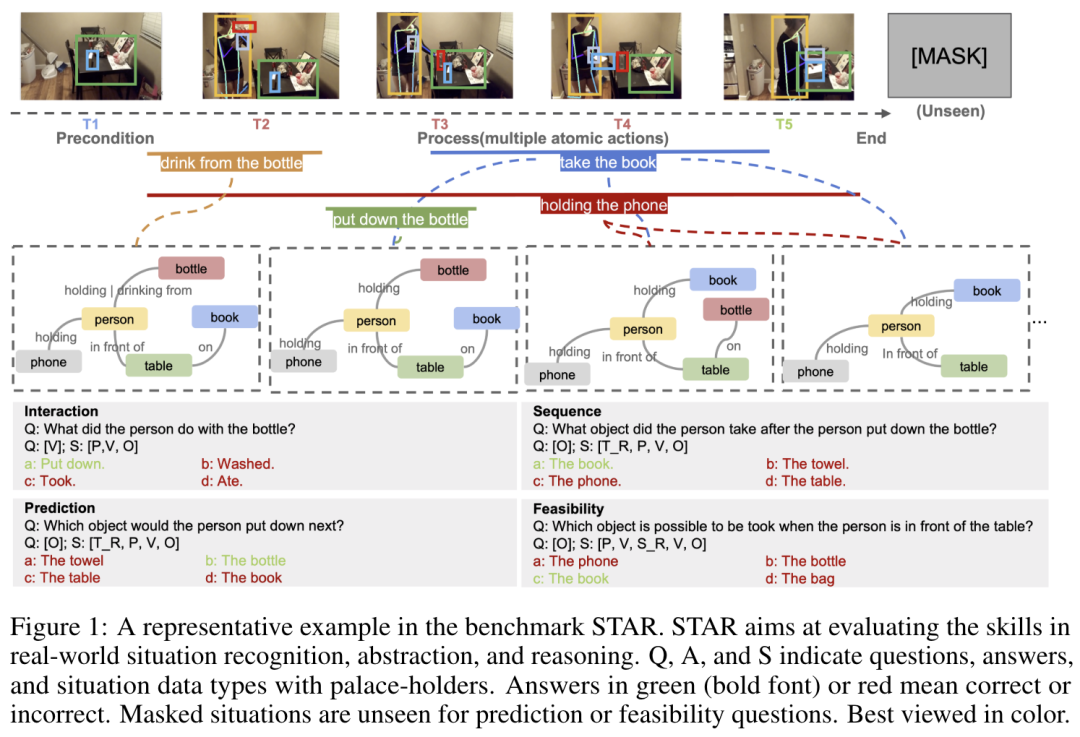
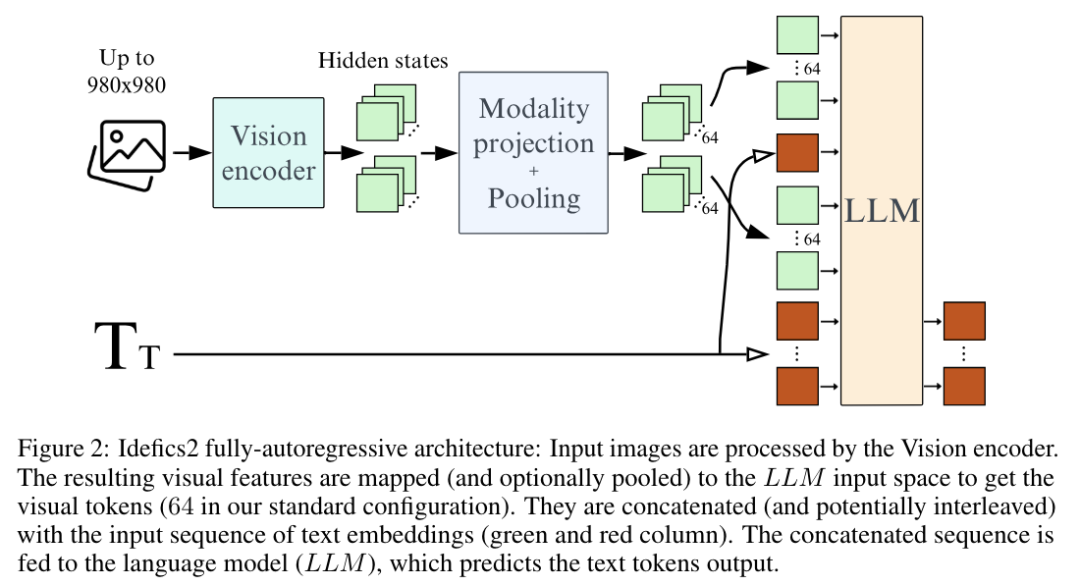
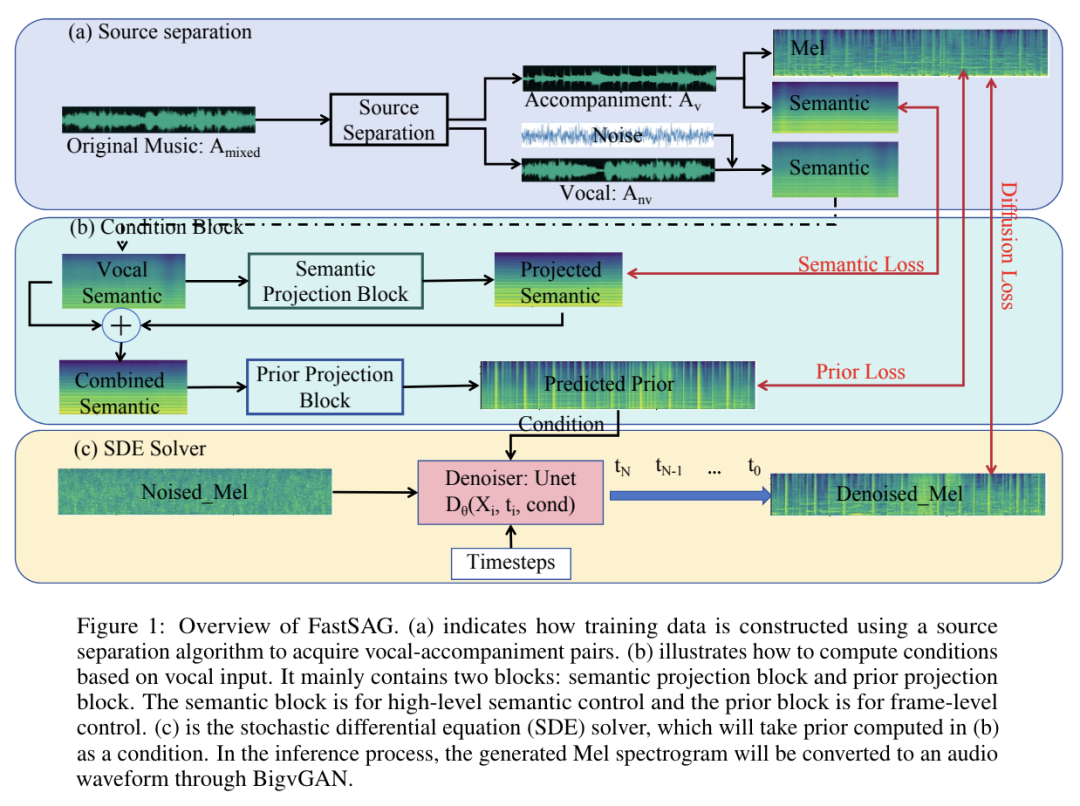
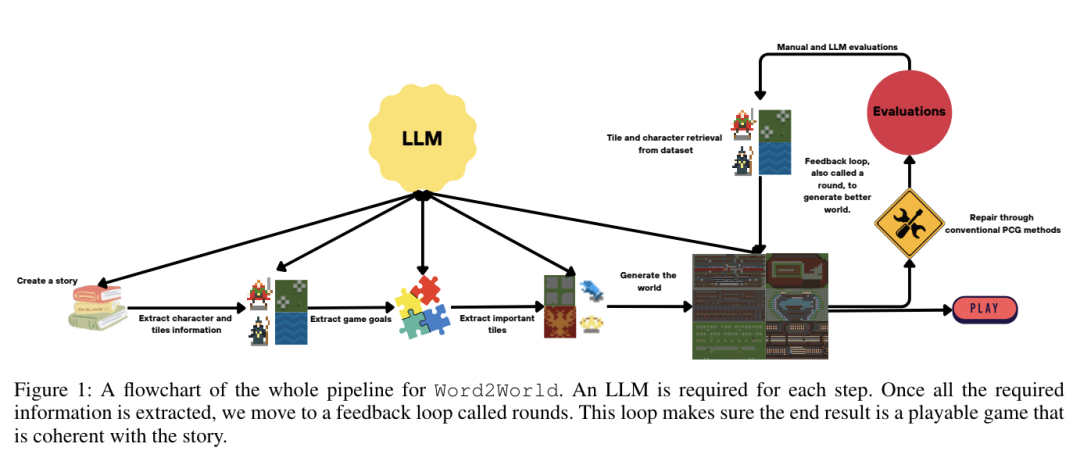
人工智能(AI)的发展对人类社会产生了深远的影响,推动了多个领域的重大进步。然而,对人工智能不断升级的需求凸显了人工智能现有产品的局限性,推动了通用人工智能(AGI)的发展。AGI 能够以媲美人类智能的效率和效力执行现实世界中的各种任务,将是人工智能发展史上的一个重要里程碑。虽然现有著作总结了人工智能的具体最新进展,但缺乏对 AGI 的定义、目标和发展轨迹的全面讨论。与现有的调查报告不同,该论文通过广泛的调查、讨论和原创性观点,深入探讨了我们接近 AGI 的关键问题以及实现 AGI 所需的策略。来自伊利诺伊大学香槟分校的研究团队及其合作者首先阐述了 AGI 所需的能力框架,整合了内部、界面和系统三个维度。由于实现 AGI 需要更先进的能力和严格的约束条件,他们进一步讨论了必要的 AGI 协调技术,来协调这些因素。值得注意的是,他们强调了以负责任的态度对待 AGI 的重要性,首先定义了 AGI 进展的关键层次,然后是评估现状的评估框架,最后给出了如何达到 AGI 巅峰的路线图。此外,为了让人们切实了解人工智能整合的普遍影响,他们概述了多个领域中实现 AGI 的现有挑战和潜在途径。总之,作为对 AGI 现状和未来轨迹的开创性探索,该论文旨在促进研究人员和从业人员对 AGI 的整体理解,并推动更广泛的公开讨论。https://arxiv.org/abs/2405.10313https://github.com/ulab-uiuc/AGI-survey目前,大型语言模型在少样本上下文学习(ICL)方面非常有效,多模态基础模型实现了超长上下文窗口,这为探索这些模型利用更多演示示例执行 ICL 提供了机会。为此,来自斯坦福大学的研究团队评估了多模态基础模型的性能,包括从少样本到多样本的 ICL。他们在横跨多个领域(自然图像、医学图像、遥感和分子图像)和任务(多类、多标签和细粒度分类)的 10 个数据集上对 GPT-4o 和 Gemini 1.5 Pro 进行了基准测试并发现,在所有数据集上,多样本 ICL(包括多达近 2000 个多模态演示示例)比少样本 ICL(小于 100 个示例)有大幅改进。此外,在许多数据集上,Gemini 1.5 Pro 的性能继续以对数线性方式提高直至测试实例的最大数量。考虑到多样本 ICL 所需的长时间提示所带来的高推理成本,他们还探索了在单次 API 调用中批处理多个查询的影响。研究表明,在零样本和多样本 ICL 条件下,多达 50 次的批量查询可带来性能提升,在多个数据集上的零样本设置中,性能提升显著的同时大幅降低了每次查询的成本和延迟。最后,他们测量了模型的 ICL 数据效率,即模型从更多示范示例中学习的速度。他们发现,虽然 GPT-4o 和 Gemini 1.5 Pro 在数据集上实现了相似的零样本性能,但在大多数数据集上,Gemini 1.5 Pro 的 ICL 数据效率都高于 GPT-4o。研究表明,多样本 ICL 可以让用户高效地调整多模态基础模型,从而适应新的应用和领域。https://arxiv.org/abs/2405.09798https://github.com/stanfordmlgroup/ManyICL来自 Meta 的研究团队提出了一系列基于早期融合 token 的混合模态模型—— Chameleon,能够理解和生成任意序列的图像和文本。他们概述了一种稳定的训练方法、配准秘诀,以及专为早期融合、基于 token 的混合模态设置而定制的架构参数化。他们在一系列任务中对模型进行了评估,包括视觉问题解答、图像字幕、文本生成、图像生成和长格式混合模态生成。Chameleon 在图像字幕任务中的表现出色,在纯文本任务中的表现优于 Llama-2,同时可以与 Mixtral 8x7B 和 Gemini-Pro 等模型竞争,并能进行非繁琐的图像生成,所有这些都在一个模型中完成。在新的长式混合模式生成评估中,提示或输出都包含图像和文本的混合序列,根据人类的判断,Chameleon 的性能也达到或超过了更大型的模型,包括 Gemini Pro 和 GPT-4V。https://arxiv.org/abs/2405.09818目前,3D 重建技术的进步实现了高质量的 3D 捕捉,但用户需要收集成百上千张图像才能创建 3D 场景。来自谷歌研究团队提出了一种通过多视角扩散模型模拟现实世界中的捕捉过程来创建 3D 场景的方法—— CAT3D。给定任意数量的输入图像和一组目标新视角,他们的模型就能生成高度一致的场景新视角。这些生成的视图可作为鲁棒性 3D 重构技术的输入,生成可从任何视角实时渲染的 3D 呈现。CAT3D 可在一分钟内创建整个 3D 场景,其性能优于现有的单幅图像和少视角 3D 场景创建方法。https://arxiv.org/abs/2405.10314目前,根据专门的视觉指令数据微调的大型视觉语言模型(VLM)在各种场景中都表现出了令人印象深刻的语言推理能力。然而,这种微调范式可能无法从交互环境中有效学习多步骤目标导向任务中的最优决策智能体。为此,来自加州大学伯克利分校、伊利诺伊大学厄巴纳-香槟分校和纽约大学的研究团队提出了一种利用强化学习(RL)对 VLM 进行微调的算法框架。具体来说,他们的框架提供任务描述,然后提示 VLM 生成思维链(CoT)推理,使 VLM 能够有效地探索导致最终文本行动的中间推理步骤。接下来,开放式文本输出会被解析为可执行的动作,从而与环境互动,获得目标导向的任务奖励。最后,他们的框架利用这些任务奖励,通过 RL 对整个 VLM 进行微调。他们提出的框架增强了智能体在各种任务中的决策能力,使 7b 模型的表现优于 GPT4-V 或 Gemini 等商业模型。此外,他们还发现 CoT 推理是提高性能的关键因素,因为去除 CoT 推理会导致他们方法的整体性能显著下降。https://arxiv.org/abs/2405.10292现实世界中的推理离不开情景,如何从周围情景中捕捉现有知识并进行相应的推理,对于人工智能来说至关重要,也极具挑战性。来自麻省理工大学和上海交通大学的研究团队提出了一个新的基准,即 “真实世界视频中的情景推理(STAR Benchmark)”,该基准通过对真实世界视频的情景抽象和基于逻辑的问题解答来评估情景推理能力。该基准基于现实世界中与人类行为或互动相关的视频,这些视频具有天然的动态性、构成性和逻辑性。数据集包括四种类型的问题,包括交互、顺序、预测和可行性。他们通过连接提取的原子实体和关系(如动作、人、物和关系)的超图来表示真实世界视频中的情境。除了视觉感知,情景推理还需要结构化的情景理解和逻辑推理,问题和答案是按程序生成的,每个问题的回答逻辑都由基于情境超图的功能程序来表示。他们对现有的各种视频推理模型进行了比较,发现它们都难以完成这项具有挑战性的情景推理任务。他们进一步提出了一种诊断性神经符号模型,该模型可以将视觉感知、情境抽象、语言理解和功能性推理区分开来。 https://arxiv.org/abs/2405.09711https://bobbywu.com/STAR/超越 Scaling Law,利用关联记忆了解 transformer 性能增大 transformer 模型的尺寸并不总能提高性能。这种现象无法用经验 Scaling Law 来解释。此外,随着模型对训练样本的记忆增加,泛化能力也会得到提高。在这项工作中,来自华为的研究团队提出了一个理论框架,揭示了基于 transformer 的语言模型的记忆过程和性能动态。他们利用 Hopfield 网络为具有关联记忆的 transformer 行为建模,从而使每个 transformer 块都能有效地进行近似近邻搜索。在此基础上,他们设计了一个类似于现代连续 Hopfield 网络的能量函数,它为注意力机制提供了一个深刻的解释。利用主化-最小化(majorization-minimization)技术,他们构建了一个全局能量函数,它捕捉到了 transformer 的分层结构。在特定条件下,他们证明可实现的最小交叉熵损失由一个近似等于 1 的常数从下往上限定。他们使用 GPT-2 在不同规模的数据上进行了实验,并在 200 万个 token 的数据集上训练了 vanilla Transformers,从而证实了理论结果。https://arxiv.org/abs/2405.08707Sora 的出现标志着文本到视频扩散模型进入了一个新时代。然而,Sora 和其他文本到视频扩散模型一样,高度依赖于提示,而目前还没有一个公开可用的数据集对文本到视频提示进行研究。在这项工作中,来自浙江大学、悉尼科技大学的研究团队提出了首个大规模文本到视频扩散模型数据集 VidProM,其包含 167 万个来自真实用户的独特文本到视频提示。此外,该数据集还包括由四种最先进的扩散模型生成的 669 万个视频以及一些相关数据。他们通过说明 VidProM 与 DiffusionDB(一个用于图像生成的大型提示图库数据集)的不同之处,强调了对一个专门用于文本到视频生成的新提示数据集的需求。这一广泛多样的数据集还开辟了许多令人兴奋的新研究领域。例如,他们建议探索文本到视频提示工程、高效视频生成以及扩散模型的视频复制检测,从而开发出更好、更高效、更安全的模型。https://arxiv.org/abs/2403.06098https://vidprom.github.io/最近在大模型方面取得的突破凸显了数据规模、标签和模态的重要意义。在这项工作中,来自微软的研究团队及其合作者,提出了首个大规模的、信息丰富的网络数据集 MS MARCO Web Search,其具有数百万真实点击查询文档标签。该数据集密切模拟真实世界的网络文档和查询分布,为各种下游任务提供了丰富的信息,并促进了各个领域的研究,如通用端到端神经索引器模型、通用嵌入模型和具有大型语言模型的下一代信息访问系统。此外,MS MARCO 网络搜索提供了一个检索基准,包含三个网络检索挑战任务,要求在机器学习和信息检索系统研究领域进行创新。https://arxiv.org/abs/2405.07526https://github.com/microsoft/MS-MARCO-Web-Search10.Hugging Face 推出视觉语言模型 Idefics2随着大型语言模型(LLMs)和视觉 transformers 的改进,人们对视觉语言模型(VLM)的兴趣与日俱增。尽管有关这一主题的文献很多,但有关视觉语言模型设计的关键决策往往缺乏依据。在这项工作中,来自 Hugging Face 和索邦大学的研究团队认为,这些没有依据的决定阻碍了该领域的进步,因为人们很难确定哪些选择能提高模型性能。为了解决这个问题,他们围绕预训练模型、架构选择、数据和训练方法进行了大量实验,并开发了一个拥有 80 亿个参数的高效基础 VLM——Idefics2。在各种多模态基准测试中,Idefics2 的性能在同类规模模型中处于领先水平,通常可与 4 倍于其规模的模型相媲美。此外,他们也发布了该模型(基础模型、指导模型和聊天模型)以及为训练该模型而创建的数据集。https://arxiv.org/abs/2405.0224611.FastSAG:实现快速非自回归歌唱伴奏生成歌唱伴奏生成(SAG)可生成器乐伴奏输入的人声,对于开发人与人工智能共生艺术创作系统至关重要。最先进的方法——SingSong——利用多阶段自回归模型来生成 SAG,但这种方法生成语义和声音 token 的速度极慢,因此无法用于实时应用。为了创建高质量和连贯的伴奏,来自香港科技大学、微软亚洲研究院的研究团队,开发了一种基于非自回归、扩散的框架,通过精心设计从人声信号中推断出的条件,直接生成目标伴奏的梅尔频谱图。通过扩散和梅尔频谱图建模,所提出的方法大大简化了基于自回归 token 的 SingSong 框架,并在很大程度上加快了生成速度。为了确保生成的伴奏与人声信号在语义和节奏上保持一致,他们还设计了语义投影、先验投影块以及一组损失函数。通过深入的实验研究,他们证明了所提出的方法能生成比 SingSong 更好的样本,并能将生成速度至少提高 30 倍。https://arxiv.org/abs/2405.07682https://fastsag.github.io/12.Word2World:通过大型语言模型生成故事和世界大型语言模型(LLM)已经在程序内容生成(PCG)领域显示出了巨大的潜力,但通过预先训练好的大型语言模型直接生成关卡仍然具有挑战性。在这项工作中,来自威特沃特斯兰德大学和纽约大学的研究团队,提出了一个能让 LLM 通过故事程序设计可玩游戏、无需任何特定任务微调的系统——Word2World。Word2World 充分利用了 LLM 创造多样化内容和提取信息的能力。结合这些能力,LLMs 可以为游戏创建故事、设计叙事,并将瓷砖放置在适当的位置,从而创建连贯的世界和可玩的游戏。https://arxiv.org/abs/2405.06686https://github.com/umair-nasir14/Word2World
内容中包含的图片若涉及版权问题,请及时与我们联系删除








评论
沙发等你来抢