
今天为大家介绍的是来自Su-In Lee 团队的一篇论文。构建可信赖和透明的基于图像的医疗人工智能(AI)系统需要在开发流程中的所有阶段对数据和模型进行审查。理想情况下,数据和相关AI系统可以使用医生已熟悉的术语来描述,但这需要医疗数据集密集地注释有语义意义的概念。在本研究中,作者提出了一种基础模型方法,名为MONET(医学概念检索器),它学习如何将医疗图像与文本连接,并在概念存在上密集地评分图像,以支持医疗AI开发和部署中的重要任务,如数据审核、模型审核和模型解释。由于疾病、肤色和成像方式的多样性,皮肤科提供了一个对MONET多功能性的苛刻用例,作者基于105,550张带有大量医学文献自然语言描述的皮肤病学图像训练了MONET。MONET能够准确地在皮肤科图像中注释概念,这与以前在临床图像的皮肤病学数据集上构建的有监督模型相抗衡。作者展示了MONET如何在整个AI系统开发流程中实现AI透明度,从构建本质上可解释的模型到数据集和模型审核,其中包括分析AI临床试验结果的案例研究。

确保医疗AI系统的透明度和稳健性涉及在每个阶段对数据和模型进行评估,从模型训练到部署后监控。然而,用于解开医疗AI系统“黑箱”的工具通常需要具有密集的人类可理解概念注释的医疗数据集。不幸的是,获取此类标签需要领域专家大量的时间。相比之下,医学界开发的丰富的临床概念注释可以使得进行多种分析成为可能。这种丰富的注释可以帮助开发医疗AI系统的研究人员更好地理解数据集中的偏差,并检测这些系统中的不良行为。此外,这些注释还可以促进更符合医生期望的AI系统的开发。然而,先前的努力已经表明,通过人类专家的大规模努力获得这些数据是不可行的。
模型部分
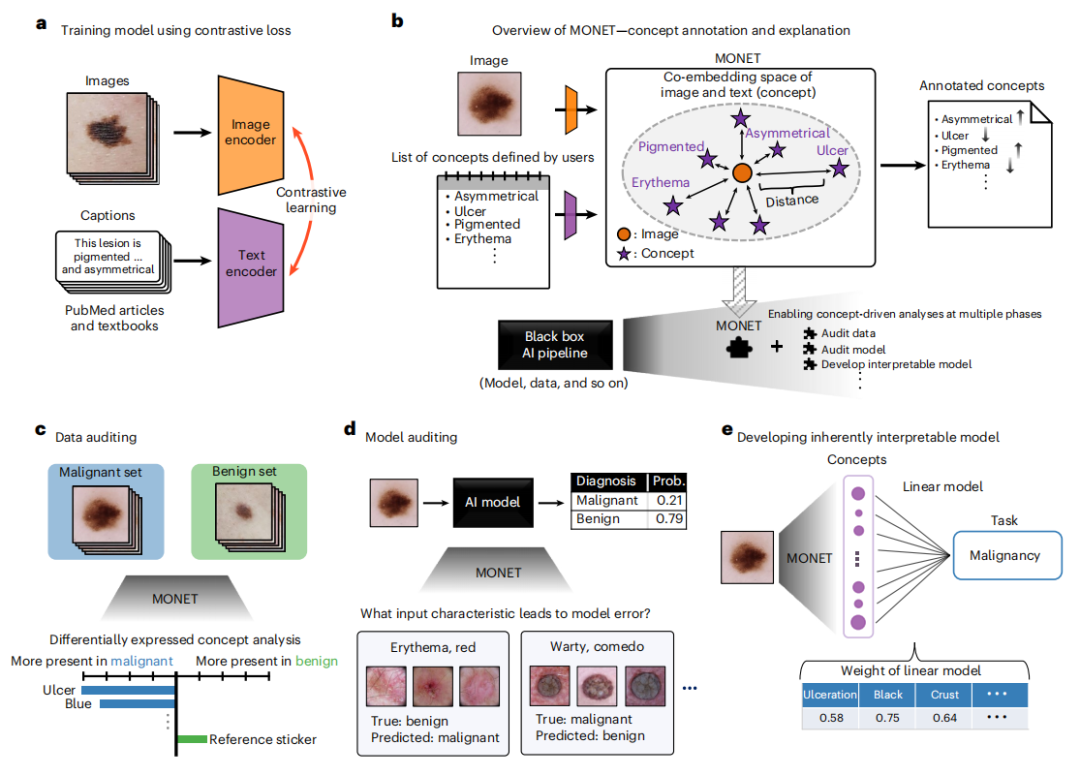
图 1
在本研究中,作者利用医学界中包含在公开的医学文献和教科书的集体知识来教授一个AI模型——MONET,该模型用医学相关的概念丰富地注释医疗图像(见图1a,b)。根据用户预定义的概念列表,MONET为每个概念的图像分配分数表明图像代表该概念的程度。作者专注于皮肤科以展示其多功能性,因为皮肤科在不同肤色和成像条件(例如,光线、模糊)下疾病表现出异质性。在这种情况下,MONET的概念注释能力允许在医疗AI流程的所有阶段进行有意义的信任度分析,如三个用例所示(见图1c-e):数据集审核、模型审核和解释模型的构建。
实验结果
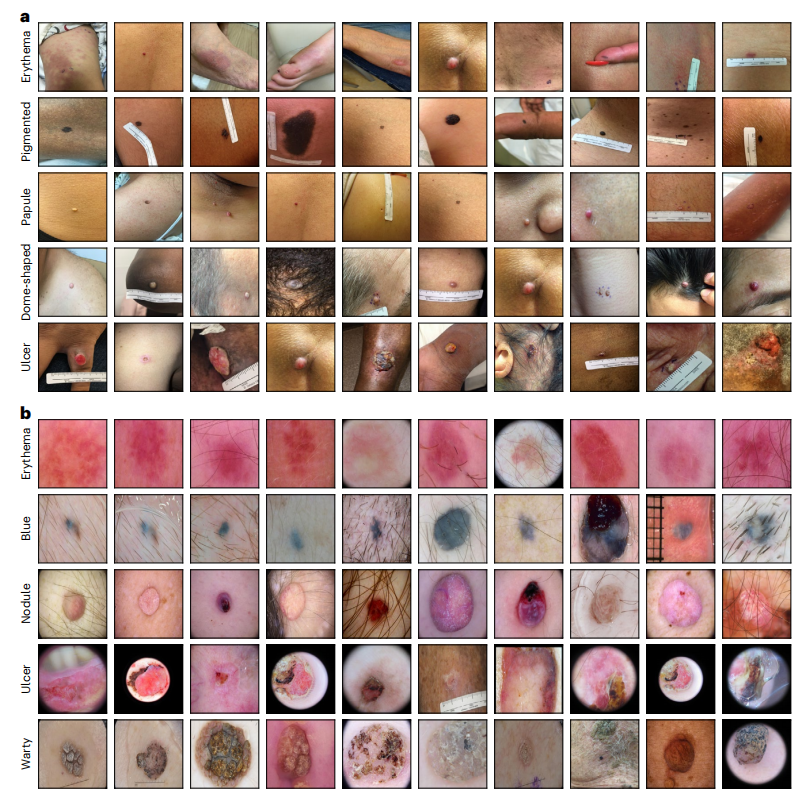
图 2
在展示如何提高医疗AI管道的透明度和可解释性之前,作者首先评估了MONET的概念注释能力。作者通过识别具有最高概念存在分数的图像来评估MONET的概念注释能力,使用的是两种广泛使用的皮肤病学图像类型:临床图像和皮肤镜图像。对于作者的评估,作者使用了来自Fitzpatrick 17k和Diverse Dermatology Image (DDI)数据集的临床图像(n=4,910),以及来自国际皮肤成像合作组织(ISIC)和Derm7pt数据集的皮肤镜图像(n=71,665)。作者观察到MONET成功检索了与各种皮肤病学术语相关的临床和皮肤镜图像(见图2)。例如,当提示“红斑”(描述一种红色或紫罗兰色)时,MONET检索出显示此类红色的图像。使用概念“蓝色”提示时,检索到的是深蓝色病变的图像,这些病变似乎是真皮中的色素沉着造成的。MONET还能够检索出具有主要形态特征(如丘疹和结节)以及次要形态特征(如溃疡)的图像。
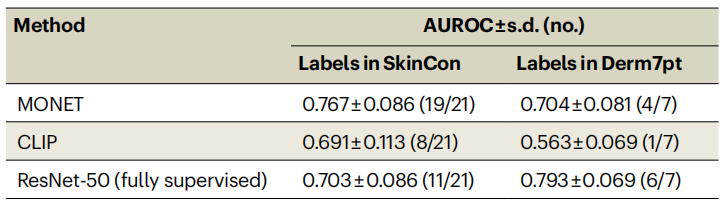
表 1
作者使用两个数据集的基准概念标签评估了MONET的概念注释性能:SkinCon用于临床图像和Derm7pt用于皮肤镜图像(见表1)。在排除具有少于30个正例的概念后,测试包括1,635个临床图像中的21个概念和1,011个皮肤镜图像中的7个概念。作者将MONET的性能与使用基于真实概念标签的ResNet-50模型进行了比较,并与一种未专门针对皮肤病学图像训练但在网络上可用的4亿个图像-文本对的对比性图像-文本模型CLIP进行了比较。作者发现,MONET在临床和皮肤镜图像上通常优于CLIP。这是预期的,因为MONET本质上是在皮肤病学数据上的CLIP的微调版本。MONET在与完全监督的基线模型的竞争中也表现出竞争力,MONET通常在临床图像上领先,而完全监督模型通常在皮肤镜图像上领先。
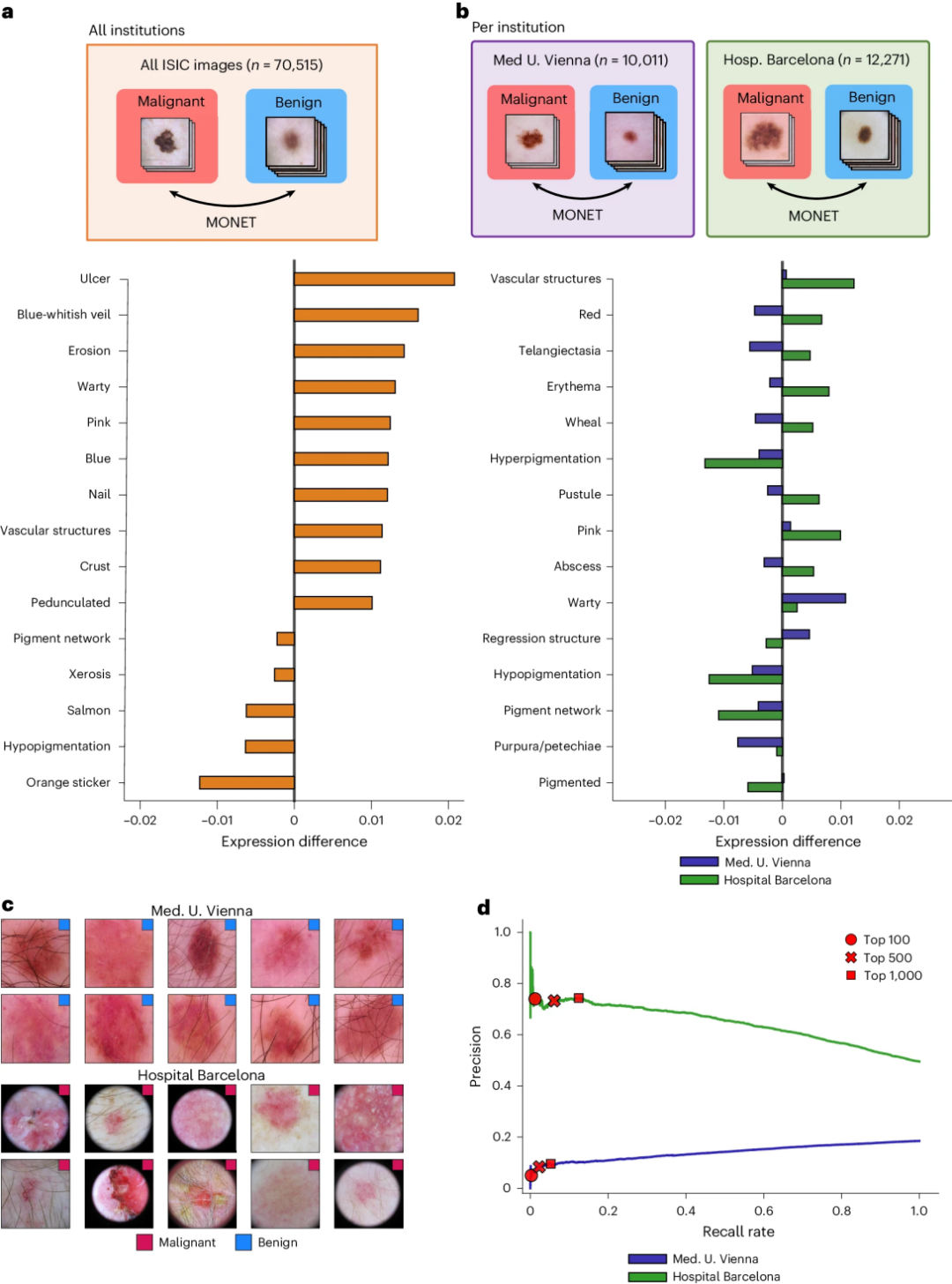
图 3
作为一个实际用例,作者使用MONET分析了ISIC数据集,它包含超过70,000张公开可用的图像。作者将图像分为恶性组(n=9,990)和良性组(n=60,525),假设恶性为预测目标,并检查了哪些概念在哪一组中更常见(见图3a)。作者专注于在ISIC挑战赛2019中发布的两个队列——维也纳医科大学(恶性:n=1,824;良性:n=8,187)和巴塞罗那临床医院(恶性:n=6,021;良性:n=6,250),它们代表了按发布年份和数据来源分类的整个ISIC数据集中的两个最大队列。作者分别对每个队列的恶性和良性图像进行了概念差异分析,然后比较了两个队列获得的概念差异表达分数(见图3b)。根据绝对差异对测试概念进行排序时,两个机构之间的顶级概念“红色”色调具有相反意义。在巴塞罗那医院,红色与恶性正相关,而在维也纳医科大学则负相关。这表明红色有可能妨碍两个机构之间医疗AI模型的可转移性。这一趋势在每个队列的红色图像中也可见(见图3c,d)。因此,这些实验表明MONET可以协助审核大规模数据集。
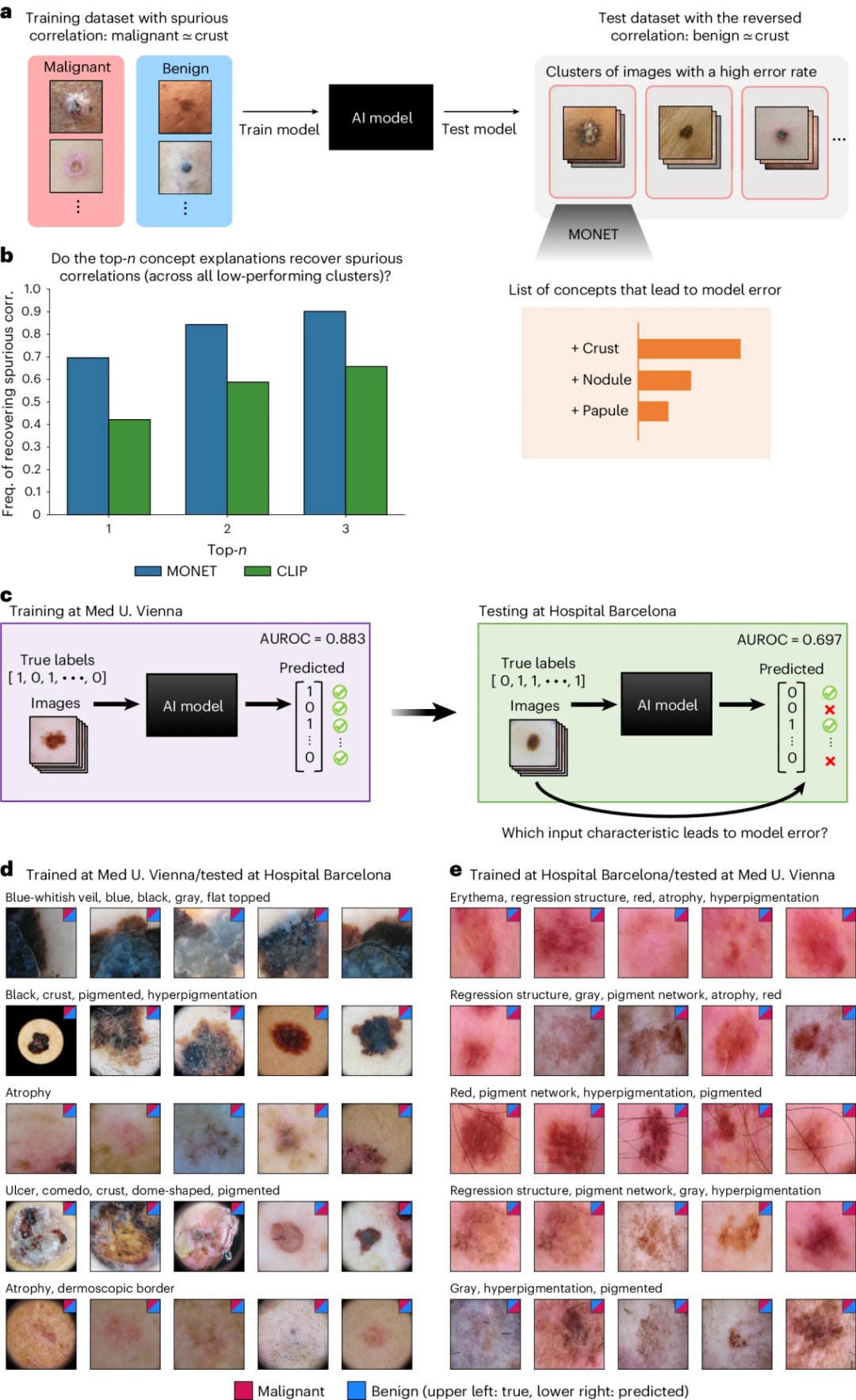
图 4
作者开发了一种名为“使用MONET进行模型审核”(MA-MONET)的方法,该方法使用MONET自动检测导致模型错误的语义上有意义的医学概念。为了验证MA-MONET,作者首先进行了基准分析(见图4a)。在基准分析中,作者训练了一个卷积神经网络(CNN)来预测一个数据集上的恶性,其中一个特定的SkinCon概念与恶性虚假相关,并在一个相关性被逆转的数据集上进行测试。作者观察到平均AUROC从验证集的0.782下降到测试集的0.463,跨越100个模拟设置。作者应用了MA-MONET来观察它是否识别出已知的虚假相关概念。作者测量了MA-MONET识别已知虚假相关的频率(见图4b)。为了展示MONET-MA在现实世界场景中的应用,作者考虑了一个常见情况,即一个模型在一个机构训练并在另一个机构部署(见图4c)。与数据审核实验类似,作者在一个机构的数据上训练CNN模型,并在另一个机构的数据上进行测试。在维也纳医科大学训练的AI模型在内部和外部验证之间的性能下降了(AUROC分别为0.883和0.697),这可能促使开发者探究是哪些输入特征导致了错误。MA-MONET的应用识别出与高错误率相关的特征(见图4d),如被标记为“蓝白色面纱状斑”、“蓝色”、“黑色”、“灰色”和“平顶型”的图像群组。相反,作者在巴塞罗那医院的数据上训练了一个AI模型,并在维也纳医科大学的数据上进行了测试,观察到AUROC从内部验证的0.832下降到外部验证的0.717。在MA-MONET结果中,错误率最高的群组的特征是概念“红斑”、“退化结构”、“红色”、“萎缩”和“色素增加”(见图4e)。这一观察也与数据审核实验中注意到的趋势一致。
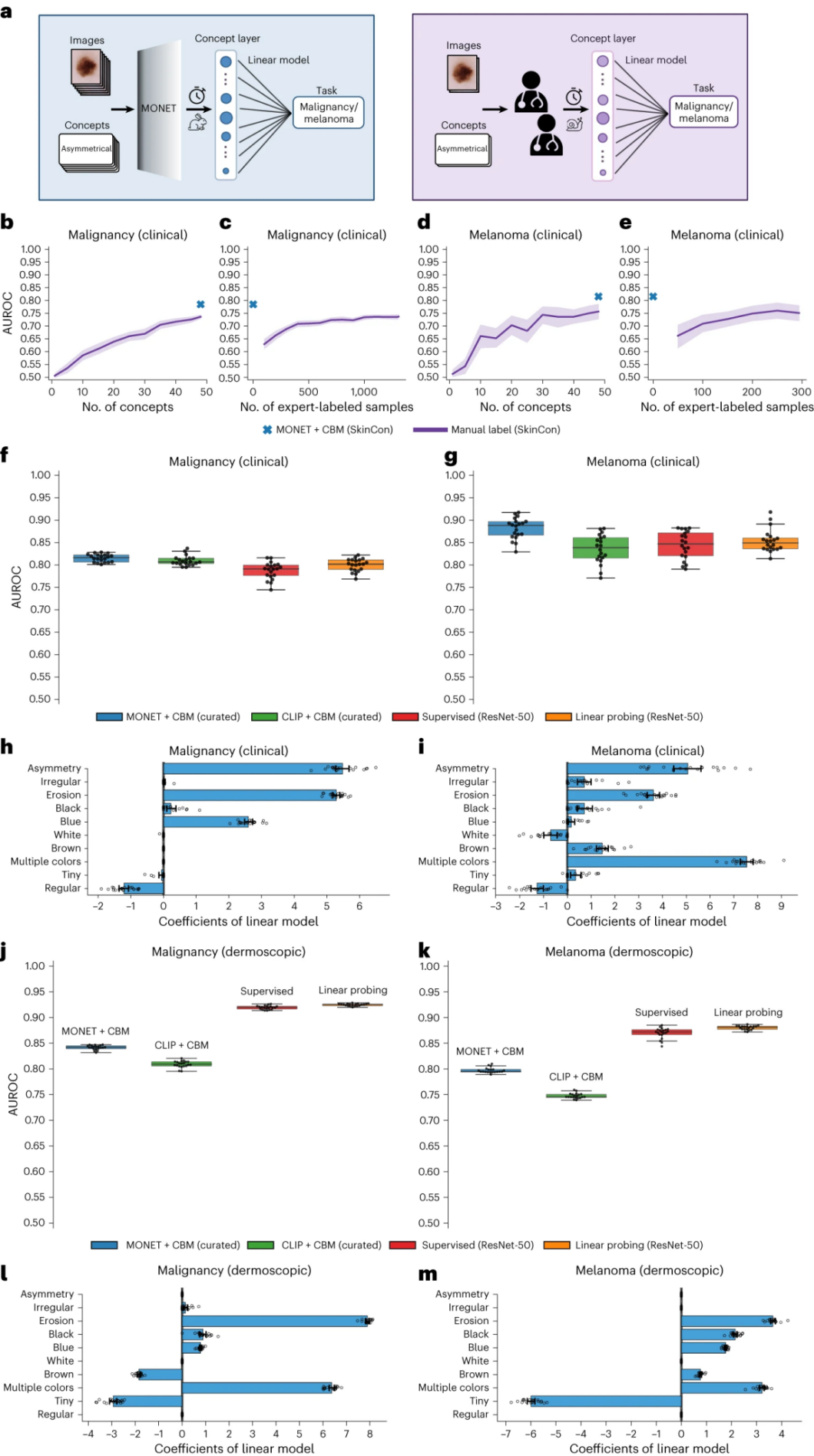
图 5
作者探索了MONET和CBMs在黑色素瘤和恶性预测中的应用,这是皮肤科AI模型最常见的预测任务。作者首先将作者的自动概念评分方法“MONET + CBM”(图5a)与手动标记方法(图5b)进行了比较。对于两个目标,手动方法的训练集大约是MONET + CBM的三分之一,因为它仅限于带有SkinCon标签的图像;MONET + CBM使用所有训练样本和概念,因为它可以自动注释概念,无需专家标记。作者观察到,访问更多的概念和样本提高了性能(图5b-e)。虽然随着数据增多,手动方法有所改进,但仍不及MONET + CBM,后者因样本量更大而受益。在从临床图像预测恶性和黑色素瘤方面,MONET + CBM在平均AUROC(恶性:0.815,黑色素瘤:0.881)和单侧配对的学生t检验(P < 0.01)方面胜过所有基线(图5f,g)。这证明了MONET能够创建既可解释又高性能的模型。作者还验证了MONET + CBM使用这些概念的方式是否与既定的临床规则一致(图5h,i)。在与临床图像相同的分析中,作者发现监督黑箱模型在恶性和黑色素瘤预测任务中始终表现更好(图5j-k)。作者对线性分类器的权重调查显示与先前知识大体一致(图5l,m);对于黑色素瘤预测,概念“糜烂”和“多种颜色”有高正权重,“微小”有高负权重,“蓝色”有正权重,这指的是在黑色素瘤中观察到的蓝白色面纱状斑的皮肤镜概念。
编译 | 于洲
审稿 | 王建民
参考资料
Kim C, Gadgil S U, DeGrave A J, et al. Transparent medical image AI via an image–text foundation model grounded in medical literature[J]. Nature Medicine, 2024: 1-12.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢