

【本工作由南大NLP实验室与华为翻译中心合作完成,论文链接:https://arxiv.org/abs/2405.13923,代码&数据:https://github.com/hy5468/TransLLM】

LLM在低资源语言上对话能力不足、安全性差,那么如何将一个经过RLHF训练的chat LLM迁移到低资源语言上呢?以往工作关注于迁移base LLM,在迁移同时或之后进行指令微调,因此指令微调注入的对话知识不会被迁移所影响。而chat LLM的对话和安全相关知识已经融入到模型参数中,在无法获得相关标注数据的情况下,进一步的迁移训练有可能会导致灾难性遗忘,反而表现不出对话和安全方面的能力。本工作中,我们提出了TransLLM框架(Figure2)。
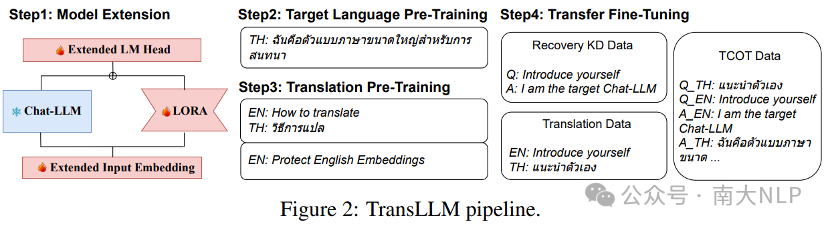
TransLLM将迁移问题建模为翻译思维链(TCOT),通过翻译任务桥接高资源和低资源语言,同时利用开源数据增强模型的基础能力,从而有效迁移对话能力。为了缓解灾难性遗忘,我们使用LoRA技术进行学习并冻结模型原有参数,同时使用chat LLM自己生成数据进行知识蒸馏(recovery KD)。以此让模型学会:利用冻结参数中的知识执行英语任务,从而保持原先模型具有的能力;利用更新参数中的知识进行迁移目标语言的任务。
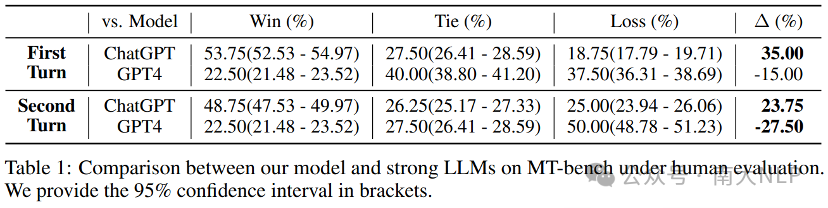
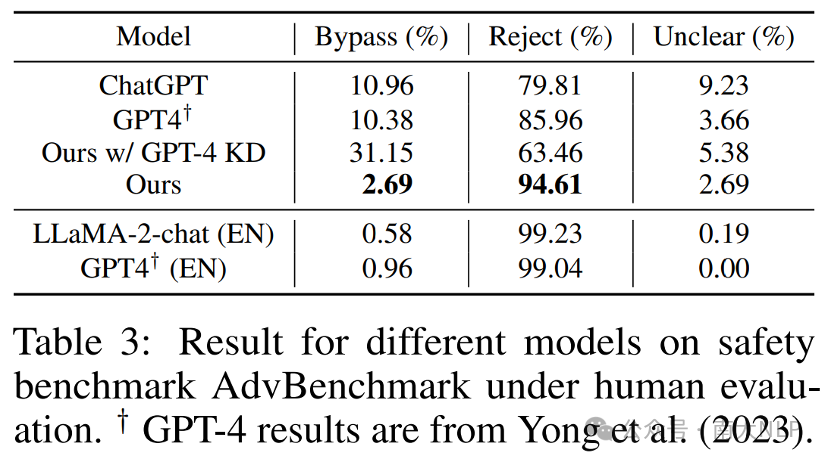
实验中我们尝试将LLaMA2-chat-7B迁移至泰语(TH)。在只使用单轮数据的情况下,我们在多轮对话评测集MT-Bench-TH的第一轮对话和第二轮对话中与ChatGPT相比分别超出35%和23.75% (Table1)。在不使用任何安全数据的情况下,TransLLM对有害泰语问题的拒绝率达到94.61%,高于ChatGPT的79.81%和GPT-4的85.96%,接近LLaMA2-chat对英语有害问题的拒绝率99.23%(Table3)。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢