

在过去的十年中,人工智能(AI)引起了工业界和学术界的极大兴趣。多年来,深度神经网络 (DNN) 模型的规模呈爆炸式增长。图形处理单元 (GPU) 和机器学习 (ML) 加速器的更广泛访问以及数据集大小的增加推动了这一增长。然而,在硬件上对此类模型在精度、峰值功耗、能耗和集成电路芯片面积方面进行有效评估仍然具有挑战性,需要较长的设计周期和领域专业知识。增加模型尺寸会加剧这个问题。在本文中,我们从不同角度提出了一套针对这一挑战的框架。我们提出了 FlexiBERT,这是第一个用于异构和灵活 Transformer架构的大规模设计空间。然后我们提出了 AccelTran,一种最先进的 Transformer 加速器。受 AccelTran 的启发,我们提出了 ELECTOR,一个Transformer加速器的设计空间,并利用我们的协同设计技术(即 BOSHCODE)实现Transformer-加速器协同设计。我们还提出了 EdgeTran,这是一种联合搜索技术,用于找出性能最佳的对,即Transformer模型和边缘人工智能设备。我们也将此框架应用于卷积神经网络(CNN)(CODEBench)。最后,我们讨论 BOSHCODE 的两个扩展:用于数据插补的 DINI 和用于向量和图搜索空间中的通用多目标优化的 BREATHE。这些工作将所提出的方法的范围扩展到更多样化的应用程序。

论文题目:Enhancing Deep Neural Networks in Diverse Resource-Constrained Hardware Settings
作者:Tuli, Shikhar
类型:2024年博士论文
学校:Princeton University(美国普林斯顿大学)
下载链接:
链接: https://pan.baidu.com/s/1hspL_CmLCc8bgvp3uFx-Qg?pwd=5skn
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
Software Availability
All code, datasets, and result reproduction scripts developed as part of this thesis have been made open-source under the BSD 3.0 license. A list of repository links for each published work is given below.
FlexiBERT Ch. 3 https://github.com/jha-lab/txf_design-space
AccelTran Ch. 4 https://github.com/jha-lab/acceltran
TransCODE Ch. 5 https://github.com/jha-lab/transcode
CODEBench Ch. 3, 4, 5 https://github.com/jha-lab/cnn_design-space
https://github.com/jha-lab/codebench
EdgeTran* Ch. 3, 4, 5 https://github.com/jha-lab/edgetran
https://github.com/jha-lab/protran
DINI Ch. 6 https://github.com/jha-lab/dini
BREATHE* Ch. 6 https://github.com/jha-lab/breathe
 在各个领域消除本论文标题的歧义。
在各个领域消除本论文标题的歧义。
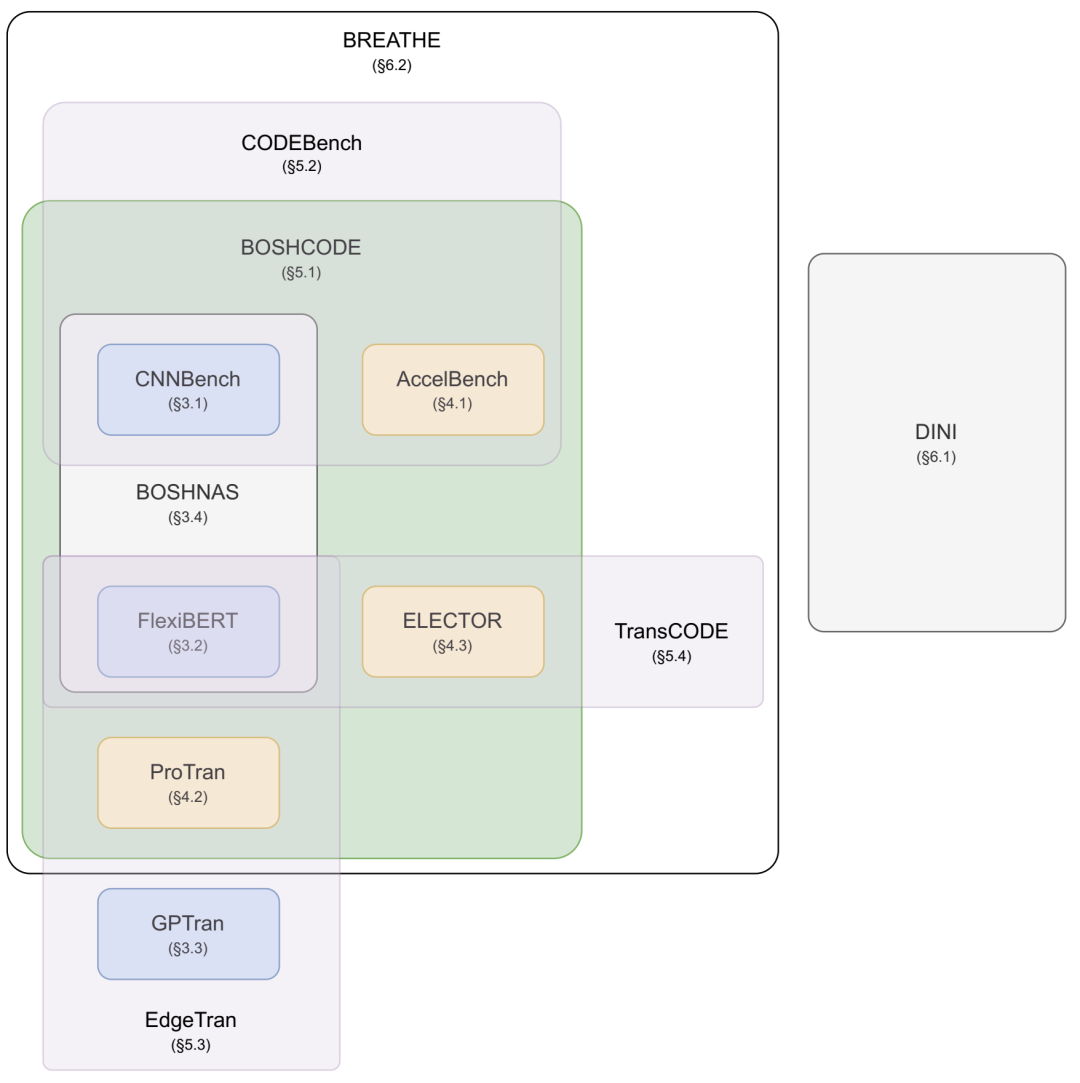 提议的框架和相应部分。
提议的框架和相应部分。
 CNNBench 管道不同部分的流程图。
CNNBench 管道不同部分的流程图。
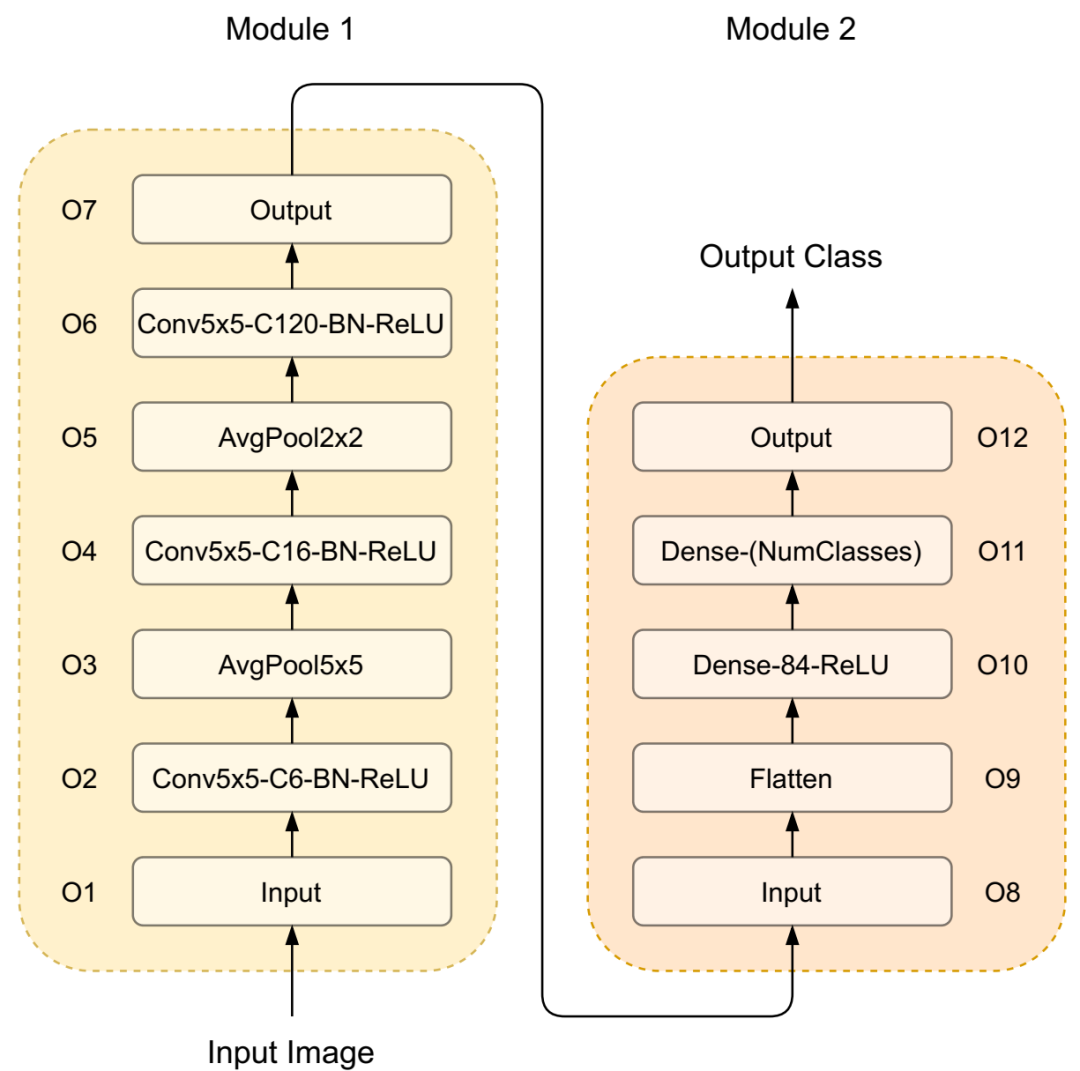 CNNBench 设计空间中 LeNet 的计算图。Dense-(NumClasses) 是基于给定数据集的输出类数量的前馈层。如果没有提及,Stride 和 padding 默认为 1。
CNNBench 设计空间中 LeNet 的计算图。Dense-(NumClasses) 是基于给定数据集的输出类数量的前馈层。如果没有提及,Stride 和 padding 默认为 1。
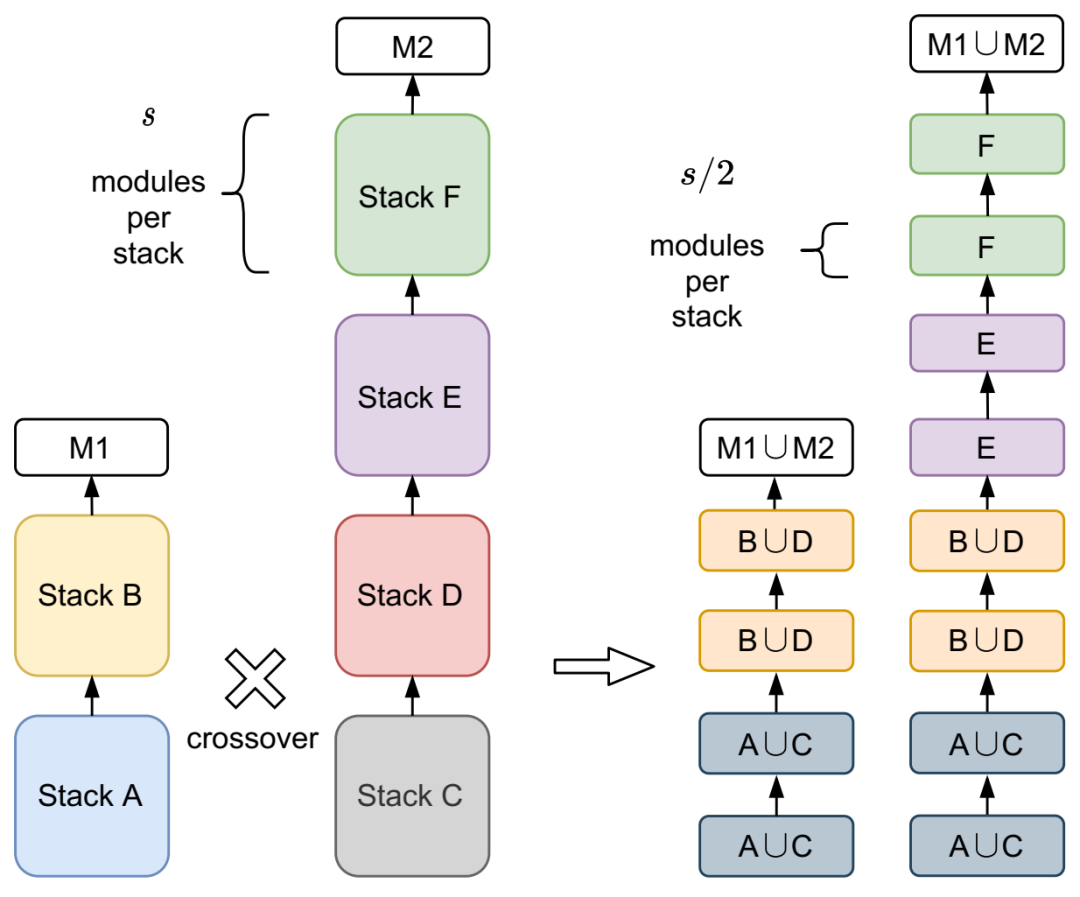
相邻模型之间的交叉。新模型是通过在每个堆栈深度(其中每个堆栈的模块数量为 s)创建局部设计空间并以堆栈大小的一半 (s/2) 创建操作组合来生成的,以获得更大的粒度。MLP 头分别用 M1 和 M2 表示。
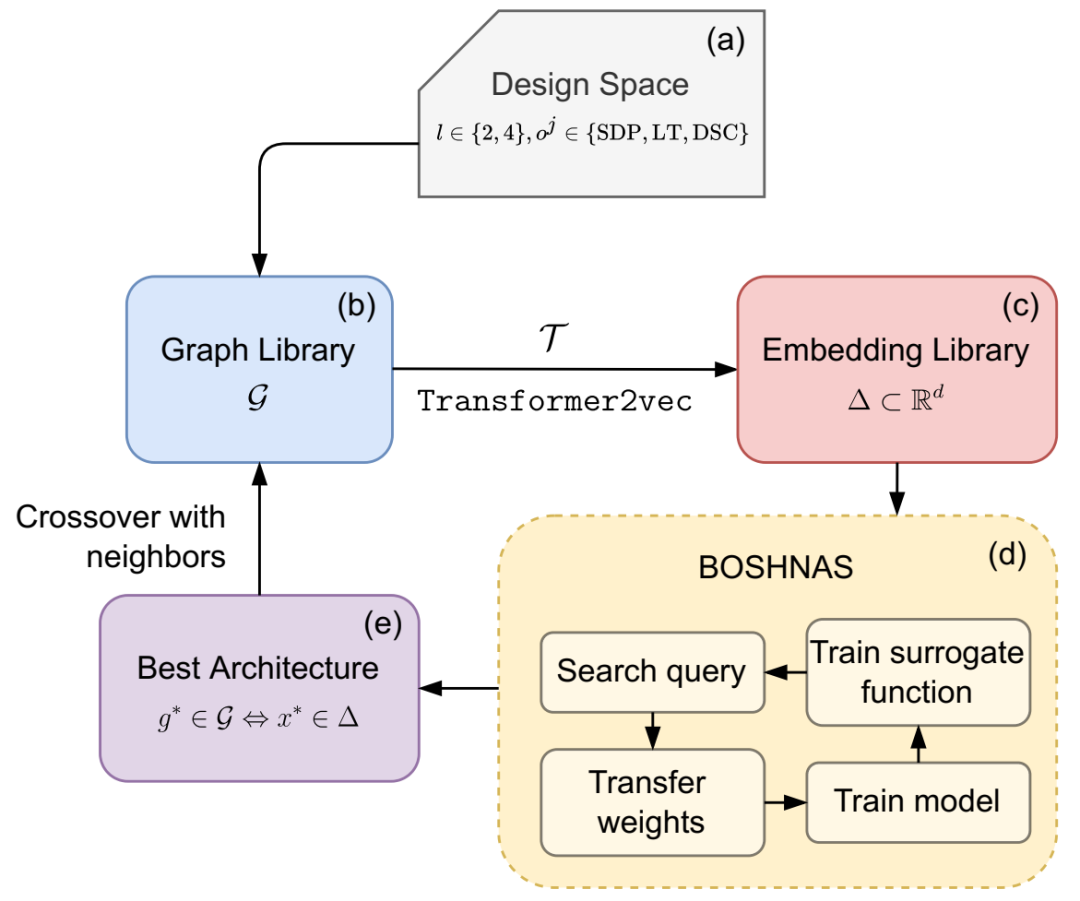 FlexiBERT 流程概览。
FlexiBERT 流程概览。
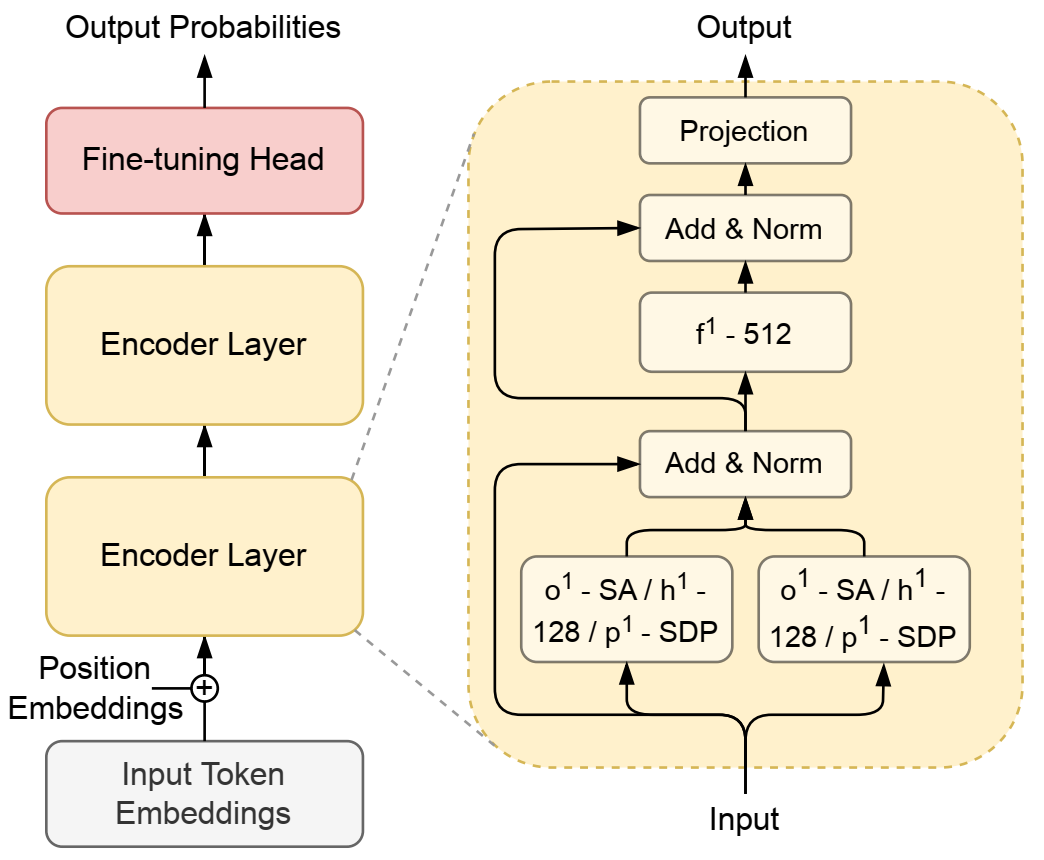 FlexiBERT 中 BERT-Tiny 的块级计算图。由于输入和输出编码器层的隐藏大小相等,因此投影层实现恒等函数。
FlexiBERT 中 BERT-Tiny 的块级计算图。由于输入和输出编码器层的隐藏大小相等,因此投影层实现恒等函数。
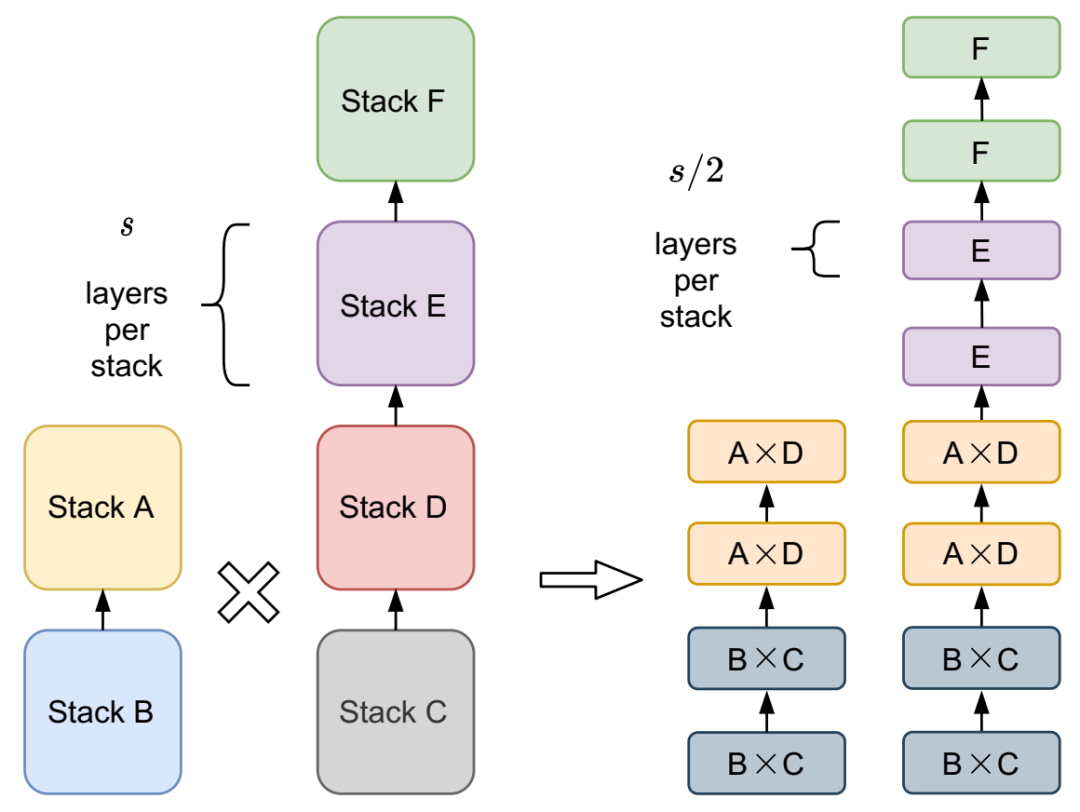 两个父模型之间的交叉产生了更细粒度的设计空间。子级中的每个堆栈配置都源自相同深度的父级设计选择的乘积。
两个父模型之间的交叉产生了更细粒度的设计空间。子级中的每个堆栈配置都源自相同深度的父级设计选择的乘积。
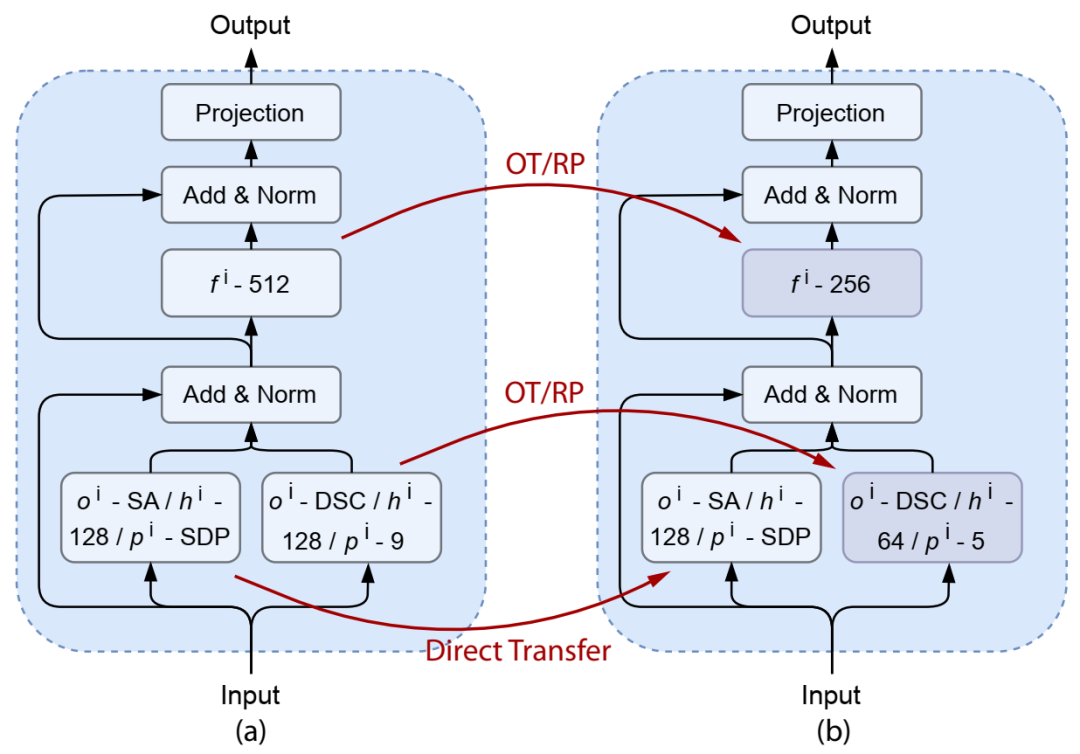 FlexiBERT 2.0 中两个相邻模型之间的权重转移。
FlexiBERT 2.0 中两个相邻模型之间的权重转移。

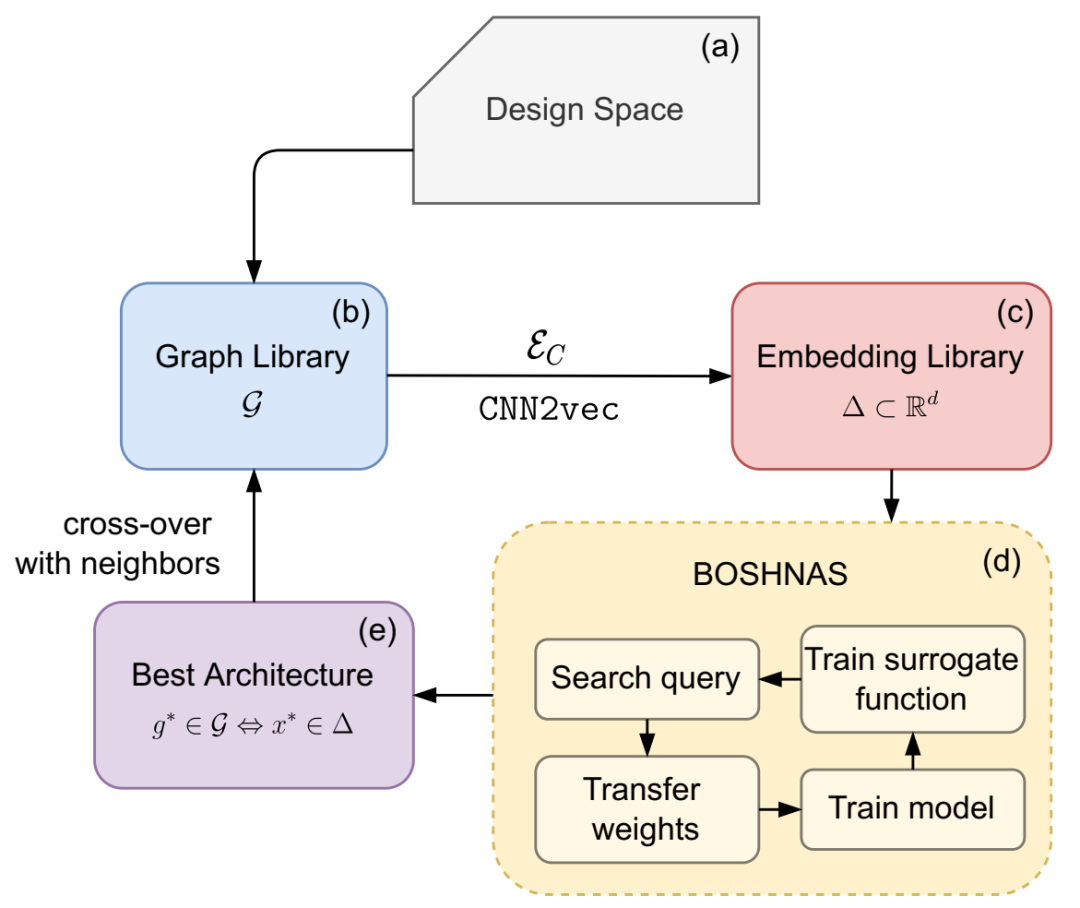
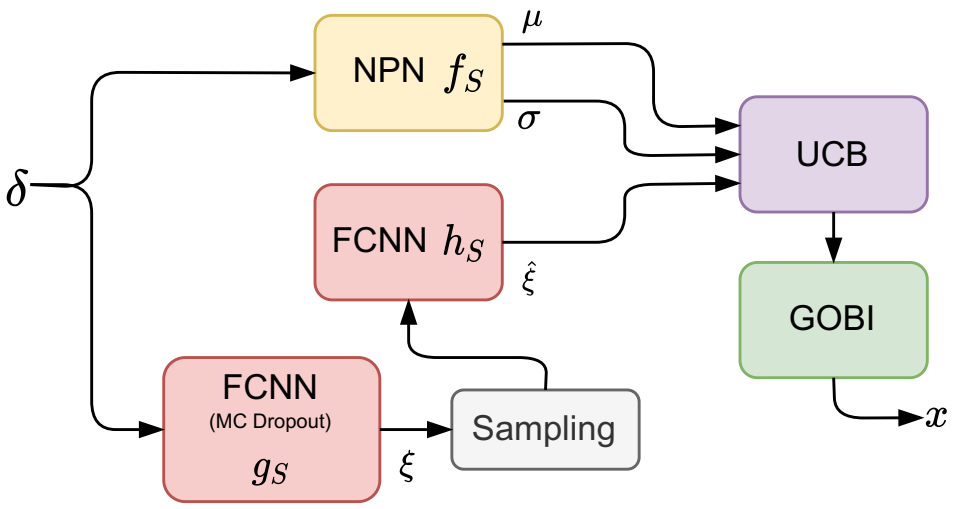 BOSHNAS 流程概述。
BOSHNAS 流程概述。
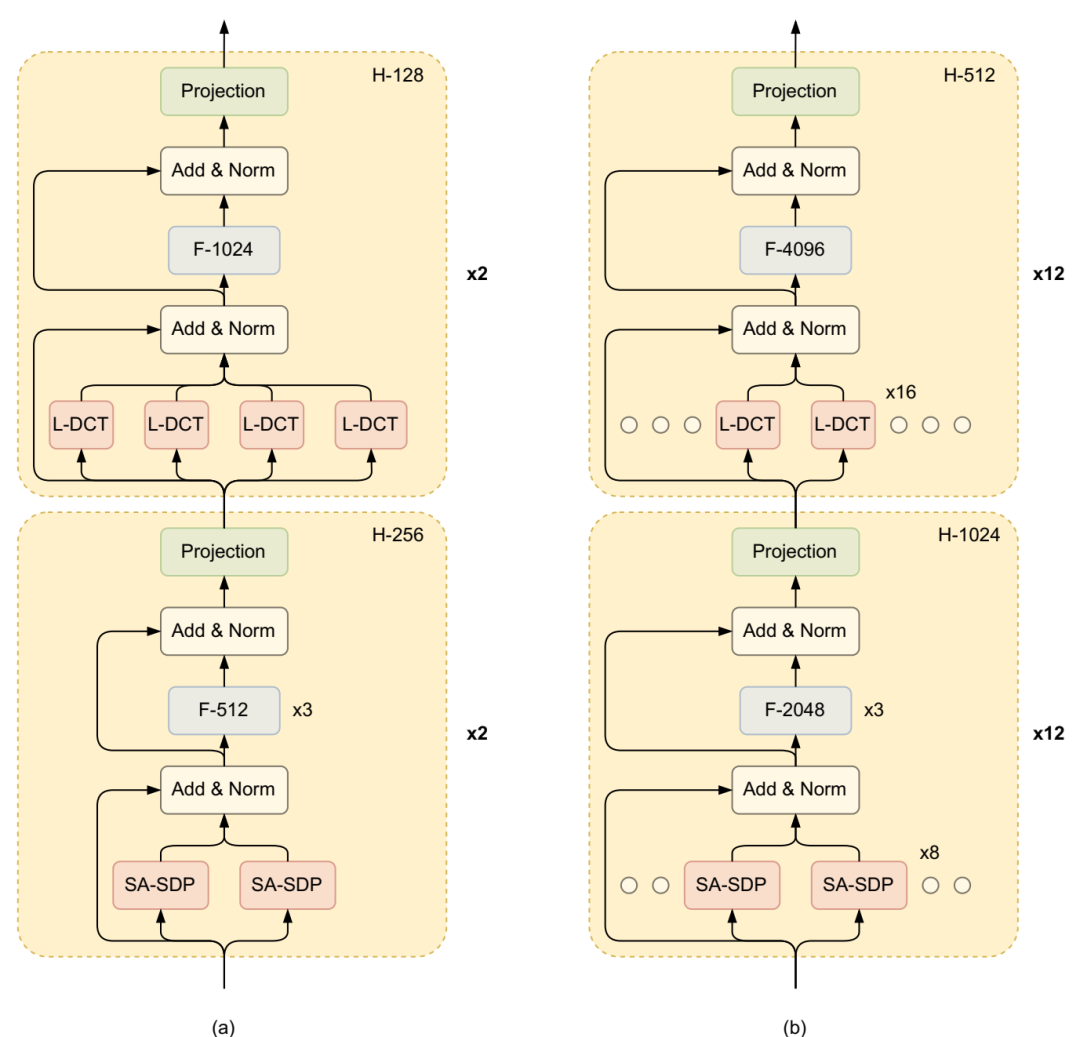 运行 BOSHNAS 管道后获得 FlexiBERT 模型:(a) FlexiBERT-Mini 及其设计选择推断以获得 (b) FlexiBERT-Large。
运行 BOSHNAS 管道后获得 FlexiBERT 模型:(a) FlexiBERT-Mini 及其设计选择推断以获得 (b) FlexiBERT-Large。
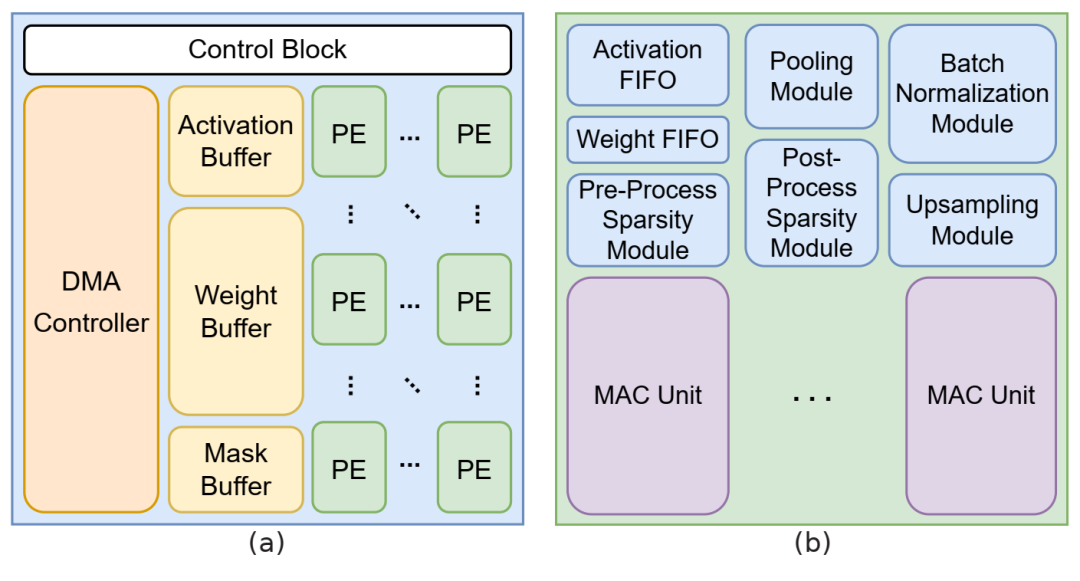 加速器/PE:(a) AccelBench 中加速器的通用布局。(b) AccelBench 加速器中 PE 的布局。
加速器/PE:(a) AccelBench 中加速器的通用布局。(b) AccelBench 加速器中 PE 的布局。
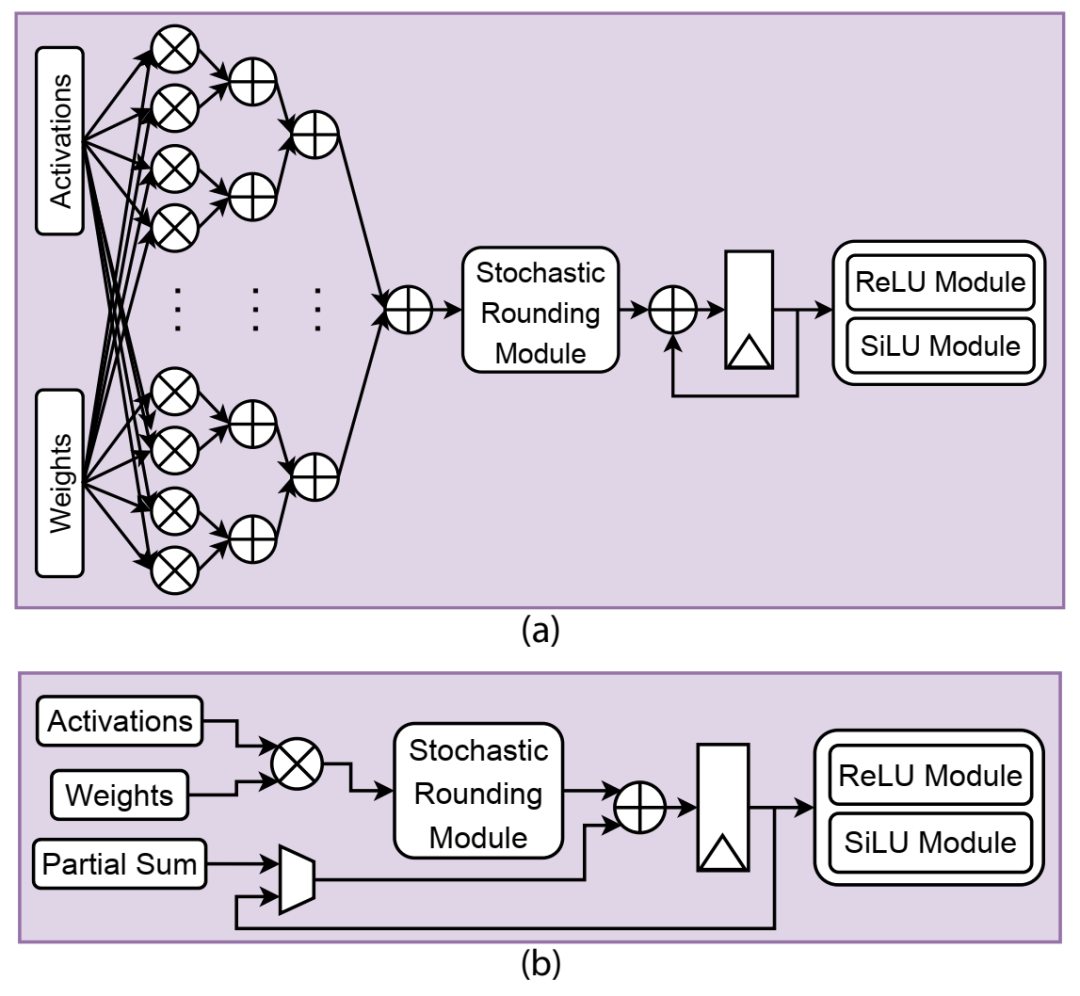 两个不同 MAC 单元的布局:(a) 16 乘法器,(b) 1 乘法器。
两个不同 MAC 单元的布局:(a) 16 乘法器,(b) 1 乘法器。
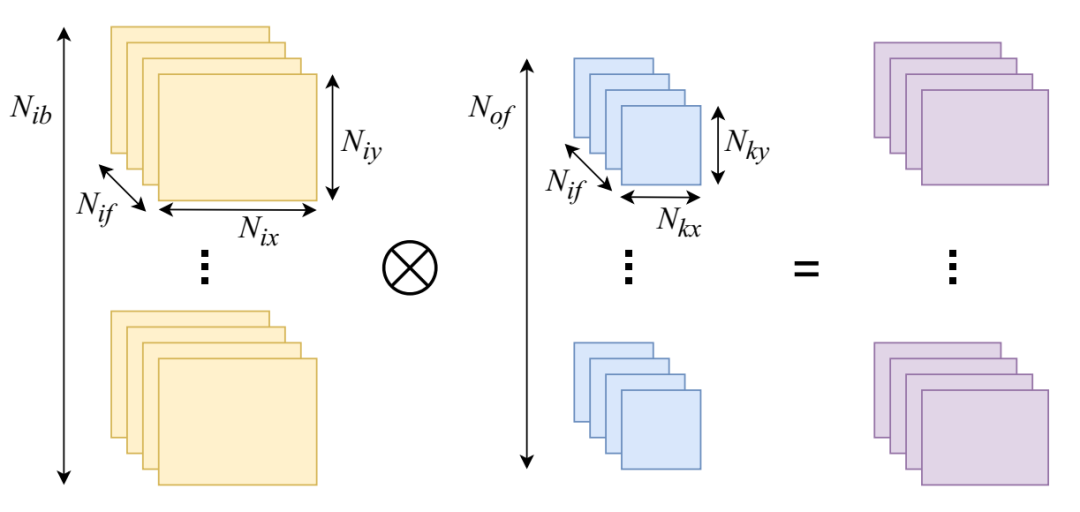 CNN 的卷积层。
CNN 的卷积层。
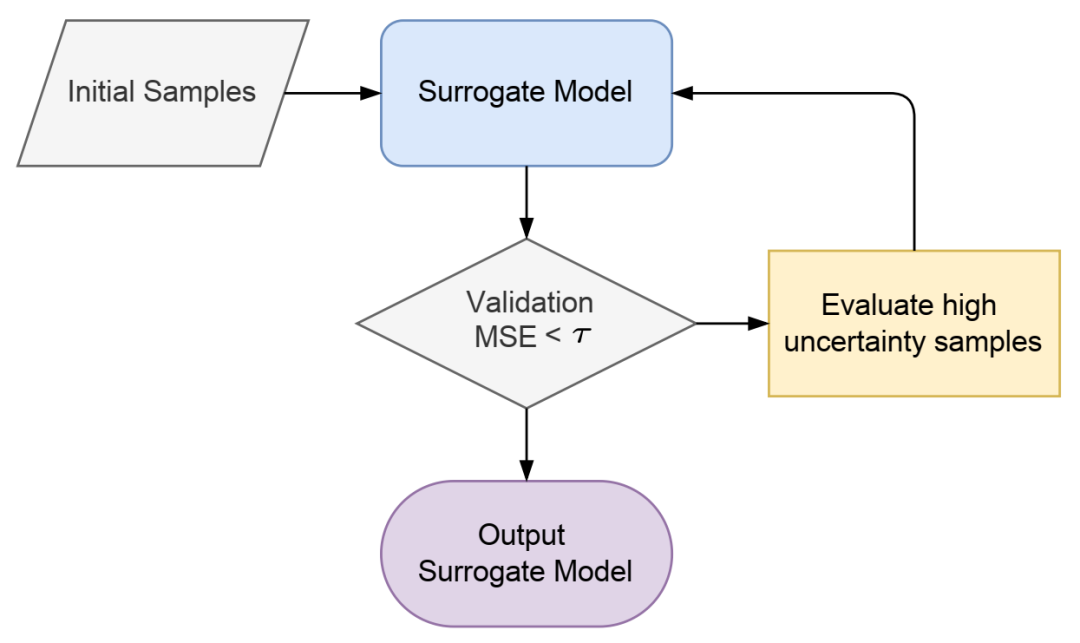 ProTran 的主动学习管道。
ProTran 的主动学习管道。
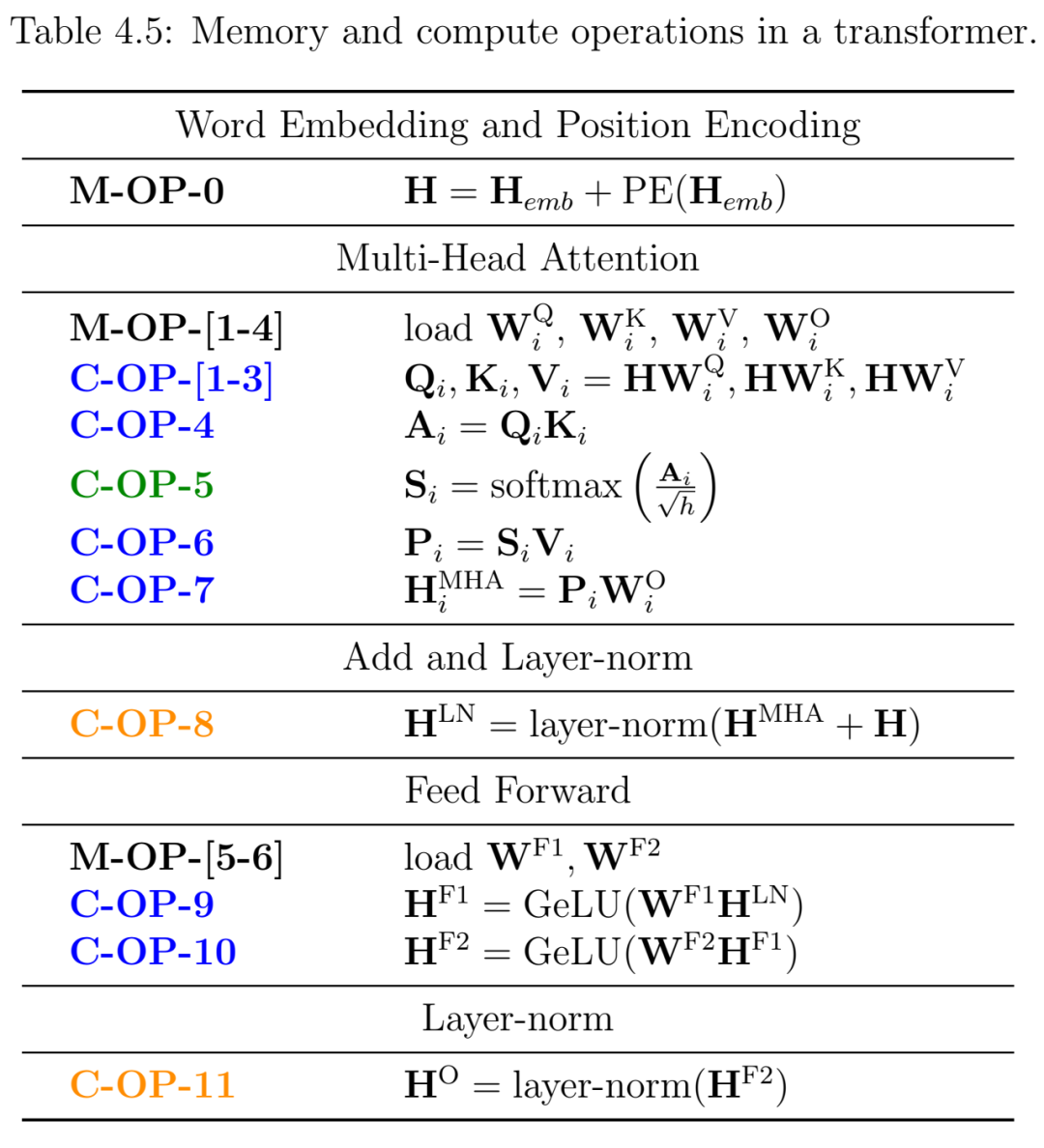
Transformer 中的内存和计算操作。
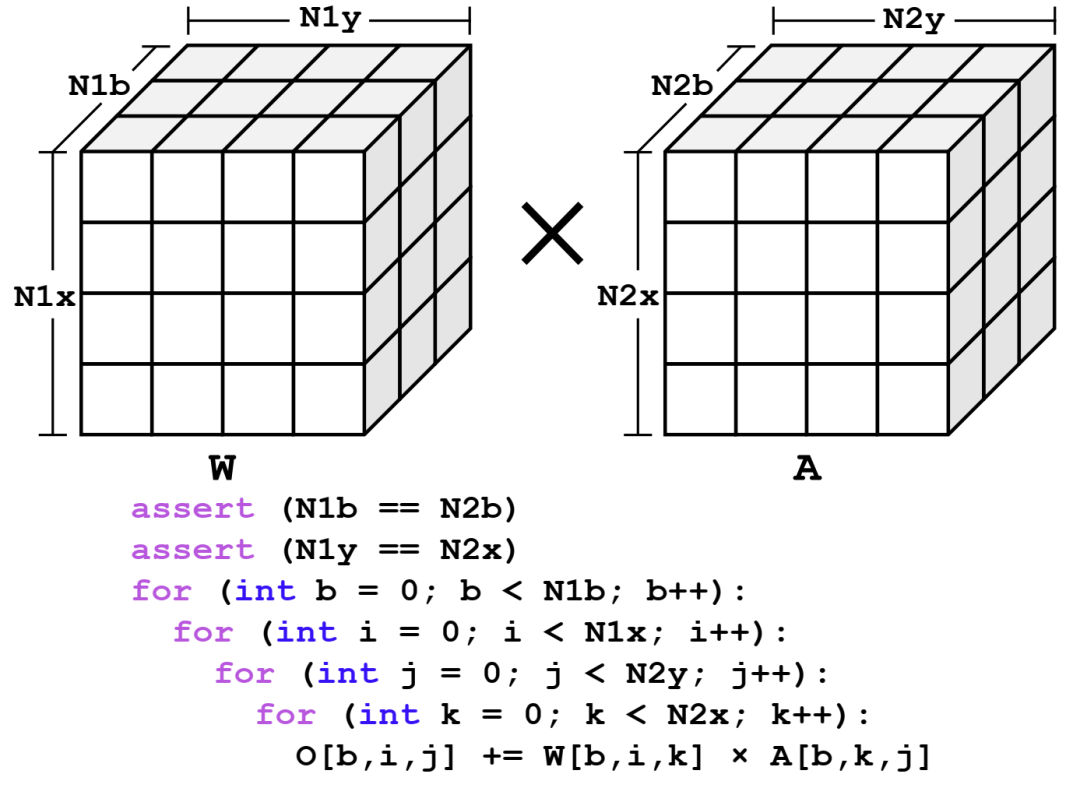 矩阵乘法运算与选定数据流(具体来说,[b,i,j,k])的平铺。这里显示的是一个张量,第一个维度是批量大小。
矩阵乘法运算与选定数据流(具体来说,[b,i,j,k])的平铺。这里显示的是一个张量,第一个维度是批量大小。
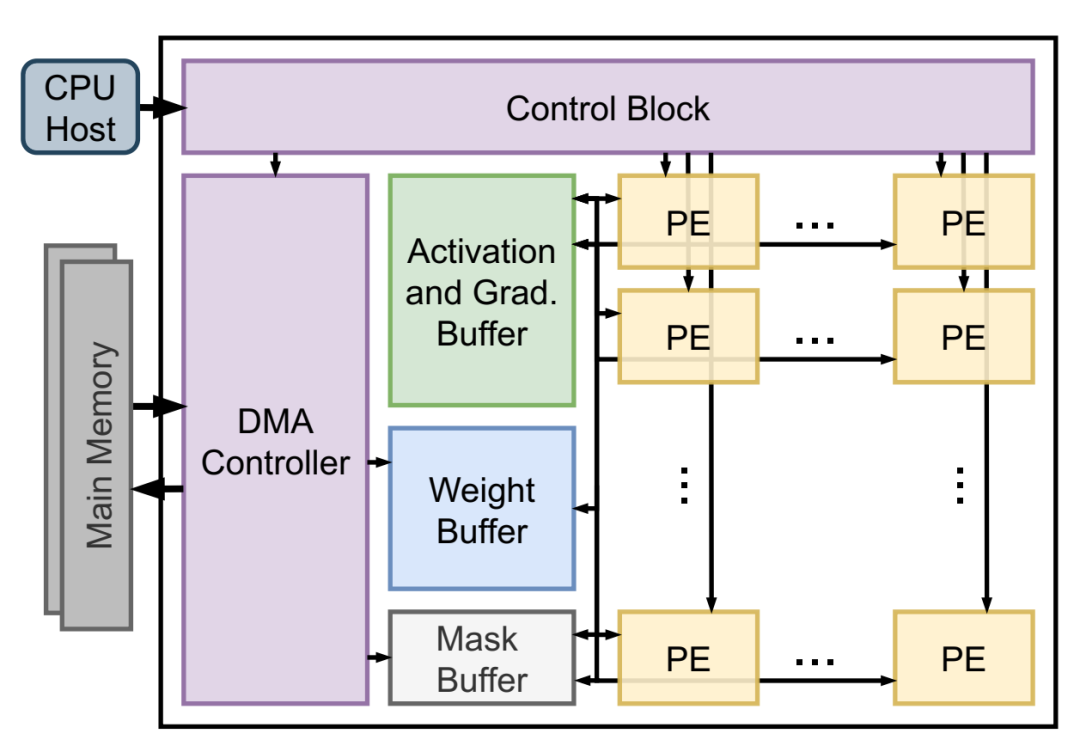
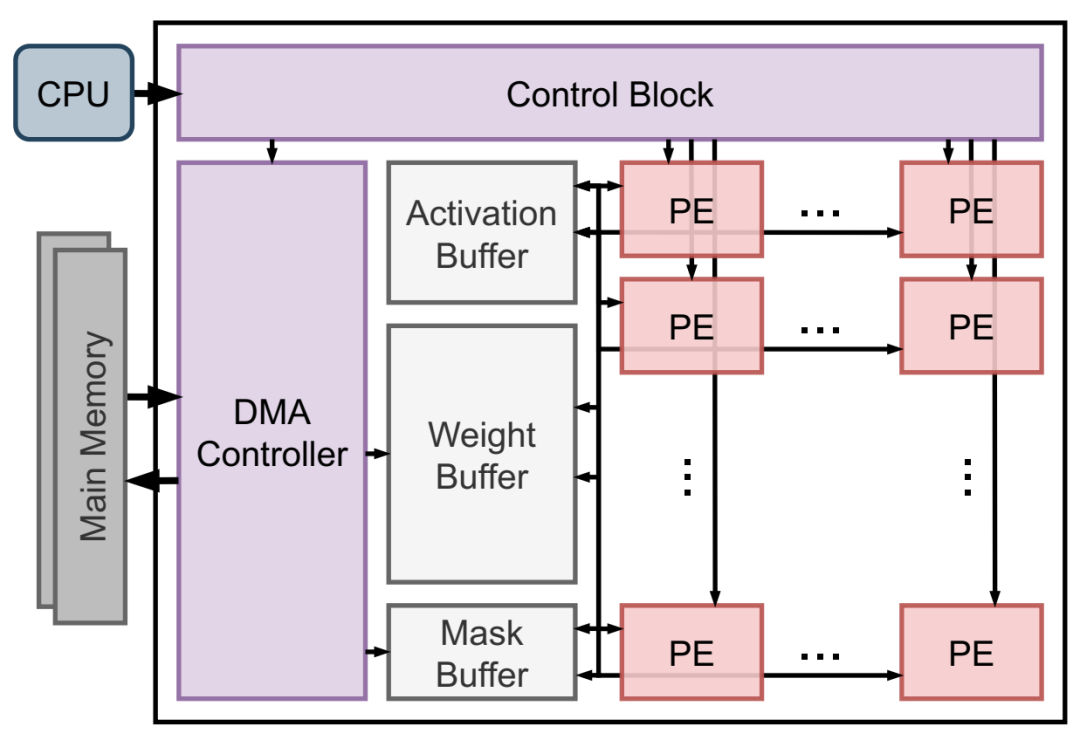 加速器架构。
加速器架构。
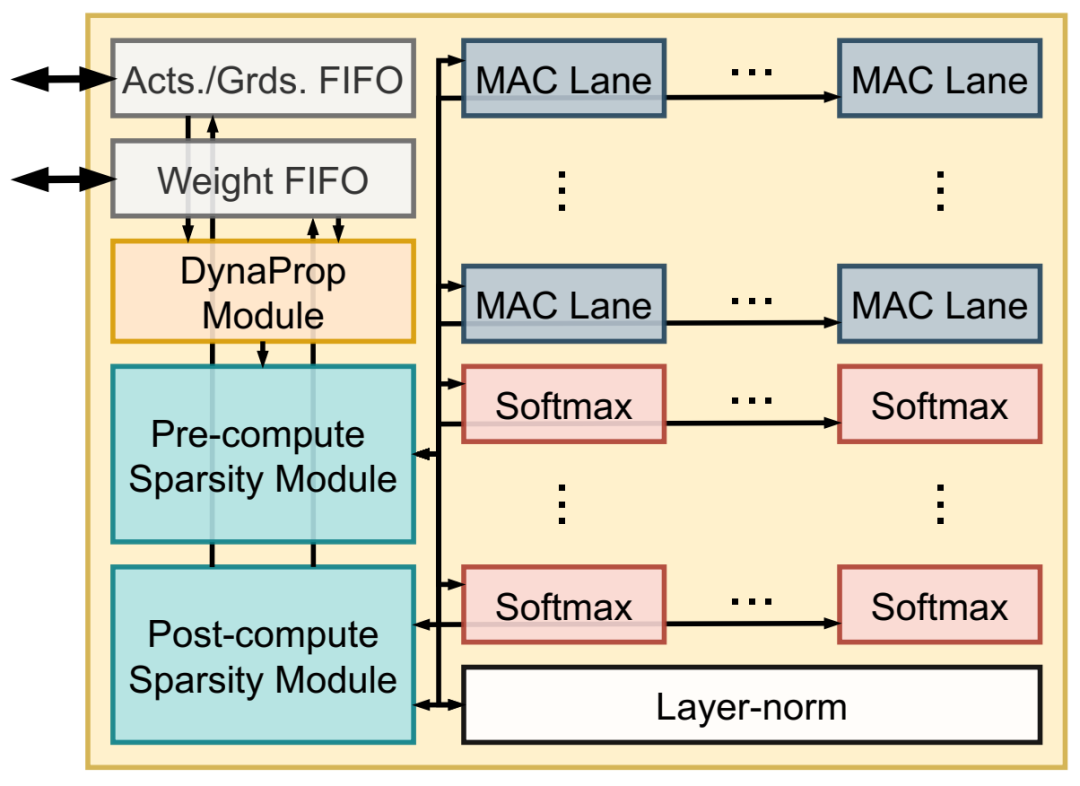 PE 的内部组件。
PE 的内部组件。
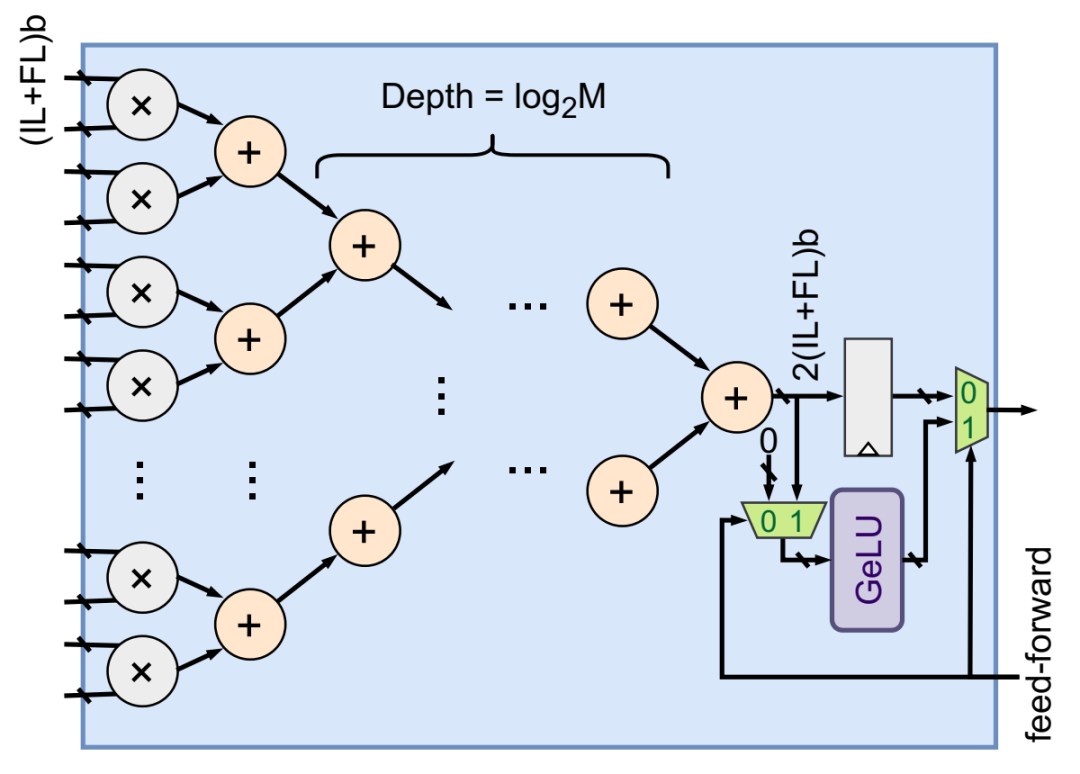 MAC 通道的架构。
MAC 通道的架构。
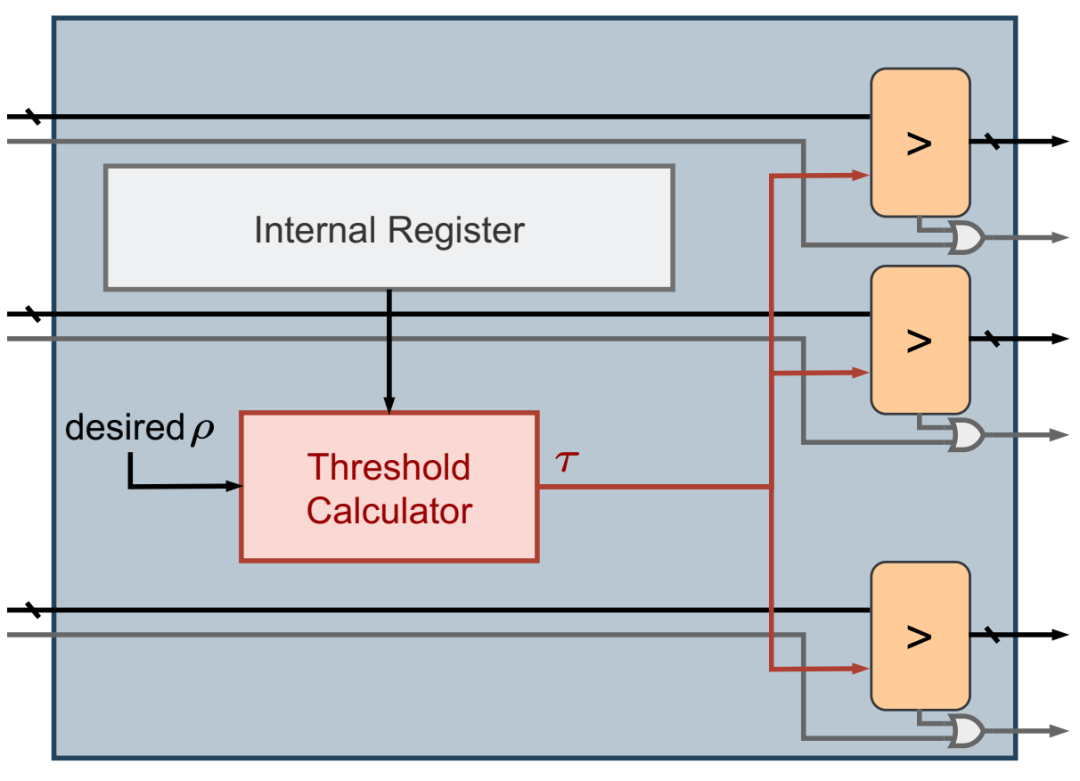 DynaTran 模块。掩码位的电线为灰色。
DynaTran 模块。掩码位的电线为灰色。
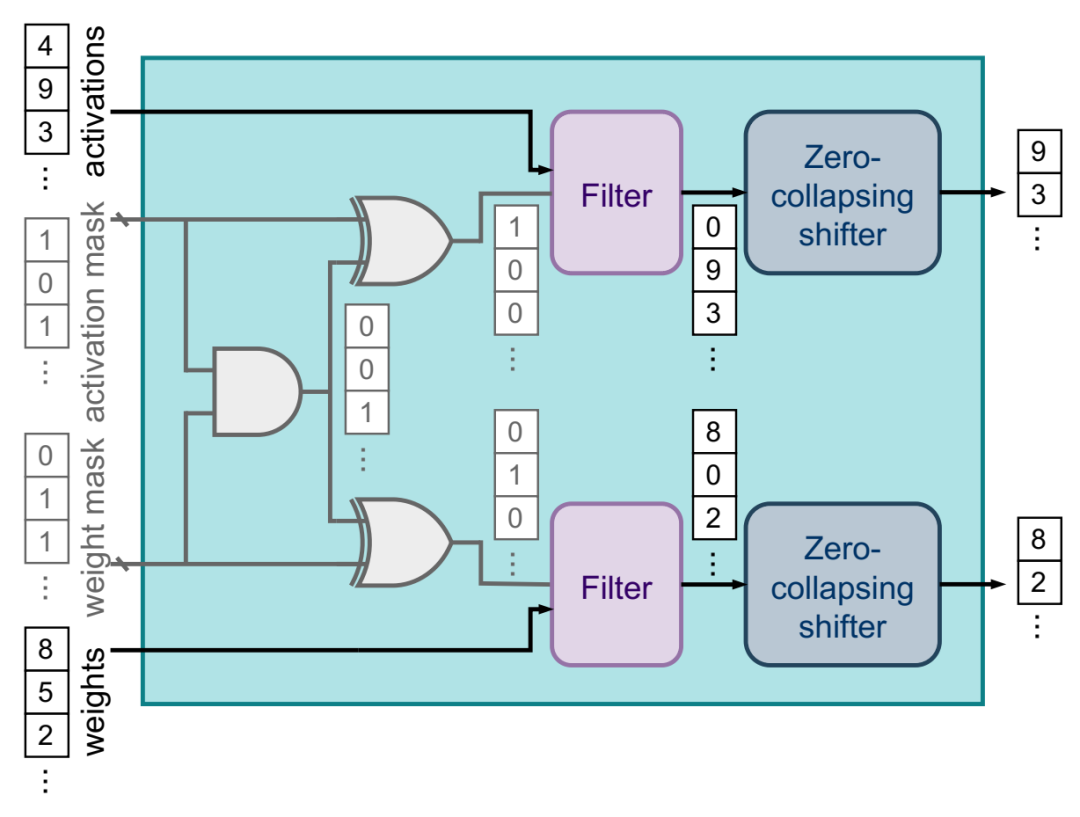 预先计算稀疏性模块。
预先计算稀疏性模块。
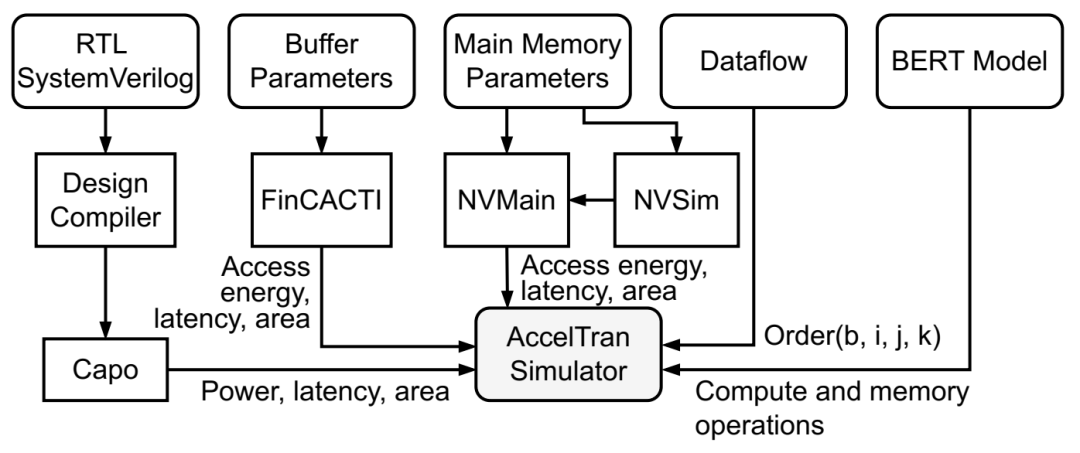 AccelTran 中的模拟流程。
AccelTran 中的模拟流程。
 ELECTOR 设计空间中典型加速器的组织。
ELECTOR 设计空间中典型加速器的组织。
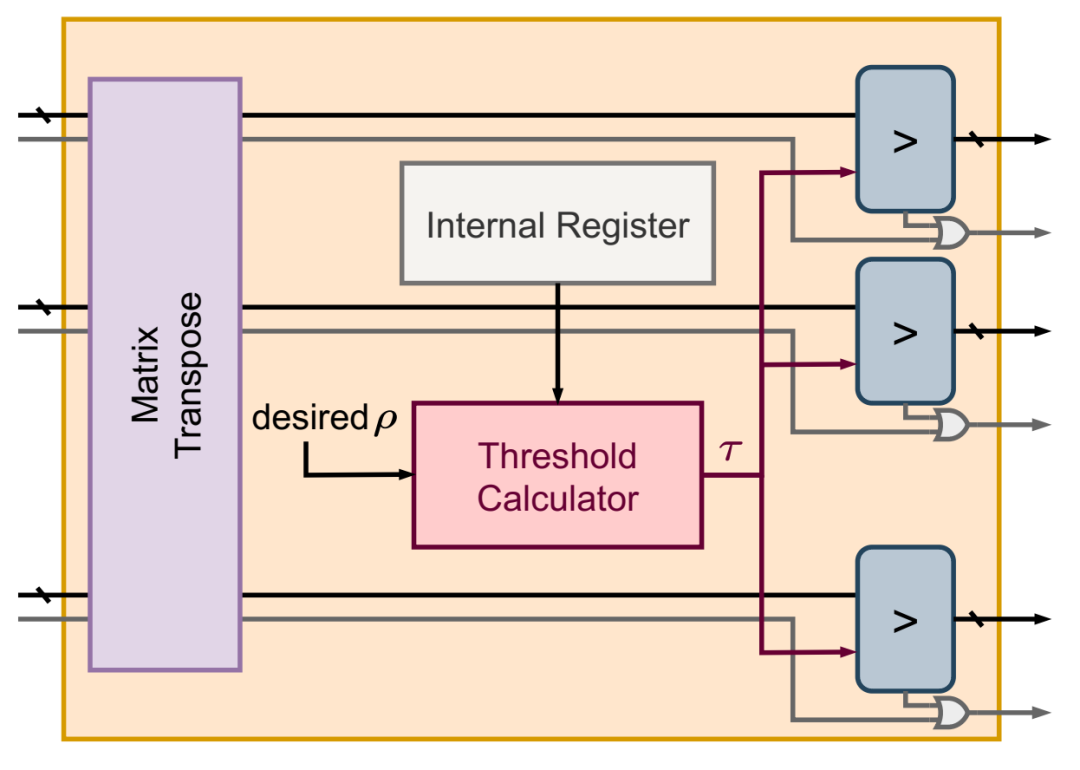 DynaProp 模块的实现。掩码位的电线为灰色。
DynaProp 模块的实现。掩码位的电线为灰色。
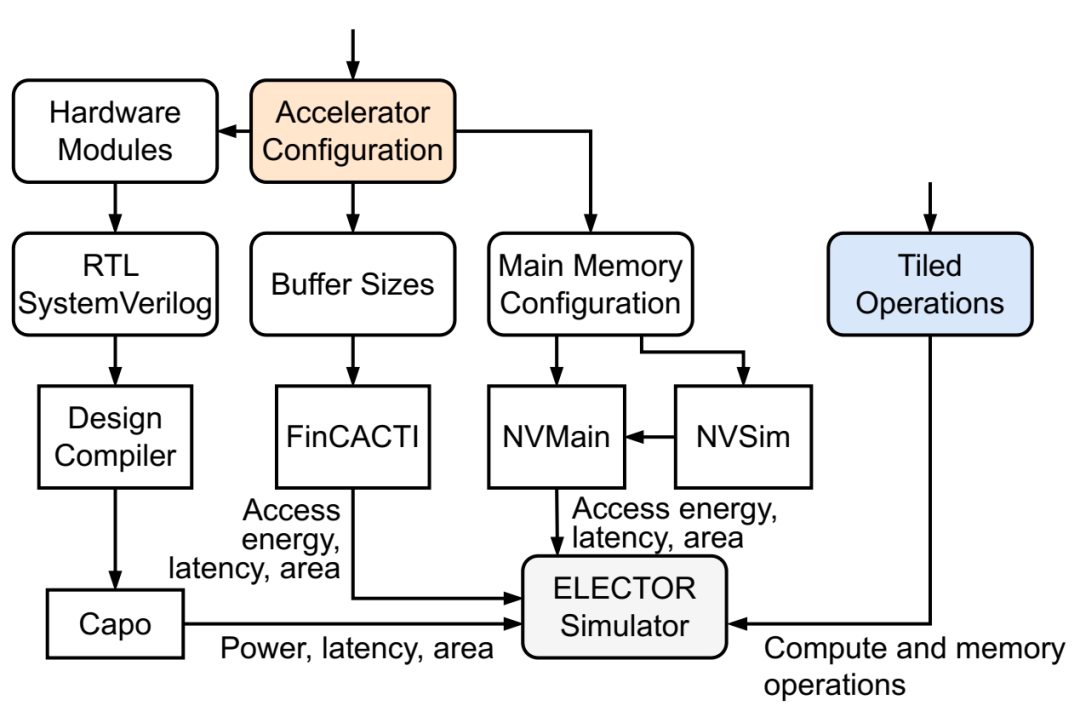 ELECTOR 中的模拟流程。
ELECTOR 中的模拟流程。
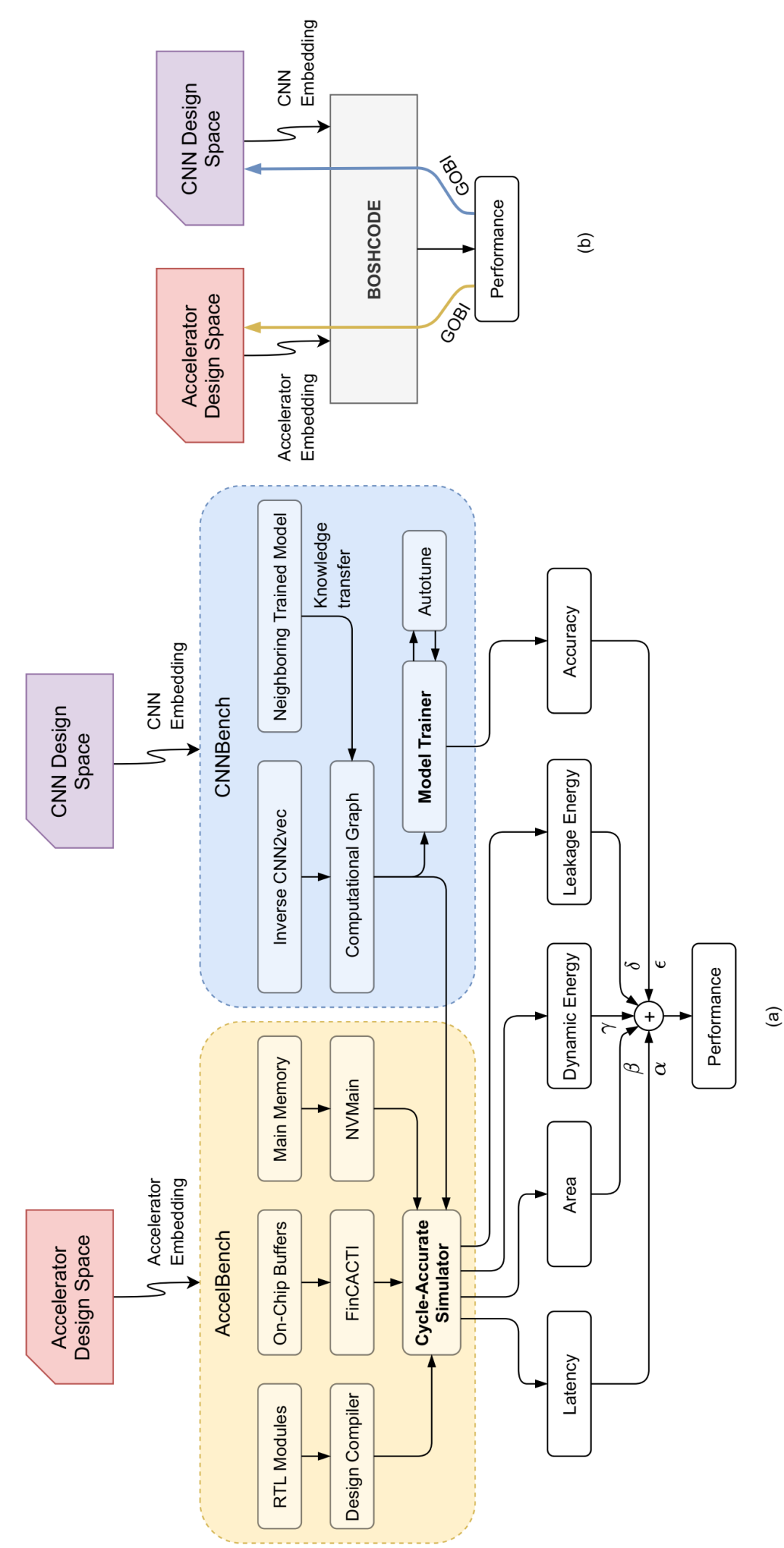 CODEBench 管道,包括 CNNBench、AccelBench 和新颖的协同设计方法 BOSHCODE:(a) 对 CNN 和加速器设计空间进行采样,以获得使用 CNNBench 和 AccelBench 框架进行模拟的新颖 CNN-加速器对。(b) BOSHCODE 从这些设计空间中学习代理函数来预测每个 CNN 加速器对的性能,实现 GOBI 来预测主动学习框架中要模拟的下一对。
CODEBench 管道,包括 CNNBench、AccelBench 和新颖的协同设计方法 BOSHCODE:(a) 对 CNN 和加速器设计空间进行采样,以获得使用 CNNBench 和 AccelBench 框架进行模拟的新颖 CNN-加速器对。(b) BOSHCODE 从这些设计空间中学习代理函数来预测每个 CNN 加速器对的性能,实现 GOBI 来预测主动学习框架中要模拟的下一对。
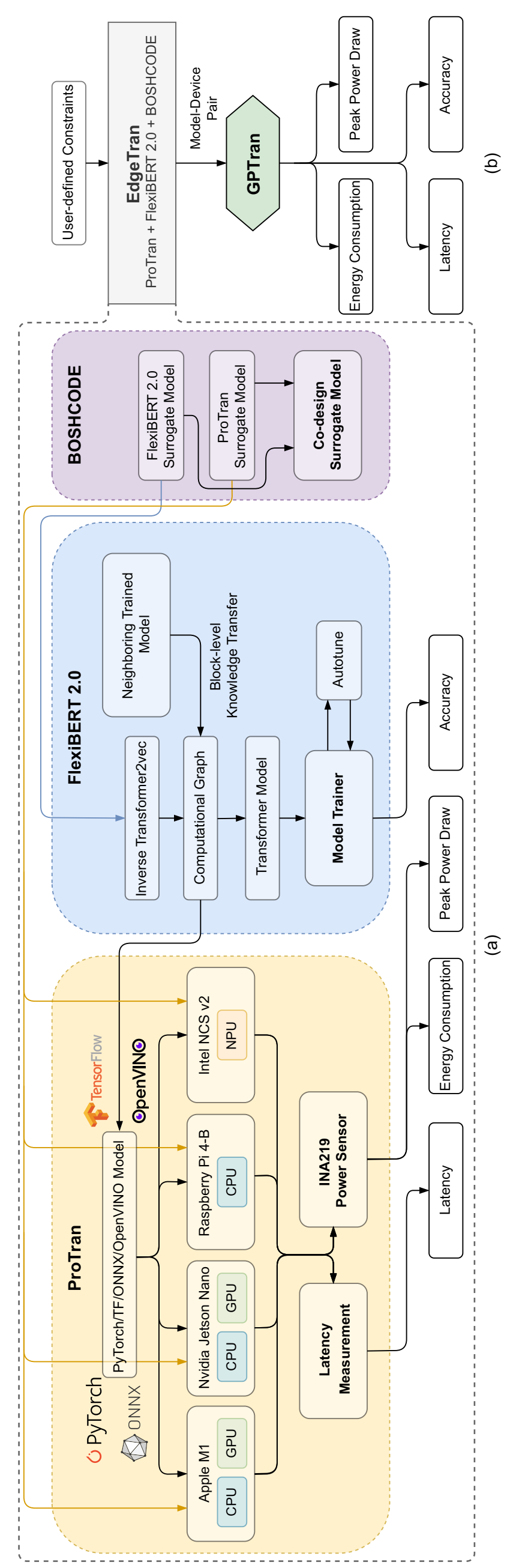 EdgeTran 框架概述:(a) ProTran 与 FlexiBERT 2.0 结合使用,对不同嵌入式平台的延迟、能耗和峰值功耗(硬件测量)进行建模,并使用 BOSHCODE 进行协同设计。(b) EdgeTran 采用从 ProTran 和 FlexiBERT 2.0 获得的代理模型来获得性能最佳的模型-设备对。我们将此模型转发给 GPTran 进行后处理和进一步优化。
EdgeTran 框架概述:(a) ProTran 与 FlexiBERT 2.0 结合使用,对不同嵌入式平台的延迟、能耗和峰值功耗(硬件测量)进行建模,并使用 BOSHCODE 进行协同设计。(b) EdgeTran 采用从 ProTran 和 FlexiBERT 2.0 获得的代理模型来获得性能最佳的模型-设备对。我们将此模型转发给 GPTran 进行后处理和进一步优化。
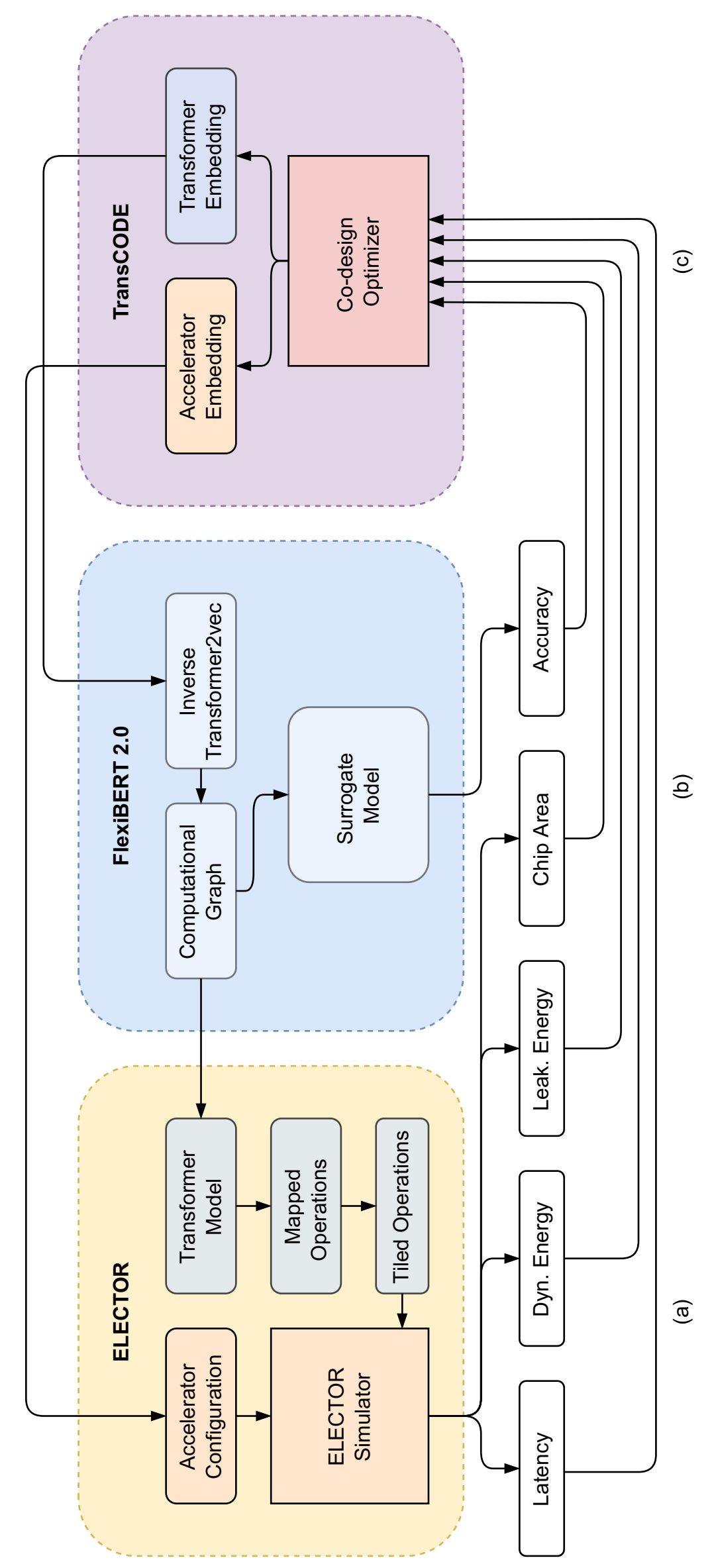 TransCODE 框架概述。(a) ELECTOR 采用加速器嵌入和Transformer计算图来模拟其在给定加速器上的训练/推理。(b) FlexiBERT 2.0 将输入Transformer嵌入转换为计算图,并采用预先训练的代理模型来预测模型精度。(c) TransCODE 优化器采用先前评估的Transformer加速器对的性能值来查询主动学习循环中的另一对。
TransCODE 框架概述。(a) ELECTOR 采用加速器嵌入和Transformer计算图来模拟其在给定加速器上的训练/推理。(b) FlexiBERT 2.0 将输入Transformer嵌入转换为计算图,并采用预先训练的代理模型来预测模型精度。(c) TransCODE 优化器采用先前评估的Transformer加速器对的性能值来查询主动学习循环中的另一对。
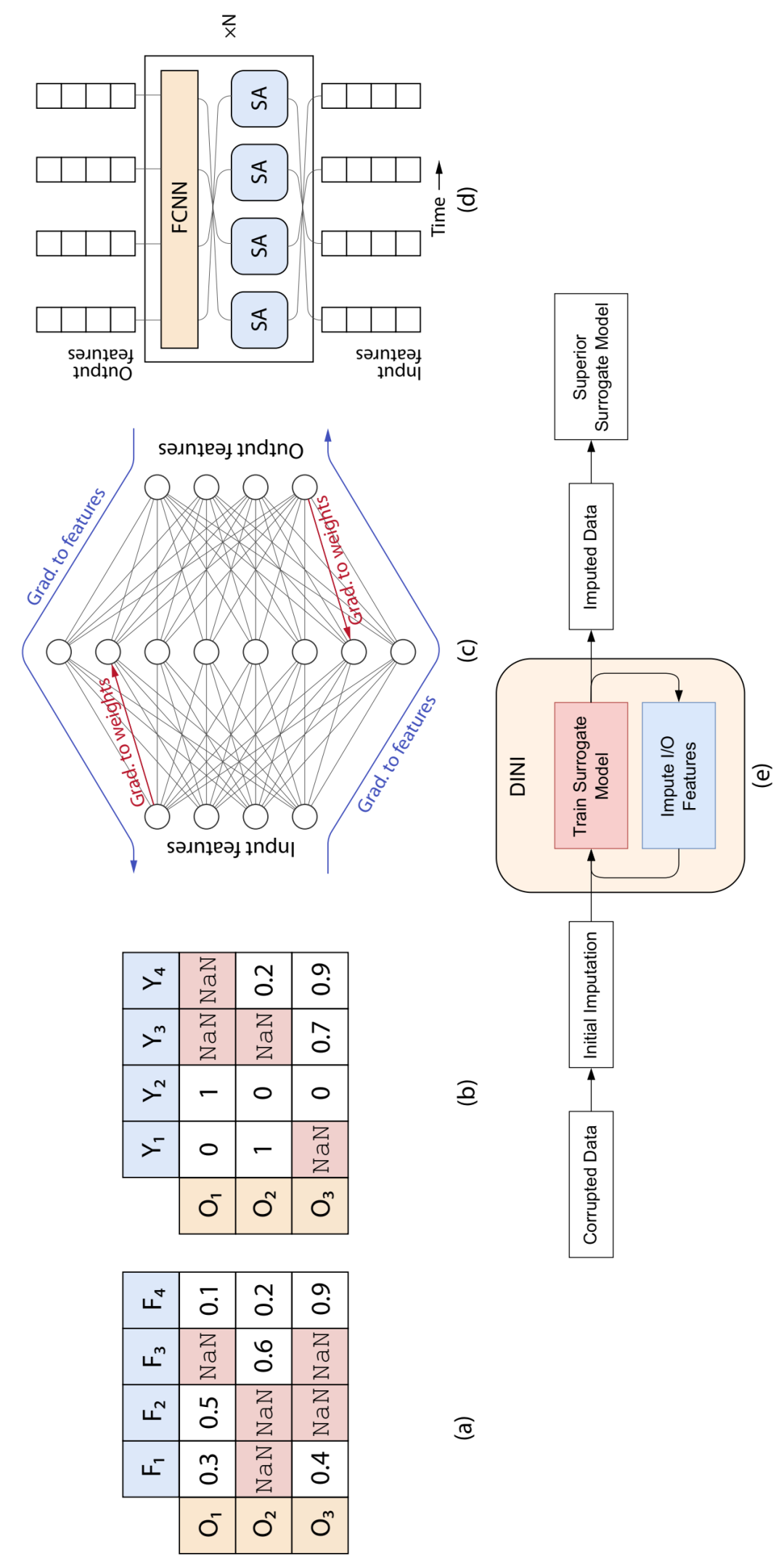 DINI 基于 DNN 的数据插补和代理建模框架。示例 (a) 输入和 (b) 输出表格数据。支持的代理模型:(c) 基于 FCNN 和 (d) 基于 Transformer 的时间序列数据。(e) DINI 管道的高级示意图。
DINI 基于 DNN 的数据插补和代理建模框架。示例 (a) 输入和 (b) 输出表格数据。支持的代理模型:(c) 基于 FCNN 和 (d) 基于 Transformer 的时间序列数据。(e) DINI 管道的高级示意图。
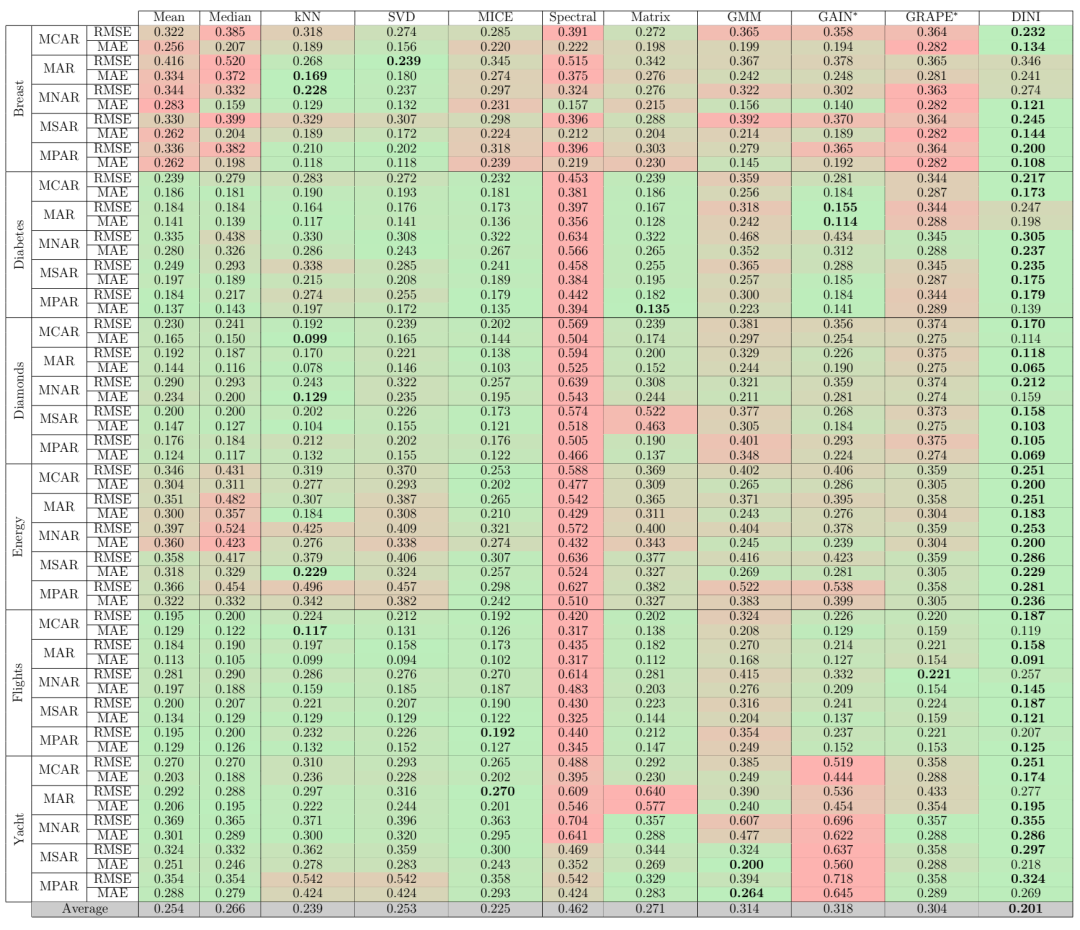 DINI 与各种基线的插补性能比较。考虑了六个数据集和五个(包括两个新提出的)腐败策略。最后一行对每列的所有条目进行平均(包括 RMSE 和 MAE 值)。为了节省空间,未显示置信区间。
DINI 与各种基线的插补性能比较。考虑了六个数据集和五个(包括两个新提出的)腐败策略。最后一行对每列的所有条目进行平均(包括 RMSE 和 MAE 值)。为了节省空间,未显示置信区间。
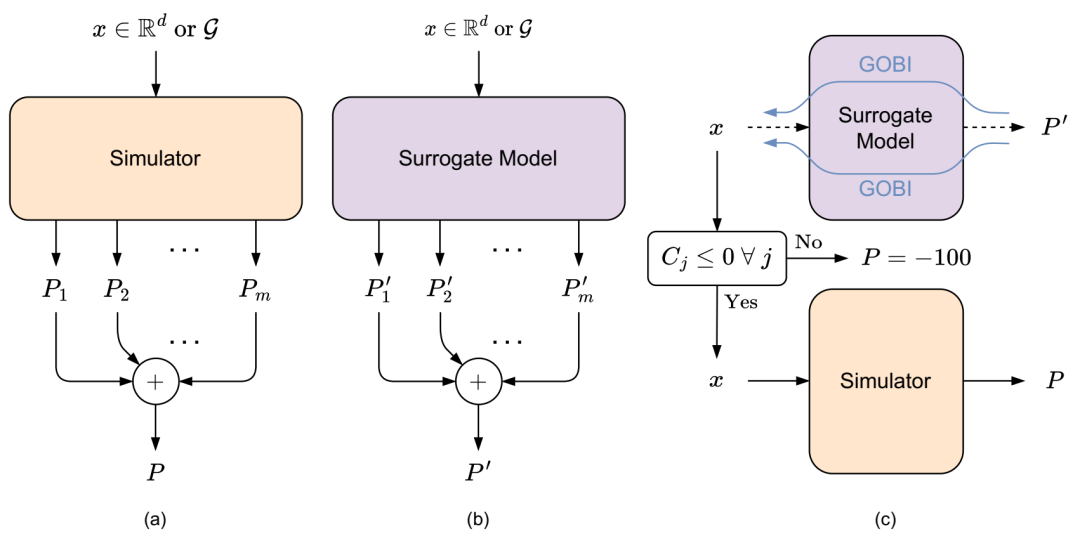 BREATHE 框架概述。(a) 模拟器采用输入 x,它可以是向量(以 Rd 为单位)或图(以 G 为单位)。它输出每个目标(Pi)对应的绩效值。P 是 SOO 个体绩效测量的凸组合。(b) 代理模型是一个轻量级的(即相对于模拟器而言计算成本较低)且模仿模拟器的可微仿真器;其预测性能为P′。(c) 将 GOBI 应用于代理模型以获得具有更高预测性能 P' 的 x。使用模拟值 P 更新数据集,以便能够重新训练代理模型。
BREATHE 框架概述。(a) 模拟器采用输入 x,它可以是向量(以 Rd 为单位)或图(以 G 为单位)。它输出每个目标(Pi)对应的绩效值。P 是 SOO 个体绩效测量的凸组合。(b) 代理模型是一个轻量级的(即相对于模拟器而言计算成本较低)且模仿模拟器的可微仿真器;其预测性能为P′。(c) 将 GOBI 应用于代理模型以获得具有更高预测性能 P' 的 x。使用模拟值 P 更新数据集,以便能够重新训练代理模型。
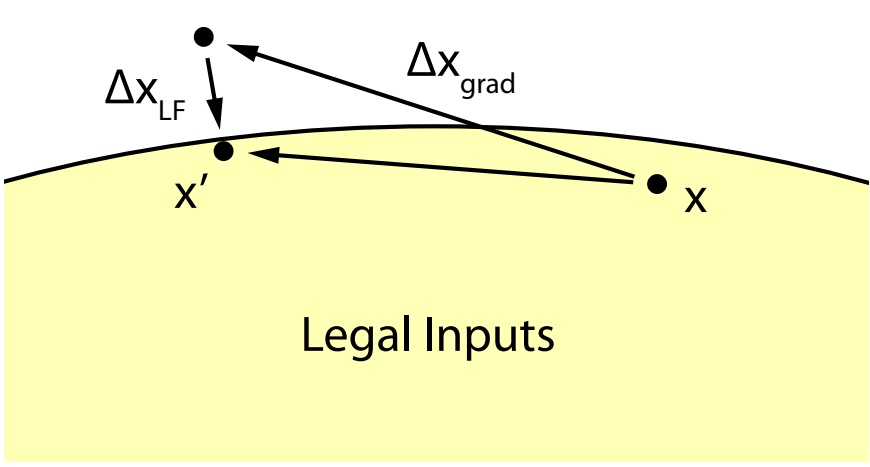 强制合法性的示意图。GOBI 产生的梯度步长 Δxgrad 位于合法输入集之外(可能是设计空间的子集)。ΔxLF 执行一个步骤,强制结果输入合法。
强制合法性的示意图。GOBI 产生的梯度步长 Δxgrad 位于合法输入集之外(可能是设计空间的子集)。ΔxLF 执行一个步骤,强制结果输入合法。
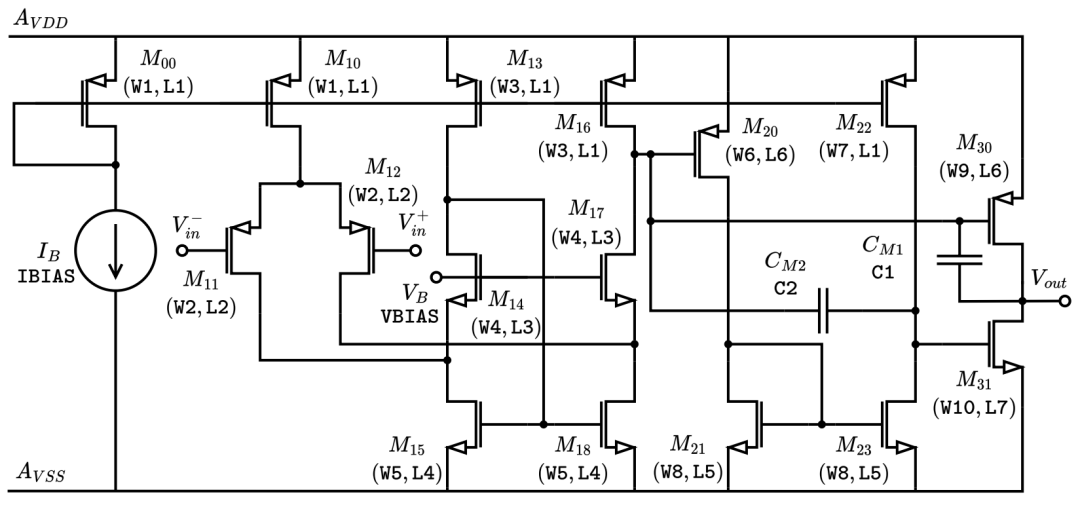 三级运算放大器的电路图。构成输入设计空间的变量以打字机字体呈现。
三级运算放大器的电路图。构成输入设计空间的变量以打字机字体呈现。
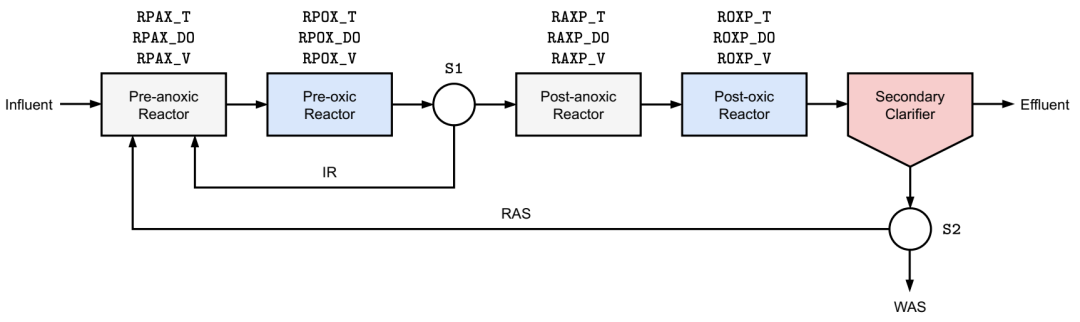 四阶段 Bardenpho 工艺的简化示意图。构成输入设计空间的变量以打字机字体呈现。
四阶段 Bardenpho 工艺的简化示意图。构成输入设计空间的变量以打字机字体呈现。
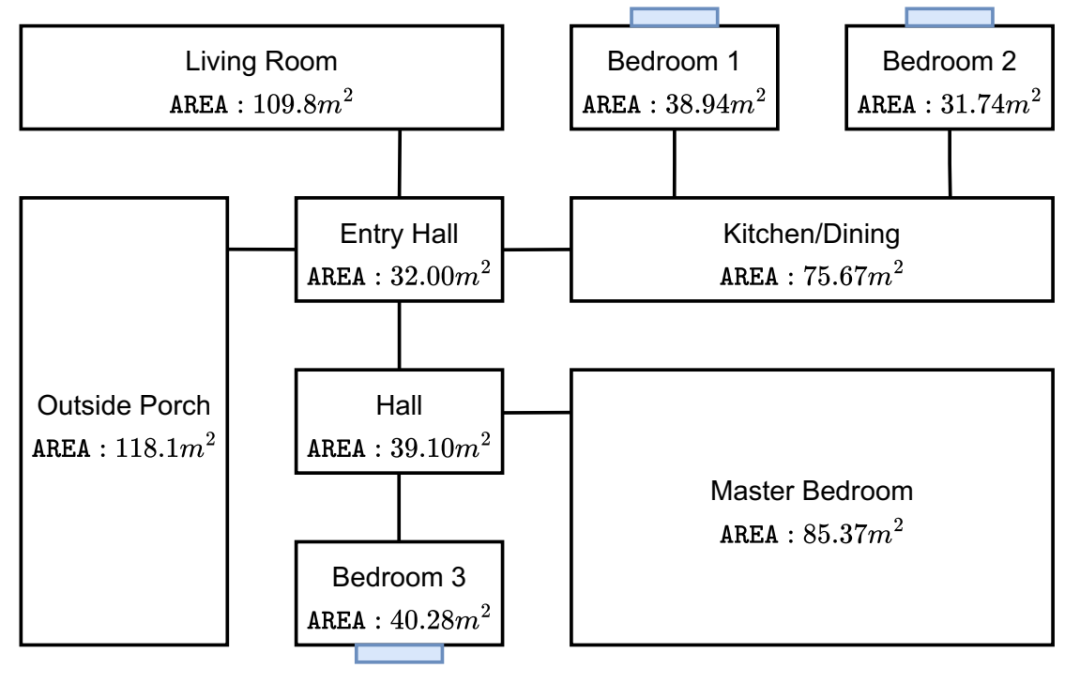 性能最佳的智能家居设计,可根据 G-BREATHE 最大限度地减少网络物理攻击的数量。
性能最佳的智能家居设计,可根据 G-BREATHE 最大限度地减少网络物理攻击的数量。
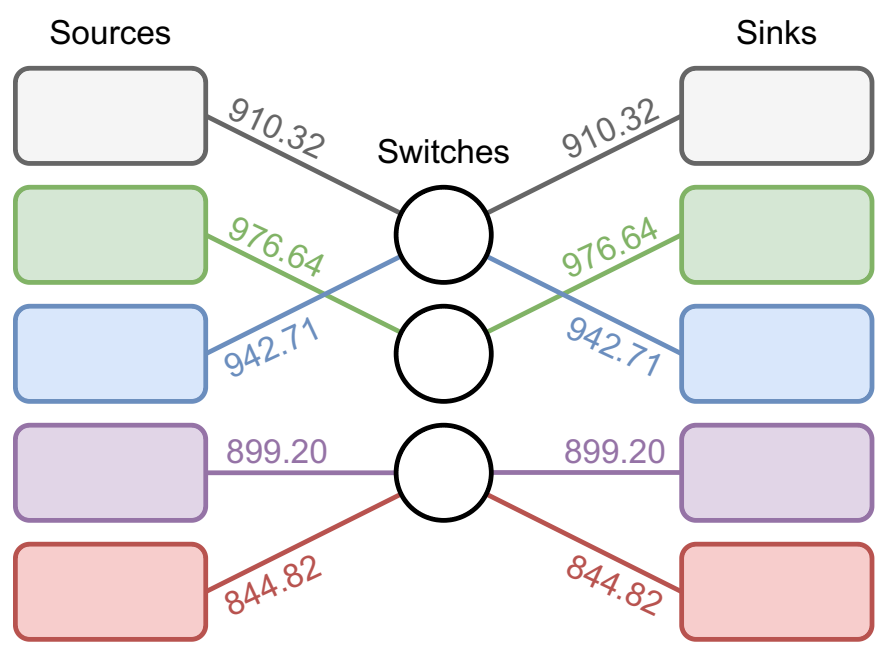 性能最佳的网络架构,可最大限度地提高 G-BREATHE 的性能。连接上的注释表示该连接的带宽(以 MB/s 为单位)。
性能最佳的网络架构,可最大限度地提高 G-BREATHE 的性能。连接上的注释表示该连接的带宽(以 MB/s 为单位)。






微信群 公众号


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢