
Dan Page for Quanta Magazine
导语

背景介绍
背景介绍
读书会框架
读书会框架
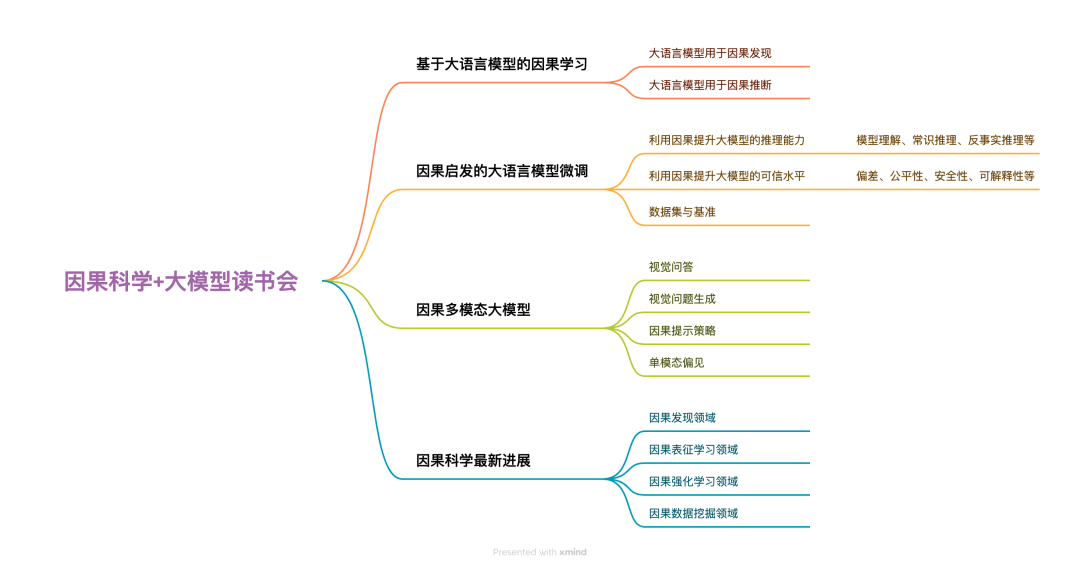
与前四季的关系
与前四季的关系
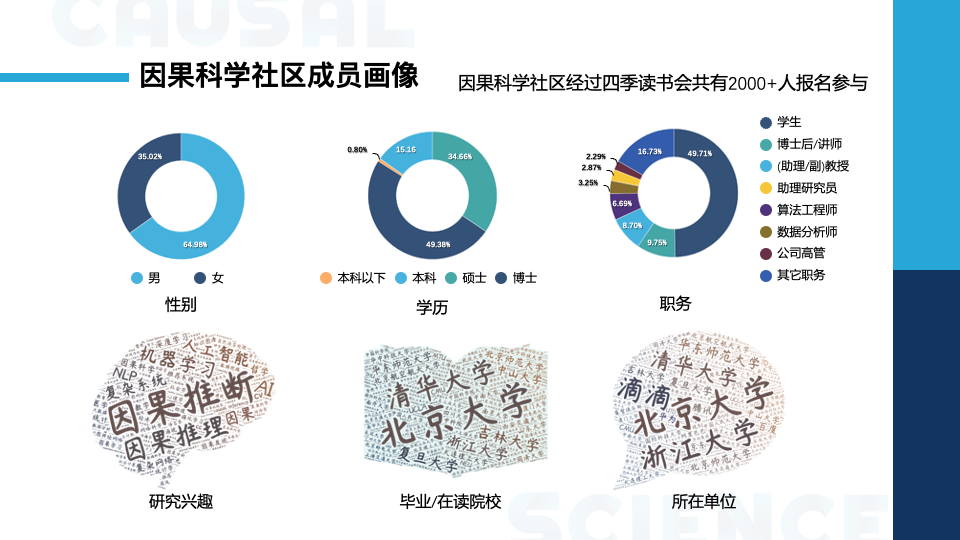
发起人介绍
发起人介绍



本季读书会运营负责人:王婷,集智俱乐部负责人,感兴趣的方向为复杂科学和科学社区运营,致力于服务科研探索者,营造跨学科探索小生境。
报名参与读书会
报名参与读书会
本读书会适合参与的对象
对CausalAI感兴趣的科研工作者;
能阅读英文文献,对复杂科学和世界本质充满好奇的探索者。
本读书会谢绝参与的对象
运行模式
举办时间
参与方式
关注线上直播:读书会的部分分享主题,会在集智俱乐部平台在线直播。
报名方式
第一步:扫码填写报名信息。

扫码报名
PC端报名:
第二步:填写信息后,付费299元。(可开发票,用于学校、研究机构或者企业报销)
如需用支付宝支付,请在PC端进入读书会页面:
https://pattern.swarma.org/study_group/46
第三步:扫码完成报名并添加负责人微信,拉入对应主题的读书会社区(微信群)。
针对学生的退费机制
加入社区后可以获得的资源

参与共创任务获取积分,共建学术社区
字幕修改任务:在集智斑图系统上直接修改字幕
读书会笔记:在交互式播放器上记录术语和参考文献
集智百科词条:围绕读书会主题中重要且前沿的知识概念梳理成词条。例如:
论文解读分享:认领待读列表中的论文,以主题报告的形式在社区分享
公众号文章:以翻译整理或者原创生产形式生产公众号文章,以介绍前沿进展。例如: 报名成为主讲人:读书会成员均可以在读书会期间申请成为主讲人。主讲人作为读书会成员,均遵循内容共创共享机制,可以获得报名费退款,并共享本读书会产生的所有内容资源。
读书会阅读材料
读书会阅读材料
阅读材料较长,为了更好的阅读体验,建议您前往集智斑图沉浸式阅读,并可收藏感兴趣的论文。

前置学习
为了让更多对这个话题感兴趣的同学可以参与讨论,并更好的交流,在大家报名之后,正式开始之前,我们会在社群内部共同组织大家学习回顾因果科学的基础知识和概念,主要是对前四季内容中,涉及到的基础部分视频进行共学回顾,包括每一季的综述分享报告,因果科学基础概念,因果发现基础,因果强化学习基础等内容。
参考因果科学学习路径梳理:https://pattern.swarma.org/article/145
基于大语言模型的因果学习
大语言模型用于因果发现
发掘变量间的因果关系对于正确决策至关重要。目前,分析随机对照试验得到的数据是确定因果关系的黄金标准。然而,随机对照试验实施成本高昂,并且有时存在道德风险。因此,人们对从观察数据中发现因果关系的因果发现方法越来越感兴趣。目前已有一系列工作探索了大语言模型(LLMs)在因果发现任务上的性能,最近的研究表明,以 GPT-4 为代表的 LLMs 包含丰富的有助于因果发现的世界知识,并且 LLMs 有能力借助世界知识提高因果关系识别的准确性。
主要参考文献
Long, Stephanie, et al. "Causal Discovery with Language Models as Imperfect Experts." ICML Workshop, 2023.
本文探讨了如何利用 LLMs 具有的专家知识来定向从观测数据学到的因果图的无向边,从而提高因果图识别的准确性。
Kıcıman, Emre, et al. "Causal reasoning and large language models: Opening a new frontier for causality." arXiv preprint arXiv:2305.00050, 2023.
本文全面分析了在合适的提示词下,LLMs 在多个领域(包括医学和气候科学)的数据集上分析成对变量之间的因果关系的性能。
Cai, Hengrui, et al. "Is Knowledge All Large Language Models Needed for Causal Reasoning?." arXiv preprint arXiv:2401.00139, 2023.
本文指出 LLMs 的因果发现能力更多取决于所提供的上下文文本信息和特定领域的知识,而不是观测数据本身。
Jiralerspong, Thomas, et al. "Efficient causal graph discovery using large language models." arXiv preprint arXiv:2402.01207, 2024.
本文提出了一种基于广度优先搜索利用 LLMs 进行因果发现的方法,只需使用线性查询次数就可以在不同因果图大小下提高因果发现任务的性能。
大语言模型用于因果推断
目前的大语言模型(LLMs)可以进行可视化和统计汇总等基本数据分析。然而,对于更具挑战性的因果推断任务,LLMs 的表现却不尽人意。想要回答因果推断问题,LLMs 需要知道估计因果效应的常用方法,以及如何利用这些方法得到答案。此外,LLMs 如何利用丰富的世界知识生成高质量的反事实数据、放宽传统因果推断假设也是值得深入研究的重要问题。
主要参考文献:
Stolfo, Alessandro, et al. "A causal framework to quantify the robustness of mathematical reasoning with language models." arXiv preprint arXiv:2210.12023, 2022.
本文提出了一个基于因果推断的框架,通过对输入空间直接干预研究LLMs在数学推理能力方面的鲁棒性和敏感性。
Jin, Zhijing, et al. "CLADDER: Assessing causal reasoning in language models." NeurIPS, 2023.
本文创建了一个基准数据集 CLADDER 以探测 LLMs 的因果推断能力,并提出了因果思维链(CoT)提示策略使 LLMs 能从问题中提取变量因果图、目标因果量和可用的数据来计算出因果效应。
Liu, Xiao, et al. "Are LLMs Capable of Data-based Statistical and Causal Reasoning? Benchmarking Advanced Quantitative Reasoning with Data." arXiv preprint arXiv:2402.17644, 2024.
本文提出了一个基准数据集,旨在评估大语言模型对于表格型数据作为输入时的统计分析能力和因果推理能力。
Liu, Xiaoyu, et al. "Large language models and causal inference in collaboration: A comprehensive survey." arXiv preprint arXiv:2403.09606, 2024.
本篇综述概述了LLMs如何通过其强大推理能力帮助因果关系发现和因果效应估计。
因果启发的大语言模型微调
利用因果提升大语言模型的推理能力
在自然语言处理(NLP)领域,因果方法已经有非常丰富的应用。进入大模型的时代后,对于更强推理能力的挖掘和利用更加需要因果赋能。大模型是否具有复杂的逻辑推理能力仍然是受到质疑的,而因果推理将在理论和实践上都让大模型的推理更加准确。不论是利用因果知识辅助大模型推理,还是用前门调整等经典因果方法去除大模型推理的偏差,都取得了显著的效果。有的研究衡量提示词对大模型生成的因果效应,从而揭示其作用并指导对提示词的操纵。
主要参考文献:
Feng, Zijian, et al. "Unveiling and Manipulating Prompt Influence in Large Language Models." arXiv preprint arXiv:2405.11891, 2024.
本文估计大模型提示词的因果效应,并据此指导提示词的操纵,以获得更好的模型输出。
Zhang, Congzhi, et al. "Causal Prompting: Debiasing Large Language Model Prompting based on Front-Door Adjustment." arXiv preprint arXiv:2403.02738, 2024.
本文提出了一种名为 Causal Prompting 的方法,通过使用前门调整对大语言模型的提示词进行因果干预,以有效减少模型偏见,并在多个自然语言处理任务上取得了优异的性能。
Zhou, Bin, et al. "CausalKGPT: Industrial structure causal knowledge-enhanced large language model for cause analysis of quality problems in aerospace product manufacturing." Advanced Engineering Informatics, 2024.
本文提出了一个结合因果和大语言模型的工业结构因果知识增强的大型语言模型,通过构建因果质量相关知识图谱和设计P-tuning微调方法,以提高对航空航天产品制造中质量缺陷问题解决的专业性与可靠性。
Yang, Sen, et al. "Neuro-symbolic integration brings causal and reliable reasoning proofs." arXiv preprint arXiv:2311.09802, 2023.
本文介绍了一种神经符号集成方法,通过大语言模型来表示问题的知识,以及一个独立的符号推理引擎来进行有意识的推理,从而产生因果关系和可靠性的推理证明,显著提高了复杂推理问题的准确性。
Feder, Amir, et al. "Causal-structure Driven Augmentations for Text OOD Generalization." NeurIPS, 2024.
这篇文章提出了一种基于因果结构驱动的数据增强方法,通过对虚假特征干预的模拟,来提高文本分类模型在面对分布外泛化问题时的鲁棒性和准确性。
Chen, Haotian, et al. "Rethinking the Development of Large Language Models from the Causal Perspective: A Legal Text Prediction Case Study." AAAI, 2024.
本文提出了一种新的因果感知自注意力机制,用于改进大语言模型在法律文本预测任务中的表现。通过将因果推理融入模型架构和评估过程中,提高了模型的泛化能力和鲁棒性,并在三个常用的法律文本预测基准测试中取得了最优的性能。
Liu, Xiaoyu, et al. "Large language models and causal inference in collaboration: A comprehensive survey." arXiv preprint arXiv:2403.09606, 2024.
本文探讨了如何利用因果推断方法来增强大型语言模型在理解、推理、公平性、安全性和可解释性方面的能力,并讨论了LLMs如何反过来帮助发现因果关系和估计处理效果,以推动更先进和公平的人工智能系统的共同发展。
利用因果提升大模型的可信水平
随着生成式大模型逐渐被广泛应用于医药、金融、传媒、军事等关键领域,人们意识到可信水平将成为大模型的一项重要性能指标。除了传统深度学习模型可解释性差的缺点,大模型还存在幻觉的现象,因而更引发对可信人工智能的需要。为此,研究人员提出了一些利用因果思想的方法,为评测大模型公平性、安全性、可解释性等在内的可信水平提供了定量且直观的思路。还有一些方法将因果方法与大模型结合,以减轻大模型的偏见或利用大模型发现有害信息。
主要参考文献:
Bhile, Pranav Arvind, et al. "Understanding Structure Of LLM using Neural Cluster Knockout." ICICV, 2024.
本文通过应用神经科学技术到大语言模型中,特别是采用“神经集群敲除”方法,揭示了神经网络的内部工作机制,旨在提高大模型系统的效率、透明度和可问责性,并为未来更精确可靠的AI系统发展奠定了基础。
Wu, Zhengxuan, et al. "Interpretability at scale: Identifying causal mechanisms in alpaca." NeurIPS, 2024.
本文介绍了一种名为Boundless DAS的新方法,通过对大语言模型Alpaca进行因果分析,发现了其解决数值推理问题时所依赖的两个可解释布尔变量的内部因果机制,并证明了这些发现在不同输入和指令下具有鲁棒性。
Jenny, David F., et al. "Exploring the Jungle of Bias: Political Bias Attribution in Language Models via Dependency Analysis." arXiv preprint arXiv:2311.08605v2, 2024.
本文从因果公平性分析的视角,提出了一种基于提示词工程的简单方法来检查大语言模型的内部决策过程,并分析了模型在政治辩论质量评分中表现出的偏见,从而为理解和减轻大模型系统中的偏见提供了新的视角。
Matton, Katie, et al. "Walk the Talk? Measuring the Faithfulness of Large Language Model Explanations." ICLR Workshop, 2024.
这篇文章介绍了一种新的方法来衡量大语言模型提供的解释的忠实度,并展示了如何使用这种方法量化忠实度以及发现包括否认存在社会偏见在内的不忠实模式。
Sheth, Paras, et al. "Causality guided disentanglement for cross-platform hate speech detection." WSDM, 2024.
本文介绍了一个跨平台仇恨言论检测模型,该模型通过因果引导的解耦方法将输入表示分解为不变和平台依赖特征,以提高仇恨言论检测的泛化能力。
Wang, Fei, et al. "A causal view of entity bias in (large) language models." arXiv preprint arXiv:2305.14695, 2023.
本文利用了结构因果模型(SCM),以减轻大型预训练语言模型中的实体偏差问题,并通过实验验证了所提出的因果干预技术在白盒和黑盒设置下对关系抽取和机器阅读理解任务的有效性。
Mishra, Ashish, et al. "LLM-Guided Counterfactual Data Generation for Fairer AI." WWW, 2024.
本文提出了一种使用大语言模型指导生成反事实数据的方法,以增强深度学习模型在面部图像分析中的公平性和可信度。
数据集与基准
大语言模型的生成能力得到了普遍认可,但对于其推理能力,许多研究人员并不完全信服。大模型在许多推理问题上得到正确结论可能是由于训练数据集的记忆而非逻辑的推演。因此像因果推理这样复杂的数学和逻辑推理,大语言模型的性能确实有待评估。而且在因果中存在的反事实描述在语料库中通常远远少于事实描述,能部分规避大模型对训练集记忆的问题,更有效地评价大模型的推理能力。目前已经有纯文本、多模态等许多不同的基准,用于衡量大模型的因果能力。
主要参考文献:
Li, Yian, et al. "Eyes Can Deceive: Benchmarking Counterfactual Reasoning Abilities of Multi-modal Large Language Models." arXiv preprint arXiv:2404.12966, 2024.
本文介绍了一个新的基准CFMM(CounterFactual MultiModal reasoning benchmark),用于评估多模态大型语言模型(MLLMs)在反事实推理能力方面的表现。
Liu, Xiao, et al. "Are LLMs Capable of Data-based Statistical and Causal Reasoning? Benchmarking Advanced Quantitative Reasoning with Data." arXiv preprint arXiv:2402.17644, 2024.
本文介绍了一个名为QRDATA的基准,旨在评估大型语言模型在处理真实世界数据时的统计和因果推理能力。
Rodriguez-Cardenas, Daniel, et al. "Benchmarking Causal Study to Interpret Large Language Models for Source Code." ICSME, 2023.
本文介绍了一个名为Galeras的基准,旨在通过因果推断来评估和解释大语言模型在软件工程任务中的性能,并通过案例研究展示了如何使用Galeras来量化提示词工程方法对ChatGPT代码生成性能的影响。
Ji, Zhenlan, et al. "Benchmarking and Explaining Large Language Model-based Code Generation: A Causality-Centric Approach." arXiv preprint arXiv:2310.06680, 2023.
本文利用了一种基于因果分析的方法,系统地评估和解释了大型语言模型(LLMs)输入提示(prompts)与生成代码之间的因果关系,并提供了一种新的因果图表示方法,以及通过调整提示来改善生成代码质量的策略。
Xie, Yuxi, et al. "ECHo: A Visio-Linguistic Dataset for Event Causality Inference via Human-Centric Reasoning." EMNLP, 2023.
本文介绍了一个名为ECHO的视觉语言数据集,并提出了一个结合了心智理论(ToM)的思维链框架(Chain-of-Thought, CoT)的方法,用于评估当前AI系统在社会情境中基于多模态信息进行推理的能力。
因果与多模态大模型
近年来,因果方法在自然语言处理(NLP)和计算机视觉(CV)上的一些应用已经取得了良好的效果。可以预见的是,对于多模态大语言模型,因果的思想将同样发挥重要的作用。对于视觉问答(VQA)、视觉问题生成(VQG)等任务,可以自然地利用因果方法建模视觉、文本等模态内及模态间的关系,或多模态信息与其他变量的关系。研究人员提出了一些方法,结合后门调整等经典的因果方法,可以从理论上消除影响模型性能的虚假相关,并且在实际应用中也明显增强了其多模态能力。
主要参考文献:
Chen, Jiali, et al. "Deconfounded visual question generation with causal inference." ACM MM, 2023.
本文提出了一种基于因果推断的视觉问题生成模型,该模型通过干预视觉特征提取和知识引导的表示提取来减轻视觉问题生成中的虚假相关性,从而生成与给定图像和目标答案更一致的问题,在VQA v2.0和OKVQA数据集上取得了优于现有模型的性能。
Chen, Meiqi, et al. "Quantifying and Mitigating Unimodal Biases in Multimodal Large Language Models: A Causal Perspective." arXiv preprint arXiv:2403.18346, 2024.
本文提出了一种因果框架来量化和减轻多模态大语言模型在复杂多模态任务中的单模态偏见(如语言偏见和视觉偏见)。
Zhao, Shitian, et al. "Causal-CoG: A Causal-Effect Look at Context Generation for Boosting Multi-modal Language Models." arXiv preprint arXiv:2312.06685, 2023.
本文提出了一种名为Causal-CoG的提示策略,通过生成和利用上下文信息来增强多模态语言模型在视觉问答任务中的准确性,并从因果关系的角度探讨了上下文信息的优势,通过因果方法选择对上下文信息有帮助的样本。
Pan, Kaihang, et al. "Auto-Encoding Morph-Tokens for Multimodal LLM." arXiv preprint arXiv:2405.01926, 2024.
本文提出了一种名为Morph-Token的新型视觉编码方法,并通过一个三阶段训练策略解决了多模态大型语言模型在视觉理解和生成任务中的目标冲突问题,实现了在多模态理解和生成任务上同时达到新的最佳性能。
Lu, Feihong, et al. "Few-Shot Multimodal Named Entity Recognition Based on Multimodal Causal Intervention Graph." LREC-COLING, 2024.
本文提出了一个名为MOUSING的新型多模态因果干预图模型,用于处理小样本多模态命名实体识别任务,通过构建多模态图并引入多模态因果干预策略来减少虚假关联,强调准确关联,从而有效对齐多模态表示,提高在小样本情况下的模型性能。
因果科学领域最新进展
因果强化学习与智能体决策
因果强化学习(Causal Reinforcement Learning, CRL)是一种结合因果推理和强化学习的方法,用于提升智能体在复杂环境中的决策能力。传统的强化学习侧重于通过试错来学习策略,而因果强化学习则在此基础上加入了因果关系的建模,以提高智能体的学习效率和决策准确性。我们将探究因果强化学习的基本概念前沿方法,以及在(大模型)智能体决策,博弈中的系列方法。
主要参考文献:
Sanghack Lee, et al. "Characterizing Optimal Mixed Policies: Where to Intervene, What to Observe." NeurIPS, 2020.
本文主要介绍了在多种决策选择的场景中,如何基于因果分析方法分析决策之间的关系,以及通过分析到的关系做更好的决策。
Junzhe Zhang, et al. "Online Reinforcement Learning for Mixed Policy Scopes." NeurIPS, 2022.
本文主要讨论了强化学习场景当中如何采用因果分析更好的进行在线学习。
Maximilian Seitzer, Bernhard Schölkopf, et al. "Causal Influence Detection for Improving Efficiency in Reinforcement Learning." NeurIPS, 2021.
本文主要介绍了如何使用发现的因果影响关系,提升强化学习方法的学习效率。
Mengyue Yang, et al. "Invariant Learning via Probability of Sufficient and Necessary Causes." NeurIPS, 2023.
本文主要介绍了如何在观察数据中识别对目标有充分必要因果效应的表征。
Sumedh A. Sontakke,et al. "Causal Curiosity: RL Agents Discovering Self-supervised Experiments for Causal Representation Learning." ICML, 2021.
本文主要介绍了在动态的可交互物理场景中,如何通过强化学习方法和因果分析方法,对观察进行因果解耦,分辨出对应不同物理概念的表征。
Jonathan Richens, et al. "Robust agents learn causal world models." ICLR, 2024. Honorable mention outstanding paper award.
本文主要讨论了智能体是否必须学习因果模型才能泛化到新领域。本文表明任何能够在一大类分布变化下满足遗憾界限的智能体,都必须学习到数据生成过程的近似因果模型,对于最优的智能体,该模型会收敛到真实的因果模型
Lewis Hammond, et al. "Reasoning about Causality in Games." Artificial Intelligence Journal, 2023.
本文主要讨论了在多智能体博弈场景里考虑因果效应的问题场景,提供了全新的因果博弈定义和分析。
因果表征学习
虽然基于深度表征学习的先进人工智能技术(包括大语言模型 GPT 和 LLaMa)在数据分析和生成方面表现出色,但它们通常会识别相关性而不是因果关系。这可能会导致潜在的虚假相关性和算法偏差,从而限制模型的可解释性和可信度。因果表征学习(Causal Representation Learning)旨在理解数据的生成过程, 并研究潜在的因果关系。通过因果表征学习 (CRL),研究人员和从业者可以更好地理解特征如何影响结果,识别可能影响决策和泛化的潜在偏见或混杂因素。
主要参考文献:
Hyvarinen, et al. "Unsupervised Feature Extraction by Time-Contrastive Learning and Nonlinear ICA." NeurIPS, 2016.
本文主要提出了利用时序数据的非稳态结构作为辅助信息进行非线性独立成分分析,从而识别潜在的因果表征。
Khemakhem, Ilyes, et al. "Variational Autoencoders and Nonlinear ICA: A Unifying Framework." AISTATS, 2020.
本文讨论了变分自编码器与非线性独立成分分析之间的联系,提出了利用辅助变量, 通过基于变分自编码器的深度生成模型进行可识别潜在表征表征学习的理论框架。
Kong, Lingjing, et al. "Partial disentanglement for domain adaptation." ICML, 2022.
本文提出了在多源域自适应任务中,可以学习具有部分可识别性的因果表征,解耦域变与域不变特征, 从而实现域自适应。
Yao, Weiran, et al. "Temporally Disentangled Representation Learning." NeurIPS, 2022.
本文提出了一个基于充分变化条件的时序数据因果表征学习框架,该框架能够在稳态与非稳态、因果结构变化与观测变化等多种场景下学习可识别的潜在变量。
Zheng, Yujia, et al. "On the Identifiability of Nonlinear ICA: Sparsity and Beyond." NeurIPS, 2022.
本文提出一种基于结构化稀疏性的因果表征学习方法, 可以在没有辅助变量或者先验归纳偏置的条件下学习可识别的潜在表征。
Lachapelle, Sébastien, et al. "Nonparametric Partial Disentanglement via Mechanism Sparsity: Sparse Actions, Interventions and Sparse Temporal Dependencies." arXiv preprint arXiv:2401.04890, 2024.
本文系统且全面地介绍了一种基于机制稀疏正则化的因果表征学习方法,通过同时学习潜在因素和解释它们的稀疏因果图模型来实现具有可识别性的特征解耦。
Chen, Guangyi, et al. "CaRiNG: Learning Temporal Causal Representation under Non-Invertible Generation Process." ICML, 2024. 本文提出利用时序上下文信息在生成过程不可逆的条件下进行可识别的因果表征学习。
Chen, Guangyi, et al. "LLCP: Learning Latent Causal Processes for Reasoning-based Video Question Answer." ICLR, 2024.
本文以事故归因与反事实预测为例,讨论了因果表征如何被应用于视频推理。
因果发现最新进展
因果发现是从数据中自动学习因果关系的过程,旨在发现变量之间的因果依赖关系,而不仅仅是相关性。它是因果推理的基础,对于预测、决策制定和科学理解非常重要。因果发现的核心挑战在于处理隐藏变量、循环因果关系、高维非线性数据、动态变化关系,同时确保结果的可解释性和高效计算。
主要参考文献:
Montagna , et al. "Scalable Causal Discovery with Score Matching." CLeaR, 2023.
本文展示了如何从观测到的非线性加性高斯噪声模型的对数似然函数的二阶导数中发现整个因果图。这个方法实现了原则性和可扩展的因果发现,大大降低了计算门槛。
Wu, Anpeng, et al. "Learning Causal Relations from Subsampled Time Series with Two Time-Slices." ICML, 2024.
本文研究了仅使用两个时间片的子采样时间序列中学习变量间因果关系的方法,开发了一种条件独立性准则,该法则可以反复应用于测试时间序列中的每个节点,并识别其所有后代节点,能够显著降低干预成本和虚假边的数量。
Dong, Xinshuai, et al. "A Versatile Causal Discovery Framework to Allow Causally-Related Hidden Variables." ICLR, 2024.
本文提出了一种基于秩缺陷测试的因果发现框架。该框架允许存在大量隐藏变量,并且这些隐藏变量之间、隐藏变量与观测变量之间,以及观测变量之间可以存在复杂的因果关系。所提出的算法能够有效地定位隐藏变量,确定其数量,并揭示包括观测变量和隐藏变量在内的完整因果结构,直至Markov等价类。
Jin, Songyao, et al. "Structural Estimation of Partially Observed Linear Non-Gaussian Acyclic Model: A Practical Approach with Identifiability." ICLR, 2024.
本文考虑线性非高斯潜在变量模型,并利用了一种广义独立噪声条件来估计这样的潜在变量图。所提出的算法通过利用高阶统计量能够有效地定位隐藏变量,确定其数量,并揭示包括观测变量和隐藏变量在内的完整因果结构。
Dai, Haoyue, et al. "Local Causal Discovery with Linear non-Gaussian Cyclic Models." AISTATS, 2024.
本文提出了一种通用、统一的局部因果发现方法,适用于线性非高斯模型,无论其是循环的还是无环的。文中将独立成分分析的应用从全局扩展到独立子空间分析,从而能够精确识别目标变量的Markov毯中的等价局部有向结构和因果强度。
Ng, Ignavier, et al. "Structure Learning with Continuous Optimization: A Sober Look and Beyond." CLeaR, 2024.
本文探讨了在何种情况下,连续优化用于有向无环图(DAG)结构学习能够表现良好或不能表现良好,以及为什么会出现这种情况,并提出了可能的改进方向。
因果数据挖掘最新进展
数据挖掘是人工智能和数据库领域研究的热点问题,旨在对大量原始数据进行搜索和分析的过程,目的是识别数据的规律和提取数据的信息。然而,大多数相关性数据发掘的模型存在以下的技术瓶颈:鲁棒性差,即加入噪声会或改变模型假设将很大程度上影响模型的输出结果;可解释性低,即对于大多数(特别是基于深度学习技术)的模型不知道其内在机制;外推性弱,即在部署数据分布与训练分布不一致时损害模型表现。目前,许多基于因果的数据挖掘的方法被提出以解决这些问题。
主要参考文献:
Tan, Juntao, et al. "Counterfactual explainable recommendation." CIKM, 2021. 该研究提出了一种反事实可解释推荐方法以寻求简单(低复杂度)的推荐和有效的解释,并且提出了可解释推荐的评估指标。
Wang, Zhenlei, et al. "Counterfactual data-augmented sequential recommendation." SIGIR, 2021. 该研究提出了一种反事实数据增强方法,以减轻序列推荐中训练数据缺失的影响,并增强模型序列推荐的能力。
Du, Xiaoyu, et al. "Invariant representation learning for multimedia recommendation." ACM MM, 2022. 该研究在多媒体推荐领域提出了一个不变表征学习框架来减轻虚假相关性的影响,并通过学习到的不变的因果表征对用户进行物品推荐。
Wang, Hao, et al. "ESCM2: entire space counterfactual multi-task model for post-click conversion rate estimation." SIGIR, 2022. 该研究提出了一种 “全空间反事实多任务建模” 的方法以同时解决预测点击后的转化率时的估计偏差和数据稀疏性问题。
Gao, Chen, et al. "Causal inference in recommender systems: A survey and future directions." ACM Transactions on Information Systems, 2024. 该研究对基于因果推断的推荐系统文献进行了全面回顾,强调了基于相关性的推荐系统面临的典型问题,并提出了未来因果推荐的一些潜在研究方向。
Li, Haoxuan, et al. "Debiased collaborative filtering with kernel-based causal balancing." ICLR 2024, Spotlight. 该研究分析了现有方法在学习倾向得分时在满足因果平衡约束方面的局限性,并提出了一个基于核函数在再生核希尔伯特空间中近似平衡函数的方法,以更好地满足因果平衡约束。
Li, Haoxuan, et al. "Relaxing the Accurate Imputation Assumption in Doubly Robust Learning for Debiased Collaborative Filtering." ICML, 2024. 该研究提出了几种新型的双稳健估计量以解决协同过滤中的选择偏差问题,这些估计量放宽了估计无偏性对于准确伪标签估计的假设。
致谢:感谢李昊轩、杨梦月、陈广义,以及周川、郑淳元、黄碧薇对读书会的大力支持以及推荐的论文阅读材料。
关于举办方和集智俱乐部读书会
关于举办方和集智俱乐部读书会

点击“阅读原文”,报名读书会
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢