

导读
随着大模型时代到来,作为高校 CV 科研工作者,他鼓励学生们要创造一切可能,参与大模型相关的研究,同时探索通过利用弱标签数据(weakly annotated data)复现CV 领域的 ChatGPT 时刻的可能性。“我们不能因为没有计算资源就选择‘避开’大模型。既然知道这是最有希望的方向,那一定要坚持并想尽各种办法。”
第16期智源专访,浙江大学求是讲席教授沈春华讲述他的研究故事。以下为专访全文(为方便流畅阅读,笔者进行了不改变原意的编辑)。
智源专访栏目意在展现行业顶尖技术研究者和创业者的研究经历和故事,本次专访为总第16期。
沈春华教授为2024智源大会多模态论坛主席,该论坛汇聚OpenAI、DeepMind、纽约大学等团队代表,即刻扫码注册,参与大会报名。

简介
沈春华,浙江大学求是讲席教授、计算机辅助设计与图形系统全国重点实验室副主任、入选教育部长江学者奖励计划。沈春华本科和硕士均毕业于南京大学,于2005年在阿德莱德大学获得计算机视觉博士学位。2006年至2011年在澳洲国立大学和 National ICT Australia 任职研究员。2011 年回到阿德莱德大学任教,同年入选 Australian Research Council Future Fellowship 人才计划,2014年破格晋升为阿德莱德大学计算机科学系正教授。2021 年底回国全职加入浙江大学。他的谷歌学者引用达71800,H-index 125。
我本科就读于南京大学强化部,现在的匡亚明学院。我本科的专业并不是计算机,更不是人工智能,当时学的是数学物理。在攻读研究生时,我转到了声信号处理领域,师从徐柏龄教授,从事语音信号处理研究,主要的课题是“说话人识别”,从此与人工智能结缘。
之所以在读研究生时选择信号处理,主要是考虑到将来可能更“好找工作”。实际上,我被阿德莱德大学录取的博士专业也是信号处理。但当我到了阿德莱德之后,之前联系好的导师跳槽去了别的高校,我不得不重新找导师,转到了图像处理和计算机视觉。当时也没有考虑到AI在未来会怎样发展,是“误打误撞”入了这一行。
之后,我去澳洲国立大学工作了五年多。2011 年我回到阿德莱德大学任教,2021年底回国入职浙江大学。这样算来,我从读博士开始,在 CV 这个领域已经有 20 年左右的时间。
现在回过头看,换到人工智能应该是比较正确的。无论是在工业界还是学术界,信号处理技术相对较为成熟,能继续深挖的东西并不多。而 20 年前,人工智能还是一个十分冷门的方向,没有多少人研究 CV 和人工智能。
 阿德莱德大学
阿德莱德大学
 FCOS是在2019 ICCV上最有影响力的论文之一
FCOS是在2019 ICCV上最有影响力的论文之一
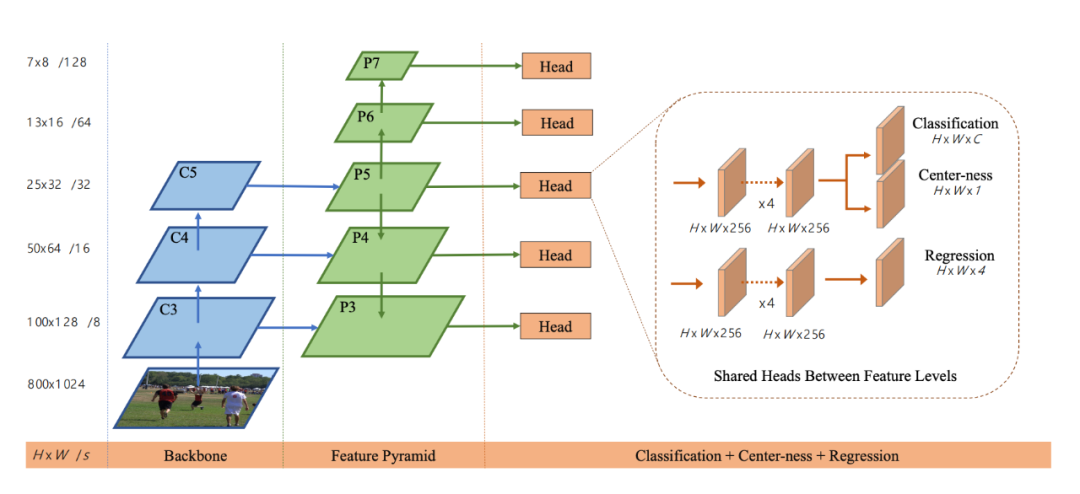 FCOS的网络架构(论文原文:https://arxiv.org/pdf/1904.01355)
FCOS的网络架构(论文原文:https://arxiv.org/pdf/1904.01355)
值得一提的是,在 ICCV 2005上,有 30 篇来自中国大陆的论文,其中一半是微软亚洲研究院发表的,也就是说中国高校合计发表了十来篇论文,占总论文数的 6%-7%。而在现在的 CVPR、ICCV 大会上,可能有 30%以上的论文第一单位归属于中国大陆的高校。从论文产出数量上来看,我们高校的进步非常明显,这是一个非常积极的信号。
和许多 CV 工作者类似,我们也希望在多模态上复现 ChatGPT 的成功。ChatGPT 和 LLM 之所以能成功,关键在于用海量的无标签数据,通过自监督的方式训练大模型,即自回归地预测下一个 token。我们希望也可以在视频和图像上实现这样的范式,到目前为止,CV领域的研究者做了很多尝试,但是进展十分有限,并没有出现类似自然语言处理的 Scaling Law。
究其原因,也许是因为人类的文字信号本身已经经过了凝练,包含人的因素。而想要将 GPT 自监督的训练模式复制到 CV 领域则不一定行的通。考虑到监督信号的获取,我们可以通过弱监督学习的方式来训练多模态大模型,例如:通过图像级(image level)的标注实现像素级(pixel level)的视觉任务,比如图像分割任务。在过去几年里,我们团队一直在从事相关的研究,未来也会一直做下去。

以多视角几何相关为例,有些研究者也试着将其与深度学习集合,在某些场景下取得了更好的效果。除了感知,许多 CV 其它的方向也都转向了深度学习,例如一些底层视觉图像处理的工作。
视觉基础模型或者多模态大模型在我看来肯定是下面几年CV最重要的方向之一。目前我看不到 CV 领域有什么技术能够取代深度学习。
多模态大模型是当下的趋势。我主要关注的多模态大模型指的是实现文字、图像、视频感知(perception)任务的大模型。大部分视觉感知任务都可以看作是多模态感知的特例。相较之下,在多模态感知场景中,我们还可以利用语言大模型的一些能力。就好比人类可以通过常识判断「天空中出现汽车」是违反自然规律的。这样的关于我们的这个世界的知识很难单纯通过图片学到。毋庸置疑,多模态大模型能够提供更好的性能。
至于Sora,文生视频效果惊艳,是 Scaling Law 的成功例子。但因为算力和数据的问题,并非所有团队都能够从头做这样的事情,也不需要。根据 OpenAI 发布的公开信息,Sora 主要是大数据和大算力的成功。高校并不具备这样的资源,我们团队也在做一些文生视频的工作,但更多是从算法层面进行一些创新,更多的是关注 video to video 的编辑任务。我们没有办法与 OpenAI 这样的公司硬碰硬地竞争,这不现实也不理智。
但高校仍然也有很多研究任务可以做。例如,图像编辑、视频编辑,这些任务和文生图文生视频紧密相关。近年来的很多论文都是在Stable Diffusion、Llama 3这样的开源大模型基础上做进一步的研究。在很长一段时间内,在开源大模型上展开研究工作会成为一种较为普遍的状态。我们不能因为没有计算资源就选择“避开”大模型。既然明明知道这是最有希望的方向,仍要坚持并想尽各种办法。
为了解决算力问题,我们也一直在寻求与工业界的合作。学术界出人,工业界出算力。
 沈春华教授在实验室
沈春华教授在实验室我一直跟我的学生强调,在选题的时候要从两个方面去思考:(1)真正原创性的研究。这类研究可能会带来比较大的影响;这是 CV 作为 Science 的一面。这个很难。或者,(2)真正解决算法落地的问题,也就是解决 CV 偏 engineering 的问题。能做到其中一点在我看来就是好工作。
在与工业界合作的过程中,我们可以洞悉他们的实际需求。例如,在牺牲尽可能小的精度的情况下,降低计算量,将算法部署在低功耗的设备上。即使算法本身没有太大的创新,但是如果能解决工业界的痛点,也非常有价值。在当下的大数据、大模型时代,学术界做的很多模型可以让工业界更为容易地使用。这是当下的趋势。
我们做研究,并不只是为了论文发表。一些审稿人会认为论文的创新性是排在第一位的,但我个人并不这么看。创新性(Novelty)和贡献(Contribution)的概念不应被混淆,创新性只是贡献的一种类型,贡献还包含其它的东西。但是很遗憾,很多审稿人会直接以创新性不足为理由拒稿,也许这是最容易用来拒稿的理由。
其实大部分研究者都看到了这个问题,特别是在 AI 领域,大家也进行了一些尝试,例如:OpenReview 等网站可以公开审稿人对论文的评价和打分,但是目前为止对审稿人信息仍采取匿名化处理。
最重要的是,所有参与审稿的人,必须有一个职业底线。现在很多审稿人不负责任,审稿意见的偏差非常大。因为投稿数太多,我们很难控制审稿的质量,很难找到足够多的负责的审稿人。也许 OpenReview 可以考虑公开审稿人的身份,这样审稿人也许就会更加负责一些,不会胡乱写审稿意见。

更多内容 尽在智源社区
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢