

【论文标题】An Improved Attention for Visual Question Answering 【作者团队】Tanzila Rahman,Shih-Han Chou,Leonid Sigal,Giuseppe Carenini 【发表时间】2020/11/4 【论文链接】https://arxiv.org/pdf/2011.02164.pdf
【推荐理由】 本文来自 Hinton 领衔的加拿大矢量 AI 研究所,向 VQA 的「编码器-解码器」框架中引入了嵌套注意力机制,在确定注意力结果与查询之间关系的同时有效融合了多模态信息,效果 SOTA。
给定一张图像和一个通过自然语言表达的形式自由、开放性的问题,视觉问答系统(VQA)旨在为这个与图像相关的问题给出准确的答案。由于该任务要求模型同时理解复杂的视觉和文本信息,所以极具挑战性。另一方面,注意力机制可以捕获模态内和模态间的依赖,它可能是最广泛地被用于解决此类挑战的机制。在本文中,作者提出了一种改进的基于注意力的 VQA 架构。作者在「编码器-解码器」框架中引入了一种嵌套注意力机制(AoA),它能够确定注意力计算结果和查询之间的关系。注意力模块会为每个查询生成加权平均。另一方面,AoA 模块首先会利用注意力结果和当前的上下文生成信息向量和一个注意力门控;接着,作者加入了另一种注意力机制将上述二者相乘,生成最终经过注意力处理之后的信息。本文还提出了多模态融合模块将视觉和文字信息融合在一起,旨在动态地决定应该分别在多大程度上考虑各个模态下的信息。在 VQA-v2 对比基准数据集上进行的大量实验证明,本文提出的方法实现了目前最先进的性能。
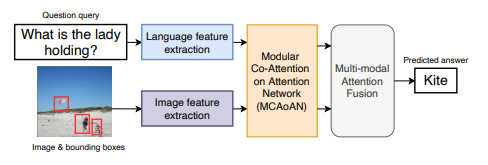
本文的主要贡献在于: (1)引入嵌套注意力模块,构建了 MCAoAN,它可以获取视觉和语言模态间和模态内的注意力,并且减小来自不相关上下文的信息流。 (2)提出了一种多模态的基于注意力的融合机制,同时考虑了图像和问题的特征。该融合网络动态地决定在省城最终用于预测正确答案的特征表征中,应该分别赋予各个模态的信息多少权重。 (3)大量在 VQA-v2 对比基准数据集上进行的实验说明,本文提出的方法性能优于对比基线,获得了 VQA 任务上目前最优的性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢