

人类对物理世界有着很强的直觉理解能力。我们通过多种感官方式观察环境并与之互动,并建立一个心理模型,预测如果我们采取特定行动(即直觉物理学),世界将如何变化。这篇论文研究借鉴了人类的见解并开发了基于模型的强化学习 (RL) 代理(Agents)。代理从他们的互动中学习并建立环境的预测模型,这些模型可以广泛推广到用不同材料制成的各种物体。研究的核心思想是引入新颖的表示并将结构先验集成到学习系统中,以在不同抽象层次上对动态进行建模。将讨论如何对底层环境进行结构推断。还将展示这种结构如何使基于模型的规划算法更有效,并帮助机器人完成复杂的操作任务(例如,操纵物体堆、倒一杯水以及将可变形泡沫塑造成目标配置)。除了视觉感知之外,触觉在人类进行身体互动时也起着至关重要的作用。将讨论如何通过构建具有各种形式的密集触觉传感器(例如手套、袜子、背心和机器人袖子)的多模态传感平台来弥合人类与机器人之间的传感差距,以及它们如何导致更结构化和物理基础的世界模型。
这篇论文由三部分组成。
第一部分,我们展示了如何在不同的抽象层次上学习世界模型,以及学习到的模型如何允许基于模型的规划在模拟和现实世界中完成具有挑战性的机器人操作任务。
第二部分,研究了使用学习到的结构化世界模型进行物理推理,该模型推断环境中不同组件之间的因果关系并执行状态和参数估计。
第三部分,超越了前两部分,后者仅假设视觉作为输入,将触觉视为一种额外的感官方式。将讨论我们开发的新型触觉传感器,以及如何将它们用于理解手与物体和人与环境的物理相互作用。

论文题目:Learning Structured World Models From and For Physical Interactions
作者:Yunzhu Li
类型:2022年博士论文
学校:Massachusetts Institute of Technology (美国麻省理工学院)
下载链接:
链接: https://pan.baidu.com/s/1lnet0Sgdbc2CKUmsGWrzTg?pwd=pyns
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5

学习进行物理交互。人类通过多种感官方式(例如视觉和触觉)感知世界,通过交互,我们建立了一个心理世界模型,该模型可以预测如果我们采取特定行动,环境将如何变化。然后,我们使用大脑中学习到的预测模型来规划我们的行动,以实现特定目标。
 场景表示和动态建模。我的研究调查了不同抽象层次的环境表示,从以对象为中心的模型到关键点和粒子,并已成功建模了各种材质的物体,包括刚体、可变形物体、颗粒材料和流体。
场景表示和动态建模。我的研究调查了不同抽象层次的环境表示,从以对象为中心的模型到关键点和粒子,并已成功建模了各种材质的物体,包括刚体、可变形物体、颗粒材料和流体。
 物理推理和基于模型的控制。我们利用学习到的动态模型中的结构和来自学习和控制社区的强大优化工具解决了各种下游任务,并在 (d) 物理场景推理和 (a–c) 操纵由不同材料制成的物体方面取得了成功。
物理推理和基于模型的控制。我们利用学习到的动态模型中的结构和来自学习和控制社区的强大优化工具解决了各种下游任务,并在 (d) 物理场景推理和 (a–c) 操纵由不同材料制成的物体方面取得了成功。
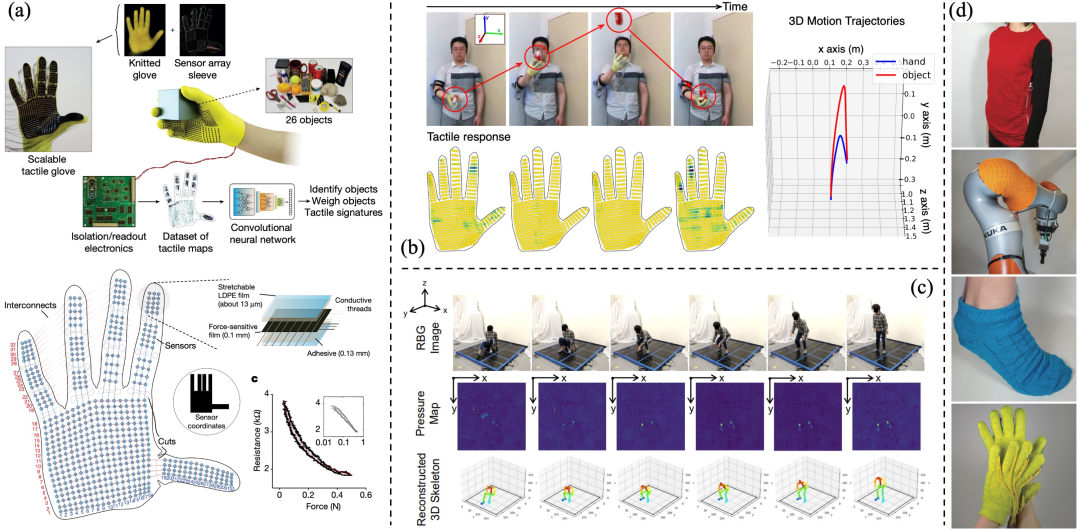 使用视觉和触觉的多模态传感平台。为了构建更好的结构化世界模型,我们需要富有表现力的多模态传感平台,其中包括所需的物理先验(例如,接触和力约束)。因此,我们以手套、袜子、背心和机器人袖子的形式构建了可扩展、可变形和灵活的触觉传感器,以获得更详细的物理交互建模,并研究各种物理活动的动态交互行为。(a)一种能够在手与物体交互过程中记录触觉信息的柔性手套。(b)触觉图像和视觉支持的手与物体动力学建模。(c)用于估计 3D 人体姿势的视觉监督触觉学习。(d)用于学习人与环境交互的 3D 共形触觉传感服装。
使用视觉和触觉的多模态传感平台。为了构建更好的结构化世界模型,我们需要富有表现力的多模态传感平台,其中包括所需的物理先验(例如,接触和力约束)。因此,我们以手套、袜子、背心和机器人袖子的形式构建了可扩展、可变形和灵活的触觉传感器,以获得更详细的物理交互建模,并研究各种物理活动的动态交互行为。(a)一种能够在手与物体交互过程中记录触觉信息的柔性手套。(b)触觉图像和视觉支持的手与物体动力学建模。(c)用于估计 3D 人体姿势的视觉监督触觉学习。(d)用于学习人与环境交互的 3D 共形触觉传感服装。
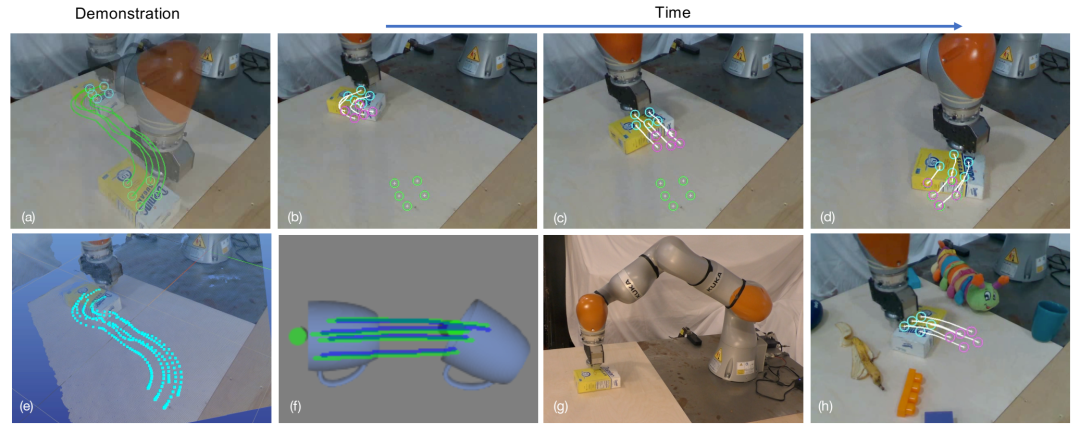 学习模型预测控制的关键点动态。(a)显示初始姿势(蓝色关键点)和目标姿势(绿色关键点)以及演示轨迹。(b)-(d)显示情节中不同点的 MPC。当前关键点为蓝色,白线和紫色关键点显示使用学习的动态模型从 MPC 算法优化的轨迹。目标关键点仍然显示为绿色。(e)在 3D 可视化器中显示演示轨迹。(f)说明类别级任务上的动态模型。实际关键点轨迹以绿色显示;使用学习模型预测的轨迹以蓝色显示。(g)我们的硬件设置概述。(h)视觉混乱的示例。
学习模型预测控制的关键点动态。(a)显示初始姿势(蓝色关键点)和目标姿势(绿色关键点)以及演示轨迹。(b)-(d)显示情节中不同点的 MPC。当前关键点为蓝色,白线和紫色关键点显示使用学习的动态模型从 MPC 算法优化的轨迹。目标关键点仍然显示为绿色。(e)在 3D 可视化器中显示演示轨迹。(f)说明类别级任务上的动态模型。实际关键点轨迹以绿色显示;使用学习模型预测的轨迹以蓝色显示。(g)我们的硬件设置概述。(h)视觉混乱的示例。
 在参考图像(左)和目标图像(右)上可视化学习到的视觉对应模型。目标图像中的彩色数字表示检测到的对应关系有效的概率。绿色标线表示具有高置信度分数的有效对应关系,红色标线表示由于遮挡,目标图像中不存在对应关系的情况,因此置信度概率较低。右下角显示了置信度热图。
在参考图像(左)和目标图像(右)上可视化学习到的视觉对应模型。目标图像中的彩色数字表示检测到的对应关系有效的概率。绿色标线表示具有高置信度分数的有效对应关系,红色标线表示由于遮挡,目标图像中不存在对应关系的情况,因此置信度概率较低。右下角显示了置信度热图。
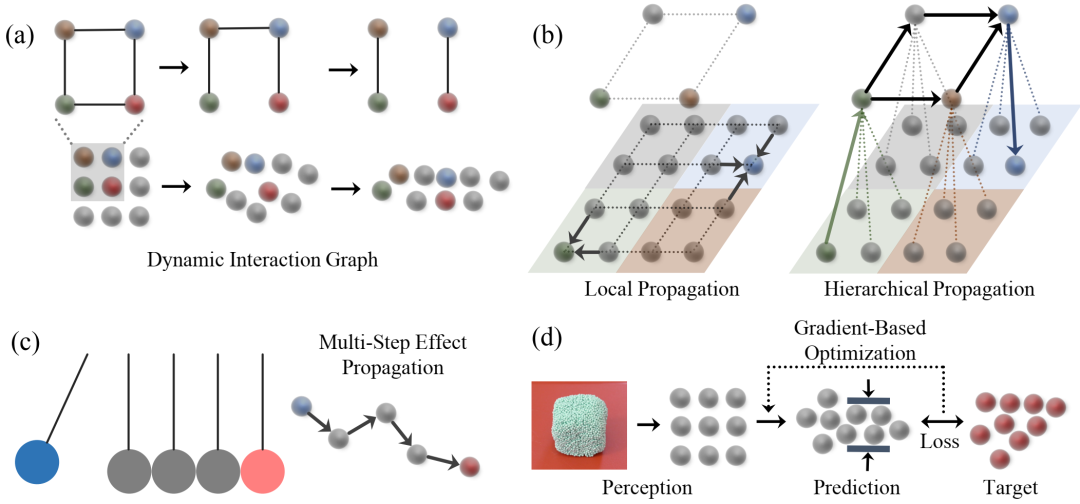 学习粒子动力学以进行控制。(a)DPI-Nets 学习粒子交互,同时随时间动态构建交互图。(b)构建分层图以进行多尺度效应传播。(c)多步骤消息传递以处理瞬时力传播。(d)使用学习到的模型进行感知和控制。我们的系统首先从视觉观察中重建基于粒子的形状。然后使用基于梯度的轨迹优化来搜索产生最理想输出的动作。
学习粒子动力学以进行控制。(a)DPI-Nets 学习粒子交互,同时随时间动态构建交互图。(b)构建分层图以进行多尺度效应传播。(c)多步骤消息传递以处理瞬时力传播。(d)使用学习到的模型进行感知和控制。我们的系统首先从视觉观察中重建基于粒子的形状。然后使用基于梯度的轨迹优化来搜索产生最理想输出的动作。
 前向模拟的定性结果。我们在四种环境(FluidFall、BoxBath、FluidShake 和 RiceGrip)中比较了地面实况 (GT) 和 HRN [Mrowca et al., 2018] 和我们的模型 (DPI-Net) 的部署。我们的 DPI-Net 的模拟效果明显更好。我们提供几帧的放大视图以显示细节。请观看我们的视频以了解更多实证结果。
前向模拟的定性结果。我们在四种环境(FluidFall、BoxBath、FluidShake 和 RiceGrip)中比较了地面实况 (GT) 和 HRN [Mrowca et al., 2018] 和我们的模型 (DPI-Net) 的部署。我们的 DPI-Net 的模拟效果明显更好。我们提供几帧的放大视图以显示细节。请观看我们的视频以了解更多实证结果。
 控制的定性结果。(a)FluidShake - 操纵一盒流体以匹配目标形状。结果和目标表示从剖面视图观看时的流体形状。(b)RiceGrip - 抓住可变形物体并将其塑造成目标形状。(c)现实世界中的 RiceGrip - 通过进行在线自适应将学习到的动力学和控制算法推广到现实世界。最后两列表示从顶部看到的最终形状。
控制的定性结果。(a)FluidShake - 操纵一盒流体以匹配目标形状。结果和目标表示从剖面视图观看时的流体形状。(b)RiceGrip - 抓住可变形物体并将其塑造成目标形状。(c)现实世界中的 RiceGrip - 通过进行在线自适应将学习到的动力学和控制算法推广到现实世界。最后两列表示从顶部看到的最终形状。
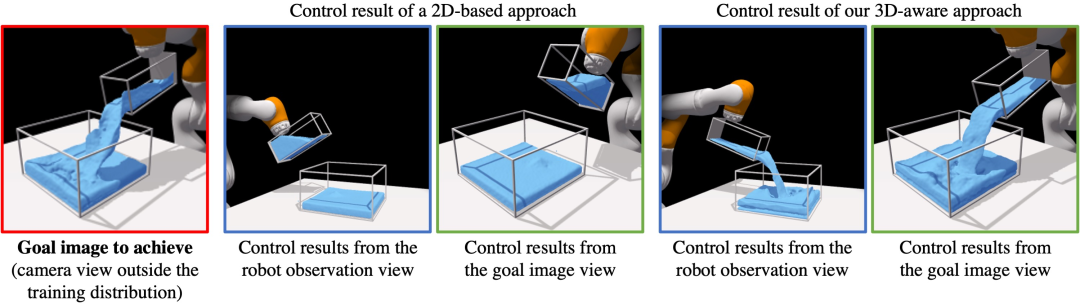 基于 2D 的基线和我们的 3D 感知方法之间的控制结果比较。此处的任务是实现左侧所示的配置,从训练分布之外的视角进行观察。代理仅从与目标截然不同的视角将单视图视觉观察作为输入(带有蓝色框架的图像)。我们的方法在这种情况下具有很好的泛化能力,并且优于基于 2D 的基线,展示了学习到的 3D 感知场景表示的优势。
基于 2D 的基线和我们的 3D 感知方法之间的控制结果比较。此处的任务是实现左侧所示的配置,从训练分布之外的视角进行观察。代理仅从与目标截然不同的视角将单视图视觉观察作为输入(带有蓝色框架的图像)。我们的方法在这种情况下具有很好的泛化能力,并且优于基于 2D 的基线,展示了学习到的 3D 感知场景表示的优势。
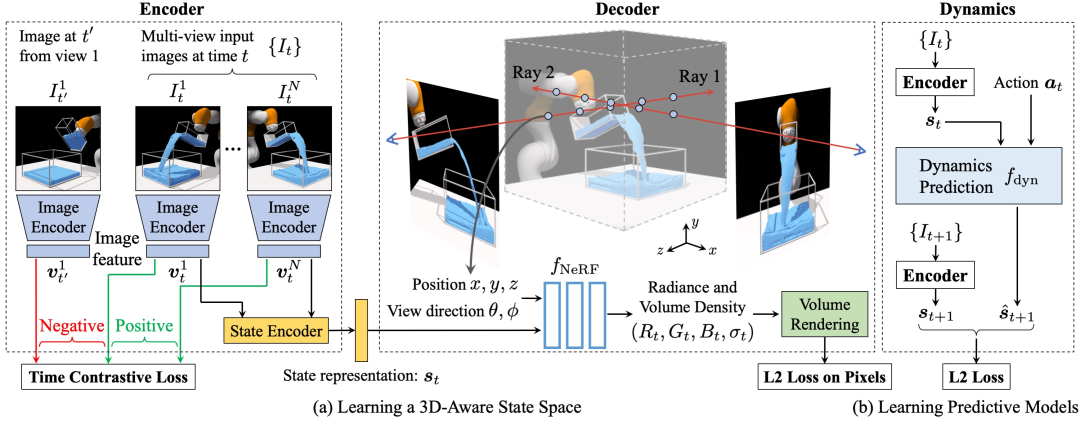 训练过程概述。左图:将输入图像映射到潜在场景表示的编码器。首先将图像发送到图像编码器以生成图像特征表示𝑣。然后,我们使用状态编码器将来自同一时间步骤的图像特征组合起来以获得状态表示𝑠𝑡。应用时间对比损失以使我们的模型对相机视点不变。中间:将场景表示作为输入并生成以给定视点为条件的视觉观察的解码器。我们使用 L2 损失来确保重建图像与地面真实图像相似。右图:动态模型,通过采用当前表示𝑠𝑡和动作𝑎𝑡来预测未来场景表示𝑠^𝑡+1。我们使用 L2 损失来强制预测的潜在表示与从真实视觉观察 𝐼𝑡+1 中提取的场景表示 𝑠𝑡+1 相似。
训练过程概述。左图:将输入图像映射到潜在场景表示的编码器。首先将图像发送到图像编码器以生成图像特征表示𝑣。然后,我们使用状态编码器将来自同一时间步骤的图像特征组合起来以获得状态表示𝑠𝑡。应用时间对比损失以使我们的模型对相机视点不变。中间:将场景表示作为输入并生成以给定视点为条件的视觉观察的解码器。我们使用 L2 损失来确保重建图像与地面真实图像相似。右图:动态模型,通过采用当前表示𝑠𝑡和动作𝑎𝑡来预测未来场景表示𝑠^𝑡+1。我们使用 L2 损失来强制预测的潜在表示与从真实视觉观察 𝐼𝑡+1 中提取的场景表示 𝑠𝑡+1 相似。
 前向预测和视点外推。(a) 我们首先将时间 𝑡 的输入图像输入到编码器以得出场景表示 𝑠𝑡。然后,动态模型将 𝑠𝑡 和相应的动作序列作为输入,以迭代方式预测未来。解码器根据预测的状态表示和输入视点合成视觉观察。(b) 我们提出了一个自动解码推理优化框架,以实现外推视点泛化。给定从训练分布之外的视点拍摄的输入图像 𝐼𝑡,编码器首先预测场景表示 𝑠𝑡。然后,解码器从 𝑠𝑡 重建观察 𝐼^𝑡 并从 𝐼𝑡 重建相机视点。我们计算 𝐼𝑡 和 𝐼^𝑡 之间的 L2 距离,并通过解码器反向传播梯度以更新 𝑠𝑡。更新过程重复 𝐾 次迭代,从而得到更准确的底层 3D 场景 𝑠𝑡。
前向预测和视点外推。(a) 我们首先将时间 𝑡 的输入图像输入到编码器以得出场景表示 𝑠𝑡。然后,动态模型将 𝑠𝑡 和相应的动作序列作为输入,以迭代方式预测未来。解码器根据预测的状态表示和输入视点合成视觉观察。(b) 我们提出了一个自动解码推理优化框架,以实现外推视点泛化。给定从训练分布之外的视点拍摄的输入图像 𝐼𝑡,编码器首先预测场景表示 𝑠𝑡。然后,解码器从 𝑠𝑡 重建观察 𝐼^𝑡 并从 𝐼𝑡 重建相机视点。我们计算 𝐼𝑡 和 𝐼^𝑡 之间的 L2 距离,并通过解码器反向传播梯度以更新 𝑠𝑡。更新过程重复 𝐾 次迭代,从而得到更准确的底层 3D 场景 𝑠𝑡。
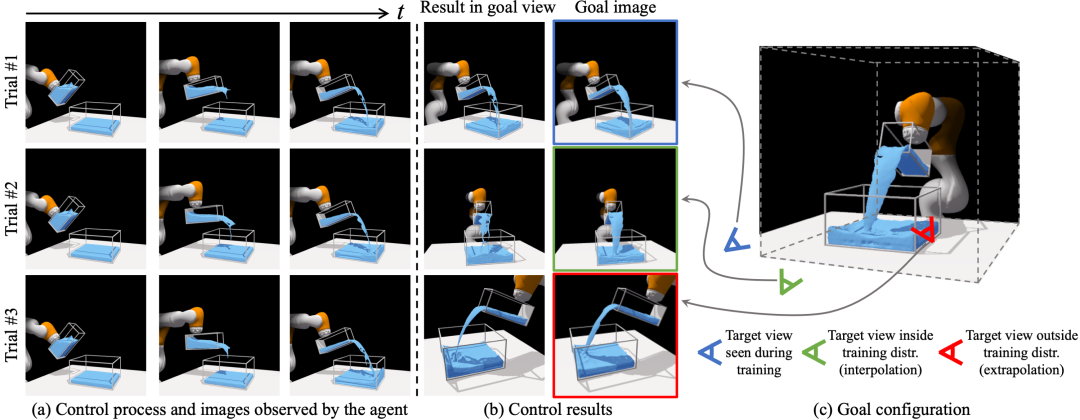 我们的方法在三种测试场景中的定性控制结果。右侧的图像显示了我们想要实现的目标配置。左边的三列显示控制过程,它们也是代理的输入图像。第四列是来自与目标图像相同视点的控制结果。试验 #1 使用与代理不同的视点来指定目标,但在训练期间遇到过。试验 #2 使用作为训练视点插值的目标视图。试验 #3 使用训练分布之外的外推视点。我们的方法在所有设置中都表现良好。
我们的方法在三种测试场景中的定性控制结果。右侧的图像显示了我们想要实现的目标配置。左边的三列显示控制过程,它们也是代理的输入图像。第四列是来自与目标图像相同视点的控制结果。试验 #1 使用与代理不同的视点来指定目标,但在训练期间遇到过。试验 #2 使用作为训练视点插值的目标视图。试验 #3 使用训练分布之外的外推视点。我们的方法在所有设置中都表现良好。
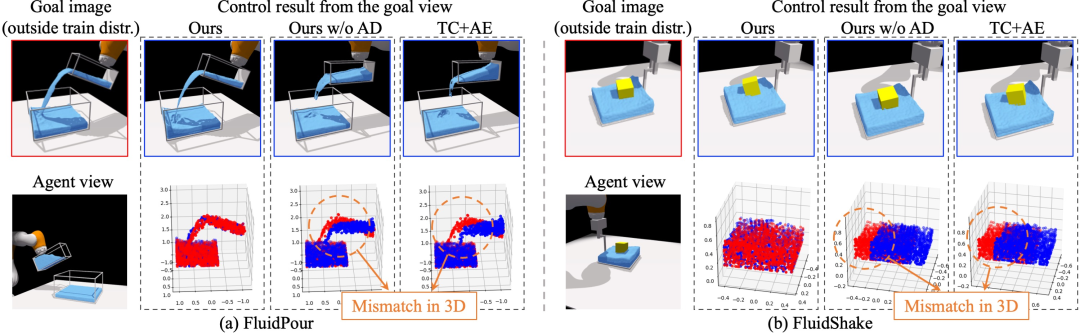 我们的方法与基线方法在控制任务上的定性比较。我们展示了 FluidPour 和 FluidShake 环境中的闭环控制结果。目标图像视点(每个块的左上图像)位于训练分布之外,与代理观察到的视点(每个块的左下图像)不同。我们的最终控制结果比不执行自动解码测试时间优化的变体(我们的无 AD)和表现最佳的基线(TC+AE)好得多,这两者都未能完成任务,并且它们的控制结果(蓝点)在流体和浮动立方体的 3D 点空间中测量时与目标配置(红点)明显偏离。
我们的方法与基线方法在控制任务上的定性比较。我们展示了 FluidPour 和 FluidShake 环境中的闭环控制结果。目标图像视点(每个块的左上图像)位于训练分布之外,与代理观察到的视点(每个块的左下图像)不同。我们的最终控制结果比不执行自动解码测试时间优化的变体(我们的无 AD)和表现最佳的基线(TC+AE)好得多,这两者都未能完成任务,并且它们的控制结果(蓝点)在流体和浮动立方体的 3D 点空间中测量时与目标配置(红点)明显偏离。
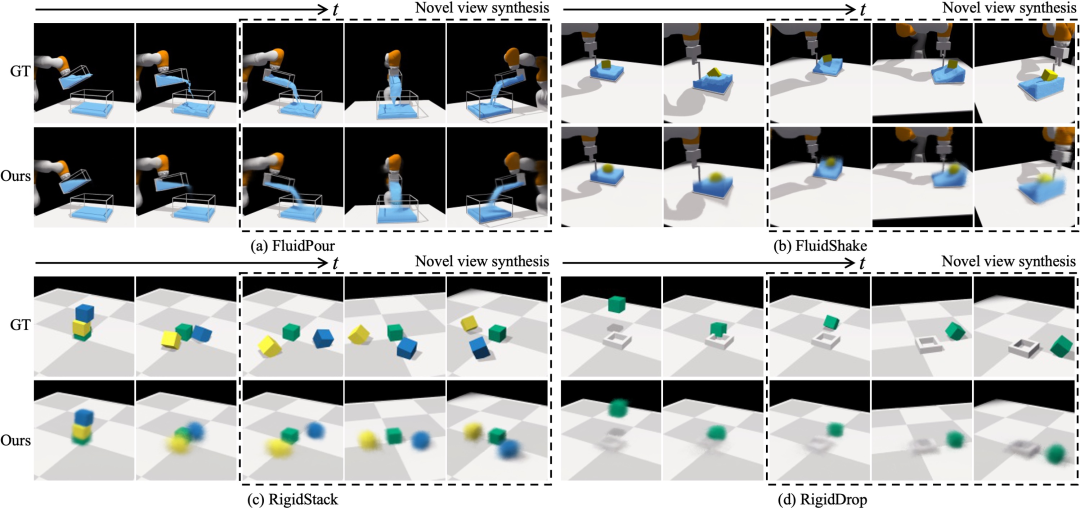 在四种环境下进行前向预测和新视图合成。给定一个场景表征和一个输入动作序列,我们的动态模型会预测后续的潜在场景表征,并将其用作解码器模型的输入,以根据不同的视点重建相应的视觉观察。在每个块中,我们根据从左到右的开环未来动态预测渲染图像。虚线框中的图像将我们模型在最后一步的新视图合成结果与来自三个不同视点的地面实况进行了比较。
在四种环境下进行前向预测和新视图合成。给定一个场景表征和一个输入动作序列,我们的动态模型会预测后续的潜在场景表征,并将其用作解码器模型的输入,以根据不同的视点重建相应的视觉观察。在每个块中,我们根据从左到右的开环未来动态预测渲染图像。虚线框中的图像将我们模型在最后一步的新视图合成结果与来自三个不同视点的地面实况进行了比较。
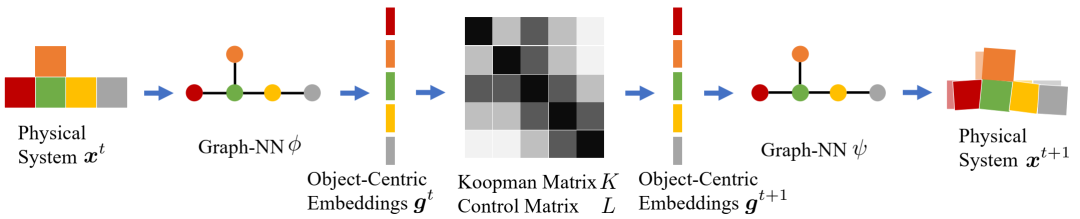 组合 Koopman 算子概述。图神经网络 𝜑 接收物理系统 𝑥𝑡 的当前状态,并在 Koopman 空间 𝑔𝑡 中生成以对象为中心的表示。然后,我们使用从公式 5.6 或公式 5.8 确定的分块 Koopman 矩阵 𝐾 和控制矩阵 𝐿 来预测下一个时间步 𝑔𝑡+1 中的 Koopman 嵌入。请注意,在 𝐾 和 𝐿 中,相同关系的对象对共享相同的子矩阵。另一个图神经网络 𝜓 将 𝑔𝑡+1 映射回原始状态空间,即 𝑥𝑡+1。𝑔𝑡 和 𝑔𝑡+1 之间的映射是线性的,并且在所有时间步骤中共享,我们可以迭代地将 𝐾 和 𝐿 应用于 Koopman 嵌入并将多个步骤滚动到未来。该公式可以实现高效的系统识别和控制综合。
组合 Koopman 算子概述。图神经网络 𝜑 接收物理系统 𝑥𝑡 的当前状态,并在 Koopman 空间 𝑔𝑡 中生成以对象为中心的表示。然后,我们使用从公式 5.6 或公式 5.8 确定的分块 Koopman 矩阵 𝐾 和控制矩阵 𝐿 来预测下一个时间步 𝑔𝑡+1 中的 Koopman 嵌入。请注意,在 𝐾 和 𝐿 中,相同关系的对象对共享相同的子矩阵。另一个图神经网络 𝜓 将 𝑔𝑡+1 映射回原始状态空间,即 𝑥𝑡+1。𝑔𝑡 和 𝑔𝑡+1 之间的映射是线性的,并且在所有时间步骤中共享,我们可以迭代地将 𝐾 和 𝐿 应用于 Koopman 嵌入并将多个步骤滚动到未来。该公式可以实现高效的系统识别和控制综合。
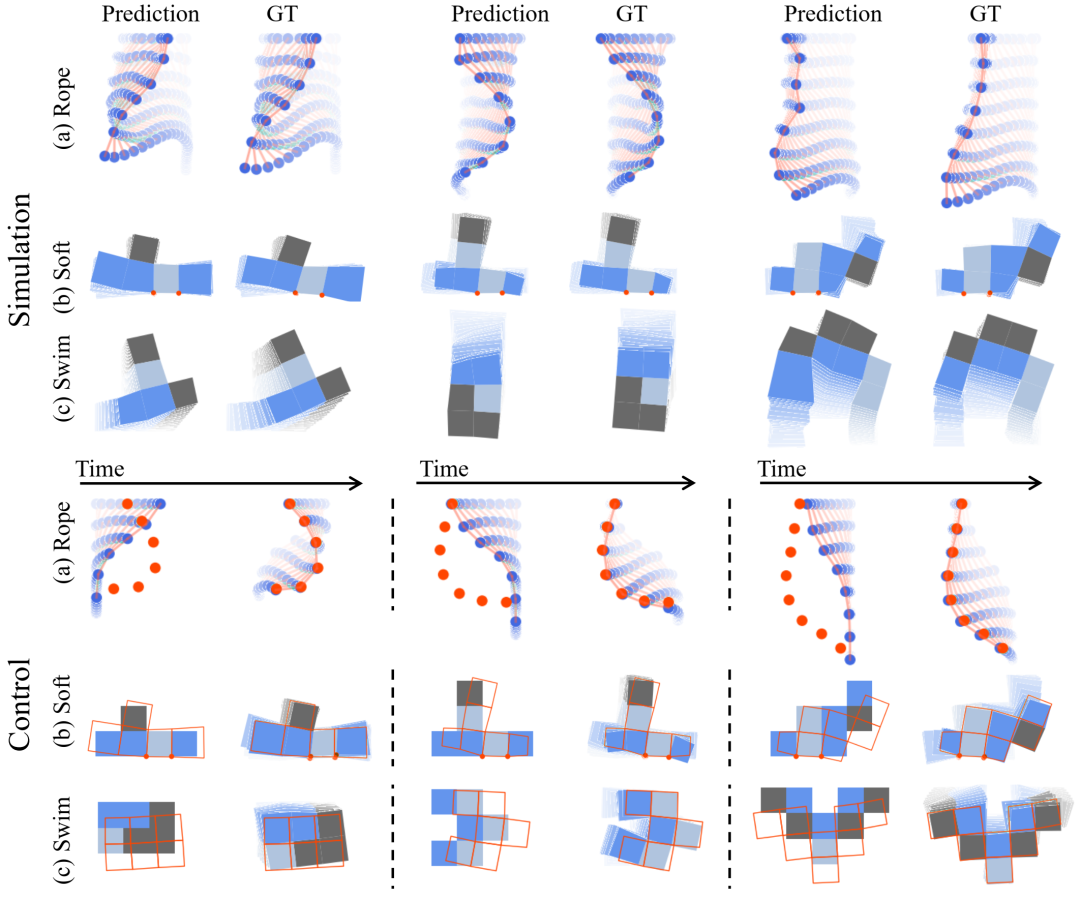 定性结果。顶部:我们的模型预测在很长一段时间内与基本事实相符。底部:对于控制,我们使用红点或框架来指示目标。我们将从我们识别的模型生成的控制信号应用于原始模拟器,这使代理能够准确地实现目标。请参阅我们网站上的补充视频以了解更多结果。
定性结果。顶部:我们的模型预测在很长一段时间内与基本事实相符。底部:对于控制,我们使用红点或框架来指示目标。我们将从我们识别的模型生成的控制信号应用于原始模拟器,这使代理能够准确地实现目标。请参阅我们网站上的补充视频以了解更多结果。
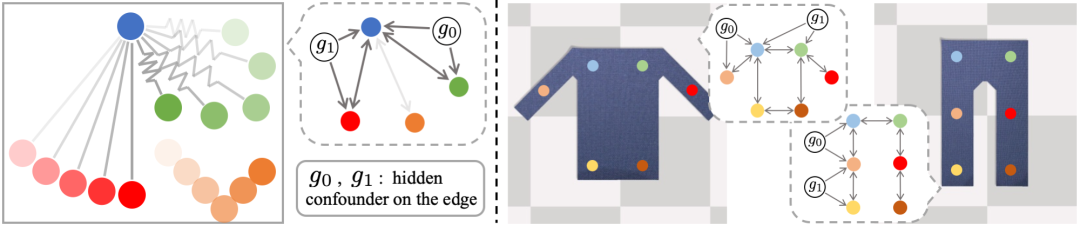 从视频中发现物理系统中的因果关系。左图显示球体通过不可见的物理关系(显示为灰色)连接在一起,四处移动。边缘类型和边缘参数等隐藏的混杂变量对底层系统的行为有因果影响。我们人类可以观察球体,推断球体之间边缘的存在和变量,并预测未来。类似地,在右侧显示的布料环境中,我们可以通过在图像上放置时间一致的关键点并确定它们之间的因果关系来找到降阶表示,以反映布料的拓扑结构。
从视频中发现物理系统中的因果关系。左图显示球体通过不可见的物理关系(显示为灰色)连接在一起,四处移动。边缘类型和边缘参数等隐藏的混杂变量对底层系统的行为有因果影响。我们人类可以观察球体,推断球体之间边缘的存在和变量,并预测未来。类似地,在右侧显示的布料环境中,我们可以通过在图像上放置时间一致的关键点并确定它们之间的因果关系来找到降阶表示,以反映布料的拓扑结构。
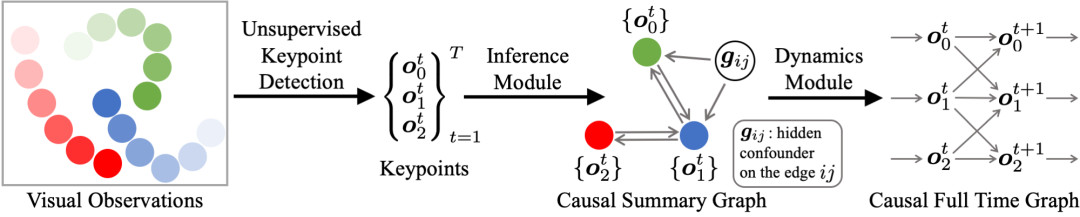 模型概述。视觉因果发现网络 (V-CDN) 由三个组件组成:(a) 感知模块,用于处理图像并提取无监督关键点作为状态表示;(b) 推理模块,用于观察关键点的运动并确定因果关系的存在以及相关的隐藏混杂因素;(c) 动态模块,通过调节当前状态和推断的因果摘要图来预测未来。
模型概述。视觉因果发现网络 (V-CDN) 由三个组件组成:(a) 感知模块,用于处理图像并提取无监督关键点作为状态表示;(b) 推理模块,用于观察关键点的运动并确定因果关系的存在以及相关的隐藏混杂因素;(c) 动态模块,通过调节当前状态和推断的因果摘要图来预测未来。
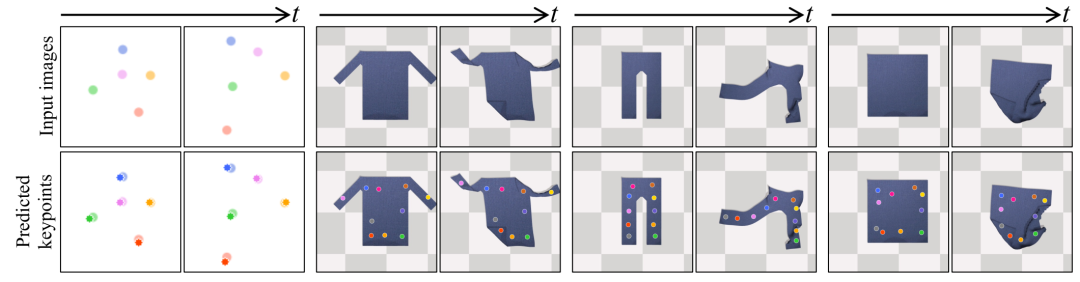 无监督关键点检测。第一行显示输入图像,第二行显示预测关键点与图像之间的叠加。感知模块在图像的前景上分配关键点,并在不同帧中持续跟踪对象。
无监督关键点检测。第一行显示输入图像,第二行显示预测关键点与图像之间的叠加。感知模块在图像的前景上分配关键点,并在不同帧中持续跟踪对象。
 预测因果总结图和未来的定性结果。我们的推理模块观察一小段图像序列并执行因果总结图的一次性发现,从而恢复多体环境中的地面真实图并捕获布料环境中的底层连接结构。右边四列中的未填充圆圈表示模型对未来的预测。我们将预测的未来关键点与真实未来叠加以进行比较。
预测因果总结图和未来的定性结果。我们的推理模块观察一小段图像序列并执行因果总结图的一次性发现,从而恢复多体环境中的地面真实图并捕获布料环境中的底层连接结构。右边四列中的未填充圆圈表示模型对未来的预测。我们将预测的未来关键点与真实未来叠加以进行比较。
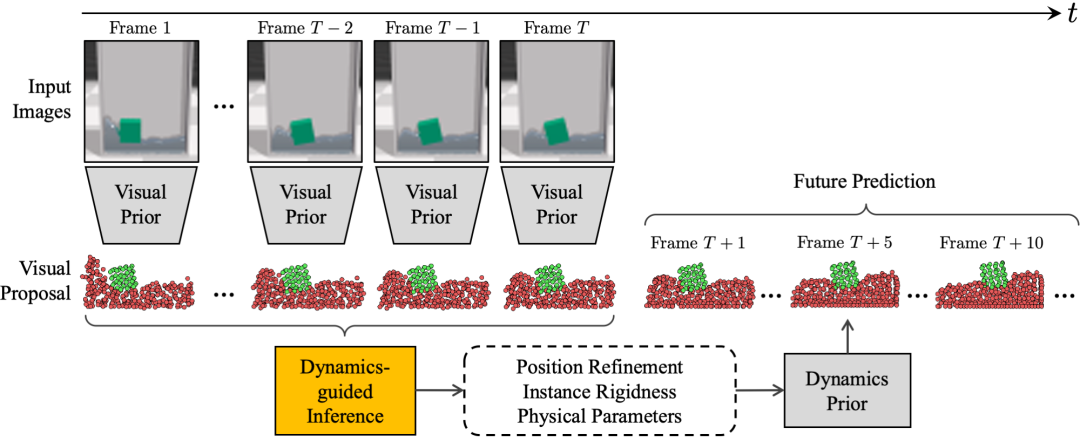 视觉基础物理学习器 (VGPL) 概述。该模型将一系列图像帧作为输入,推理底层物理属性,并做出未来预测。输入帧首先经过感知模块 (视觉先验),该模块通过给出粒子位置和实例分组的建议,以粒子表示形式重建输入场景。然后,推理模块通过更新粒子位置、估计每个实例的刚度和预测场景的物理参数来细化建议。动力学模块 (动力学先验) 接收推理模块的输出并预测未来的粒子位置。请查看我们的项目页面以获取视频插图:http://visual-physics-grounding.csail.mit.edu/。
视觉基础物理学习器 (VGPL) 概述。该模型将一系列图像帧作为输入,推理底层物理属性,并做出未来预测。输入帧首先经过感知模块 (视觉先验),该模块通过给出粒子位置和实例分组的建议,以粒子表示形式重建输入场景。然后,推理模块通过更新粒子位置、估计每个实例的刚度和预测场景的物理参数来细化建议。动力学模块 (动力学先验) 接收推理模块的输出并预测未来的粒子位置。请查看我们的项目页面以获取视频插图:http://visual-physics-grounding.csail.mit.edu/。
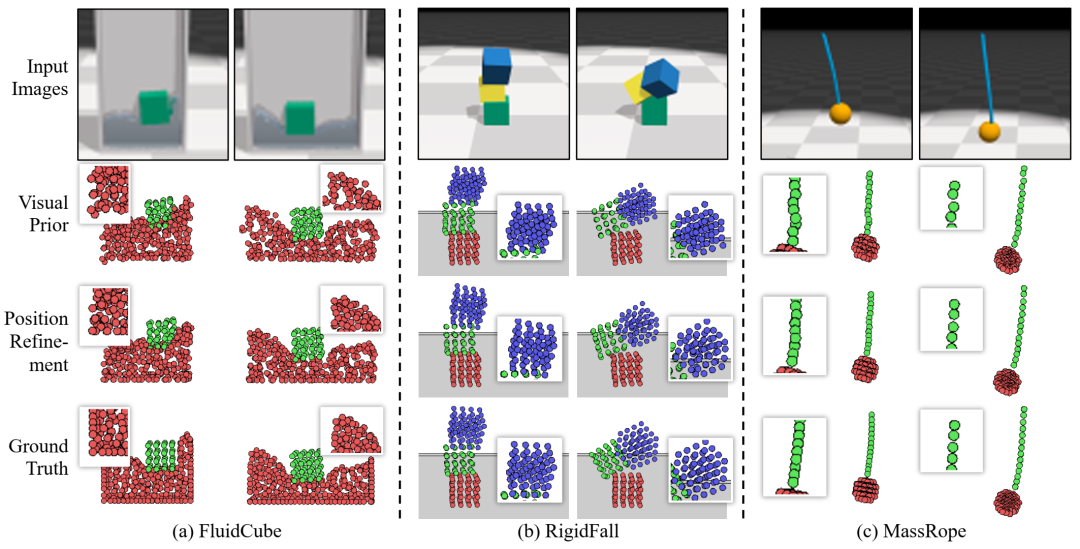 粒子位置细化的定性结果。对于每个环境,我们并排比较了视觉先验输出的两帧、位置细化输出的两帧和地面实况的两帧。对于每个输出帧,我们提供放大视图来说明粒子的细节。细化后,(a) 流体可以更好地保持密度约束,(b) 刚性物体更接近正确的形状,(c) 绳子变得不那么颠簸。细化后预测的粒子位置都更接近地面实况。
粒子位置细化的定性结果。对于每个环境,我们并排比较了视觉先验输出的两帧、位置细化输出的两帧和地面实况的两帧。对于每个输出帧,我们提供放大视图来说明粒子的细节。细化后,(a) 流体可以更好地保持密度约束,(b) 刚性物体更接近正确的形状,(c) 绳子变得不那么颠簸。细化后预测的粒子位置都更接近地面实况。
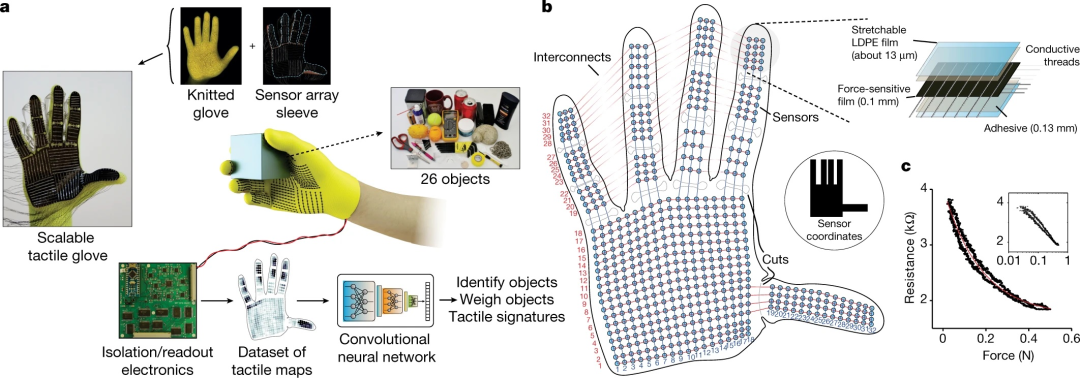 STAG 是一个从人类抓握中学习的平台。(a)STAG 由一个传感器阵列组成,该阵列有 548 个元件,覆盖整个手部,并附在定制针织手套上。电读出电路用于以大约 7.3 fps 的速度获取每个传感器记录的法向力。使用此设置,我们可以在与 26 个不同物体交互时记录 135,187 个触觉图的数据集。纯触觉信息训练的深度卷积神经网络可用于识别或称量物体并探索人类抓握的触觉特征。中间显示的手套是渲染图。(b)STAG 架构的设计显示了 548 个传感器的各个位置,以及互连、插槽和 64 个电极。压阻传感器阵列由层压简单材料制成,可以轻松扩展到不同的架构(图 8-6 和 8-8)。(c) 每个传感器元件通过显示贯穿膜电阻的变化来响应法向力。传感器特性在多个设备之间可重复,并且长期可靠(图 8-5)。插图以对数力标度显示了相同的特性(轴标签与主图相同)。
STAG 是一个从人类抓握中学习的平台。(a)STAG 由一个传感器阵列组成,该阵列有 548 个元件,覆盖整个手部,并附在定制针织手套上。电读出电路用于以大约 7.3 fps 的速度获取每个传感器记录的法向力。使用此设置,我们可以在与 26 个不同物体交互时记录 135,187 个触觉图的数据集。纯触觉信息训练的深度卷积神经网络可用于识别或称量物体并探索人类抓握的触觉特征。中间显示的手套是渲染图。(b)STAG 架构的设计显示了 548 个传感器的各个位置,以及互连、插槽和 64 个电极。压阻传感器阵列由层压简单材料制成,可以轻松扩展到不同的架构(图 8-6 和 8-8)。(c) 每个传感器元件通过显示贯穿膜电阻的变化来响应法向力。传感器特性在多个设备之间可重复,并且长期可靠(图 8-5)。插图以对数力标度显示了相同的特性(轴标签与主图相同)。
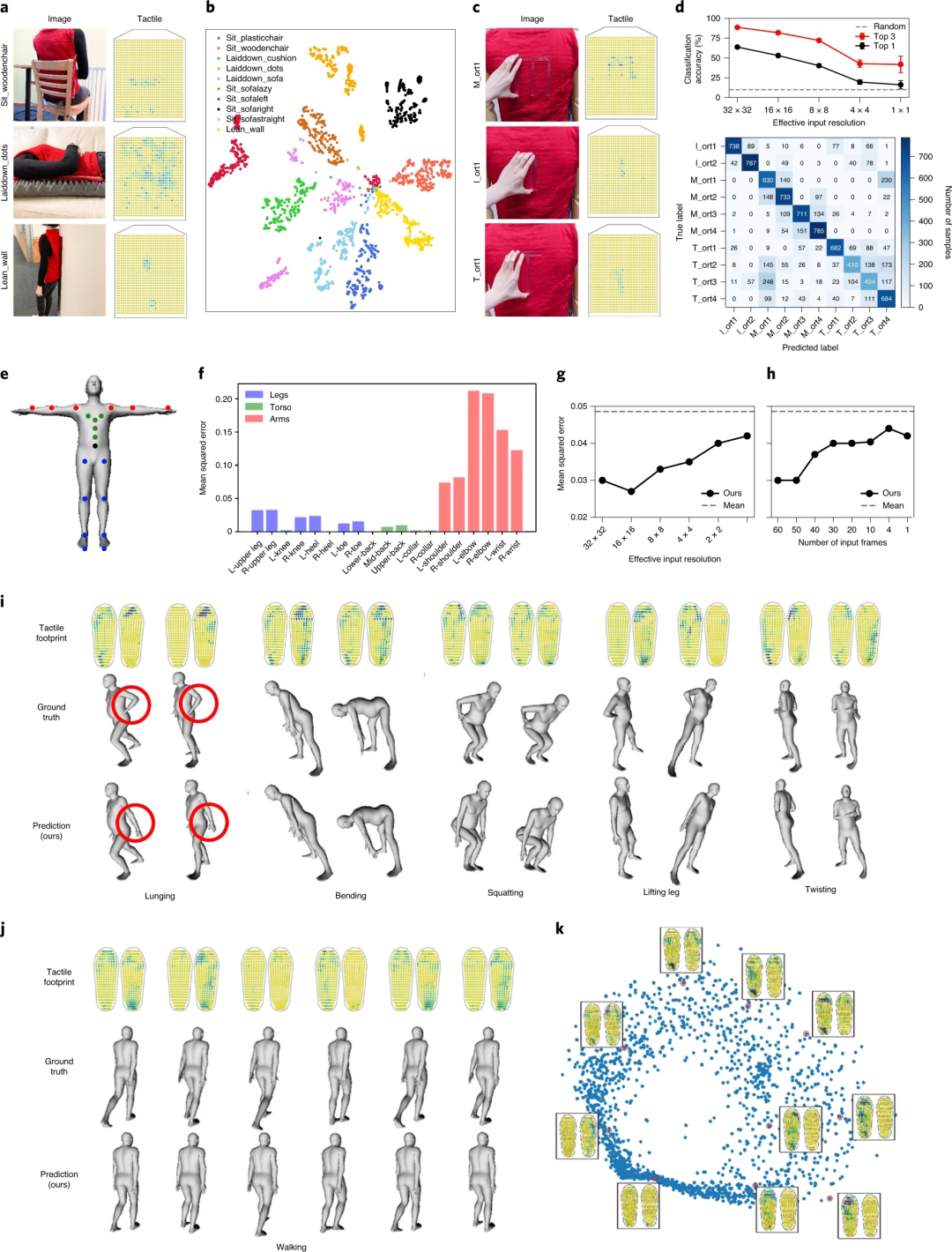
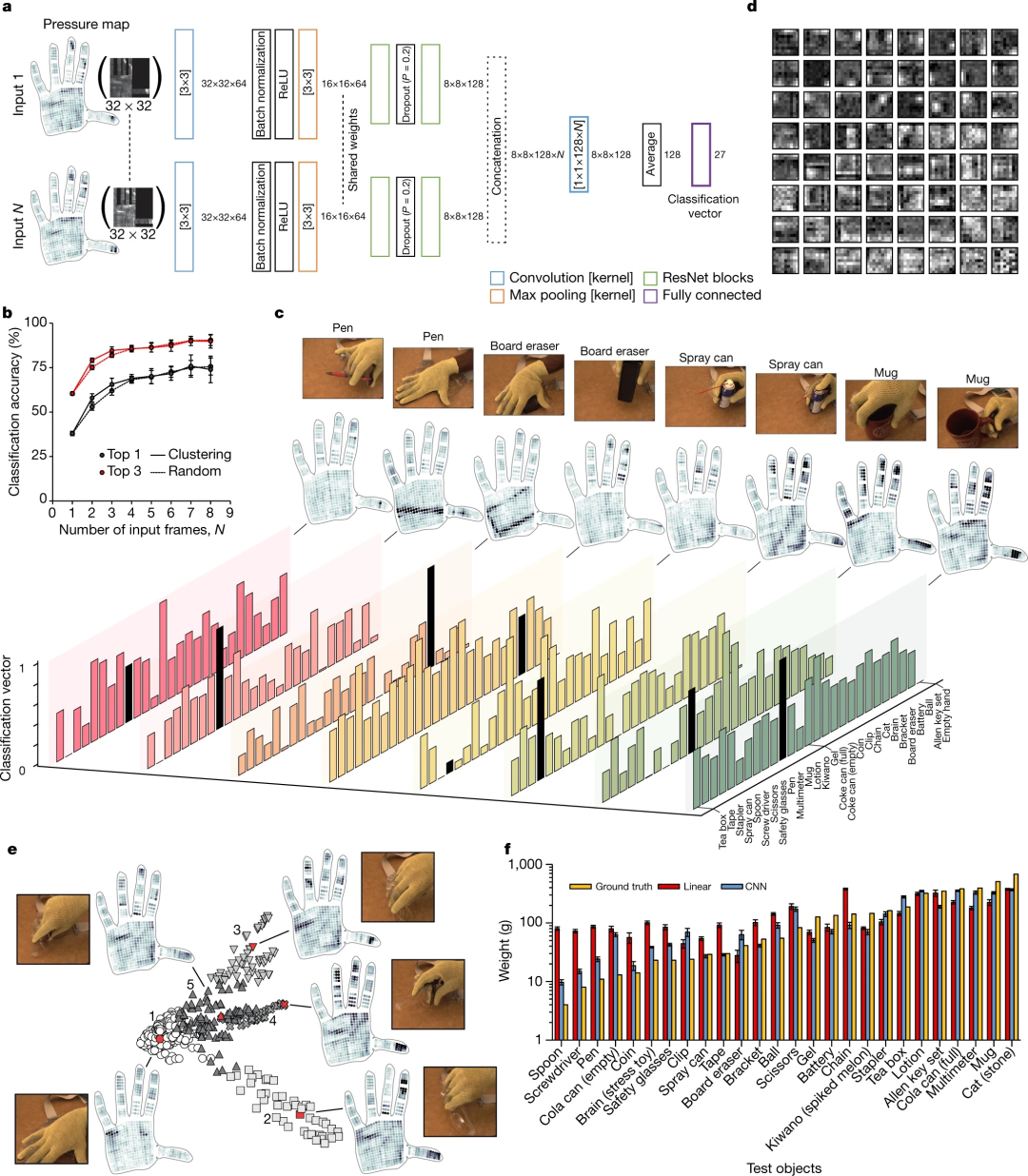 根据触觉信息识别物体并称量物体。(a)用于根据触觉信息识别物体的 CNN 架构以 N 个触觉数据阵列(32 × 32 阵列)作为输入。整流线性单元 (ReLU) 用于将非线性引入模型。“Dropout”是一种正则化技术,可随机删除网络节点以减少对训练数据的过度拟合。“最大池化”用于通过仅传递局部最高激活来降低数据的维数。(b)与随机选择输入相比,使用来自 N 个不同簇的一组多样化触觉图作为输入时,物体识别准确度会提高;结果是十次训练运行的平均值(平均值 ± s.d.)。这里每个不同的簇(如 (e) 所示)都是一组类似的抓握动作。(c)单手操作物体时的一组代表性示例。显示了触觉图、相应的视觉图像和来自单个触觉图输入的分类向量(底部)——真实对象标签用黑色标记。(d)显示了由缩放版本的网络学习到的卷积滤波器(参见第 8.2 节)。请注意,输入和网络已缩放以在更高的分辨率下可视化滤波器。图 8-10i-j 分别显示了网络的原始 3×3 卷积滤波器和原始 ImageNet 训练的 ResNet 滤波器。(e)对来自单个对象交互的触觉图进行聚类有助于识别与该对象相对应的一组不同的触觉图。五个不同的聚类用于提取五个触觉输入(N),以红色显示。(f)基于“留一法”的 CNN 权重预测结果与线性模型的比较(平均值±95%置信区间)。
根据触觉信息识别物体并称量物体。(a)用于根据触觉信息识别物体的 CNN 架构以 N 个触觉数据阵列(32 × 32 阵列)作为输入。整流线性单元 (ReLU) 用于将非线性引入模型。“Dropout”是一种正则化技术,可随机删除网络节点以减少对训练数据的过度拟合。“最大池化”用于通过仅传递局部最高激活来降低数据的维数。(b)与随机选择输入相比,使用来自 N 个不同簇的一组多样化触觉图作为输入时,物体识别准确度会提高;结果是十次训练运行的平均值(平均值 ± s.d.)。这里每个不同的簇(如 (e) 所示)都是一组类似的抓握动作。(c)单手操作物体时的一组代表性示例。显示了触觉图、相应的视觉图像和来自单个触觉图输入的分类向量(底部)——真实对象标签用黑色标记。(d)显示了由缩放版本的网络学习到的卷积滤波器(参见第 8.2 节)。请注意,输入和网络已缩放以在更高的分辨率下可视化滤波器。图 8-10i-j 分别显示了网络的原始 3×3 卷积滤波器和原始 ImageNet 训练的 ResNet 滤波器。(e)对来自单个对象交互的触觉图进行聚类有助于识别与该对象相对应的一组不同的触觉图。五个不同的聚类用于提取五个触觉输入(N),以红色显示。(f)基于“留一法”的 CNN 权重预测结果与线性模型的比较(平均值±95%置信区间)。
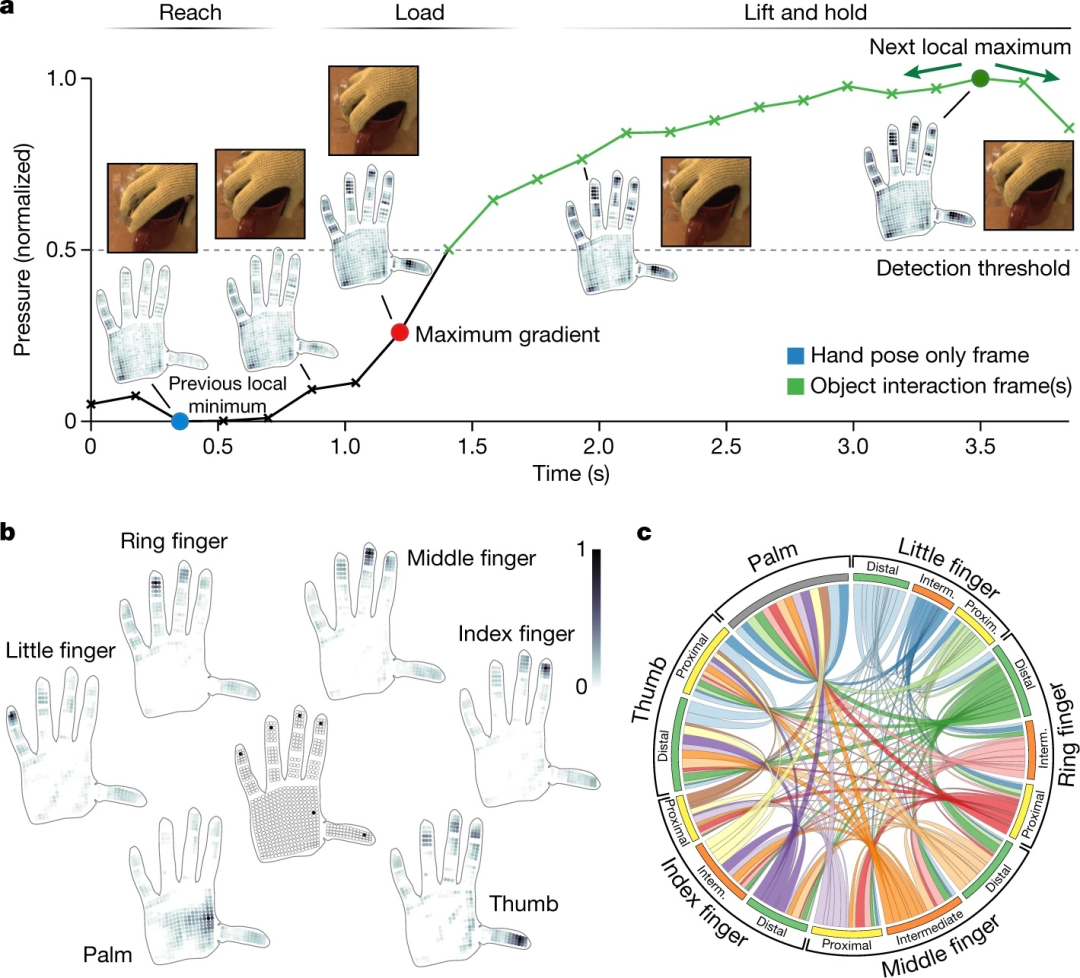 物体操作和抓握过程中手部各区域之间的协作性。(a)在典型的交互序列中,手部逐渐变得灵活,直到接触点(到达阶段),并且在握住物体时会经历触觉力的突然上升。我们使用动作负载阶段的最大梯度(红色)将物体握持时的触觉图分解为两部分 - 手势信号(蓝色)和物体相关压力(从绿色帧中减去蓝色帧)。物体交互帧被自动检测并标记为绿色;完整的信号分解细节在方法中描述。(b)分解的物体相关压力帧集可用于提取特定传感器与整个手之间的相关性。此处的地图显示了选定像素(在中央手中标记)与整个手之间的相关性。大多数指尖与其他手指和拇指一起使用(精确抓握的标志),而手掌上的区域通常在抓握物体时使用,这会导致整个手掌与物体接触。(c) 圆形图显示了手的不同部位之间的相对对应关系(见第 8.2 节)。大手指的远端指骨通常与拇指一起使用,在抓握物体时产生力量,并产生强烈的协同作用。
物体操作和抓握过程中手部各区域之间的协作性。(a)在典型的交互序列中,手部逐渐变得灵活,直到接触点(到达阶段),并且在握住物体时会经历触觉力的突然上升。我们使用动作负载阶段的最大梯度(红色)将物体握持时的触觉图分解为两部分 - 手势信号(蓝色)和物体相关压力(从绿色帧中减去蓝色帧)。物体交互帧被自动检测并标记为绿色;完整的信号分解细节在方法中描述。(b)分解的物体相关压力帧集可用于提取特定传感器与整个手之间的相关性。此处的地图显示了选定像素(在中央手中标记)与整个手之间的相关性。大多数指尖与其他手指和拇指一起使用(精确抓握的标志),而手掌上的区域通常在抓握物体时使用,这会导致整个手掌与物体接触。(c) 圆形图显示了手的不同部位之间的相对对应关系(见第 8.2 节)。大手指的远端指骨通常与拇指一起使用,在抓握物体时产生力量,并产生强烈的协同作用。
 STAG 图像和读出电路架构。(a) 电极绝缘之前完成的 STAG 图像。(b) STAG 扫描图。(c) 基于电气接地的信号隔离电路(基于 D’Alessio [1999])。通过将 32 个单刀双掷 (SPDT) 开关之一接地来选择读出期间的活动行。使用 32:1 模拟开关一次选择 32 列中的一列。这里 𝑅𝑐 是充电电阻,𝑉ref 是参考电压,𝑅𝑔 设置放大器增益。(d) 与 STAG 接口的预制印刷电路板。右上角和底部显示的两个连接器连接到传感器矩阵的列和行电极。充电电阻 (𝑅𝑐) 位于印刷电路板的背面。
STAG 图像和读出电路架构。(a) 电极绝缘之前完成的 STAG 图像。(b) STAG 扫描图。(c) 基于电气接地的信号隔离电路(基于 D’Alessio [1999])。通过将 32 个单刀双掷 (SPDT) 开关之一接地来选择读出期间的活动行。使用 32:1 模拟开关一次选择 32 列中的一列。这里 𝑅𝑐 是充电电阻,𝑉ref 是参考电压,𝑅𝑔 设置放大器增益。(d) 与 STAG 接口的预制印刷电路板。右上角和底部显示的两个连接器连接到传感器矩阵的列和行电极。充电电阻 (𝑅𝑐) 位于印刷电路板的背面。
 传感器架构和常规 32 × 32 阵列。(a) 传感器层压架构的简化版本。(b) 传感器通过层压 FSF 以及每侧的正交电极组装而成,这些电极由一层双面胶和可拉伸的 LDPE 薄膜固定并绝缘(参见第 8.2 节)。(c) 用于组装平行电极的夹具。各个电极可以像针一样穿入结构中,以组装间距为 2.5 毫米的平行电极。(d) (a) 中所示架构的组装版本。(e) 基于 (b) 中设计的 STAG 的常规 32 × 32 阵列版本。
传感器架构和常规 32 × 32 阵列。(a) 传感器层压架构的简化版本。(b) 传感器通过层压 FSF 以及每侧的正交电极组装而成,这些电极由一层双面胶和可拉伸的 LDPE 薄膜固定并绝缘(参见第 8.2 节)。(c) 用于组装平行电极的夹具。各个电极可以像针一样穿入结构中,以组装间距为 2.5 毫米的平行电极。(d) (a) 中所示架构的组装版本。(e) 基于 (b) 中设计的 STAG 的常规 32 × 32 阵列版本。
 对平面上 32 × 32 规则阵列上的九个物体进行采样记录。在平面上放置的规则传感器阵列(图 8-6d)上操纵九个不同的物体。这些物体的静止模式很容易看到。用尖锐物体(如笔或刺角瓜的针头)按压触觉阵列会产生具有单一传感器分辨率的信号。
对平面上 32 × 32 规则阵列上的九个物体进行采样记录。在平面上放置的规则传感器阵列(图 8-6d)上操纵九个不同的物体。这些物体的静止模式很容易看到。用尖锐物体(如笔或刺角瓜的针头)按压触觉阵列会产生具有单一传感器分辨率的信号。
 可拉伸传感器阵列的膨胀设计。(a)从 FSF 激光切割的标准膨胀设计。(b)膨胀的实际设计包括用于布线电极的孔(以红色和蓝色显示),以及允许方形传感岛旋转的槽,从而增强了传感器阵列的可拉伸性。(c)制造阵列的特写,显示绝缘之前的导电线电极。(d)具有膨胀设计的完全制造的 10 × 10 阵列。(e)膨胀图案化使传感器阵列可以轻松折叠、挤压和拉伸而不会造成损坏。(f)阵列还可以在多个方向上拉伸。
可拉伸传感器阵列的膨胀设计。(a)从 FSF 激光切割的标准膨胀设计。(b)膨胀的实际设计包括用于布线电极的孔(以红色和蓝色显示),以及允许方形传感岛旋转的槽,从而增强了传感器阵列的可拉伸性。(c)制造阵列的特写,显示绝缘之前的导电线电极。(d)具有膨胀设计的完全制造的 10 × 10 阵列。(e)膨胀图案化使传感器阵列可以轻松折叠、挤压和拉伸而不会造成损坏。(f)阵列还可以在多个方向上拉伸。
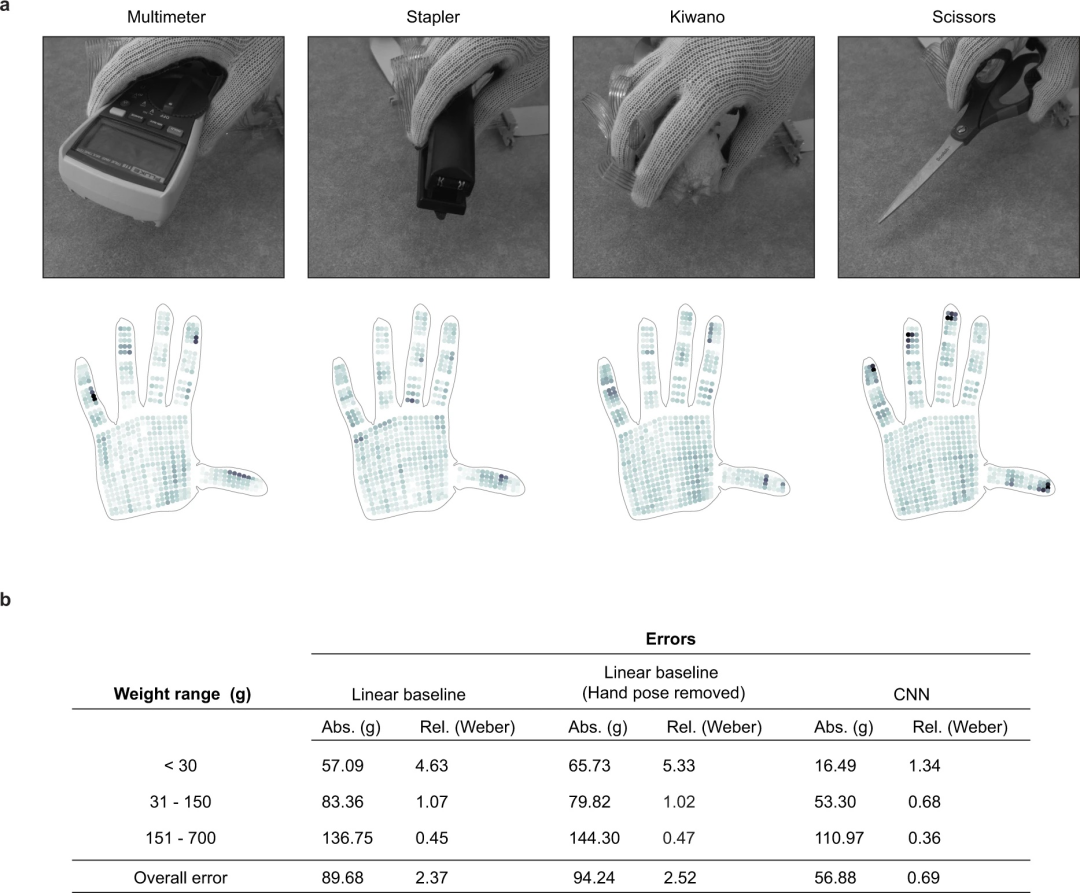 重量估计示例和性能。(a)来自重量估计数据集的四个代表性示例,其中使用多指抓取从顶部提起物体。(b)重量估计性能以每个重量间隔的平均绝对误差和相对误差(归一化为每个物体的重量)表示。相对误差类似于韦伯分数。我们观察到,无论是否移除手势信号,CNN 的表现都优于线性基线。两个线性基线的总体误差相当。
重量估计示例和性能。(a)来自重量估计数据集的四个代表性示例,其中使用多指抓取从顶部提起物体。(b)重量估计性能以每个重量间隔的平均绝对误差和相对误差(归一化为每个物体的重量)表示。相对误差类似于韦伯分数。我们观察到,无论是否移除手势信号,CNN 的表现都优于线性基线。两个线性基线的总体误差相当。
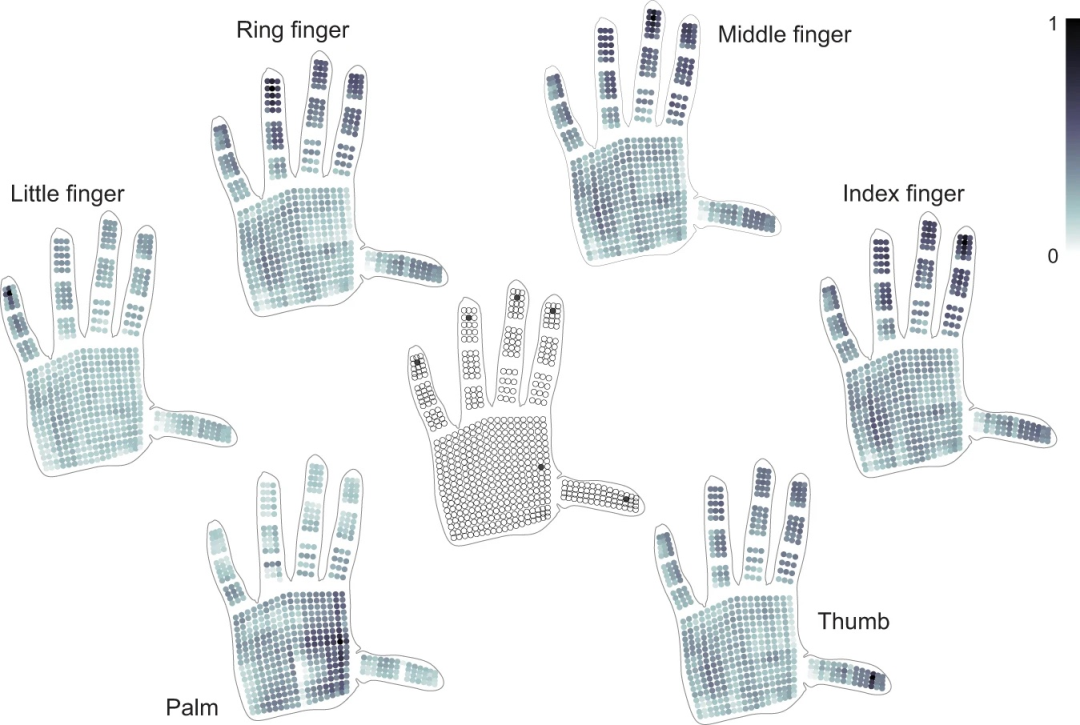 使用分解后的手势信号的六个单独传感器的对应图。从物体交互中分解出的手势信号用于集体提取传感器和整只手之间的相关性(类似于使用分解后的物体相关信号的图 8-3b)。与图 8-3b 不同,指尖处的像素与其余手指的结构相关性较低。
使用分解后的手势信号的六个单独传感器的对应图。从物体交互中分解出的手势信号用于集体提取传感器和整只手之间的相关性(类似于使用分解后的物体相关信号的图 8-3b)。与图 8-3b 不同,指尖处的像素与其余手指的结构相关性较低。
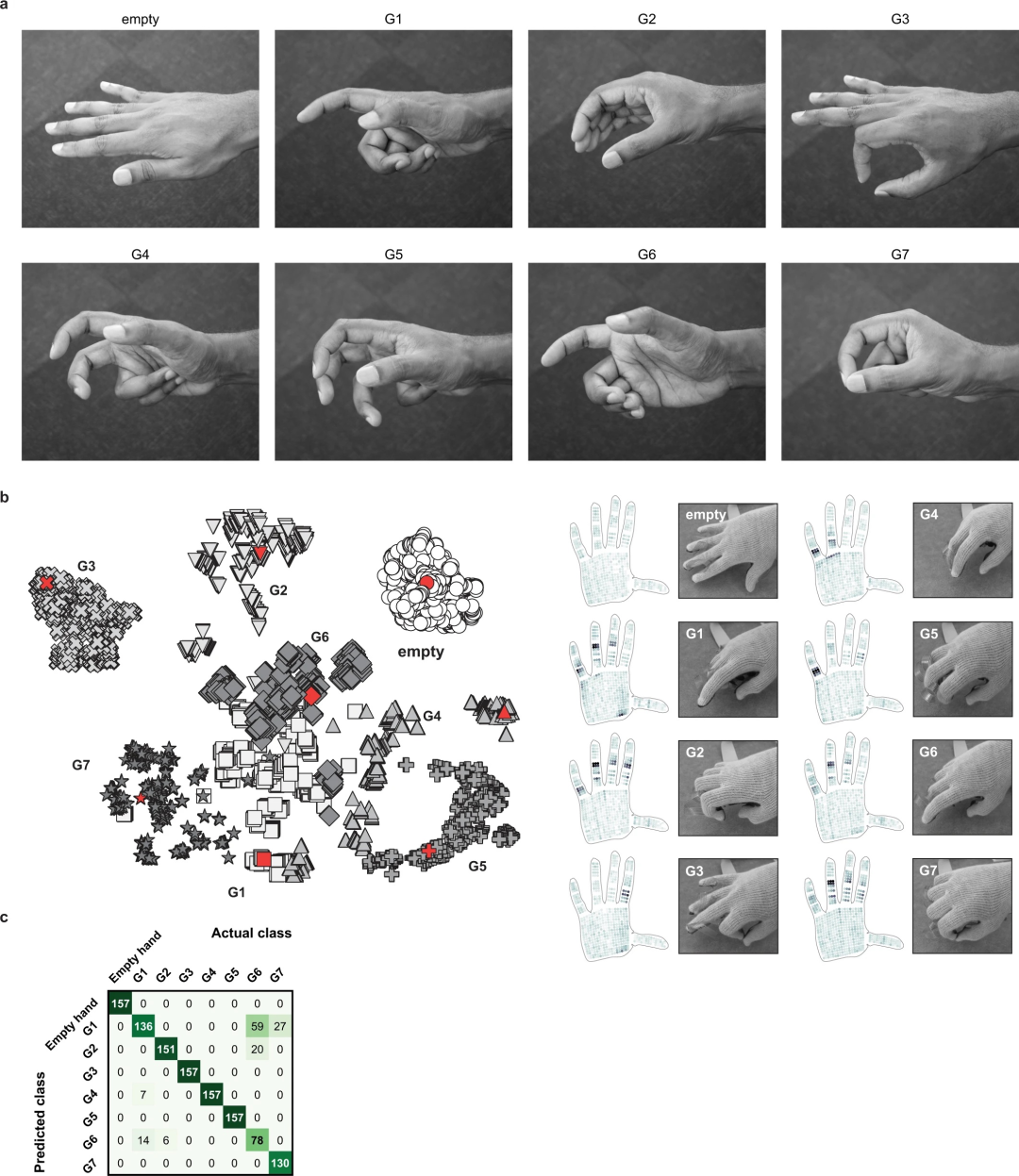 来自有关节手的手势信号。(a)手势数据集中使用的手势图像。姿势 G1 至 G7 是从最近的抓握分类法中提取的。在记录中,每个姿势都是从中性空手姿势连续表达出来的。(b)当使用 t-SNE 对该数据集中的触觉数据进行聚类时,每个不同的组都代表一个手势。右侧显示了示例触觉图。相应的样本用红色标记。(c)使用图 8-2a 中所示的相同 CNN 架构,可以以 89.4% 的准确率(10 次运行的平均值,3,080 个训练帧和 1,256 个不同的测试帧)对手势信号进行分类。混淆矩阵元素表示每个手势(列)被归类为可能手势(行)之一的频率。它表明手势 G1 和 G6 有时会被错误识别,但其他手势几乎被完美识别。
来自有关节手的手势信号。(a)手势数据集中使用的手势图像。姿势 G1 至 G7 是从最近的抓握分类法中提取的。在记录中,每个姿势都是从中性空手姿势连续表达出来的。(b)当使用 t-SNE 对该数据集中的触觉数据进行聚类时,每个不同的组都代表一个手势。右侧显示了示例触觉图。相应的样本用红色标记。(c)使用图 8-2a 中所示的相同 CNN 架构,可以以 89.4% 的准确率(10 次运行的平均值,3,080 个训练帧和 1,256 个不同的测试帧)对手势信号进行分类。混淆矩阵元素表示每个手势(列)被归类为可能手势(行)之一的频率。它表明手势 G1 和 G6 有时会被错误识别,但其他手势几乎被完美识别。
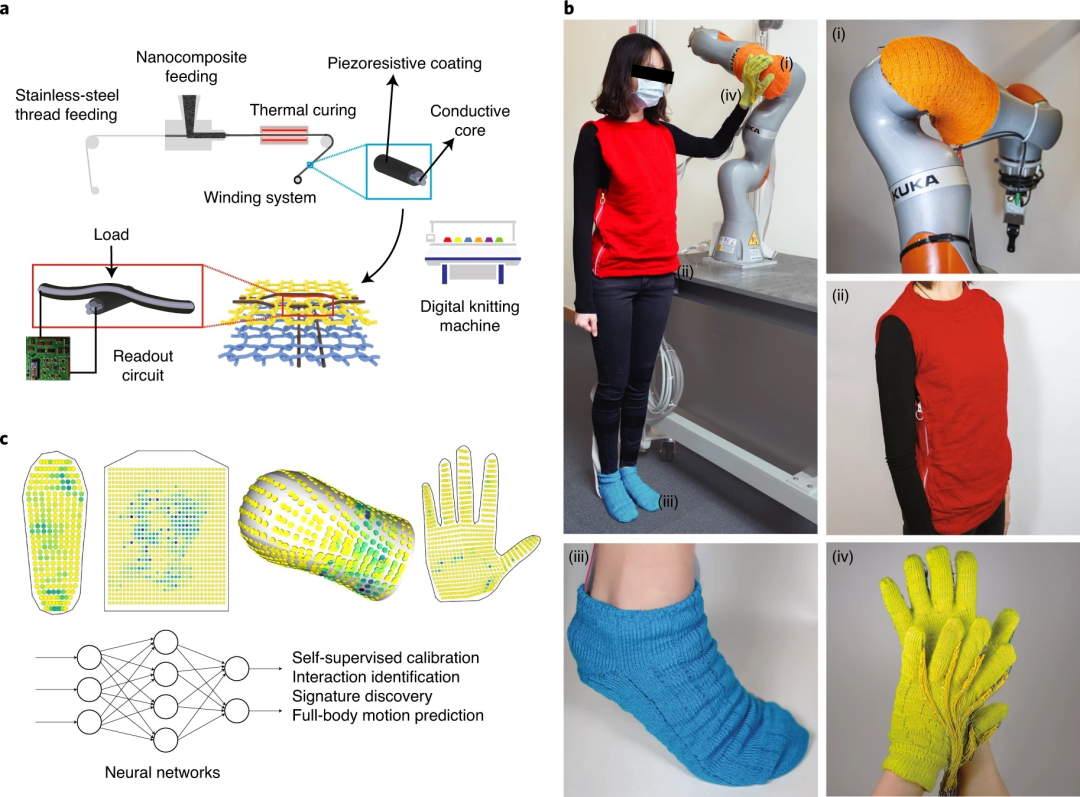 基于纺织品的触觉学习平台。(a)使用定制的同轴压阻纤维制造系统和数字机器编织可扩展制造触觉感应纺织品的示意图。商用导电不锈钢线涂有压阻纳米复合材料(由聚二甲基硅氧烷 (PDMS) 弹性体作为基质和石墨/铜纳米颗粒作为导电填料组成)。(b)数字化设计和自动编织的全尺寸触觉感应可穿戴设备:(i)人造机器人皮肤、(ii)背心、(iii)袜子和(iv)手套。(c)使用机器学习技术探索人与环境互动过程中收集的触觉框架示例及其应用。
基于纺织品的触觉学习平台。(a)使用定制的同轴压阻纤维制造系统和数字机器编织可扩展制造触觉感应纺织品的示意图。商用导电不锈钢线涂有压阻纳米复合材料(由聚二甲基硅氧烷 (PDMS) 弹性体作为基质和石墨/铜纳米颗粒作为导电填料组成)。(b)数字化设计和自动编织的全尺寸触觉感应可穿戴设备:(i)人造机器人皮肤、(ii)背心、(iii)袜子和(iv)手套。(c)使用机器学习技术探索人与环境互动过程中收集的触觉框架示例及其应用。
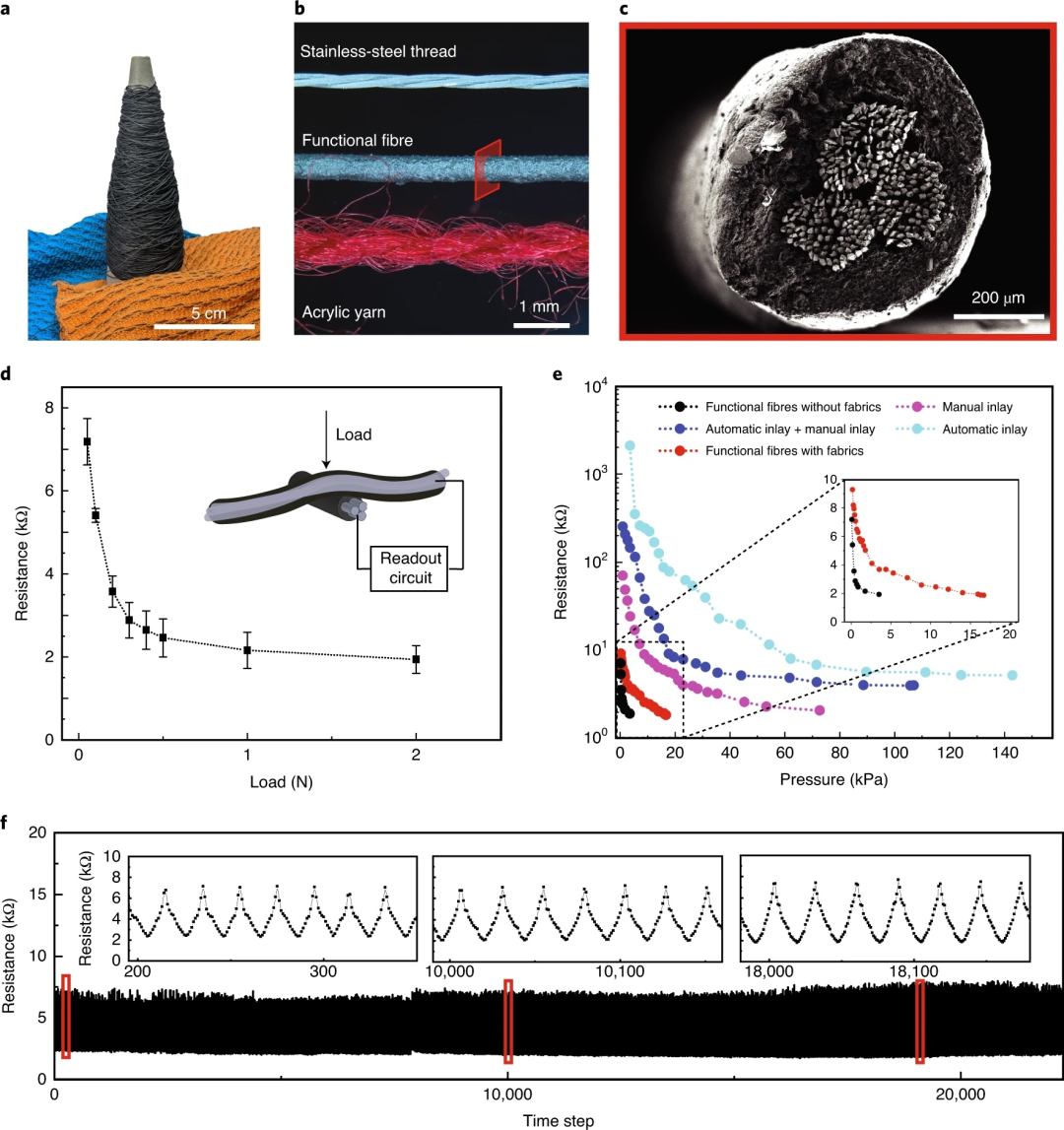 功能纤维的特性。(a)压阻功能纤维(>100m)和传感织物的照片。(b)不锈钢线、同轴压阻纤维和丙烯酸针织纱的光学图像。(c)压阻纤维的扫描电子显微镜 (SEM) 横截面图像。(d)典型传感器(由两个压阻纤维组成)对压力(或法向力)的响应电阻曲线。误差线表示四个单独传感器的标准偏差。(e)织物结构(“手动”镶嵌和自动镶嵌)对设备性能的影响。作为缓冲剂,柔软织物(红色曲线)的引入降低了灵敏度并增加了传感范围。此外,从自动镶嵌中获得的肋状结构会在两个对齐的织物(深蓝色和浅蓝色曲线)之间产生间隙,从而进一步降低灵敏度并增加检测范围。(f)典型传感器在 1,000 次力加载和卸载循环中性能稳定。
功能纤维的特性。(a)压阻功能纤维(>100m)和传感织物的照片。(b)不锈钢线、同轴压阻纤维和丙烯酸针织纱的光学图像。(c)压阻纤维的扫描电子显微镜 (SEM) 横截面图像。(d)典型传感器(由两个压阻纤维组成)对压力(或法向力)的响应电阻曲线。误差线表示四个单独传感器的标准偏差。(e)织物结构(“手动”镶嵌和自动镶嵌)对设备性能的影响。作为缓冲剂,柔软织物(红色曲线)的引入降低了灵敏度并增加了传感范围。此外,从自动镶嵌中获得的肋状结构会在两个对齐的织物(深蓝色和浅蓝色曲线)之间产生间隙,从而进一步降低灵敏度并增加检测范围。(f)典型传感器在 1,000 次力加载和卸载循环中性能稳定。
 自我监督校正。(a) 触觉袜子的校正程序。穿着者踩在电子秤上(在脚和秤之间放置一个网球以增强保形接触),并收集袜子和秤的同步读数。触觉手套也使用相同的方法。(b) 使用校准手套的响应作为参考,对背心进行自我监督校正的程序。机器人手臂袖子也使用相同的方法。右侧(a,b)的条形图显示了触觉响应和秤读数之间的相关性:“原始”表示原始未处理的触觉信号的校正;“手动”表示手动调整数据的相关性,其中所有饱和触觉信号都被剪切;“自我监督”表示自我监督校正后获得的相关性。(c–h),袜子 (c,d)、背心 (e,f) 和机器人手臂袖子 (g,h) 的原始读数和校正读数示例。我们的方法消除了伪影并增强了传感器的平滑度。颜色条表示每个传感点的相对压力。
自我监督校正。(a) 触觉袜子的校正程序。穿着者踩在电子秤上(在脚和秤之间放置一个网球以增强保形接触),并收集袜子和秤的同步读数。触觉手套也使用相同的方法。(b) 使用校准手套的响应作为参考,对背心进行自我监督校正的程序。机器人手臂袖子也使用相同的方法。右侧(a,b)的条形图显示了触觉响应和秤读数之间的相关性:“原始”表示原始未处理的触觉信号的校正;“手动”表示手动调整数据的相关性,其中所有饱和触觉信号都被剪切;“自我监督”表示自我监督校正后获得的相关性。(c–h),袜子 (c,d)、背心 (e,f) 和机器人手臂袖子 (g,h) 的原始读数和校正读数示例。我们的方法消除了伪影并增强了传感器的平滑度。颜色条表示每个传感点的相对压力。
 学习人与环境的相互作用。(a)示例照片和触觉帧。(b)触觉背心记录的姿势数据集的 t-SNE 图。每个姿势对应的簇的分离说明了传感背心的判别能力。(c)在触觉背心上按下“M”、“I”和“T”的示例照片和触觉帧。(d)字母分类准确度随着传感器分辨率的降低而下降(顶部)。用于对字母和方向进行分类的混淆矩阵(底部)。(e)我们模型中代表身体姿势的 19 个关节角度的位置。(f)姿势预测中的均方误差。(g,h)传感器分辨率(g)和输入帧数(h,时间窗口)对预测性能的影响。虚线表示定义为训练数据的典型平均姿势的基线。(i) 比较 MOCAP 记录的各种姿势(真实情况)和我们的模型从触觉袜子压力帧中恢复的相同姿势。手臂区域的显著错误以红色突出显示。(j) 步行的时间序列预测。(k) 步行触觉图上的 PCA(插图为相应的触觉帧)。
学习人与环境的相互作用。(a)示例照片和触觉帧。(b)触觉背心记录的姿势数据集的 t-SNE 图。每个姿势对应的簇的分离说明了传感背心的判别能力。(c)在触觉背心上按下“M”、“I”和“T”的示例照片和触觉帧。(d)字母分类准确度随着传感器分辨率的降低而下降(顶部)。用于对字母和方向进行分类的混淆矩阵(底部)。(e)我们模型中代表身体姿势的 19 个关节角度的位置。(f)姿势预测中的均方误差。(g,h)传感器分辨率(g)和输入帧数(h,时间窗口)对预测性能的影响。虚线表示定义为训练数据的典型平均姿势的基线。(i) 比较 MOCAP 记录的各种姿势(真实情况)和我们的模型从触觉袜子压力帧中恢复的相同姿势。手臂区域的显著错误以红色突出显示。(j) 步行的时间序列预测。(k) 步行触觉图上的 PCA(插图为相应的触觉帧)。
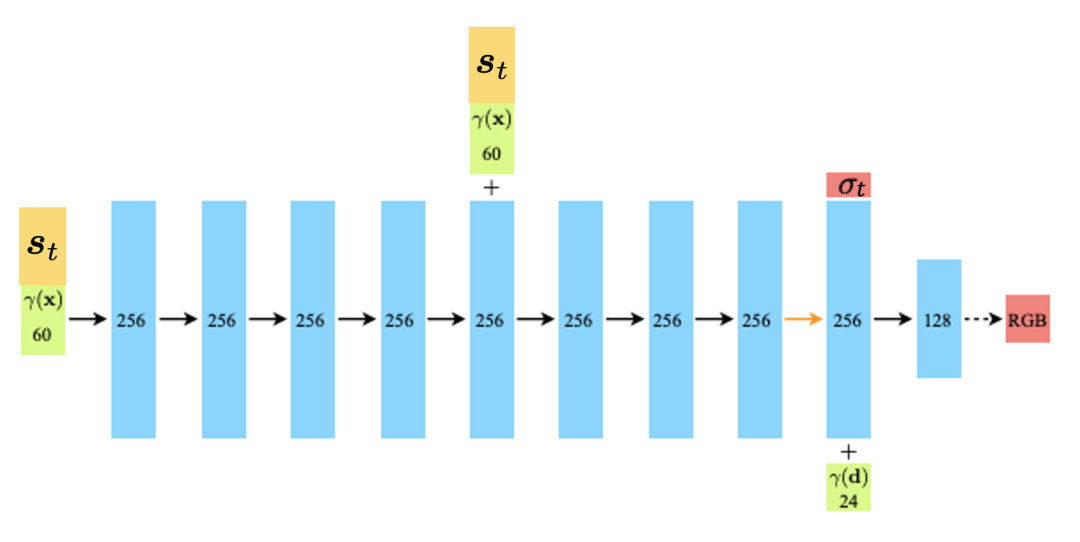 我们的解码器网络架构的可视化。所有层都是标准的全连接层,其中黑色箭头表示具有 ReLU 激活的层,橙色箭头表示没有激活的层,虚线黑色箭头表示具有 S 形激活的层,并且“+”表示向量连接。我们将输入位置的位置编码𝛾(𝑥) 和我们学习的状态表示 𝑠𝑡 连接起来,并将它们传递到 8 个全连接的 ReLU 层,每个层有 256 个通道。我们遵循 NeRF [Mildenhall et al., 2020] 架构,并包含一个将此输入连接到第五层的激活的跳跃连接。附加层输出体积密度𝜎𝑡(使用 ReLU 进行校正以确保输出体积密度为非负)和 256 维特征向量。该特征向量与输入观察方向 𝛾(𝑑) 的位置编码连接,并由具有 128 个通道的附加全连接 ReLU 层处理。最后一层(具有 S 形激活)输出位置 𝑥 处发射的 RGB 辐射度,如方向为 𝑑 的射线所见,给定当前 3D 状态表示 𝑠𝑡。
我们的解码器网络架构的可视化。所有层都是标准的全连接层,其中黑色箭头表示具有 ReLU 激活的层,橙色箭头表示没有激活的层,虚线黑色箭头表示具有 S 形激活的层,并且“+”表示向量连接。我们将输入位置的位置编码𝛾(𝑥) 和我们学习的状态表示 𝑠𝑡 连接起来,并将它们传递到 8 个全连接的 ReLU 层,每个层有 256 个通道。我们遵循 NeRF [Mildenhall et al., 2020] 架构,并包含一个将此输入连接到第五层的激活的跳跃连接。附加层输出体积密度𝜎𝑡(使用 ReLU 进行校正以确保输出体积密度为非负)和 256 维特征向量。该特征向量与输入观察方向 𝛾(𝑑) 的位置编码连接,并由具有 128 个通道的附加全连接 ReLU 层处理。最后一层(具有 S 形激活)输出位置 𝑥 处发射的 RGB 辐射度,如方向为 𝑑 的射线所见,给定当前 3D 状态表示 𝑠𝑡。
 使用真实世界数据进行动态预测。(a)我们构建了一个包含四个 D415 RGBD 摄像机的数据记录装置,以记录人体将水从一个杯子倒到另一个杯子的过程,然后使用记录的数据来评估我们模型的动态预测能力。(b)我们在从四个摄像机视图预测未来时,并排比较了地面真实数据和我们模型的预测。我们的模型正确地识别了液体何时倒出并开始填充底部容器。请观看我们的补充视频以获得更好的可视化效果。
使用真实世界数据进行动态预测。(a)我们构建了一个包含四个 D415 RGBD 摄像机的数据记录装置,以记录人体将水从一个杯子倒到另一个杯子的过程,然后使用记录的数据来评估我们模型的动态预测能力。(b)我们在从四个摄像机视图预测未来时,并排比较了地面真实数据和我们模型的预测。我们的模型正确地识别了液体何时倒出并开始填充底部容器。请观看我们的补充视频以获得更好的可视化效果。







微信群 公众号


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢