
Datawhale干货
作者:同济子豪兄,Datawhale成员
Datawhale干货
作者:同济子豪兄,Datawhale成员
01
大模型爆火两年,到底谁家“遥遥领先”?
ChatGPT爆火之后,国内外掀起大模型军备竞赛,通义千问、文心一言、零一万物、Kimi Chat、Llama3、SoRA、GPT4、GPT4o……各家厂商的开源、闭源大模型如雨后春笋般涌现。
你肯定会在各种营销号中看到“比肩 GPT4”、“超越 GPT4V”、“最强大模型易主”、“新晋炸子鸡”、“开源扛把子”、“新 SOTA”、“多模态霸榜”、“杀疯了”、“Karpathy 点赞!”、“Github 狂揽 XX 星”、“国产小钢炮”等夸张字眼。


但很多大模型都面临尴尬处境:跑分没输过,体验没赢过。
那么,到底如何公平、透明、客观、准确评价大模型的各项能力?作为开发者,到底应该选择哪款大模型?
数学、代码、推理、逻辑、记忆、理解、生成、知识、多模态、智能体,各项赛道哪些大模型独占鳌头?

最简单的办法就是:让各家大模型“做同一套卷子”、同台竞技,实时对战!
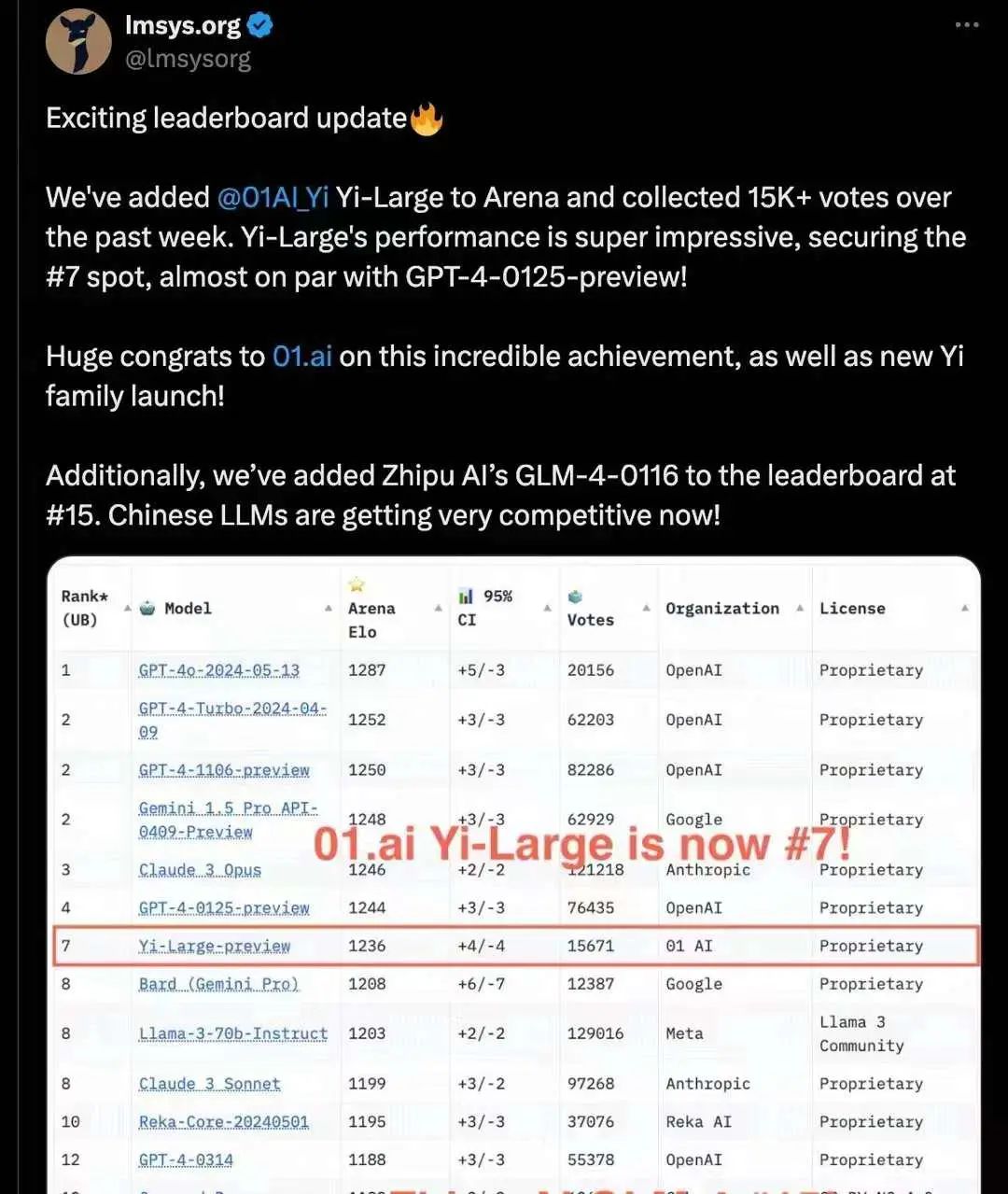
例如在国外的 Chatbot Arena 大模型对战平台,目前国产大模型中,分数最高的是 Yi-Large。
02
Compass Arena:让大模型同台竞技
上海人工智能实验室 司南 OpenCompass 和 魔搭 ModelScope 联手推出了国内首个大语言模型竞技场 Compass Arena。
Compass Arena 体验链接:
它引入全新的匿名对战模式,支持通义千问、文心一言、Meta、月之暗面、零一万物、百川智能、字节豆包、书生浦语、智谱AI、讯飞星火等15家大模型厂商的27个大模型。

03
比起单纯“跑分打榜”
Compass Arena 有以下几个好处
1.透明公正:大家都做同一道题,是骡子是马,高下立见。
2.匿名性:用户双盲测试,消除大厂滤镜和先入为主的光环,聚焦大模型能力本身。
3.模型全:目前涵盖15家大模型厂商的27个大模型。即将发布 Compass Arena 榜单,这个榜单非常客观。
4.中立:魔搭 ModelScope 是中国最大的AI开源社区,立场公正,开发者真正用手投票,没有商业化和营销号干预。

04
大模型做各科高考题,到底水平如何?
2024年3月,我使用 OpenCompass 中的 GaokaoBench 高考题库,详细测评了几款主流大模型做各科高考题的分数。
GaokaoBench 高考题库涵盖近 12 年各学科的 1781 道选择题、218 道填空题、812 道解答题。
我发现,主流中文大模型在语文、数学、地理、政治、历史、生物、物理、化学等学科,确实与 GPT4 相比毫不逊色,但在英文水平上相形见绌。

05
挑战 2024 年高考语文作文题
跑分总感觉差一点意思,为了更直观比较大模型的生成能力,我直接将2024年高考语文作文原题作为 Prompt 提示词,输入 Compass Arena 平台,打开“自选对战”模式。


仔细阅读 AI 写出的高考语文作文可以发现,通义千问 Qwen-max-0428 深度理解了题意,以“在信息洪流中寻找真问题”为题目,阐述了互联网信息洪流时代的碎片化、表面化、快餐化问题,并进一步思考:我们如何保持独立思考,寻找并解决真正的问题。主题鲜明、论点清晰、结构合理、行文流畅。


而零一万物的扛把子大模型 Yi-Large,则揭示了人工智能发展带来了伦理道德、隐私保护、就业结构变化等新问题,以及对社会、法律、道德、文化等多个层面的影响。它像一个紧跟科技热点的高中生,又像一个关心人类命运、承担社会责任的哲学家。

近几年,AI 做高考题成为每年必谈的话题,大模型的理解、生成、逻辑、记忆、写作能力逐年突飞猛进。
而有了 Compass Arena 这个平台,个人开发者可以跨过算力、数据、算法、开发门槛,直观测评出不同大模型针对同一个问题的效果,让真正优秀的大模型脱颖而出!

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢