活动
论文
风云榜
专栏
知识树
项目
社交
登录/注册
AlphaFold3不开源,DeepMind商业化最大的一道坎来了
ML
芯片架构
CV
智药局 2024-06-10 23:10 分享
以下文章来源于mp.weixin.qq.com
AlphaFold3的出现,对于整个生物医药都有巨大的意义。
但因为其没有立刻开源,掀起了一场强烈的开源闭源争议,甚至遭到了科学界的抵制。
据专业人士估计,像DeepMind那样训练AlphaFold3可能需要花费超过100万美元的云计算资源。
对于如今动辄上亿美元的AI大模型军备赛不算什么,但也已经是非常多实验室无法承受的数字。
尽管
DeepMind立马“滑跪
”,宣布将在6个月内面向学术界开源,但这个决定仍然不能让科学家们满意。
学术进步岂能受到资本制约?已经有不少
团体立项复现A
lph
aFold3,难不成DeepMind的商业化之路要断了?
开源争议
今年5月,Google DeepMind 和 Isomorphic Labs 发布了新一代AlphaFold3。
这是一种革命性模型,用于预测蛋白质、DNA、RNA、小分子等的几乎所有生物分子结构和相互作用。
但AlphaFold3并没有选择开源,取而代之的是提供网页版的AlphaFold server。
AlphaFold3 与其前代产品相比有很大不同。它采用了一种名为“扩散网络”的技术,类似于 DALL-E 等图像生成程序中使用的技术。
AlphaFold server是一款 Web 服务器,但DeepMind给予其非常大的限制,每人每天只能使用20次(最开始是10次),并且限制不少序列的输入,包括部分配体以及病毒蛋白序列。
这也限制了AlphaFold3网页版几乎没法用于药物研发。
从服务协议中可以看到,Alphafold3禁止与任何商业活动有关,包括代表商业组织进行的研究;
禁止在大多数下游工具(chimerax、foldseek、或AutoDock 等)中使用其预测;
禁止用于训练类似AlphaFold3的类似模型。
但这样限了独立研究人员和初创企业的创新能力。换句话说科学无法被复现,结果无法被验证,也很难建立和产生新的科学知识。
研究人员无法完全理解、改进或调整 AlphaFold3 以满足特定需求,从而减缓科学界的进步。
不开源?究竟是谁的锅
于是忍无可忍的科学家们终于向Nature发起了进攻。
AIphaFold3发布几天后,由加州大学旧金山分校计算结构生物学家 Stephanie Wankowic联合其他9 位科学家共同撰写了一封致《自然》杂志的
公开信
。
信中指出:“AlphaFold3不开源不符合科学进步的原则,科学进步依赖于社区评估、使用和巩固现有工作的能力”,此后已有 600 多名研究人员在信中签名。
为什么矛头对准的是Nature?
在很多人看来,Deepmind 或 Isomorphic Labs作为商业团队维护知识产权无可厚非,它们需要对股东和合作伙伴负责。
团队已经尽可能的发布有价值的信息,例如公布“伪代码”,即数据集,以及对代码功能和工作原理的描述。
而作为“把关人”的Nature,则应该肩负起维护科学出版的责任,如果没有足够的细节和验证材料证明该工作,期刊有责任和义务拒绝发表。当读者读到论文的时候,按理来说不应该因为审稿人。
关于这一问题,Nature也进行了回应,首先就是发表机构的微妙差异。
当初AlphaFold2是DeepMind团队与欧洲分子生物学实验室的欧洲生物信息学研究所合作的,后者是政府支持设立的机构,也就是非盈利机构。
现在,DeepMind 已与Isomorphic Labs 合作,后者是一家位于伦敦的药物开发公司,一家商业公司。
也就是说,因为合作对象和使用途径的问题,AF3和AF2开源是不能混为一谈。
而当前全球大多数研究都是私人资助,Nature认为如果不让成果发表出来,可能更加无法促进双方的交流,因为期刊与私营部门合作并与其科学家合作非常重要。
但科学家们为什么要研读一份他们无法复现的论文呢?如果无法亲身使用模型,又怎么让人相信论文中关于AF3模型性能大幅提升的论据?
科学论文的发布应该是严谨的,就因为Nature的一念之差,结果导致三方都不满意的局面。
好在DeepMind及时出来补救。DeepMind 此前宣布,
宣布
将在六个月内将 AlphaFold3 代码和模型权重提供给学术界使用。当时智药局也做了第一时间的报道。
但科学家表示,这个版本的 AlphaFold3 是否具备全部功能,尤其是预测蛋白质与潜在药物分子或配体结合的结构的能力,仍是一个疑问。
寻找可替代方案
外界一直猜测DeepMind究竟会以怎样的形式开源,目前可以想到的有几种方式:
1、提供服务器或 API ,学术界使用免费或者费用极低
2、开放阉割版,但内部使用更先进的模型
不过以上这两种情况都没法使研究人员满意。大家需要的是能够重新训练模型,以更好地模拟蛋白质和潜在药物之间的相互作用。
无论是学术团队还是制药公司,都渴望能够有用自己的专有数据重新训练的 AlphaFold3版本,并且对于制药公司而言,几乎不可能将核心项目上传到公共网络中。
为了避免受制于DeepMind,科学家正在尽最大努力破解AF3。其中有两个团队走在最前列。
一个是哥伦比亚大学和哈佛医学院的研究人员于 5 月中旬推出了
OpenFold
。这个非盈利团队曾经完美地复刻了AlphaFold2,不仅包括推理代码和模型参数,可重现和改进 AlphaFold2 的速度和准确性,还包括完整的训练代码,可以训练一整套衍生模型。
该团队也宣布开启了OpenFold3模型的开发,同样公布代码和数据库,不会对商业用途有任何限制。
还有一个则是软件工程师Phil Wang领导的开源团队,团队包括密苏里大学、莱比锡大学以及生物信息学专家等,该项目几乎每天都有更新。(https://github.com/lucidrains/alphafold3-pytorch)
不过呢,开源的挑战不在于复现代码,而在于训练 AI 模型所需的大量计算资源。
业内人士估计,AlphaFold3需要花费高达 100 万美元的云计算资源,对于非盈利团队可能负担较大。
开源闭源之争
Nature没有说错的一点是,引领人工智能在生物技术领域革命的主导权,正在逐渐从非盈利团队走向了商业化机构。
就像OpenAI一样,此前标榜着自己是一家无盈利的AI研究机构,GPT前几代都按照承诺全面开源。
但一旦商业化苗头开始兴起,OpenAI宁愿给用户免费使用最新的ChatGPT/GPT-4O,仍然打死都不愿意开源。
按照这样的思路,DeepMind将AlphFold2全面开源,AlphaFold3选择性开源,之后的4代和5代极有可能完全闭源。
医药领域不像通用大模型对于算力有极大的需求,如今 Isomorphic Labs已经和礼来、诺华等跨国药企合作,能够拿到大型制药公司的数据,并且通过真实数据设计试验。
优质数据对模型性能提升至关重要,而大规模的数据收集几乎只会发生在商业团体,越来越和开源模型拉开差距。
例如以10亿美元设立的Xaira Therapeutics,整合了来自David Baker团队RFdiffusion的AI模型,尽管这些都是开源模型,但在10亿美元资金的推动下,势必在开源版本基础上进行扩展和升级。
总结而言,AlphaFold3的事件体现了一场长期存在的冲突:
科学进步与知识产权 (IP)
。生物医药又极其看重对知识产权的保护,包括新药物分子以及技术平台等。
讨论这件事的意义在于,
未来十年开源与闭源的争论都可能持续存在。
毕竟企业有正当理由保护其投资,但过度的知识产权限制会阻碍科学进步并限制创新的社会效益。
不过笔者认为一旦“人工智能+生物医药”有足够多的确定性,开源问题将得到很大程度上的解决。
就如同OpenAI作为市场领先者选择闭源,但Meta开源的Llama为其带来了大量的声望,很多初创公司也因为“开源”ChatGPT而声名鹊起。
也就是说,有开源和闭源之争并不一定是坏事,这意味着该领域的商业化进程在逐步清晰。
—The End—
推荐阅读
内容中包含的图片若涉及版权问题,请及时与我们联系删除
点赞
收藏
评论
分享到Link
举报反馈
举报类型(必选)
样式问题
涉嫌广告
内容抄袭
内容侵权
政治相关
内容涉黄
其他
举报详情(选填)
0/200
评论列表
沙发等你来抢
去评论
评论
登录
后可提问交流
沙发等你来抢


 开源争议
开源争议

 不开源?究竟是谁的锅
不开源?究竟是谁的锅
 寻找可替代方案
寻找可替代方案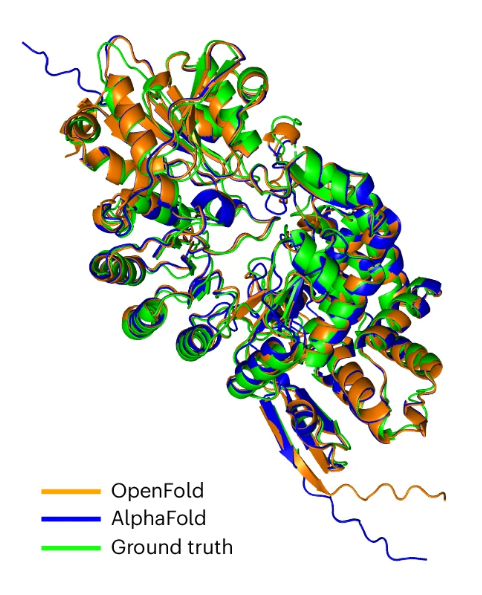
 开源闭源之争
开源闭源之争


 开源争议不开源?究竟是谁的锅寻找可替代方案开源闭源之争
开源争议不开源?究竟是谁的锅寻找可替代方案开源闭源之争
评论
沙发等你来抢