
化学文献中蕴含着丰富信息,通过“化学文本挖掘技术”提取关键数据,从而构建庞大的数据库,不仅能够为实验化学家提供详尽的物理化学性质和合成路线指引,还能够为计算化学家提供丰富的数据和洞见用于模型构建和预测。然而,由于化学语言的复杂性和论文风格的多样性,从化学文献中提取结构化数据是一项极具挑战性的任务。因此,许多文本挖掘工具应运而生,旨在解决这一棘手难题,助力科学研究迈向新的高峰。然而,这些针对特定数据集和语法规则构建的文本提取模型往往缺乏灵活的迁移能力。近两年,以ChatGPT为代表的大语言模型(LLMs)风靡全球,引领了人工智能和自然语言处理领域的快速发展。能否利用通用大语言模型强大的文本理解和文字处理能力,从复杂化学文本中灵活准确地提取信息,解放数据标注工人的劳动力,加速领域数据的收集呢?
中国科学院上海药物研究所郑明月团队在五项化学文本挖掘任务上对多个大语言模型的能力进行了全面综合的探究,包括化合物实体识别、反应角色标注、金属有机框架(MOF)合成信息提取、核磁共振波谱(NMR)数据提取和反应合成段落转换动作序列。团队成员基于多种大语言模型探索了多种策略,证实了微调大模型在化学知识信息提取任务上的通用性和准确性,有望加速各领域的数据收集和科学发现。相关研究论文以“Fine-tuning large language models for chemical text mining”为题于2024年6月7日发表在Chemical Science上。

1 背景
由于化学语言的复杂性和异质性,从复杂的化学文献中提取结构化数据是一项具有挑战性的任务。设计针对特定任务的模型和算法,需要广泛的领域知识和复杂的数据处理,难以适应不同的提取任务,通常需要互补协作来完成复杂的信息提取任务,从而限制了它们的通用性和实用性。
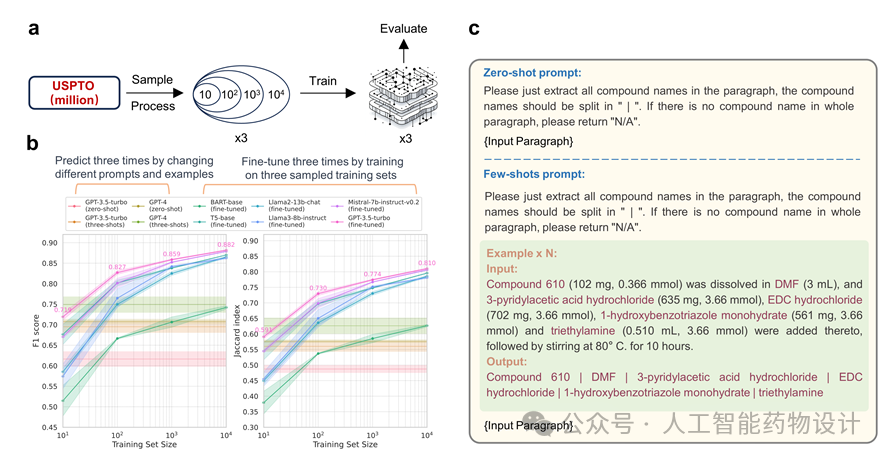
以2022年11月发布的 ChatGPT 为代表的大型语言模型(LLMs)展示了通用人工智能(AGI)的潜力。但是当前,LLMs仍然很难准确回答基于事实和知识的问题,如果将LLMs用于知识提取任务应该可以减轻幻觉,并充分利用其强大的文本理解和处理能力。但是Chen等人的基准研究发现仅基于提示工程的ChatGPT 在生物医学文本挖掘方面的表现显著差于已有模型[1]。这可能是因为人类的表达是不清晰、不完整、模糊、难以提炼的,而且模型的输出可能缺乏标准化,导致在从复杂文本(如专利或科学文献)挖掘数据时性能不佳,这种零样本或少样本提示往往不足以解决复杂场景的多样性问题,难以保证提取数据的质量。本研究主要从五个化学文本挖掘任务来探索微调大模型在复杂信息提取上的潜力(图1)。

2 结果与讨论
2.1 Paragraph2Compound:化合物实体识别
研究人员基于USPTO数据集,从数百万个自动标注的段落-实体对中随机抽样用于训练模型(图2a),并确保每个较小子集包含在较大子集中。微调模型和依赖于提示工程的结果均来自于三次独立实验(图2b)。图2c展示了在这个化合物实体识别任务中如何使用零样本和少样本提示,来指导大语言模型在不改变模型权重的情况下得到更好的输出。由于任务简单且指令清晰,仅依赖于提示工程的GPT-3.5-turbo和GPT-4获得超过0.60的F1分数,各微调模型的性能均随着训练集大小的增加而稳定上升,达到超过0.85的F1分数。
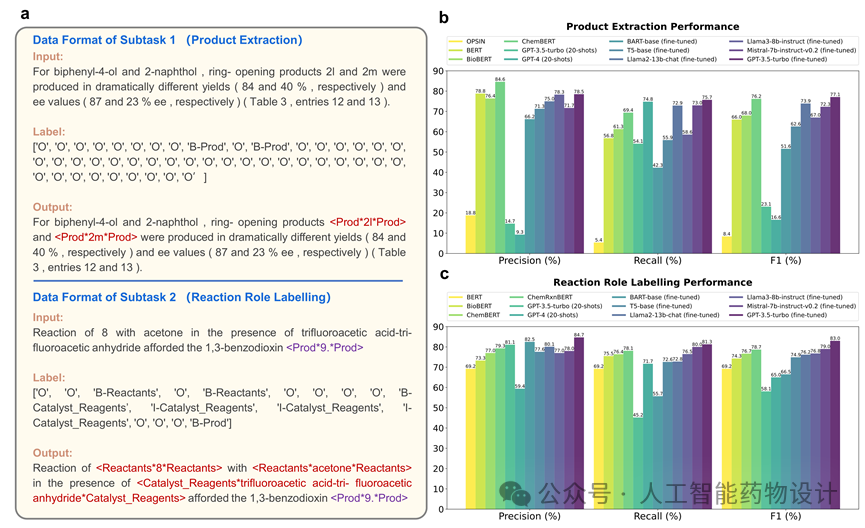
2.2 Paragraph2RXNRole:反应角色识别
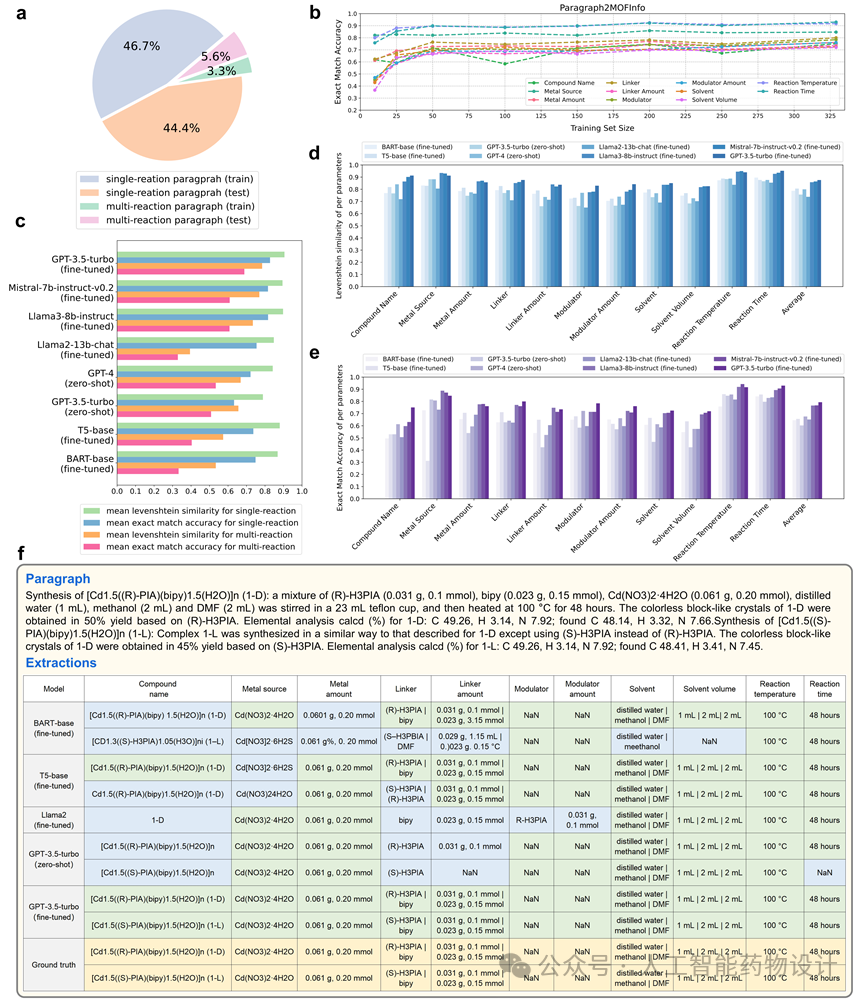
2.3 Paragraph2MOFInfo:MOF合成信息提取
研究人员重新手工标注了Zheng等人的数据集[3],包含329条训练集和329条测试集,并使用 Levenshtein 相似性和完全匹配准确率作为指标来客观评估模型定制化提取结构化数据的能力。虽然大多数模型在11个参数中实现了较高的Levenshtein相似性(图4d),但只有少数模型保持了较高的完全匹配准确率(图4e),而这是格式化数据提取关注的黄金指标。图4f中展示了不同模型从文本段落提取多条反应信息的结果,该段落中包含两个反应,第一个反应以(R)-H3PIA 和bipy为连接子,并明确提供所有反应条件,第二个反应用(S)-H3PIA替换(R)-H3PIA,并保持所有其他条件不变。大多数模型能够成功理解语义,并从段落中提取出两个反应。然而,只有经过微调的GPT-3.5-turbo完美地提取出与标注答案完全一致的信息,其它模型均有不同程度的错误,特别是涉及到多个物质和多个数量的信息提取时。
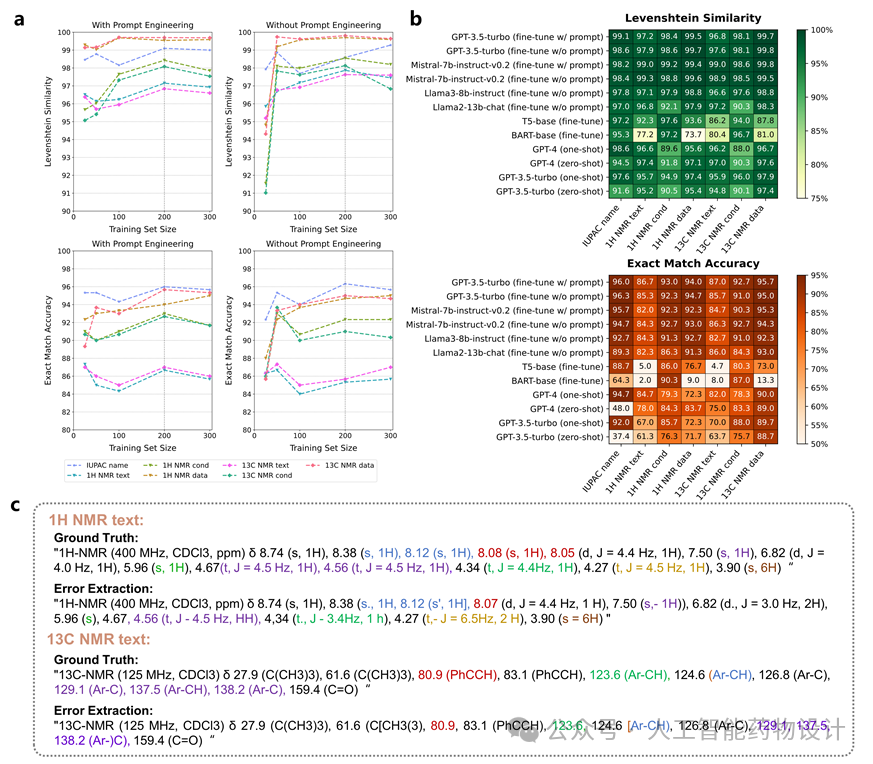
2.5 Paragraph2Action:合成段落转换为动作序列
上述任务只需要模型提取出存在于段落中的特定信息。但是,Paragraph2Action任务要求模型理解段落,并将实验过程转换为结构化的合成步骤(动作序列)。显然,仅使用提示工程的GPT模型难以完成这项任务,尤其是涉及多个复杂转换和提示描述不足时。为了探索仅使用提示工程时GPT模型的最大潜力,研究人员将转换示例的数量从6个逐渐增加到30个和60个。尽管示例中至少包含一次所有类型的操作,并且接近GPT-3.5-turbo-0613的4096和GPT-4-0613的8192个词元个数限制,但它们在少样本场景下的表现仍然令人失望。即使是最先进的GPT-4在60个样本的上下文学习中,也仅达到32.7%的完全匹配准确率。此外,由于上下文较长,推理时会耗费大量的词元数,带来巨大的推理花销。
然而,微调预训练的语言模型展现了不错的性能。在1060条手动标注训练数据上微调 Mistral-7b-instruct-v0.2和GPT-3.5-turbo等LLM,能够达到64.8%和63.6%的完全匹配准确率(表1),轻松超过了Vaucher等人之前报道的SOTA结果[4]。该方法集成了三个Transformer模型,每个模型都对200万条基于规则的数据进行了任务自适应预训练,并在14 168条增强数据上进行了微调。当GPT-3.5-turbo在14 168条增强数据上进行微调,完全匹配准确率能够进一步提升至69.0%。对于实现自动化合成来说,生成严格遵循语法规则的可执行指令是具有挑战性的。微调LLMs有望在弥补模糊自然语言和结构化机器可执行编程语言之间的鸿沟方面起到至关重要的作用,显著提高定制化转换的准确性。在这类涉及“模糊规则”或难以定义的转换任务中,使用高质量标注数据微调 LLMs或许具有较大优势。
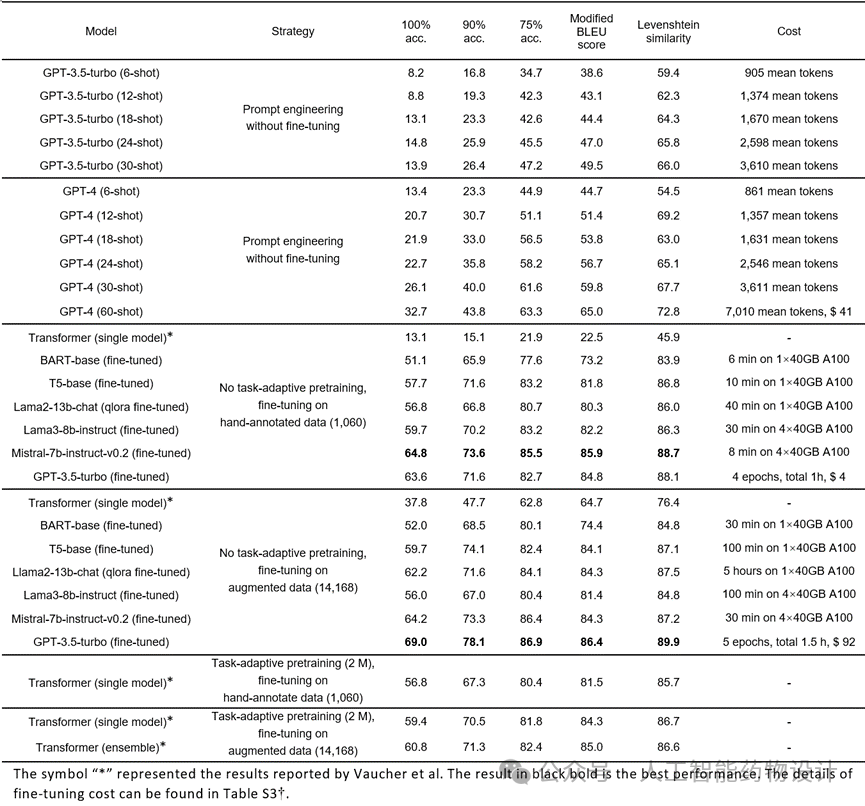
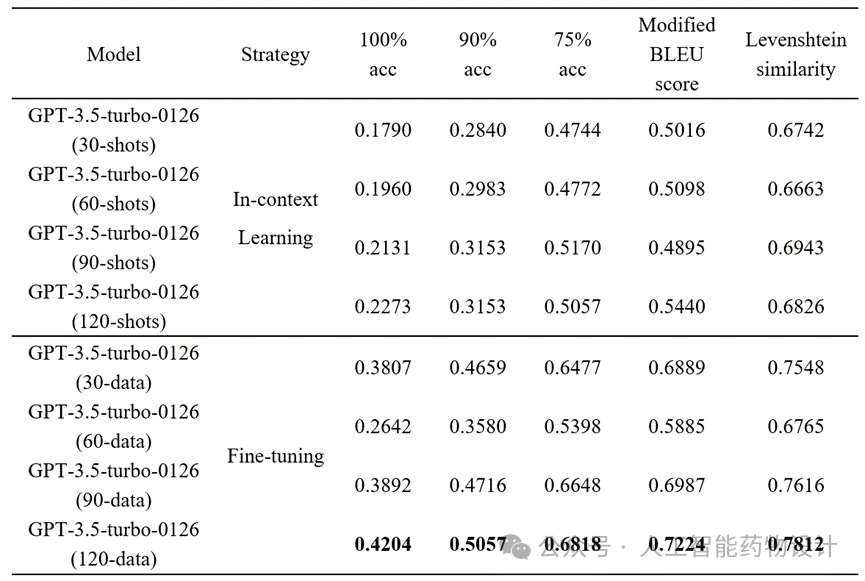
由于内存限制,上下文学习的上限往往受到最大输入长度的限制,将基于零样本或少样本提示的模型与使用完整数据集训练的微调模型比较并不公平。为了客观地比较上下文学习和微调方法的性能,应为同一个大模型提供相同数量的相同示例。在这里,研究人员测试了最新的GPT-3.5-turbo-0125,上下文长度扩展到16 K并同时支持微调。研究人员在采样过程中尽可能涵盖所有类型的动作,随着示例数量从30个增加到60个、90个和120个,上下文学习和微调的性能都在提高(表2),但微调模型在完全匹配准确率等指标上的通常更优10-20%。这可能归因于上下文学习中的信息丢失,而微调以调整参数的形式学习提取模式从而达到更高的准确性。
3 结论
本研究探索了微调大语言模型在化学文本挖掘上的潜力,从五个任务上全面综合地展示了微调LLMs的通用性、稳健性和有效性,为其他领域数据的标准化、格式化提取提供参考,有望加速科学发现的积累与进步。
中国科学院上海药物研究所博士研究生张玮、南京中医药大学与上海药物所联合培养硕士研究生王庆功为本文的共同第一作者。中国科学院上海药物研究所郑明月研究员、付尊蕴博士后为本文通讯作者。本研究得到了国家自然科学基金、国家重点研发专项、上海药物研究所与上海中医药大学中医药创新团队联合研究项目、上海市超级博士后计划、上海市科技重大专项等项目的资助。
参考文献
[1]Q. Chen, H. Sun, H. Liu, Y. Jiang, T. Ran, X. Jin, X. Xiao, Z. Lin, H. Chen and Z. Niu, An Extensive Benchmark Study on Biomedical Text Generation and Mining with ChatGPT, Bioinformatics, 2023, btad557.
[2]J. Guo, A. S. Ibanez-Lopez, H. Gao, V. Quach, C. W. Coley, K. F. Jensen and R. Barzilay, Automated chemical reaction extraction from scientific literature, J. Chem. Inf. Model., 2021, 62, 2035-2045.
[3]Z. Zheng, O. Zhang, C. Borgs, J. T. Chayes and O. M. Yaghi, ChatGPT Chemistry Assistant for Text Mining and the Prediction of MOF Synthesis, J. Am. Chem. Soc., 2023, 145, 18048-18062.
(点击下方“阅读原文”跳转)

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢